試圖擺脫 for 回圈以加快執行基于 if、elif 條件涉及多列和多行的“C”列中的填充值。無法找到合適的解決方案。
嘗試使用條件、選項和默認值應用 np.where。但未能獲得預期的結果,因為我無法從熊貓系列物件中提取單個值。
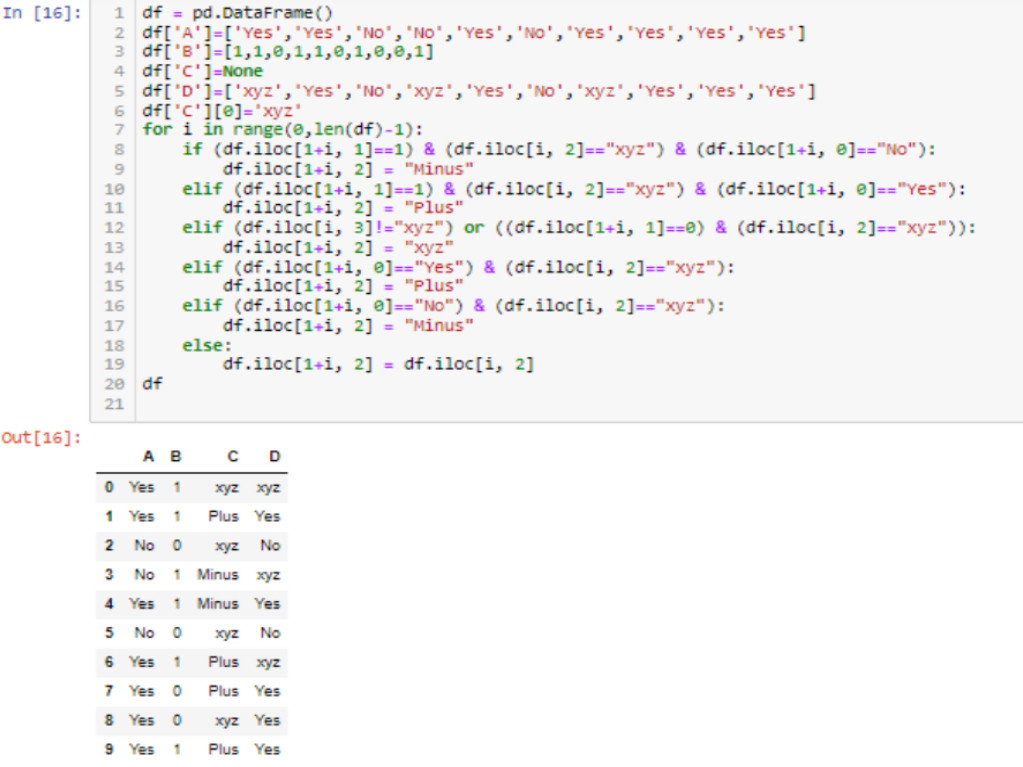
df = pd.DataFrame()
df['A']=['Yes','Yes','No','No','Yes','No','Yes','Yes','Yes','Yes']
df['B']=[1,1,0,1,1,0,1,0,0,1]
df['C']=None
df['D']=['xyz','Yes','No','xyz','Yes','No','xyz','Yes','Yes','Yes']
df['C'][0]='xyz'
for i in range(0,len(df)-1):
if (df.iloc[1 i, 1]==1) & (df.iloc[i, 2]=="xyz") & (df.iloc[1 i, 0]=="No"):
df.iloc[1 i, 2] = "Minus"
elif (df.iloc[1 i, 1]==1) & (df.iloc[i, 2]=="xyz") & (df.iloc[1 i, 0]=="Yes"):
df.iloc[1 i, 2] = "Plus"
elif (df.iloc[i, 3]!="xyz") or ((df.iloc[1 i, 1]==0) & (df.iloc[i, 2]=="xyz")):
df.iloc[1 i, 2] = "xyz"
elif (df.iloc[1 i, 0]=="Yes") & (df.iloc[i, 2]=="xyz"):
df.iloc[1 i, 2] = "Plus"
elif (df.iloc[1 i, 0]=="No") & (df.iloc[i, 2]=="xyz"):
df.iloc[1 i, 2] = "Minus"
else:
df.iloc[1 i, 2] = df.iloc[i, 2]
df
期待社區的幫助,將上述代碼修改為執行時間更少的更好的代碼。最好使用 numpy Vectorization。
uj5u.com熱心網友回復:
使用 Numpy 或 Pandas 肯定無法有效地對回圈進行矢量化,因為回圈攜帶的資料依賴于df['C']. 由于 Pandas 直接索引和字串比較,回圈非常慢。希望您可以使用Numba有效地解決此問題。您首先需要將列轉換為強型別Numpy 陣列,以便 Numba 有用。請注意,Numba 處理字串的速度非常慢,因此最好直接使用 Numpy 執行矢量化檢查。
這是生成的代碼:
import numpy as np
import numba as nb
@nb.njit('UnicodeCharSeq(8)[:](bool_[:], int64[:], bool_[:])')
def compute(a, b, d):
n = a.size
c = np.empty(n, dtype='U8')
c[0] = 'xyz'
for i in range(0, n-1):
prev_is_xyz = c[i] == 'xyz'
if b[i 1]==1 and prev_is_xyz and not a[i 1]:
c[i 1] = 'Minus'
elif b[i 1]==1 and prev_is_xyz and a[i 1]:
c[i 1] = 'Plus'
elif d[i] or (b[i 1]==0 and prev_is_xyz):
c[i 1] = 'xyz'
elif a[i 1] and prev_is_xyz:
c[i 1] = 'Plus'
elif not a[i 1] and prev_is_xyz:
c[i 1] = 'Minus'
else:
c[i 1] = c[i]
return c
# Convert the dataframe columns to fast Numpy arrays and precompute some check
a = df['A'].values.astype('U8') == 'Yes'
b = df['B'].values.astype(np.int64)
d = df['D'].values.astype('U8') != 'xyz'
# Compute the result very quickly with Numba
c = compute(a, b, d)
# Store the result back
df['C'].values[:] = c.astype(object)
這是我機器上的結果性能:
Basic Pandas loops: 2510 us
This Numba code: 20 us
Thus, the Numba implementation is 125 times faster. In fact, most of the time is spent in the Numpy conversion code and not even in compute. The gap should be even bigger on large dataframes.
Note that the line df['C'].values[:] = c.astype(object) is much faster than the equivalent expression df['C'] = c (about 16 times).
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/443060.html