我有兩個資料框(df1,df2),df1 包含主題串列,df2 包含 df1 中的主題及其集群或組。
這是一個示例輸入資料框:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'topics':['algebra', 'evolution', 'calculus', 'quantum', 'geometry', 'botany', 'physics', 'zoology']})
給予

df2 = pd.DataFrame({'topics':['algebra', 'calculus', 'geometry','evolution', 'botany', 'zoology', 'quantum', 'physics'],
'cluster':[0, 0, 0, 1, 1, 1, 2, 2]
})
給予
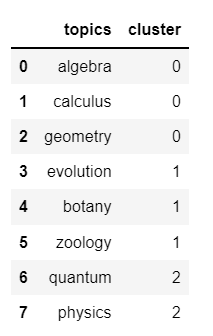
從上面的資料幀中,我需要創建一個具有矩陣結構的最終資料幀,如下所示(例如,如果同一集群中的相應主題,則分配 1,否則分配 0)?
uj5u.com熱心網友回復:
這是一個有效的矢量化解決方案:
s = df2.set_index('topics')['cluster']
new_df = pd.concat([s.eq(s[k]) for k in df1['topics']], axis=1).loc[df1['topics'].tolist()].astype(int).set_axis(df1['topics'], axis=1)
輸出:
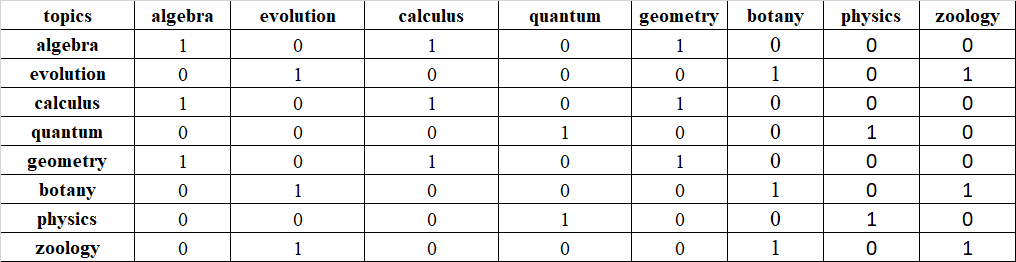
>>> new_df
topics algebra evolution calculus quantum geometry botany physics zoology
topics
algebra 1 0 1 0 1 0 0 0
evolution 0 1 0 0 0 1 0 1
calculus 1 0 1 0 1 0 0 0
quantum 0 0 0 1 0 0 1 0
geometry 1 0 1 0 1 0 0 0
botany 0 1 0 0 0 1 0 1
physics 0 0 0 1 0 0 1 0
zoology 0 1 0 0 0 1 0 1
uj5u.com熱心網友回復:
這就是我想出的:
new_df = pd.DataFrame(index=df2.topics)
for _, row in df2.iterrows():
new_df[row.values[0]] = (df2.cluster == row.values[1]).astype(int).values
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/443074.html
下一篇:在串列值之后命名資料框