本文是位元組跳動資料平臺資料引擎SparkSQL團隊針對 Spark History Server (SHS) 的優化實踐分享,

文 | 位元組跳動資料平臺—資料引擎—SparkSQL團隊
在位元組跳動內部,我們實作了一套全新的云原生 Spark History 服務—— UIService,相比開源的 SHS,UIService 存盤占用和訪問延遲均降低 90% 以上,目前 UIService 服務已經在位元組跳動內部廣泛使用,并且作為火山引擎湖倉一體分析服務 LAS(LakeHouse Analytics Service)的默認服務,
LAS
業務背景
開源 Spark History Server 架構
為了能夠更好理解本次重構的背景和意義,首先對原生 Spark History Server 原理做個簡單的介紹,
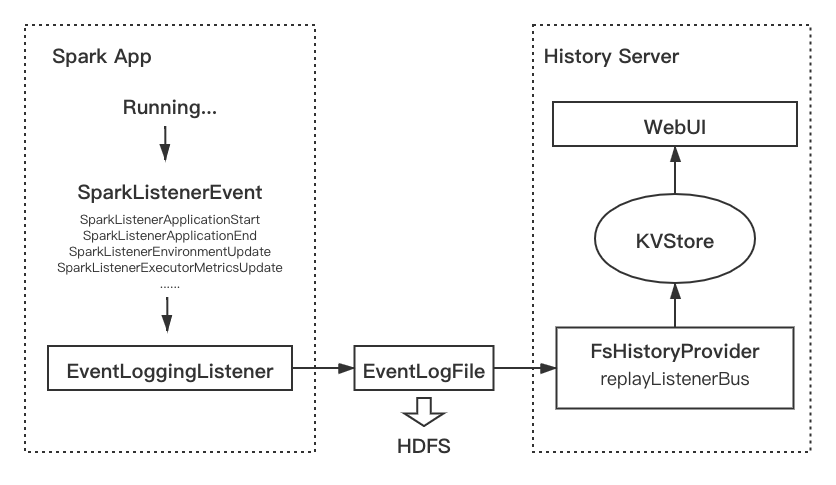
開源 Spark History Server 流程圖
Spark History 建立在 Spark 事件(Spark Event)體系之上,在 Spark 任務運行期間會產生大量包含運行資訊的SparkListenerEvent,例如 ApplicationStart / StageCompleted / MetricsUpdate 等等,都有對應的 SparkListenerEvent 實作,所有的 event 會發送到ListenerBus中,被注冊在ListenerBus中的所有listener監聽,其中EventLoggingListener是專門用于生成 event log 的監聽器,它會將 event 序列化為 Json 格式的 event log 檔案,寫到檔案系統中(如 HDFS),通常一個機房的任務的檔案都存盤在一個路徑下,
在 History Server 側,核心邏輯在 FsHistoryProvider中,FsHistoryProvider 會維持一個執行緒間歇掃描配置好的 event log 存盤路徑,遍歷其中的 event log 檔案,提取其中概要資訊(主要是 appliaction_id, user, status, start_time, end_time, event_log_path),維護一個串列,當用戶訪問 UI,會從串列中查找請求所需的任務,如果存在,就完整讀取對應的 event log 檔案,進行決議,決議的程序就是一個回放程序(replay),Event log 檔案中的每一行是一個序列化的 event,將它們逐行反序列化,并使用 ReplayListener將其中資訊反饋到 KVStore 中,還原任務的狀態,
無論運行時還是 History Server,任務狀態都存盤在有限幾個類的實體中,而它們則存盤在 KVStore中,KVStore是 Spark 中基于記憶體的KV存盤,可以存盤任意的類實體,前端會從KVStore查詢所需的物件,實作頁面的渲染,
痛點
存盤空間開銷大
Spark 的事件體系非常詳細,導致 event log 記錄的事件數量非常大,對于UI顯示來說,大部分 event 是無用的,并且 event log 一般使用 json 明文存盤,空間占用較大,對于比較復雜或時間長的任務,event log 可以達到幾十GB,位元組內部7天的 event log 占用約 3.2 PB 的 HDFS 存盤空間,
回放效率差,延遲高
History Server 采用回放決議 event log 的方式還原 Spark UI,有大量的計算開銷,當任務較大就會有明顯的回應延遲,回應延遲是指從用戶發起前端訪問到頁面 UI 完全渲染出來的等待時長,作業結束之后,用戶可能要等十幾分鐘甚至半小時才能通過 History Server 看到作業歷史,而大型作業結束后,用戶往往希望盡快看到作業歷史從而根據作業歷史進行問題診斷和作業優化,用戶等待 UI 完成渲染時間過長,非常影響用戶體驗,
擴展性差
如上所述,History Server 的FsHistoryProvider在回放決議檔案之前,需要先掃描配置的 event log 路徑,遍歷其中的 event log,將所有檔案的元資訊加載到記憶體中,這使得原生服務成為了有狀態的服務,因此每次服務重啟,都需要重新加載整個路徑,才能對外服務,每個任務在完成后,也需要等待下一輪掃描才能被訪問到,
當集群任務數量增多,每一輪掃描檔案的耗時以及元資訊記憶體占用都會增加,這也要求服務有越來越高的資源配置,如果通過拆分 event log 路徑來縮小單實體的壓力,需要對路由規則進行改造,運維難度增大,目前,位元組跳動內部通過增加 UIService 實體就可以方便的進行水平擴展,
非云原生
Spark History Server 并非是云原生的服務,在公有云場景下改造和維護成本高,首先公有云場景需要進行租戶資源隔離,其次公有云場景下不同用戶的 workload 差異很大,不同用戶任務量有數量級的差別,會出現大量長尾作業,為每個用戶單獨部署 History Server 計算和存盤成本過大且不均衡,而部署統一的 History Server 無法做到資源隔離,一旦出現問題影響較多用戶,兩種方式運維成本都會很高,火山引擎湖倉一體分析引擎 LAS(Lakehouse Analytics Service),提供了云原生的 UIService,可以有效解決上述問題,
UIService
方案
為了解決前面的三個問題,我們嘗試對 History Server 進行改造,
如上所述,無論運行中的 Spark Driver 還是 History Server,都是通過監聽 event,將其中包含的任務變化資訊反映到幾種 UI 相關的類的實體中,然后存入KVStore供 UI 渲染,也就是說,KVStore中存盤著 UI 顯示所需的完備資訊,對于 History Server 的用戶來說,絕大多數情況下我們只關心任務的最終狀態,而無需關心引起狀態變化的具體 event,
因此,我們可以只將 KVStore 持久化下來,而不需要存盤大量冗余的 event 資訊,此外,KVStore原生支持了 Kryo 序列化,性能明顯于 Json 序列化,我們基于此思想重寫了一套新的 History Server 系統,命名為 UIService,
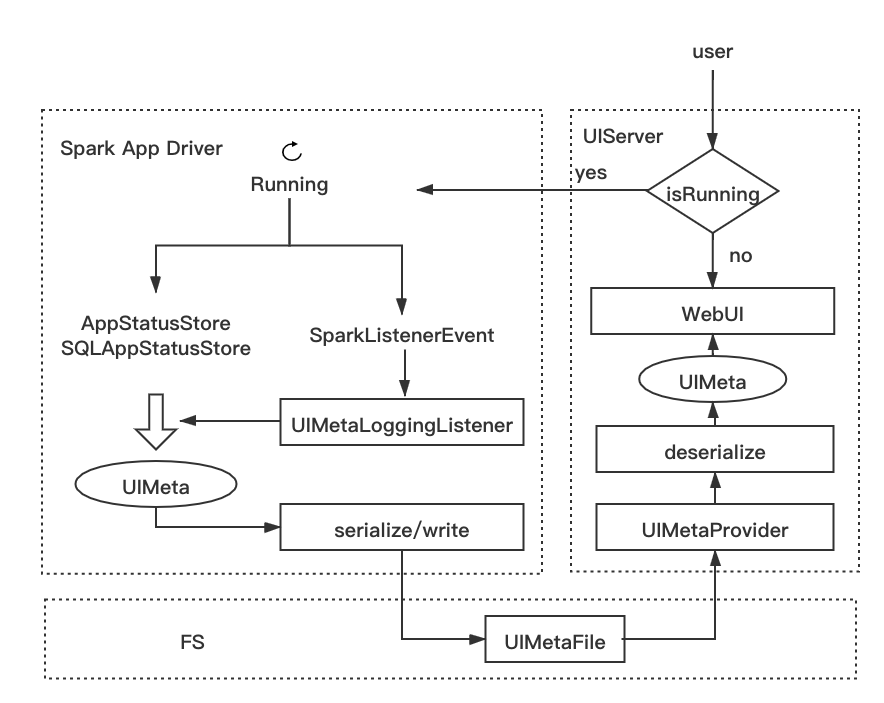
UIService框架圖
實作
UIMetaStore
KVStore中和 UI 相關的所有類實體,我們將這些類統稱為 UIMeta 類,具體包括 AppStatusStore和SQLAppStatusStore中的資訊(如下所列),我們定義一個類 UIMetaStore來抽象,一個UIMetaStore即一個任務所有 UI 資訊的集合,
UIMetaStore所包含資訊:
#AppStatusStore
org.apache.spark.status.JobDataWrapper
org.apache.spark.status.ExecutorStageSummaryWrapper
org.apache.spark.status.ApplicationInfoWrapper
org.apache.spark.status.PoolData
org.apache.spark.status.ExecutorSummaryWrapper
org.apache.spark.status.StageDataWrapper
org.apache.spark.status.AppSummary
org.apache.spark.status.RDDOperationGraphWrapper
org.apache.spark.status.TaskDataWrapper
org.apache.spark.status.ApplicationEnvironmentInfoWrapper
#SQLAppStatusStore
org.apache.spark.sql.execution.ui.SQLExecutionUIData
org.apache.spark.sql.execution.ui.SparkPlanGraphWrapper
UIMetaStore 還定義了持久化檔案的資料結構,結構如下:
4-Byte Magic Number: "UI_S"
----------- Body ---------------
4_byte_length_of_class_name | class_name_str1 | 4_byte_length | serialized_of_class1_instance1
4_byte_length_of_class_name | class_name_str1 | 4_byte_length | serialized_of_class1_instance2
4_byte_length_of_class_name | class_name_str2 | 4_byte_length | serialized_of_class2_instance1
4_byte_length_of_class_name | class_name_str2 | 4_byte_length | serialized_of_class2_instance2
- Magic Number用于檔案型別標識校驗,
- Body 是 UIMetaStore 的主體資料,使用連續存盤,每一個 UI 相關的類實體,會序列化成四個片段:類名長度(4 byte long 型別)+ 類名(string 型別)+ 資料長度(4 byte long 型別)+ 序列化的資料(二進制型別),在讀取時順序讀取,每個元素先讀取長度資訊,再根據長度讀取后續相應資料進行反序列化,
- 使用 Spark 原生的KVStoreSerializer序列化,可以保證前后兼容性,
UIMetaLoggingListener
類似于EventLoggingListener,為 UIMeta 開發了專用的 Listener —— UIMetaLoggingListener,用于監聽事件,寫 UIMeta 檔案,
和EventLoggingListener進行對比:EventLoggingListener每接受一個 event 都會觸發寫,寫的是序列化的 event;而UIMetaLoggingListener只會被特定的 event 觸發,目前是只會被stageEnd,JobEnd 事件觸發,但每次寫操作是批量的寫,將上一階段的UIMetaStore的資訊完整地持久化,
做一個類比,EventLoggingListener好比流式,不斷地追加寫,而 UIMetaLoggingListener類似于批式,定期將任務狀態快照下來,
UIMetaProvider
替換原先的FsHistoryProvider,主要區別在于:
將讀取 event log 檔案和回放生成KVStore的流程改為讀取UIMetaFile,反序列化出UIMetaStore,
去掉了FsHistoryProvider的路徑掃描邏輯;每次 UI 訪問,根據 appid 和路徑規則,直接去讀取 UIMetaFile 決議,這使得 UIService 無需預加載所有檔案元資訊,不需要隨著任務數量增加提高服務器配置,方便了水平擴展,
優化
避免重復寫
由于每個 stage 完成都會觸發寫 UIMeta 檔案,這樣對于 UIMeta 的很多元素,可能會出現重復持久化的情況,增加寫入耗時和檔案的大小,因此我們在UIMetaLoggingListener內部維護了一個 map,記錄已經被序列化的實體,在寫 UIMeta 檔案時進行過濾,只寫沒有寫過或者資料發生改變的元素,這樣可以杜絕大部分的寫冗余,
此外,開發期間發現,占用空間最大的是task級別資訊TaskDataWrapper,在一個 stage 完成觸發寫時,可能會將仍處于 RUNNING 狀態的 stage 的 task 序列化下來,這樣當 RUNNING 的 stage 完成時,task 資訊會再被寫一次,也會造成資料冗余,因此我們對序列化TaskDataWrapper資訊進行過濾,在 stage 結束時只持久化狀態是 Completed 的 task 資訊,
支持回退到 event log
鑒于 UIService 在初期有存在問題的風險,我們還支持了回退機制,即訪問一個任務的 UI,優先嘗試走 UIService 的路徑:決議 UIMeta 檔案,如果 UIMeta 檔案不存在或者決議報錯,會回退到讀 event log 檔案的路徑,避免 UI 訪問失敗,同時還支持將 event log 檔案轉換成 UIMeta 檔案,這樣下一次呼叫時就可以使用 UIService,這個功能保證我們遷移程序的平滑,
收益
存盤收益
線上測驗顯示存盤平均減少85%,總量減少92.4%,
下圖顯示了某機房 event log 和 UIMeta 存盤占用監控,可以看到 UIMeta 較 event log 在存盤量上有數量級的減少,目前位元組內部7天的 event log 占用存盤空間 3.2 PB,改用 UIMeta 后,空間占用只有350TB,
憑借 UIService 的存盤優勢,我們可以保留更長時間的日志資訊,有助于歷史分析,問題復盤,目前我們已從保留7天日志提高到了保留30天,并可以根據需求增大保留時間,
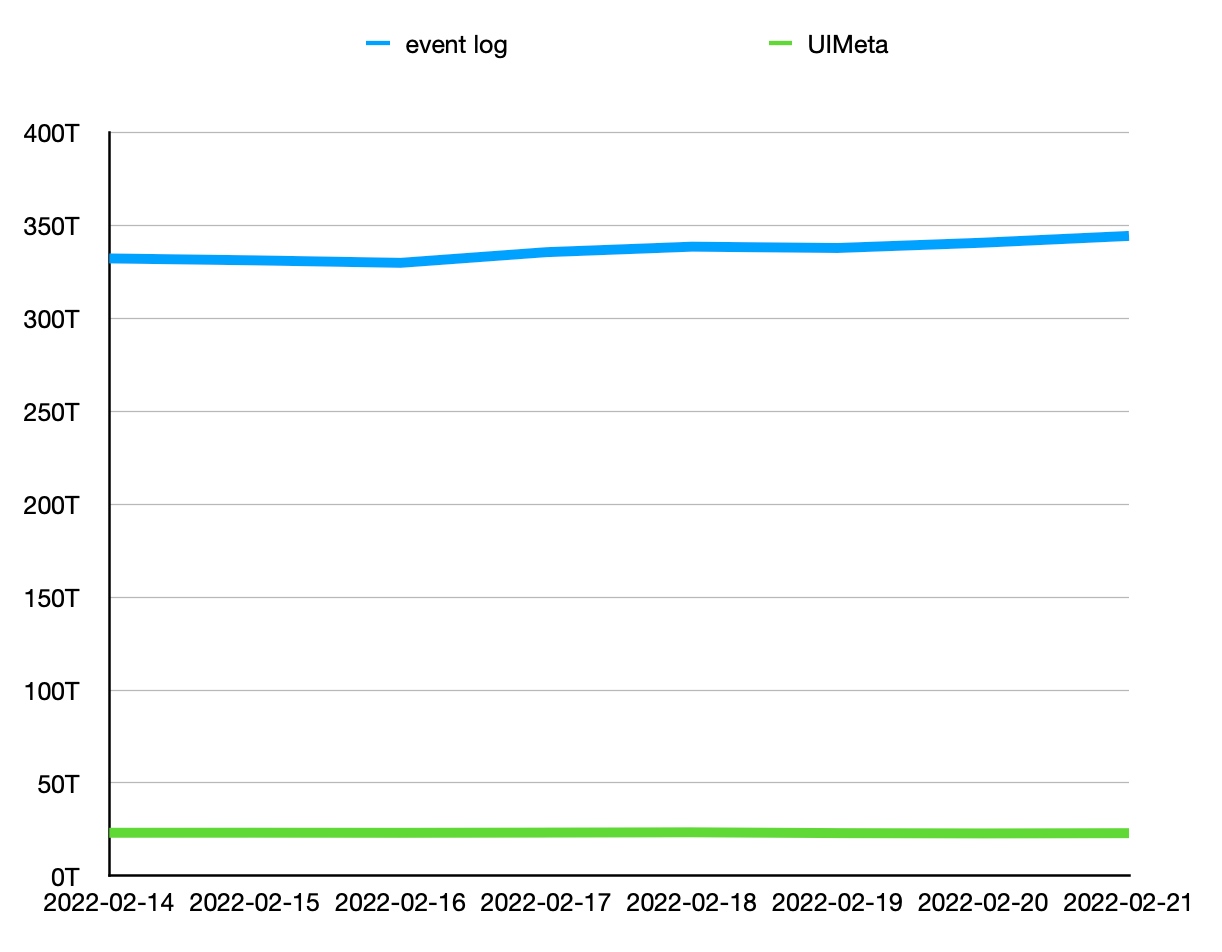
某機房 event log/UIMeta HDFS存盤監控對比
訪問延遲收益
訪問延遲:平均縮短 35%,PCT90/95/99 分別減少 84.6%/90.8%/93.7%
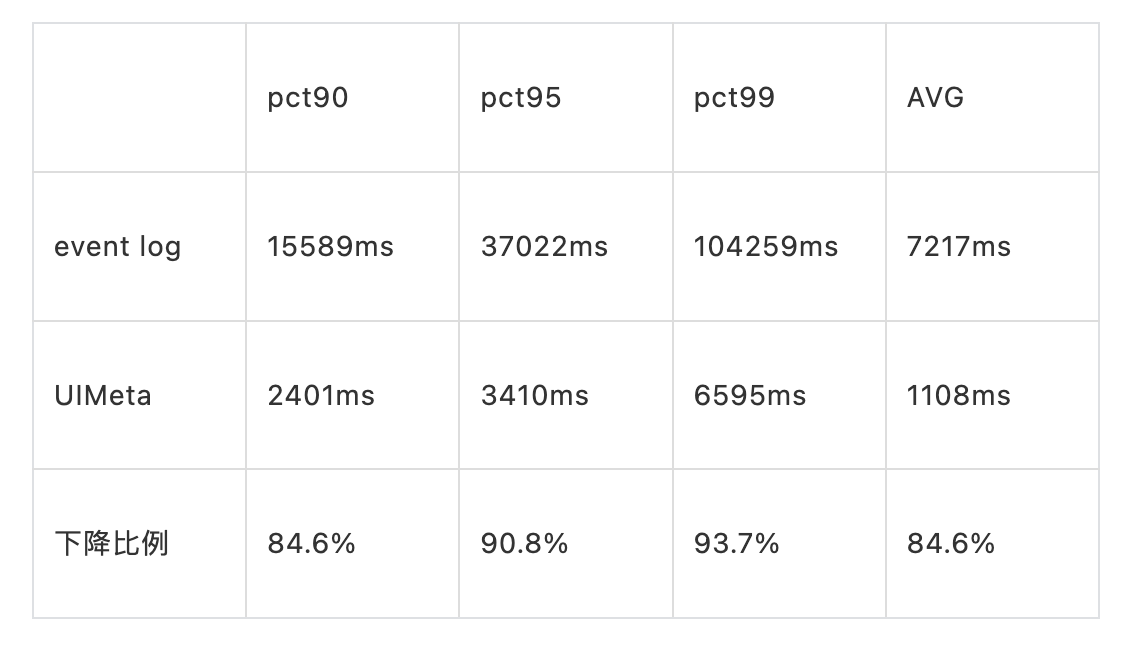
訪問延遲百分位分布
如下圖所示,UIService 的 UI 訪問延遲整體較比 event log 向左移,長尾任務明顯減少,
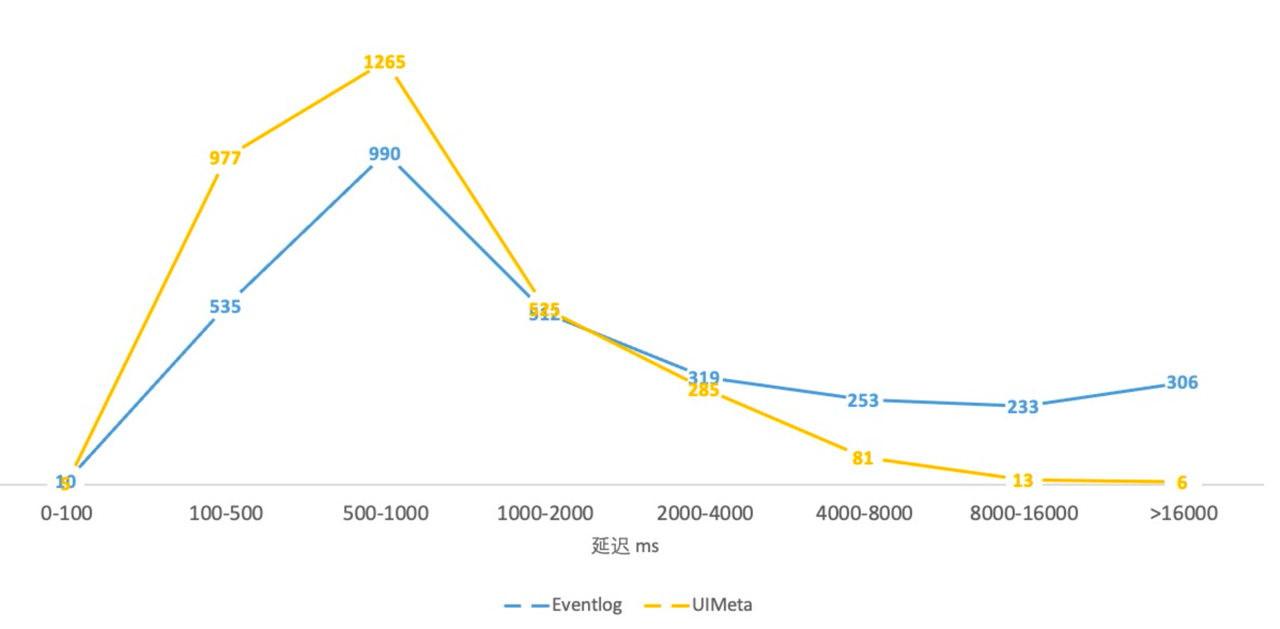
訪問延遲分布圖
架構收益
去掉了原生 History Server 遍歷路徑,預加載的耗時環節,消除從任務完成到 History Server 可訪問的時間間隔,從原本的平均 10min 左右降低到秒級,任務完成即可立即對外提供服務,同時使 History Server 可以水平擴展,能更好應對未來任務量增長帶來的挑戰,
目前,位元組跳動內部我們通過增加 UIService 實體就可以方便的進行橫向擴展,在火山引擎湖倉一體分析服務 LAS 中,我們也基于 UIService 實作了支持租戶訪問隔離,云原生的,可按需伸縮的 Spark History Server,
點擊了解火山引擎湖倉一體分析服務LAS
歡迎關注位元組跳動資料平臺同名公眾號
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/443492.html
標籤:大數據
上一篇:Impala的使用