我正在嘗試從設定如下圖的 API 中提取資料。我只是想提取日志資料。我將如何在 tExtractJsonFields 上進行映射。我一直在嘗試在主元素樹之外輸出非空白字符(在序言或結語中)錯誤
{<?xml version="1.0" encoding="UTF-8"?><root><status>success</status>
<data>
<story>
<ID>BL0492PE</ID>
<name>Atlas</name>
<type>assessment</type>
<app>
<ID>pioneer</ID>
<name>PS</name>
<version>2.9.7</version>
</app>
</story>
<logs>
<firstname>Jan</firstname>
<lastname>Doe</lastname>
<country>********</country>
<city>********</city>
<status>
<complete>true</complete>
<updated>2021-10-25T13:04:45 02:00</updated>
</status>
</logs>
<logs>
<firstname>Peter</firstname>
<lastname>Pan</lastname>
<country>********</country>
<city>********</city>
<status>
<complete>true</complete>
<updated>2021-10-25T13:04:45 02:00</updated>
</status>
</logs></data><hash>1fda</hash><response_time>0.22277402877807617</response_time></root>}
uj5u.com熱心網友回復:
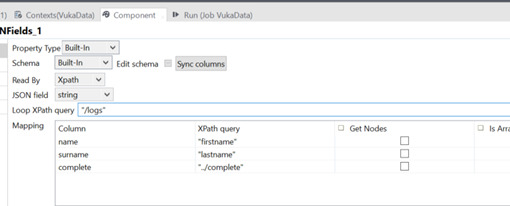
如果我參考您實際 XML 的螢屏截圖,您的“xpath 查詢”運算式似乎不正確。看來您已經反轉了 Column 和 XpathQuery。
此外,您不會使用此運算式訪問“完整”,您需要使用"./status/complete".
要直接訪問日志,請使用"//logs"或"/root/logs"。
uj5u.com熱心網友回復:
我還假設在 tExtractXMLField xml 欄位上選擇 Body 而不是字串。謝謝
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/447875.html
上一篇:讀取XMLCLOB列中的標簽