Hadoop版本:2.9.2
什么是機架感知
通常大型 Hadoop 集群是以機架的形式來組織的,同一個機架上的不同節點間的網路狀況比不同機架之間的更為理想,NameNode 設法將資料塊副本保存在不同的機架上以提高容錯性,
HDFS 不能夠自動判斷集群中各個 DataNode 的網路狀況情況,Hadoop 允許集群的管理員通過配置 net.topology.script.file.name 引數來確定節點所處的機架,組態檔提供了 ip 到 rackid 的翻譯,NameNode 通過這個配置知道集群中各個 DataNode 機器的 rackid,如果 net.topology.script.file.name 沒有設定,則每個 ip 都會被翻譯成 /default-rack,機器感知如下圖所示:
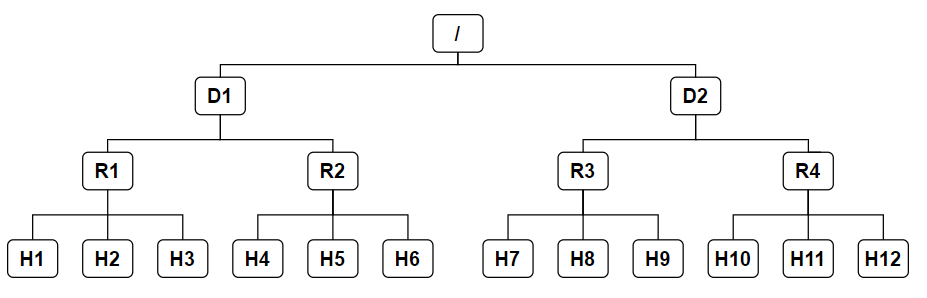
圖中的 D 和 R 是交換機,H 是 DataNode,則 H1 的 rackid = /D1/R1/H1,有了 rackid 資訊(這些 rackid 資訊可以通過 net.topology.script.file.name 配置)就可以計算出任意兩臺 DataNode 之間的距離,
- distance(/D1/R1/H1 , /D1/R1/H1) = 0 相同的 DataNode
- distance(/D1/R1/H1 , /D1/R1/H2) = 2 同 rack 下的不同 DataNode
- distance(/D1/R1/H1 , /D1/R2/H4) = 4 同 IDC 下的不同 DataNode
- distance(/D1/R1/H1 , /D2/R3/H7) = 6 不同 IDC 下的 DataNode
說明:
- 當沒有配置機架資訊時,所有的機器 Hadoop 都在同一個默認的機架下,名為 "/defult-rack",這種情況的任何一臺 DataNode 機器,bug物理上是否屬于同一個機架,都會被認為是在同一個機架下,
- 一旦配置 net.topology.script.file.name,就按照網路拓撲結構來尋找 DataNode:net.topology.script.file.name 這個配置選項的 value 指定為一個可執行程式,通常為一個腳本,
Hadoop機架感知的作用
不開啟機架感知的缺點
默認情況下,hadoop 的機架感知是沒有被啟用的,所以,在通常情況下,hadoop 集群的 HDFS 在選機器的時候,是隨機選擇的,
也就是說,如果實際節點不完全在相同的機架,但是又沒有配置機架感知很有可能在寫資料時:
hadoop 將第一塊資料 block1 寫到了 rack1 上,然后隨機的選擇下將 block2 寫入到了 rack2 下,此時兩個 rack 之間產生了資料傳輸的流量,再接下來,在隨機的情況下,又將 block3 重新又寫回了 rack1,此時,兩個 rack 之間又產生了一次資料流量,在 job 處理的資料量非常的大,或者往 hadoop 推送的資料量非常大的時候,這種情況會造成 rack 之間的網路流量成倍的上升,成為性能的瓶頸,進而影響作業的性能以至于整個集群的服務,
開啟機架感知的優勢
不同節點之間的通信能夠盡量發生在同一個機架之內,而不是跨機架;
為了提高容錯能力,DataNode 會盡可能把資料塊的副本放到多個機架上,
機架感知的配置
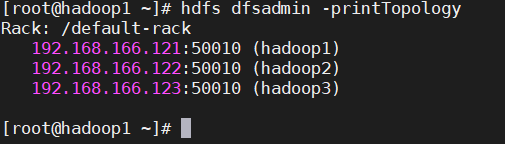
檢查當前集群機架配置情況
執行hdfs dfsadmin -printTopology列印當前機架資訊,可以看到默認所有節點都是一個機架 default-rack,此時沒有配置機架感知,
hdfs dfsadmin -printTopology
自定義機器機架位置
新建機架組態檔topology.data
vim $HADOOP_HOME/topology.data
由于官方組態檔沒有確切的說明到底是主機名還是 ip 地址會被傳入到腳本,所以在腳本中最好兼容主機名和 ip 地址,
192.168.166.121 hadoop1 /switch1/rack1
192.168.166.122 hadoop2 /switch1/rack1
192.168.166.123 hadoop3 /switch1/rack2
自定義機架感知腳本
在Hadoop的安裝目錄下新建腳本topology.sh
vim $HADOOP_HOME/topology.sh
撰寫腳本內容
#!/bin/bash
# 此處是你的機架組態檔topology.sh所在目錄
HADOOP_CONF=/opt/servers/hadoop
while [ $# -gt 0 ] ;
do
#腳本第一個引數節點ip或者主機名稱賦值給nodeArg
nodeArg=$1
#以只讀的方式打開機架組態檔
exec<${HADOOP_CONF}/topology.data
#宣告回傳值臨時變數
result=""
#開始逐行讀取
while read line
do
#賦值行內容給ar,通過這種 變數=( 值 )的方式賦值,下面可以通過陣列的方式取出每個詞
ar=( $line )
#判斷輸入的主機名或者ip是否和該行匹配
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]
then
#將機架資訊賦值給result
result="${ar[2]}"
fi
done
shift
#-z判斷字串長度是否為0,不為0輸出實際機架,為0回傳默認機架資訊
if [ -z "$result" ]
then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
配置core-site.xml檔案機架感知
腳本必須添加可執行權限
chmod 777 topology.sh
修改 core-site.xml 檔案,
<!-- 配置機架感知配置腳本 -->
<property>
<name>net.topology.script.file.name</name>
<!-- 注意這里是你腳本的實際位置 -->
<value>/opt/servers/hadoop/topology.sh</value>
</property>
分發組態檔和腳本
rsync-script etc/hadoop/core-site.xml
rsync-script topology.*
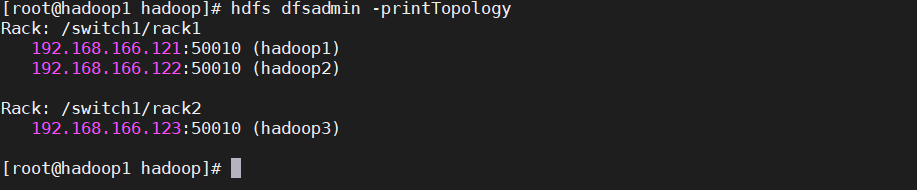
驗證機架感知配置
重啟集群,執行 hdfs dfsadmin -printTopology 列印機架資訊,可以看到集群已經按照配置感應到節點機架位置,
hdfs dfsadmin -printTopology
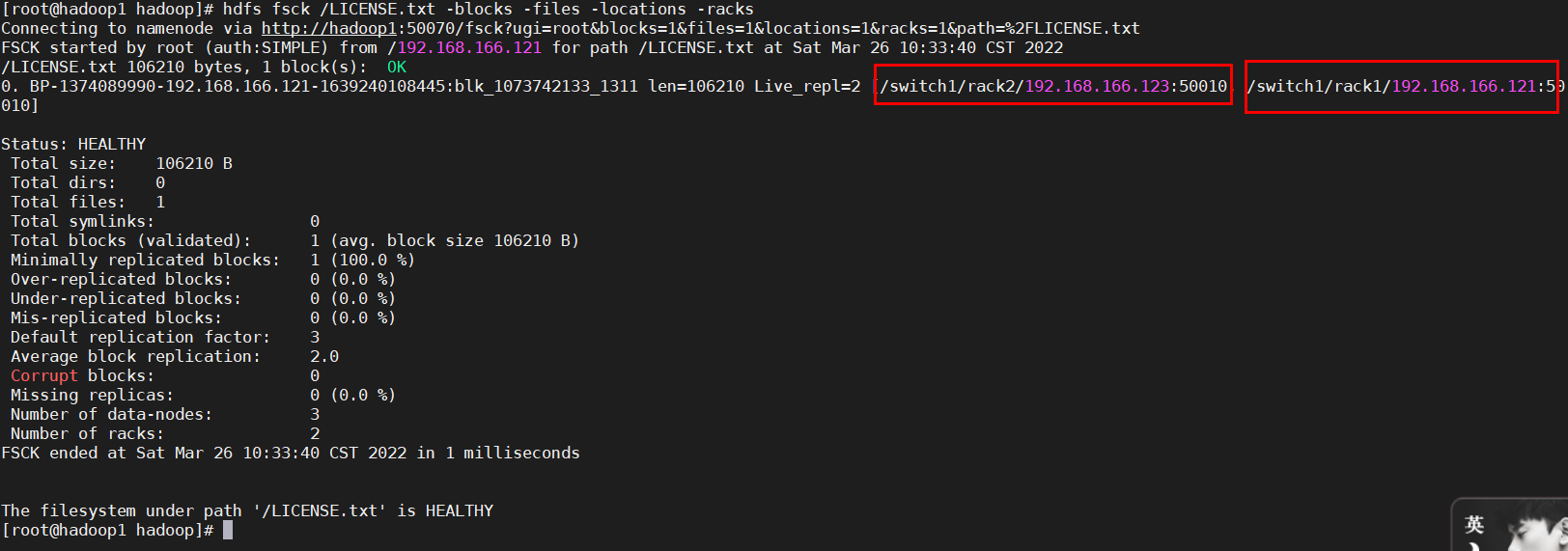
測驗上傳檔案,因為只搭建了三個節點,因此設定副本數為2,查看兩個副本是否存在不同的機架rack1和rack2上的節點,
在 hadoop2.8 版本之前的版本上述的結論可能不同,主要跟 Hadoop 的副本策略有關,詳細的副本策略請看 https://weixiaodyanlei.xyz/archives/hdfs-fu-ben-ji-zhi
hdfs dfs -D dfs.replication=2 -put LICENSE.txt /
可以通過如下命令查看 HDFS 中的檔案所在機架
hdfs fsck /LICENSE.txt -blocks -files -locations -racks
參考博客:https://blog.csdn.net/qq_31454379/article/details/105497503
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/449802.html
標籤:大數據