我的小個人實用工具是為了好玩而構建的。我有一個串列框,其中標題和新聞時間是從 2 個鏈接中抓取的,并在單擊“查看標題”按鈕后列印在串列框中。這可以正常作業。一切都好!
現在我想從串列框中選擇報紙標題,單擊“查看內容”按鈕,并在多行文本框中查看新聞內容。所以我想在下面的文本框中查看所選標題的新聞內容。我指定標題與新聞內容的鏈接相同。但是我對構建它的功能有疑問:
def content():
if title.select:
#click on title-link
driver.find_element_by_tag_name("title").click()
#Download Content to class for every title
content_download =(" ".join([span.text for span in div.select("text mbottom")]))
#Print Content in textobox
textbox_download.insert(tk.END, content_download)
So I imagined that to get this, we would have to simulate clicking on the title of the news to open it (in html it is title), then select the text of the content (in html it is text mbottom) and then copy it in the tetbox of my file. It should be so? What are you saying? Obviously I have poorly written the code and it doesn't work. I'm not very good at scraping. Could anyone help me? Thank you
The complete code is this (is executable correctly and scrapes titles and now. I don't call the content function in the button). Aside from the above function, the code is working good and fetches the title and news time
from tkinter import *
from tkinter import ttk
import tkinter as tk
import sqlite3
import random
import tkinter.font as tkFont
from tkinter import ttk
window=Tk()
window.title("x")
window.geometry("800x800")
textbox_title = tk.Listbox(window, width=80, height=16, font=('helvetic', 12), selectbackground="#960000", selectforeground="white", bg="white") #prima era self.tutti_pronostici, per far visualizzare le chiamate dall'altra finestra
textbox_title.place(x=1, y=1)
textbox_download = tk.Listbox(window, width=80, height=15, font=('helvetic', 12), selectbackground="#960000", selectforeground="white", bg="white") #prima era self.tutti_pronostici, per far visualizzare le chiamate dall'altra finestra
textbox_download.place(x=1, y=340)
#Download All Titles and Time
def all_titles():
allnews = []
import requests
from bs4 import BeautifulSoup
# mock browser request
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
#ATALANTA
site_atalanta = requests.get('https://www.tuttomercatoweb.com/atalanta/', headers=headers)
soup = BeautifulSoup(site_atalanta.content, 'html.parser')
news = soup.find_all('div', attrs={"class": "tcc-list-news"})
for each in news:
for div in each.find_all("div"):
time= (div.find('span', attrs={'class': 'hh serif'}).text)
title=(" ".join([span.text for span in div.select("a > span")]))
news = (f" {time} {'ATALANTA'}, {title} (TMW)")
allnews.append(news)
#BOLOGNA
site_bologna = requests.get('https://www.tuttomercatoweb.com/bologna/', headers=headers)
soup = BeautifulSoup(site_bologna.content, 'html.parser')
news = soup.find_all('div', attrs={"class": "tcc-list-news"})
for each in news:
for div in each.find_all("div"):
time= (div.find('span', attrs={'class': 'hh serif'}).text)
title=(" ".join([span.text for span in div.select("a > span")]))
news = (f" {time} {'BOLOGNA'}, {title} (TMW)")
allnews.append(news)
allnews.sort(reverse=True)
for news in allnews:
textbox_title.insert(tk.END, news)
#Download Content of News
def content():
if titolo.select:
#click on title-link
driver.find_element_by_tag_name("title").click()
#Download Content to class for every title
content_download =(" ".join([span.text for span in div.select("text mbottom")]))
#Print Content in textobox
textbox_download.insert(tk.END, content_download)
button = tk.Button(window, text="View Titles", command= lambda: [all_titles()])
button.place(x=1, y=680)
button2 = tk.Button(window, text="View Content", command= lambda: [content()])
button2.place(x=150, y=680)
window.mainloop()
uj5u.com熱心網友回復:
當你得到title,time然后你可以直接進入link詳細資訊頁面 - 并將它們保持成對。
news = f" {time} '{place}', {title} (TMW)"
link = div.find('a')['href']
results.append( [news, link] )
稍后您只能顯示news,但是當您選擇標題時,您可以獲取索引并從中獲取link并allnews直接下載它-requests改為使用driver
def content():
# tuple with indexes of all selected titles
selection = listbox_title.curselection()
print('selection:', selection)
if selection:
item = allnews[selection[-1]]
print('item:', item)
url = item[1]
print('url:', url)
要選擇完整的新聞,您必須使用select(".text.mbottom")點。
為了顯示新聞,最好Text()改用Listbox()
因為你運行相同的代碼ATALANTA,BOLOGNA所以我將這段代碼移動到函式中get_data_for(place),現在我什至可以使用for-loop 在更多地方運行它。
for place in ['atalanta', 'bologna']:
results = get_data_for(place)
allnews = results
完整的作業代碼 (1) - 我試圖只保留重要的元素。
我使用pack()而不是place()因為它允許調整視窗大小并且它也會調整大小Listbox()并且Text()
import tkinter as tk # PEP8: `import *` is not preferred
from tkinter import ttk
import requests
from bs4 import BeautifulSoup
# PEP8: all imports at the beginning
# --- functions --- # PEP8: all functions directly after imports
def get_data_for(place):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
results = []
response = requests.get(f'https://www.tuttomercatoweb.com/{place}/', headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news = soup.find_all('div', attrs={"class": "tcc-list-news"})
for each in news:
for div in each.find_all("div"):
time = div.find('span', attrs={'class': 'hh serif'}).text
title = " ".join(span.text for span in div.select("a > span"))
news = f" {time} {place.upper()}, {title} (TMW)"
link = div.find('a')['href']
results.append( [news, link] )
return results
def all_titles():
global allnews # inform function to use global variable instead of local variable
allnews = []
for place in ['atalanta', 'bologna']:
print('search:', place)
results = get_data_for(place)
print('found:', len(results))
allnews = results
allnews.sort(reverse=True)
listbox_title.delete('0', 'end')
for news in allnews:
listbox_title.insert('end', news[0])
#Download Content of News
def content():
# tuple
selection = listbox_title.curselection()
print('selection:', selection)
if selection:
item = allnews[selection[-1]]
print('item:', item)
url = item[1]
print('url:', url)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
content_download = "\n".join(item.get_text() for item in soup.select("div.text.mbottom"))
text_download.delete('1.0', 'end') # remove previous content)
text_download.insert('end', content_download)
# --- main ---
allnews = [] # global variable with default value at start
window = tk.Tk()
window.geometry("800x800")
listbox_title = tk.Listbox(window, selectbackground="#960000", selectforeground="white", bg="white")
listbox_title.pack(fill='both', expand=True, pady=5, padx=5)
text_download = tk.Text(window, bg="white")
text_download.pack(fill='both', expand=True, pady=0, padx=5)
buttons_frame = tk.Frame(window)
buttons_frame.pack(fill='x')
button1 = tk.Button(buttons_frame, text="View Titles", command=all_titles) # don't use `[]` to execute functions
button1.pack(side='left', pady=5, padx=5)
button2 = tk.Button(buttons_frame, text="View Content", command=content) # don't use `[]` to execute functions
button2.pack(side='left', pady=5, padx=(0,5))
window.mainloop()
結果:
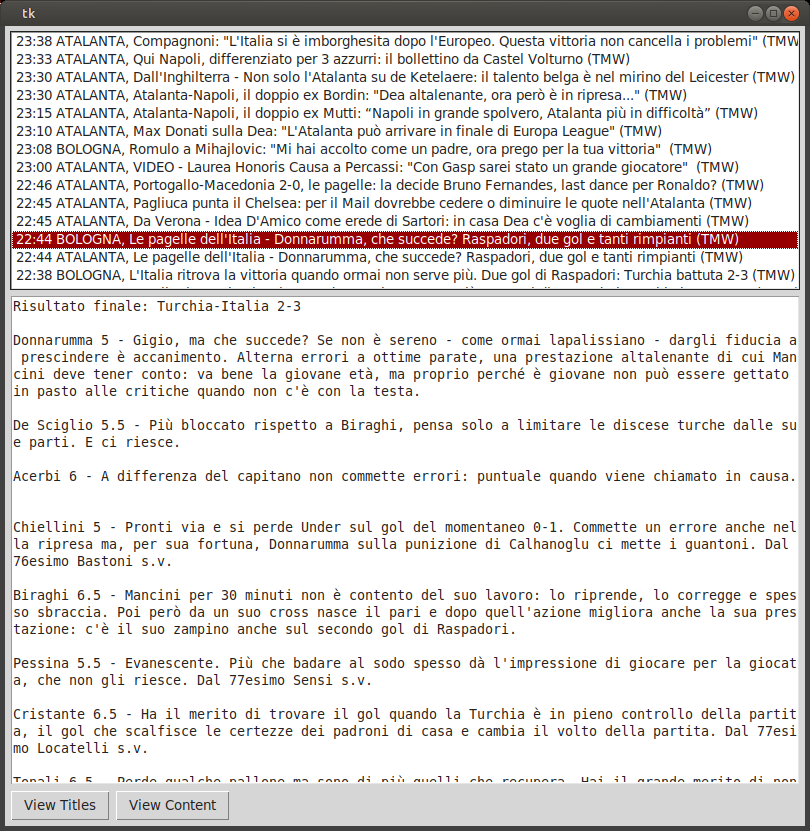
編輯:
排序問題:今天的標題在串列的末尾,但它們應該在開頭 - 所有這些都是因為它們僅使用排序,time但需要使用date timeor排序number time。
You would enumerate every tcc-list-news and then every day would have own number and they would sort (almost) correctly. because you want to sort in reverse order then you may need -number instead of number to get correct order.
for number, each in enumerate(news):
for div in each.find_all("div"):
time = div.find('span', attrs={'class': 'hh serif'}).text
title = " ".join(span.text for span in div.select("a > span"))
news = f" {time} {place.upper()}, {title} (TMW)"
link = div.find('a')['href']
results.append( [-number, news, link] )
and after sorting
for number, news, url in allnews:
listbox_title.insert('end', news)
Full working code (2)
import tkinter as tk # PEP8: `import *` is not preferred
from tkinter import ttk
import requests
from bs4 import BeautifulSoup
# PEP8: all imports at the beginning
# --- functions --- # PEP8: all functions directly after imports
def get_data_for(place):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
results = []
response = requests.get(f'https://www.tuttomercatoweb.com/{place}/', headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news = soup.find_all('div', attrs={"class": "tcc-list-news"})
for number, each in enumerate(news):
for div in each.find_all("div"):
time = div.find('span', attrs={'class': 'hh serif'}).text
title = " ".join(span.text for span in div.select("a > span"))
news = f" {time} {place.upper()}, {title} (TMW)"
link = div.find('a')['href']
results.append( [-number, news, link] )
return results
def all_titles():
global allnews # inform function to use global variable instead of local variable
allnews = []
for place in ['atalanta', 'bologna']:
print('search:', place)
results = get_data_for(place)
print('found:', len(results))
allnews = results
allnews.sort(reverse=True)
listbox_title.delete('0', 'end')
for number, news, url in allnews:
listbox_title.insert('end', news)
#Download Content of News
def content():
# tuple
selection = listbox_title.curselection()
print('selection:', selection)
if selection:
item = allnews[selection[-1]]
print('item:', item)
url = item[2]
print('url:', url)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
content_download = "\n".join(item.get_text() for item in soup.select("div.text.mbottom"))
text_download.delete('1.0', 'end') # remove previous content)
text_download.insert('end', content_download)
# --- main ---
allnews = [] # global variable with default value at start
window = tk.Tk()
window.geometry("800x800")
listbox_title = tk.Listbox(window, selectbackground="#960000", selectforeground="white", bg="white")
listbox_title.pack(fill='both', expand=True, pady=5, padx=5)
text_download = tk.Text(window, bg="white")
text_download.pack(fill='both', expand=True, pady=0, padx=5)
buttons_frame = tk.Frame(window)
buttons_frame.pack(fill='x')
button1 = tk.Button(buttons_frame, text="View Titles", command=all_titles) # don't use `[]` to execute functions
button1.pack(side='left', pady=5, padx=5)
button2 = tk.Button(buttons_frame, text="View Content", command=content) # don't use `[]` to execute functions
button2.pack(side='left', pady=5, padx=(0,5))
window.mainloop()
BTW
Because you sort in reverse order so you get 00:30 bologna before 00:30 atalanta - to get 00:30 atalanta before 00:30 bologna you would have to keep time, place as separated values and use key= in sort() to assign function which would reverse only time but not place and number. Maybe it would be simpler to put all in pandas.DataFrame which has better methot to sort it.
Version with pandas.DataFrame and 
Full working code (4)
import tkinter as tk # PEP8: `import *` is not preferred
from tkinter import ttk
from tkinter.scrolledtext import ScrolledText # https://docs.python.org/3/library/tkinter.scrolledtext.html
import requests
import requests_cache # https://github.com/reclosedev/requests-cache
from bs4 import BeautifulSoup
import pandas as pd
# PEP8: all imports at the beginning
# --- functions --- # PEP8: all functions directly after imports
def get_data_for(place):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
results = []
response = requests.get(f'https://www.tuttomercatoweb.com/{place}/', headers=headers)
print('url:', response.url)
print('status:', response.status_code)
#print('html:', response.text[:1000])
soup = BeautifulSoup(response.content, 'html.parser')
news = soup.find_all('div', attrs={"class": "tcc-list-news"})
for number, each in enumerate(news):
for div in each.find_all("div"):
time = div.find('span', attrs={'class': 'hh serif'}).text
title = " ".join(span.text for span in div.select("a > span"))
news = f" {time} {place.upper()}, {title} (TMW)"
link = div.find('a')['href']
results.append( [number, time, place, title, news, link] )
return results
def all_titles():
global df
allnews = [] # local variable
for place in ['atalanta', 'bologna']:
print('search:', place)
results = get_data_for(place)
print('found:', len(results))
allnews = results
text_download.insert('end', f"search: {place}\nfound: {len(results)}\n")
df = pd.DataFrame(allnews, columns=['number', 'time', 'place', 'title', 'news', 'link'])
df = df.sort_values(by=['number', 'time', 'place', 'title'], ascending=[True, False, True, True])
df = df.reset_index()
listbox_title.delete('0', 'end')
for index, row in df.iterrows():
listbox_title.insert('end', row['news'])
def content(event=None): # `command=` executes without `event`, but `bind` executes with `event` - so it needs default value
# tuple
selection = listbox_title.curselection()
print('selection:', selection)
if selection:
item = df.iloc[selection[-1]]
#print('item:', item)
url = item['link']
#print('url:', url)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'
}
# keep page in database `SQLite`
# https://github.com/reclosedev/requests-cache
# https://sqlite.org/index.html
session = requests_cache.CachedSession('titles')
response = session.get(url, headers=headers)
#response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
content_download = "\n".join(item.get_text() for item in soup.select("div.text.mbottom"))
text_download.delete('1.0', 'end') # remove previous content)
text_download.insert('end', content_download)
# --- main ---
df = None
window = tk.Tk()
window.geometry("800x800")
# ---
# [Tkinter: How to display Listbox with Scrollbar — furas.pl](https://blog.furas.pl/python-tkitner-how-to-display-listbox-with-scrollbar-gb.html)
frame_title = tk.Frame(window)
frame_title.pack(fill='both', expand=True, pady=5, padx=5)
listbox_title = tk.Listbox(frame_title, selectbackground="#960000", selectforeground="white", bg="white")
listbox_title.pack(side='left', fill='both', expand=True)
scrollbar_title = tk.Scrollbar(frame_title)
scrollbar_title.pack(side='left', fill='y')
scrollbar_title['command'] = listbox_title.yview
listbox_title.config(yscrollcommand=scrollbar_title.set)
listbox_title.bind('<Double-Button-1>', content) # it executes `content(event)`
# ----
text_download = ScrolledText(window, bg="white")
text_download.pack(fill='both', expand=True, pady=0, padx=5)
# ----
buttons_frame = tk.Frame(window)
buttons_frame.pack(fill='x')
button1 = tk.Button(buttons_frame, text="View Titles", command=all_titles) # don't use `[]` to execute functions
button1.pack(side='left', pady=5, padx=5)
button2 = tk.Button(buttons_frame, text="View Content", command=content) # don't use `[]` to execute functions
button2.pack(side='left', pady=5, padx=(0,5))
window.mainloop()
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/453395.html
標籤:python python-3.x selenium web-scraping beautifulsoup