我正在嘗試使用 ggarrange 函式將兩個圖組合在一起。因此,我有以下代碼:
ZINB_estimates_2 <- (list(m1 = best.mod.1, m2 = best.mod.2, m3 = best.mod.3,
m4 = best.mod.4)
%>% purrr::map_dfr(tidy, effects = "fixed", conf.int = TRUE,
.id = "model")
%>% select(model, component, term, estimate, conf.low, conf.high)
## drop conditional intercept term (not interesting)
%>% filter(!(term == "(Intercept)"))
## create new 'term' that combines component and term
%>% mutate(term_orig = term,
term = forcats::fct_inorder(paste(term, component, sep = "_")))
%>% relabel_predictors(
c("Reports_month_prior" = "Previous number of reports",
"Year_numeric" = "Year",
"factor(Coy_Season)2" = "Season: Pup-rearing",
"factor(Coy_Season)3" = "Season: Dispersal",
"Number_4w_AC" = "Previous number of AC")))
model_names <- list(
'zi' = "Probability of observing a week
with no coyote reports",
'cond' = "Abundance of coyote reports per week"
)
model_labeller <- function(variable, value){
return(model_names[value])
}
ZINB_estimates_2$component_2 = factor(ZINB_estimates_2$component, levels = c('zi', 'cond'))
ZINB_estimates_2$term_orig_2 = factor(ZINB_estimates_2$term_orig, levels = c('factor(Coy_Season)3',
'factor(Coy_Season)2',
'Year_numeric',
'Number_4w_AC',
'Reports_month_prior'))
p1_2 <- ggplot(ZINB_estimates_2 %>% filter(component_2 == "zi"),
aes(x = estimate, xmin = conf.low, xmax = conf.high, y = term_orig_2))
geom_pointrange(shape = 15, aes(colour = model),
position = position_dodge(width = 0.40))
facet_wrap(~component_2, labeller = model_labeller, scale = "free_x", ncol=2)
theme_minimal()
coord_capped_cart(bottom='right')
theme(strip.text.x = element_text(size = 12, face = "bold"),
panel.spacing = unit(0, "lines"), legend.position = "none",
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.border=element_blank(),
axis.line.x = element_line(colour = "grey40", linetype = "solid"),
axis.ticks.x = element_line(colour = "grey40", linetype = "solid"),
plot.margin = unit(c(0, -0.1, 0, 0), "cm"))
xlab("Coefficient estimate") ylab("")
geom_vline(xintercept = 0,
colour = "grey80",
linetype = 1)
annotate("rect", ymin = -Inf, ymax = 1.5,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
annotate("rect", ymin = 2.5, ymax = 3.5,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
annotate("rect", ymin = 4.5, ymax = Inf,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
scale_color_lancet()
scale_y_discrete(labels= c("Year",
"Previous number of AC", "Previous number of reports"))
p2_2 <- ggplot(ZINB_estimates_2 %>% filter(component_2 == "cond"),
aes(x = estimate, xmin = conf.low, xmax = conf.high, y = term_orig_2))
geom_pointrange(shape = 15, aes(colour = model),
position = position_dodge(width = 0.40))
facet_wrap(~component_2, labeller = model_labeller, scale = "free_x", ncol=2)
coord_capped_cart(bottom='right')
theme_minimal()
theme(strip.text.x = element_text(size = 12, face = "bold"),
panel.spacing = unit(0, "lines"), legend.position = "none",
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.border=element_blank(),
axis.line.x = element_line(colour = "grey40", linetype = "solid"),
axis.ticks.x = element_line(colour = "grey40", linetype = "solid"),
plot.margin = unit(c(0, 0, 0, 0), "cm"))
xlab("Coefficient estimate") ylab("")
geom_vline(xintercept = 0,
colour = "grey80",
linetype = 1)
annotate("rect", ymin = -Inf, ymax = 1.5,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
annotate("rect", ymin = 2.5, ymax = 3.5,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
annotate("rect", ymin = 4.5, ymax = Inf,
xmin = -Inf, xmax = Inf, fill = 'grey80', alpha = 0.3)
scale_color_lancet()
scale_y_discrete(labels= c("Season: Dispersal", "Season: Pup-rearing", "Year",
"Previous number of AC", "Previous number of reports"))
library(egg)
ggarrange(p1_2, p2_2
theme(axis.text.y = element_blank(),
axis.line.y = element_blank(),
axis.title.y= element_blank(),
axis.ticks.y= element_blank(),
panel.spacing = unit(0, "lines")),
nrow = 1)
結果如下圖。
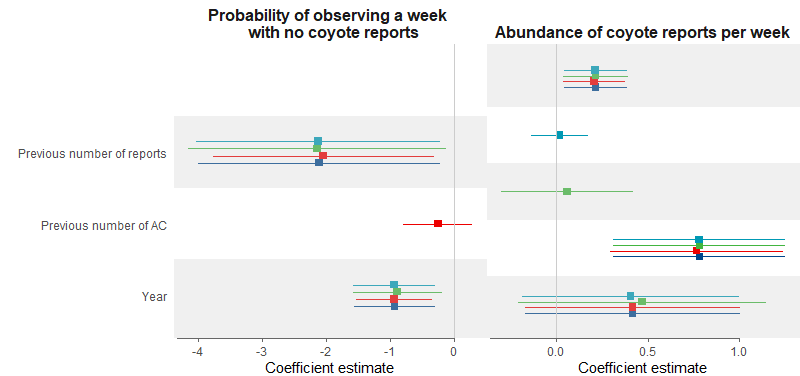
但是,因為我的兩個圖表之間的變數數量不同,所以我的變數不在 y 軸上對齊。我嘗試使用我的第二個圖表的 y 軸,但它仍然不能正常作業。我理想的情節看起來像這樣(用 PowerPoint 制作),y 軸在各個情節中是相同的:
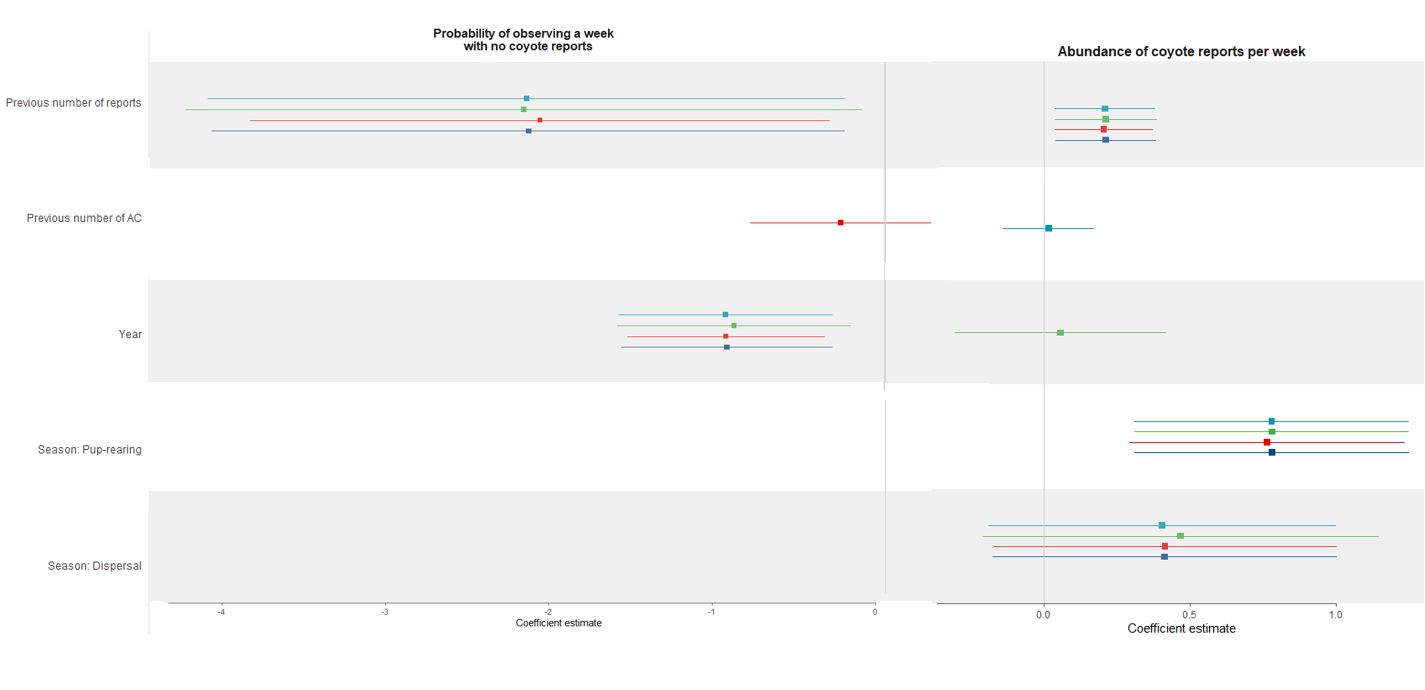
理想情況下,我正在尋找使用 ggplot2/ggarrange 的解決方案,但我對替代方案持開放態度。
uj5u.com熱心網友回復:
實作所需結果的一種方法是在每個圖中固定 y 比例的限制,即對每個圖執行limits_y <- unique(ZINB_estimates_2$term_orig_2)并使用這些限制scale_y_discrete。
注意:由于您沒有提供資料,我使用了一些假的隨機示例資料。此外,我利用繪圖功能使代碼更精簡并減少重復代碼。
library(ggplot2)
library(magrittr)
library(egg)
#> Loading required package: gridExtra
limits_y <- unique(ZINB_estimates_2$term_orig_2)
p <- ZINB_estimates_2 %>%
split(.$component_2) %>%
lapply(plot_fun)
ggarrange(p[[2]], p[[1]]
theme(axis.text.y = element_blank(),
axis.line.y = element_blank(),
axis.title.y= element_blank(),
axis.ticks.y= element_blank(),
panel.spacing = unit(0, "lines")),
nrow = 1)
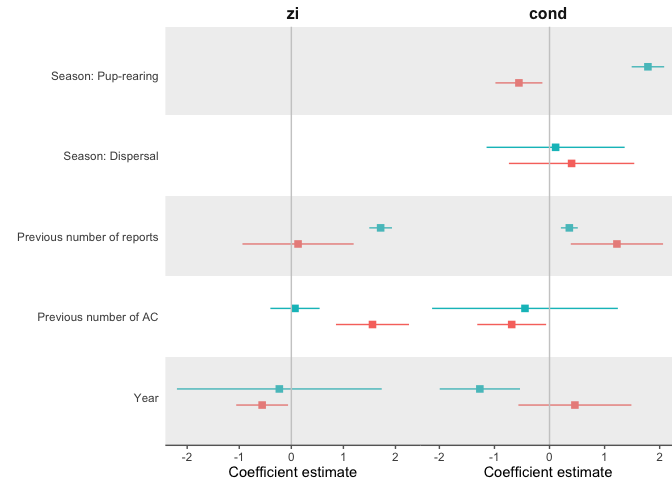
繪圖功能
plot_fun <- function(x) {
ggplot(x, aes(x = estimate, xmin = conf.low, xmax = conf.high, y = term_orig_2))
geom_pointrange(
shape = 15, aes(colour = model),
position = position_dodge(width = 0.40)
)
facet_wrap(~component_2, scale = "free_x", ncol = 2)
theme_minimal()
theme(
strip.text.x = element_text(size = 12, face = "bold"),
panel.spacing = unit(0, "lines"), legend.position = "none",
panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.border = element_blank(),
axis.line.x = element_line(colour = "grey40", linetype = "solid"),
axis.ticks.x = element_line(colour = "grey40", linetype = "solid"),
plot.margin = unit(c(0, -0.1, 0, 0), "cm")
)
xlab("Coefficient estimate")
ylab("")
geom_vline(
xintercept = 0,
colour = "grey80",
linetype = 1
)
annotate("rect",
ymin = -Inf, ymax = 1.5,
xmin = -Inf, xmax = Inf, fill = "grey80", alpha = 0.3
)
annotate("rect",
ymin = 2.5, ymax = 3.5,
xmin = -Inf, xmax = Inf, fill = "grey80", alpha = 0.3
)
annotate("rect",
ymin = 4.5, ymax = Inf,
xmin = -Inf, xmax = Inf, fill = "grey80", alpha = 0.3
)
scale_y_discrete(labels = c(
A = "Year", B = "Previous number of AC", C = "Previous number of reports",
D = "Season: Dispersal", E = "Season: Pup-rearing"
), limits = limits_y)
}
資料
set.seed(123)
ZINB_estimates_2 <- data.frame(
term_orig_2 = c(rep(LETTERS[1:3], each = 2), rep(LETTERS[1:5], each = 2)),
model = letters[1:2],
component_2 = c(rep("zi", 6), rep("cond", 10)),
estimate = rnorm(16)
)
ci <- rnorm(16)
ZINB_estimates_2$conf.low <- ZINB_estimates_2$estimate - ci
ZINB_estimates_2$conf.high <- ZINB_estimates_2$estimate ci
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/453818.html
上一篇:如何讓ggrepel在美國地圖邊界之外移動(某些)標簽?
下一篇:通過邊界框或多邊形子集空間特征