目錄
- 一、概述
- 1)Hadoop發行版本
- 1、Apache Hadoop發行版
- 2、DKhadoop發行版
- 3、Cloudera發行版
- 4、Hortonworks發行版
- 5、華為hadoop發行版
- 2)Hadoop1.x -》 Hadoop2.x的演變
- 3)Hadoop2.x與Hadoop3.x區別對比
- 1)Hadoop發行版本
- 二、Hadoop的發展簡史
- 三、Hadoop生態系統
一、概述
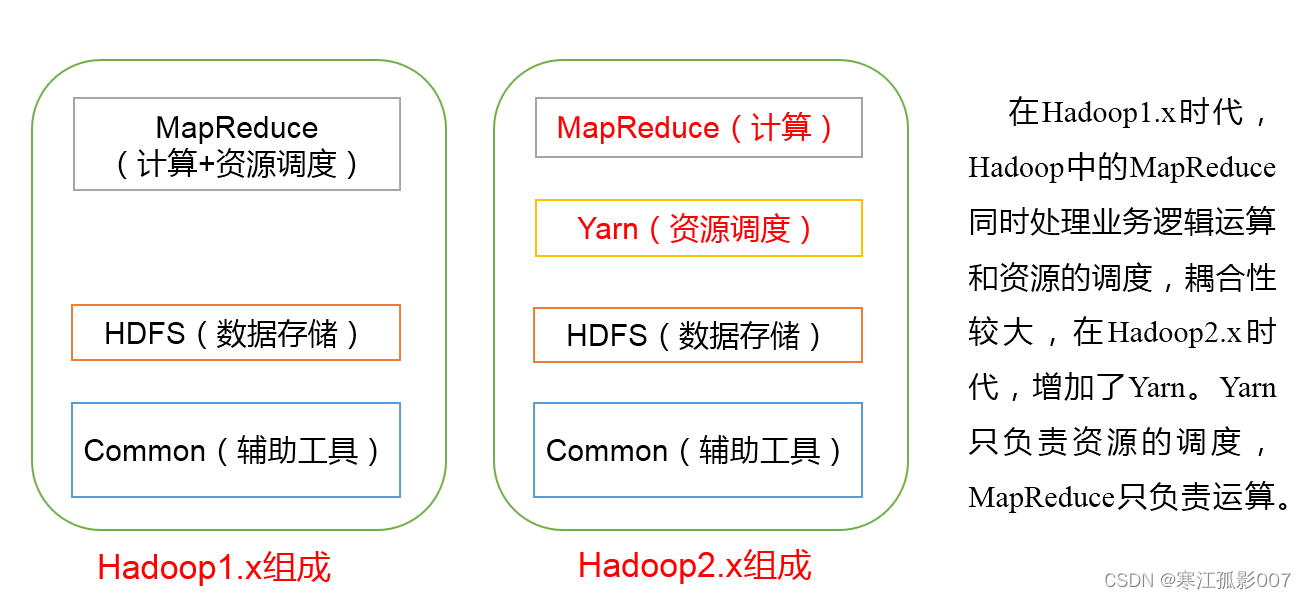
Hadoop是Apache軟體基金會下一個開源分布式計算平臺,以hdfs(Hadoop Distributed File System)、MapReduce(Hadoop2.0加入了YARN,Yarn是資源調度框架,能夠細粒度的管理和調度任務,還能夠支持其他的計算框架,比如spark)為核心的Hadoop為用戶提供了系統底層細節透明的分布式基礎架構,hdfs的高容錯性、高伸縮性、高效性等優點讓用戶可以將Hadoop部署在低廉的硬體上,形成分布式系統,目前最新版本已經是3.x了,官方檔案
1)Hadoop發行版本
1、Apache Hadoop發行版
官方地址:https://hadoop.apache.org
Apache版本最原始(最基礎)的版本,對于入門學習最好,
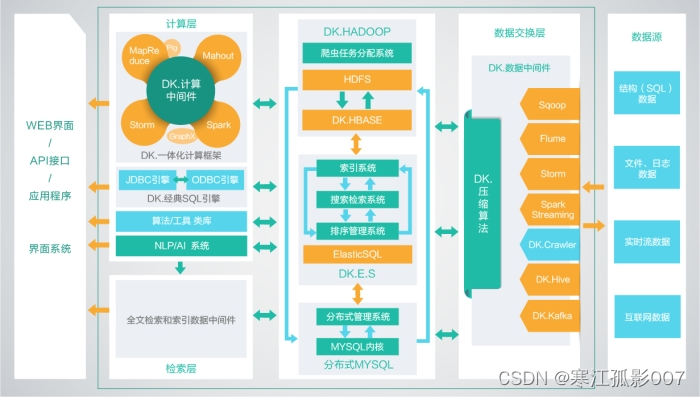
2、DKhadoop發行版
Github地址:https://github.com/dkhadoop/dk-fitting
有效的集成了整個HADOOP生態系統的全部組件,并深度優化,重新編譯為一個完整的更高性能的大資料通用計算平臺,實作了各部件的有機協調,因此DKH相比開源的大資料平臺,在計算性能上有了高達5倍(最大)的性能提升,DKhadoop將復雜的大資料集群配置簡化至三種節點(主節點、管理節點、計算節點),極大的簡化了集群的管理運維,增強了集群的高可用性、高可維護性、高穩定性,
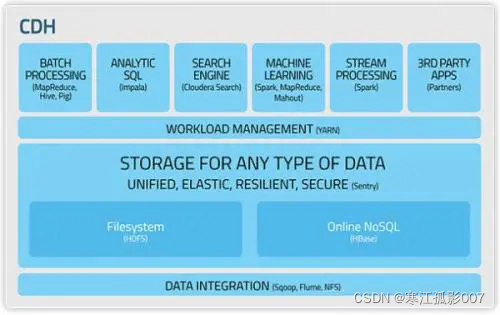
3、Cloudera發行版
官方地址:https://www.cloudera.com/products/open-source/apache-hadoop.html
CDH是Cloudera的hadoop發行版,完全開源,比Apache hadoop在兼容性,安全性,穩定性上有增強,
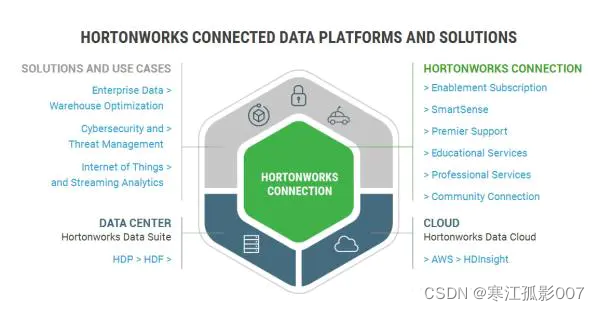
4、Hortonworks發行版
官方地址:https://www.cloudera.com/products/hdp.html
Hortonworks 的主打產品是Hortonworks Data Platform (HDP),也同樣是100%開源的產品,其版本特點:HDP包括穩定版本的Apache Hadoop的所有關鍵組件;安裝方便,HDP包括一個現代化的,直觀的用戶界面的安裝和配置工具,
5、華為hadoop發行版
華為FusionInsight大資料平臺是集Hadoop生態發行版、大規模并行處理資料庫、大資料云服務于一體的融合資料處理與服務平臺,擁有端到端全生命周期的解決方案能力,除了提供包括批處理、記憶體計算、流計算和MPPDB在內的全方位資料處理能力外,還提供資料分析挖掘平臺、資料服務平臺,幫助用戶實作從資料到知識,從知識到智慧的轉換,進而幫助用戶從海量資料中挖掘資料價值,
2)Hadoop1.x -》 Hadoop2.x的演變
3)Hadoop2.x與Hadoop3.x區別對比
License
- Hadoop 2.x - Apache 2.0,開源
- Hadoop 3.x - Apache 2.0,開源
支持的最低Java版本
- Hadoop 2.x - java的最低支持版本是java 7
- Hadoop 3.x - java的最低支持版本是java 8
容錯
- Hadoop 2.x - 可以通過復制(浪費空間)來處理容錯,
- Hadoop 3.x - 可以通過Erasure編碼處理容錯,
資料平衡
- Hadoop 2.x - 對于資料,平衡使用HDFS平衡器,
- Hadoop 3.x - 對于資料,平衡使用Intra-data節點平衡器,該平衡器通過HDFS磁盤平衡器CLI呼叫,
存盤Scheme
- Hadoop 2.x - 使用3X副本Scheme,
- Hadoop 3.x - 支持HDFS中的擦除編碼,
存盤開銷
- Hadoop 2.x - HDFS在存盤空間中有200%的開銷,
- Hadoop 3.x - 存盤開銷僅為50%,
存盤開銷示例
Hadoop 2.x - 如果有6個塊,那么由于副本方案(Scheme),將有18個塊占用空間,
Hadoop 3.x - 如果有6個塊,那么將有9個塊占用6塊空間,3個用于奇偶校驗,
YARN時間線服務
- Hadoop 2.x - 使用具有可伸縮性問題的舊時間軸服務,
- Hadoop 3.x - 改進時間線服務v2并提高時間線服務的可擴展性和可靠性,
默認埠范圍
- Hadoop 2.x - 在Hadoop 2.0中,一些默認埠是Linux臨時埠范圍,所以在啟動時,他們將無法系結,
- Hadoop 3.x - 但是在Hadoop 3.0中,這些埠已經移出了短暫的范圍,
工具
- Hadoop 2.x - 使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具,
- Hadoop 3.x - 可以使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具,
兼容的檔案系統
- Hadoop 2.x - HDFS(默認FS),FTP檔案系統:它將所有資料存盤在可遠程訪問的FTP服務器上, Amazon S3(簡單存盤服務)檔案系統Windows Azure存盤Blob(WASB)檔案系統,
- Hadoop 3.x - 它支持所有前面以及Microsoft Azure Data Lake檔案系統,
Datanode資源
- Hadoop 2.x - Datanode資源不專用于MapReduce,我們可以將它用于其他應用程式,
- Hadoop 3.x - 此處資料節點資源也可用于其他應用程式,
MR API兼容性
- Hadoop 2.x - 與Hadoop 1.x程式兼容的MR API,可在Hadoop 2.X上執行,
- Hadoop 3.x - 此處,MR API與運行Hadoop 1.x程式兼容,以便在Hadoop 3.X上執行,
支持Microsoft Windows
- Hadoop 2.x - 它可以部署在Windows上,
- Hadoop 3.x - 它也支持Microsoft Windows,
插槽/容器
- Hadoop 2.x - Hadoop 1適用于插槽的概念,但Hadoop 2.X適用于容器的概念,通過容器,我們可以運行通用任務,
- Hadoop 3.x - 它也適用于容器的概念,
單點故障
- Hadoop 2.x - 具有SPOF的功能,因此只要Namenode失敗,它就會自動恢復,
- Hadoop 3.x - 具有SPOF的功能,因此只要Namenode失敗,它就會自動恢復,無需人工干預就可以克服它,
HDFS聯盟
- Hadoop 2.x - 在Hadoop 1.0中,只有一個NameNode來管理所有Namespace,但在Hadoop 2.0中,多個NameNode用于多個Namespace,
- Hadoop 3.x - Hadoop 3.x還有多個名稱空間用于多個名稱空間,
可擴展性
- Hadoop 2.x - 我們可以擴展到每個群集10,000個節點,
- Hadoop 3.x - 更好的可擴展性, 我們可以為每個群集擴展超過10,000個節點,
訪問資料
- Hadoop 2.x - 由于資料節點快取,我們可以快速訪問資料,
- Hadoop 3.x - 這里也通過Datanode快取我們可以快速訪問資料,
HDFS快照
- Hadoop 2.x - Hadoop 2增加了對快照的支持, 它為用戶錯誤提供災難恢復和保護,
- Hadoop 3.x - Hadoop 2也支持快照功能,
平臺
- Hadoop 2.x - 可以作為各種資料分析的平臺,可以運行事件處理,流媒體和實時操作,
- Hadoop 3.x - 這里也可以在YARN的頂部運行事件處理,流媒體和實時操作,
群集資源管理
- Hadoop 2.x - 對于群集資源管理,它使用YARN, 它提高了可擴展性,高可用性,多租戶,
- Hadoop 3.x - 對于集群,資源管理使用具有所有功能的YARN,
二、Hadoop的發展簡史
-
Hadoop最初是由Apache Lucene專案的創始人Doug Cutting開發的文本搜索庫,Hadoop源自始于2002年的Apache Nutch專案——一個開源的網路搜索引擎并且也是Lucene專案的一部分,
-
在2004年,Nutch專案也模仿GFS開發了自己的分布式檔案系統NDFS(Nutch Distributed File System),也就是HDFS的前身,
-
2004年,谷歌公司又發表了另一篇具有深遠影響的論文,闡述了MapReduce分布式編程思想,
-
2005年,Nutch開源實作了谷歌的MapReduce,
-
到了2006年2月,Nutch中的NDFS和MapReduce開始獨立出來,成為Lucene專案的一個子專案,稱為Hadoop,同時,Doug Cutting加盟雅虎,
-
2008年1月,Hadoop正式成為Apache頂級專案,Hadoop也逐漸開始被雅虎之外的其他公司使用,
-
2008年4月,Hadoop打破世界紀錄,成為最快排序1TB資料的系統,它采用一個由910個節點構成的集群進行運算,排序時間只用了209秒,
-
在2009年5月,Hadoop更是把1TB資料排序時間縮短到62秒,Hadoop從此名聲大震,迅速發展成為大資料時代最具影響力的開源分布式開發平臺,并成為事實上的大資料處理標準,
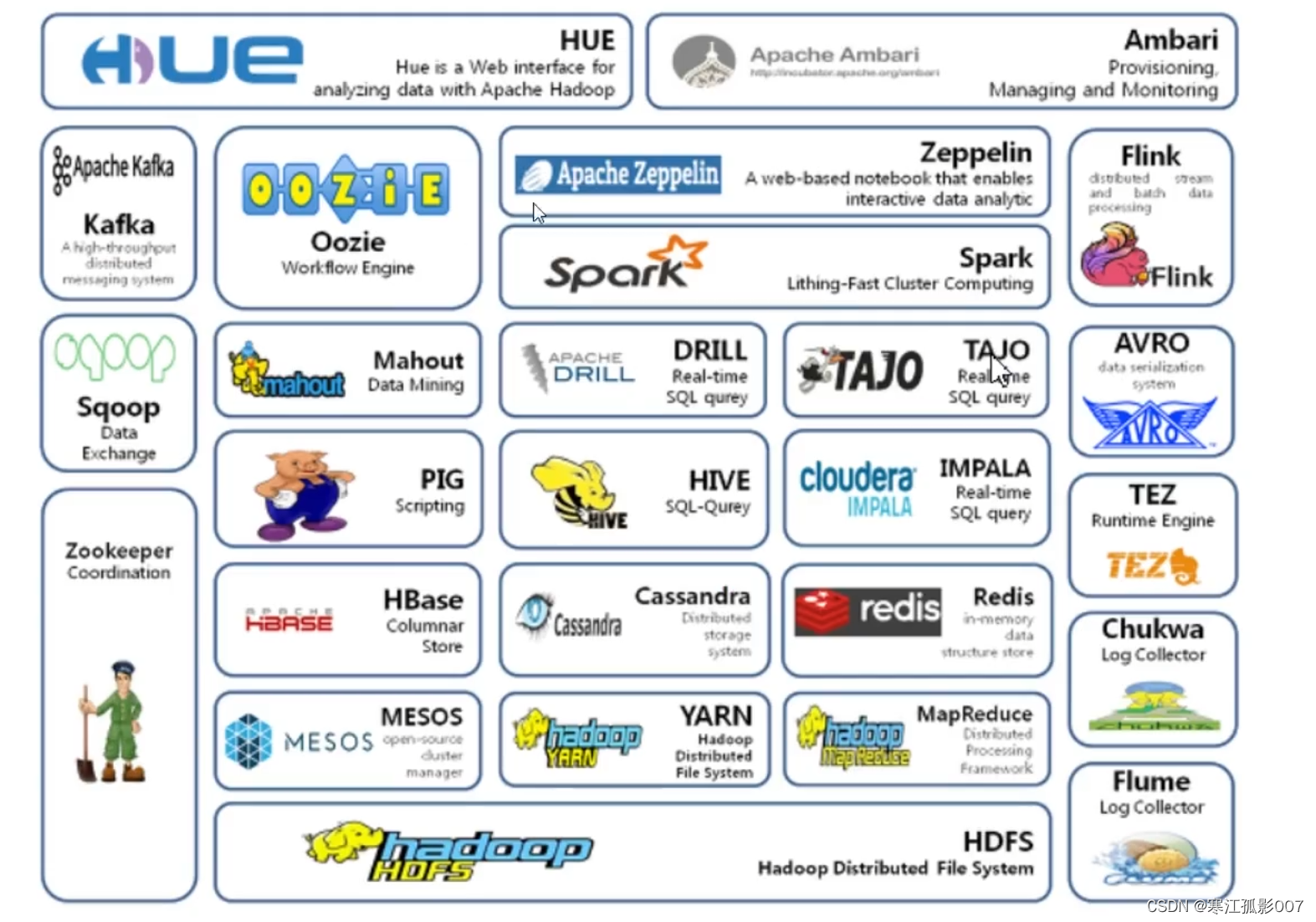
三、Hadoop生態系統
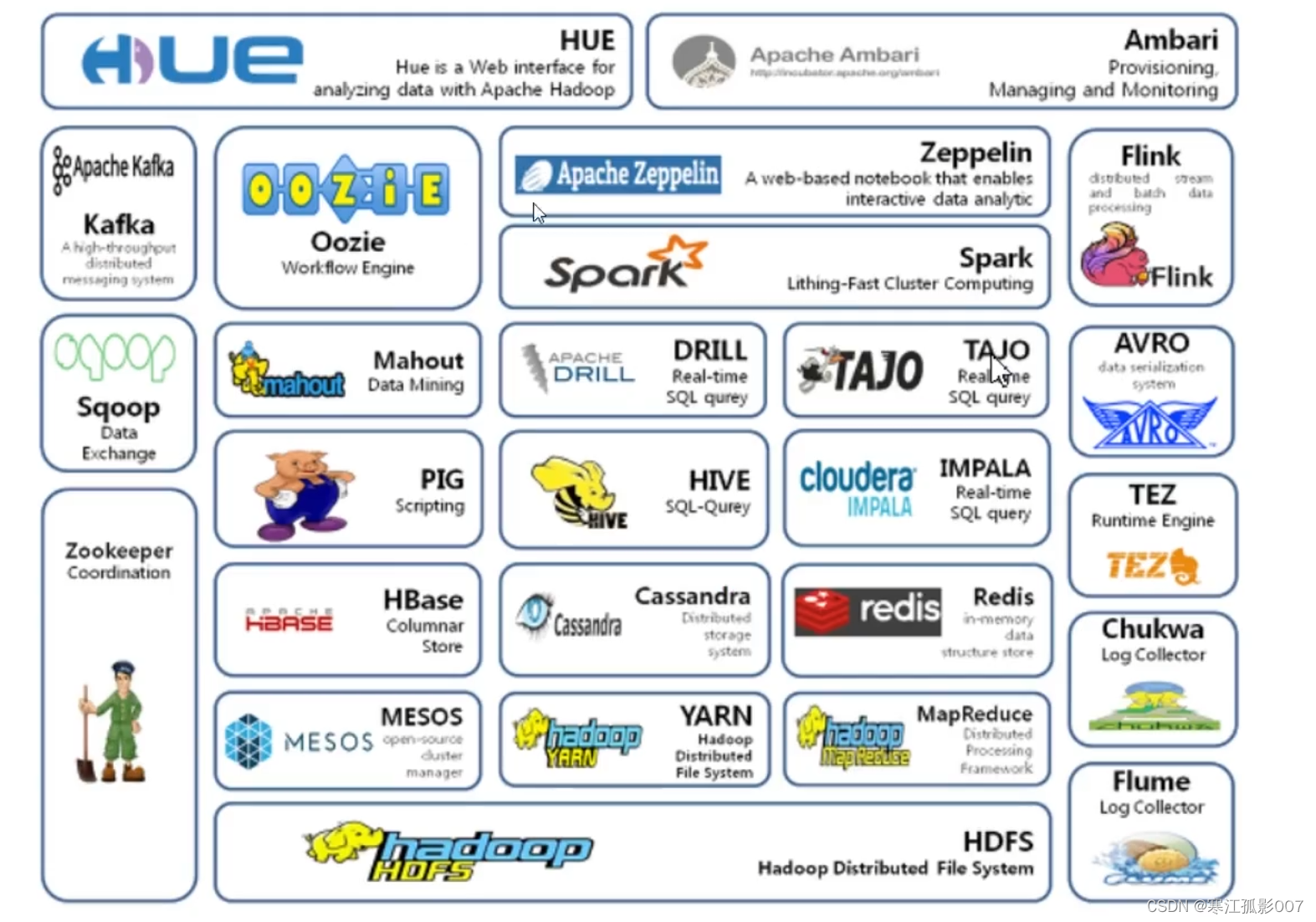
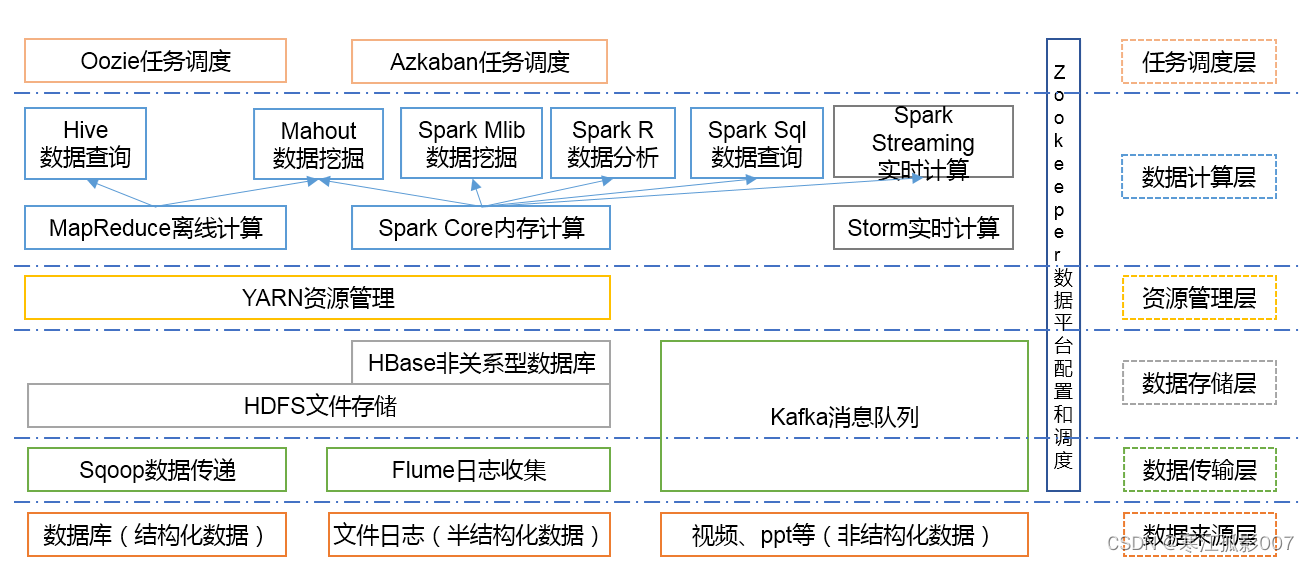
- HDFS——Hadoop分布式檔案系統,GFS的Java開源實作,運行于大型商用機器集群,可實作分布式存盤,
- MapReduce——一種并行計算框架,Google MapReduce模型的Java開源實作,基于其寫出來的應用程式能夠運行在由上千個商用機器組成的大型集群上,并以一種可靠容錯的方式并行處理T級別及以上的資料集,(第一代的計算框架,自身存在一些弊端,所以導致企業里已經很少使用了),
- Yarn——Apache Hadoop YARN (Yet Another Resource Negotiator,另一種資源協調者)是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統,可為上層應用提供統一的資源管理和調度,它的引入為集群在利用率、資源統一管理和資料共享等方面帶來了巨大好處,
- Spark——Spark是加州大學伯克利分校AMP實驗室(Algorithms, Machines, and People Lab)開發的通用記憶體并行計算框架,借鑒了MapReduce之上發展而來的,繼承了其分布式并行計算的優點并改進了MapReduce明顯的缺陷,使用場景如下:
-
復雜的批量處理(Batch Data Processing),偏重點在于處理海量資料的能力,至于處理速度可忍受,通常的時間可能是在數十分鐘到數小時;
-
基于歷史資料的互動式查詢(Interactive Query),通常的時間在數十秒到數十分鐘之間
-
基于實時資料流的資料處理(Streaming Data Processing),通常在數百毫秒到數秒之間
-
- Storm——Storm用于“連續計算”,對資料流做連續查詢,在計算時就將結果以流的形式輸出給用戶,如今已被Flink替代,
- Flink——Apache Flink是一個面向資料流處理和批量資料處理的可分布式的開源計算框架,它基于同一個Flink流式執行模型(streaming execution model),能夠支持流處理和批處理兩種應用型別,由于流處理和批處理所提供的SLA(服務等級協議)是完全不相同, 流處理一般需要支持低延遲、Exactly-once保證,而批處理需要支持高吞吐、高效處理,所以在實作的時候通常是分別給出兩套實作方法,或者通過一個獨立的開源框架來實作其中每一種處理方案,
- Flume——一個可用的、可靠的、分布式的海量日志采集、聚合和傳輸系統,
- Hive——是為提供簡單的資料操作而設計的分布式資料倉庫,它提供了簡單的類似
SQL語法的HiveQL語言進行資料查詢, - Zookeeper——分布式協調系統,Google Chubby的Java開源實作,是高可用的和可靠的分布式協同(coordination)系統,提供分布式鎖之類的基本服務,用于構建分布式應用,
- Hbase——基于Hadoop的分布式資料庫,Google BigTable的開源實作 是一個有
序、稀疏、多維度的映射表,有良好的伸縮性和高可用性,用來將資料存盤到各個計算節點上, - Cloudbase——基于Hadoop的資料倉庫,支持標準的SQL語法進行資料查詢,
- Pig——大資料流處理系統,建立于Hadoop之上為并行計算環境提供了一套資料工
作流語言和執行框架, - Mahout——基于HadoopMapReduce的大規模資料挖掘與機器學習演算法庫,
- Oozie——MapReduce作業流管理系統,
- Sqoop——資料轉移系統,是一個用來將Hadoop和關系型資料庫中的資料相互轉
移的工具,可以將一個關系型資料庫中的資料匯入Hadoop的HDFS中,也可以將HDFS
的資料匯入關系型資料庫中, - Scribe——Facebook開源的日志收集聚合框架系統,
這里只是列舉了一部分Hadoop生態里的組件,稍微介紹了一下,上面提到的目前企業里最常見的組件的原理介紹,安裝部署,以及企業級使用會在后續分享出來,請耐心等待……
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/455620.html
標籤:大數據