這兩天都是在跟檔案打交道,很有趣,每一步都不會順心如意,但每一步的解決都有所獲益,首先是對檔案變化的監測,能找到很多辦法,例如通過ELK家族的Filebeat工具來探測,但是外部工具不好融合進Storm,最好是自己寫Java程式來監測,
引入Java NIO 監控檔案
其實jdk7以上版本就有一個比較不錯的選擇,那就是nio包里的WatchService監控器,我覺得它有兩方面的優點,其一就是由作業系統的信號通知機制,當檔案目錄中出現變化就發信號給應用層監控器,那么這種由作業系統主動通知的效率就遠好于應用程式對檔案的反復輪巡,而且不占用過多系統資源;其二編程模型并不采用觀察者模式注冊監聽器的方案,而是將多執行緒問題隱藏起來,客戶端對api采取回圈阻塞的直觀呼叫,這就非常有利于嵌入到各種運行容器當中去執行檔案采集監控,
另外監測檔案變化后按行采集變化記錄我采用了RadmonAccessFile物件,這個檔案操作物件常用于斷點續傳此類的需求,很方便,關鍵要設計一個可持久化的位移記錄檔案,保證采集器重啟后總能從未讀取的最新變化資料點位置開始采集資料,如下圖所示:
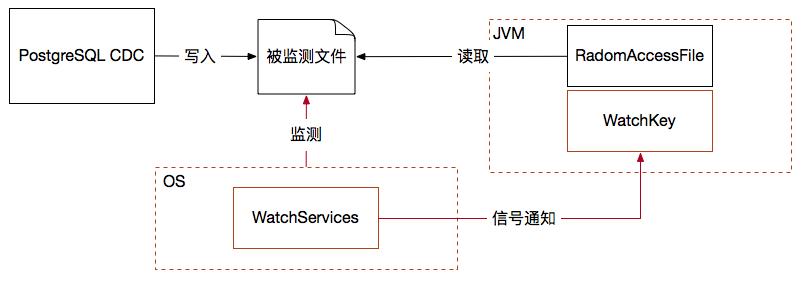
檔案監控與采集功能嵌入Storm集群之后又出現了一個新問題,那就是Storm spout實體不會如你所愿地運行在指定的機器上,而是完全由Storm集群隨機地在節點上指定運行,但被監測的檔案位置是固定的,反正總有笨辦法:當Storm集群啟動后,確定spout運行的機器節點,再由該機器執行cdc檔案輸出程式,但是這樣耦合性太強,必須跟隨Storm對spout實體的安排而變化采集位置,維護管理就會很麻煩,而且很容易出錯,
引入分布式檔案系統
因此我就引出了一個新的假設:通過分布式檔案系統(dfs)來解決此問題,但是dfs的選型很重要,Hadoop hdfs肯定不行,它脫離了普通檔案系統的操作方式,最終我挑選了兩款dfs,一是ClusterFS,二是MooseFS,它們都具有fuse結合功能,通過Mount dfs到本地目錄的方式,讓訪問dfs如同訪問本地目錄檔案一樣無縫結合,dfs的任一客戶端節點對檔案的修改,都會在所有dfs客戶端節點上被通知,因此我讓Storm的所有節點都成為dfs的客戶端,這樣無論spout隨機運行在任何節點上,都可以在本節點的相同目錄中去訪問dfs中的被監測的檔案,同時被監測檔案還具有了多副本的高可靠性,
這種解決分布式計算程序中與分布式存盤結合的方案,也就是Storm計算節點由于是集群動態分配位置,無法固定住Storm spout的檔案采集位置,因此我選擇了分布式檔案系統的思路,主要是利用了GlusterFS連接Linux fuse(用戶空間檔案系統)的辦法,使得每一個spout節點都是dfs客戶端,那么無論spout被分配在哪個節點,都可以通過監測并讀取本節點的GlusterFS客戶端掛載(mount)的目錄來實作對PostgreSQL cdc輸出檔案副本的資料采集,
但是測驗中發現一個大bug,讓我虎軀一震,bug原因分析:
制服Bug的藝術
內置在spout中的Java檔案監控器(WatchService)監控目錄變化是通過作業系統傳遞來的信號驅動的,這樣spout就可以等待式檔案變化實作監控,可是我想當然的以為就算PostgreSQL cdc輸出節點與spout檔案采集監控節點不是一臺機器也可以,只要通過分布式檔案系統同步副本,spout節點就一定能感知到當前目錄副本的變化,事實上我錯了,spout中的watchservice根本就感知不到目錄副本的變化,因此想要得到作業系統的檔案變化信號通知,必須對檔案目錄的讀寫是在一臺機器上,才會有檔案變化信號發送給上層應用,我之前的測驗正確僅僅是因為PostgreSQL輸出和spout監控是同一臺服務器,
那么問題就來了,我的假設就是spout不用考慮采集點的目錄位置,否則逆向根據storm集群分配好spout節點地址后才能進行pg監控,顯然這是顛倒流程了,又試過MooseFS和NFS,結果一樣,NFS還不如分布式檔案系統高效,
當無路可走的時候,認為自己的假設即將失敗的時候,一個新的思路開啟了我的靈感,為什么非要spout只設定1個并行度呢?按照參與Storm集群拓撲的作業數是3個,那就設定spout并行度為3,這樣每一個機器就都會有一個spout監控本地GlusterFS掛載目錄,那么無論我的PostgreSQL cdc輸出程式是在哪個節點啟動,同時只會有一個spout感應到副本變化開始推送資料,其他都是wait,這樣就解決了問題,同樣也保證了即便是換一個節點進行PostgreSQL cdc檔案輸出,前一個spout實體自然wait,新的spout就作業了,依然完美地保證了PostgreSQL cdc程式與spout的可靠性冗余,
本文來自博客園,作者:程式員守護石,轉載請注明原文鏈接:https://www.cnblogs.com/readbyte/p/16100177.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/455628.html
標籤:其他
上一篇:大資料Hadoop生態系統介紹