
桔妹導讀:在各大互聯網公司都提倡資料驅動的今天,AB實驗是我們進行決策分析的一個重要利器,一次實驗程序會包含多個環節,今天主要給大家分享滴滴實驗平臺在分組環節推出的一種提升分組均勻性的新方法,本文首先會介紹一下滴滴AB實驗的相關情況,以及在實驗分組環節中遇到的問題,然后介紹目前在實驗物件分組方面的通用做法,以及我們對分組環節的改進,最后是新方法的效果介紹,
1. AB實驗概述
互聯網公司中,當用戶規模達到一定的量級之后,資料驅動能夠幫助公司更好的決策和發展,在滴滴各個團隊中,我們經常會面臨不同的產品設計方案的選擇或者多個演算法方案的決策,比如頂部導航欄的排序方案一二三,派單演算法一二三等等,傳統的解決方法通常是由該領域經驗豐富的專家來決定,或者由團隊成員討論決定,有時候甚至是隨機選擇一個方案上線,雖然在某些情況下傳統解決辦法也是有效的,但是讓AB實驗后的資料說話,會讓方案選擇更加有信服力,
滴滴Apollo AB實驗平臺,支持了滴滴諸多業務的功能優化、策略優化以及運營活動,提供了在線實驗以及離線實驗的能力,并行實驗數達到 6000+ / 周,在分組方法上提供隨機分組以及時間片分組來應對不同的實驗場景,效果分析方面,我們對基礎指標、率指標、均值指標、留存指標等多種型別的指標提供了均值檢驗、VCM、Bootstrap等多種分析手段,
2. 分組的問題
一次完整的AB實驗可以分為以下幾步:

第一步:
設計實驗方案,包括確定實驗物件,劃分實驗組,確定實驗提升目標等,
第二步:
進行人群分組,一般是一個空白組加一個或多個實驗組
第三步:
將需要實驗的策略,方案或者功能施加到各個組,收集資料
第四步:
對實驗關心的指標進行分析觀察
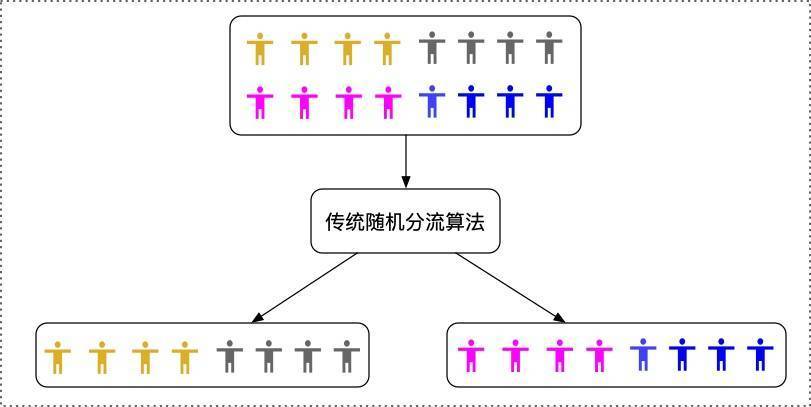
本文主要討論其中第二步的實作,業界在進行實驗物件分組的時候,最常用的是隨機分組方式,這也是滴滴諸多實驗中占比最大的分組方式,隨機分組的做法可以實作為對實驗物件的某個ID欄位進行哈希后對100取模,根據結果值進入不同的桶,多個不同的組分別占有一定比例的桶,實驗物件在哈希取模之后,會得到0 ~ 99的一個數,即為該實驗物件落入的桶,這個桶所屬的組就是該實驗物件的組,

上述的這種分組方式稱為CR(Complete Randomization)完全隨機分組,進行一次CR,能將一批實驗物件分成對應比例的組,但是由于完全隨機的不確定性,分完組后,各個組的實驗物件在某些指標特性上可能天然就分布不均,均值,標準差等差異較大,如果分組不均,則將會影響到第四步的實驗效果分析的進行,可能遮蓋或者夸大實驗的效果,
待分流的個體具備一定的內在特點,比如就GMV這個指標來說,人群中會存在高GMV,中等GMV,低GMV等不同層次的用戶,如下圖所示,對于實驗人群進行完全隨機分流的方式,存在一定概率的不均勻,比如高GMV人群在某個組中的分配比例偏高,導致兩個組的GMV相對差異較大,比如一次實驗中,希望提升北京市的GMV 1%,在進行分組之后,實驗組的人群GMV天然就比對照組的人群GMV高2%,這樣實驗進行的結果就變的無法比較,如果沒有注意到實驗前的組間不均情況,甚至可能驗證出錯誤的結論,
基于CR的風險較大的情況,一般會對CR進行簡單的一步優化,即進行RR(Rerandomization),RR是在每次跑CR之后,驗證CR的分組結果組間的差異是否小于實驗設定的閾值,當各組的觀察指標小于閾值或者重新分組次數大于最大允許分組次數后,停止分組,
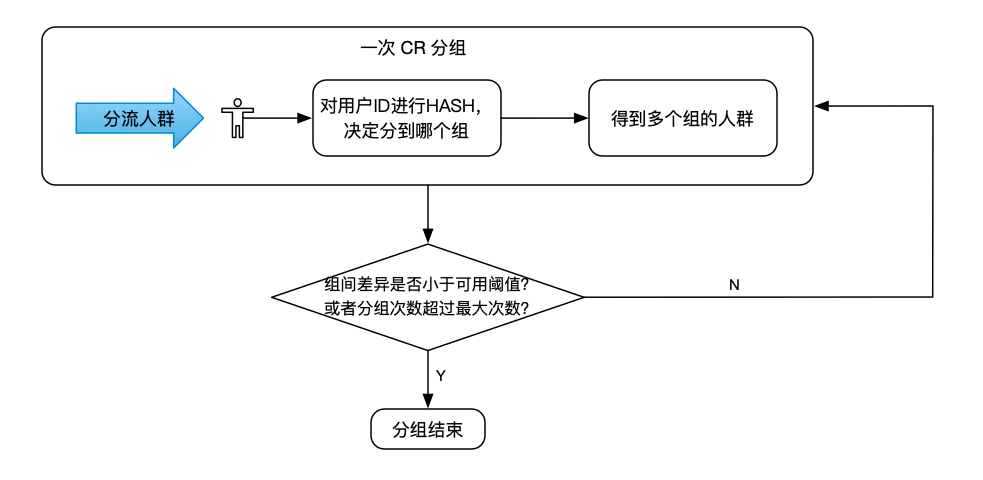
相比于CR,RR通過犧牲計算時間,能在一定概率上得到符合要求的分組,重分組次數與輸入的實驗物件樣本大小相關,樣本量越大,需要進行重分的次數一般較少,但是RR分組能得到符合要求的分組有一定的概率,且需要花更多的時間,所以,我們希望通過對分組演算法的改進,在一次分組程序中分出觀察指標均勻的分組結果,如下圖所示,
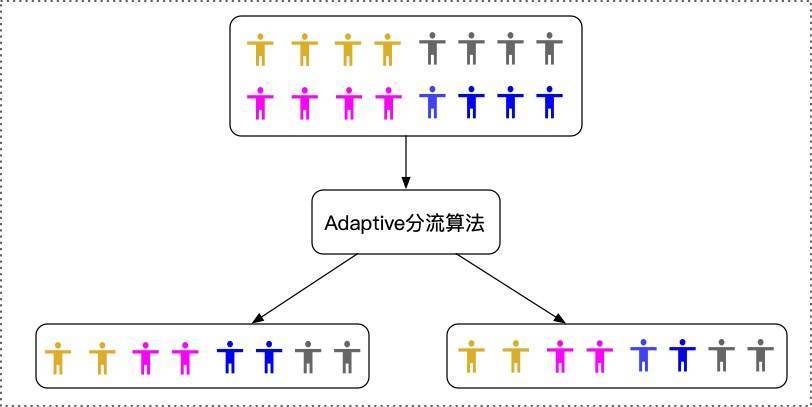
3. 自適應分組
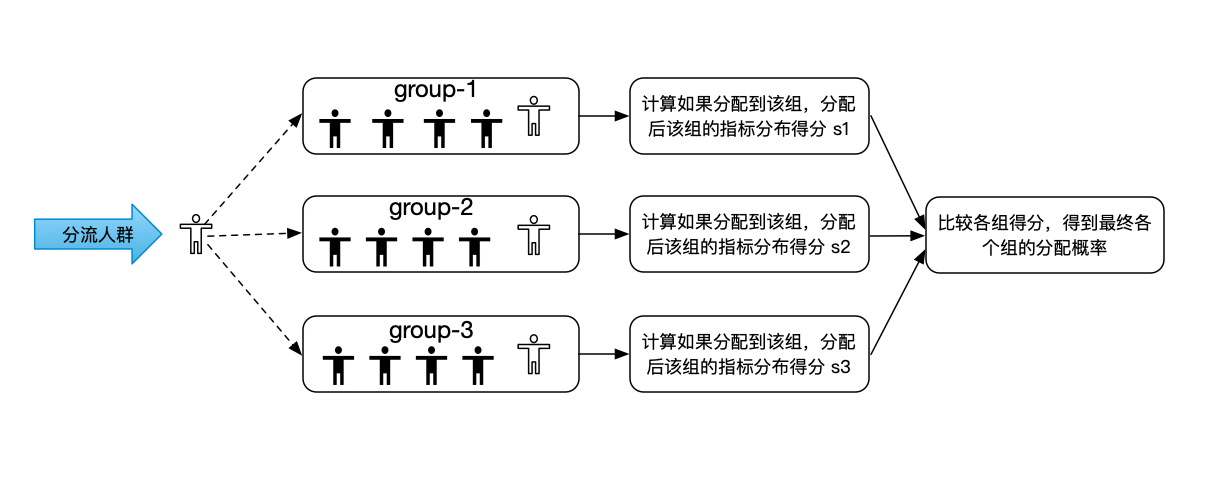
Apollo實驗平臺實作了滴滴AI LAB團隊設計的Adaptive(自適應)分組演算法,Adaptive分組方法可以在只分組一次的情況下,讓選定的觀測指標在分組后每組分布基本一致,可以極大的縮小相對誤差,相比于傳統的CR分組,Adaptive分組的演算法更加復雜,在遍歷人群進行分組的同時,每個組都需要記錄目前為止已經分配的樣本數,以及已經分配的樣本在選定的觀測指標上的分布情況,從分流人群中拿到下一個要分的物件后,會對實驗的各個組進行計算,計算該物件如果分配到本組,本組的觀測指標分布得分情況,然后綜合各個組的預分配得分情況,得到最終各個組對于該實驗物件的分配概率,
4. 系統設計
系統互動流程如下:
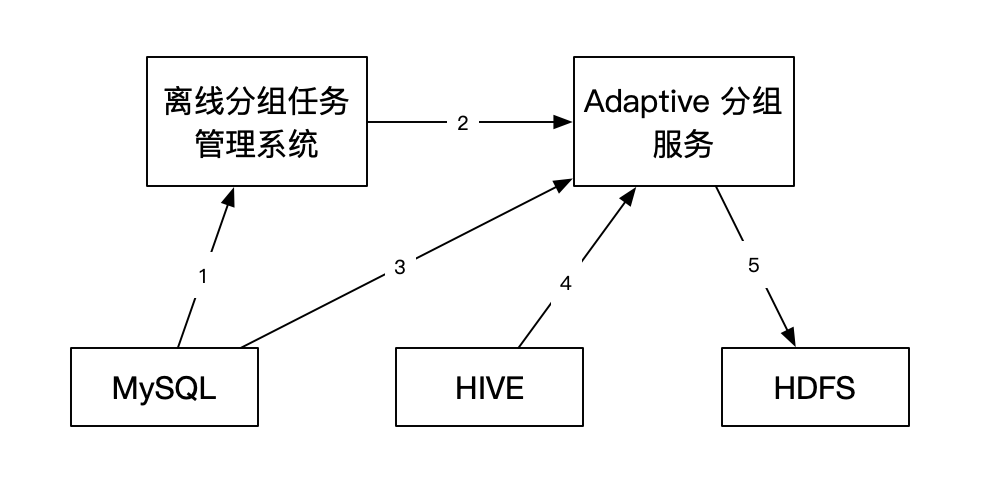
Adaptive分組方案的設計與實作復用了Apollo AB實驗已有離線分組架構的能力,用戶在實驗平臺通過API介面或者頁面創建完Adaptive實驗之后,實驗平臺會將分組需求發送到分組任務管理系統,生成分組任務存入資料庫中,Adaptive分組執行分為以下幾個步驟:
首先分組任務管理系統從資料庫中獲取需要進行分組的任務,然后根據任務型別呼叫不同的分組服務,Adaptive分組服務從資料庫中獲取實驗對應的計算資訊,根據實驗計算資訊中的觀察指標,從HIVE中獲取指標資料,根據人群資訊的地址獲取人群資料,執行完分組演算法之后,將分組結果寫入HDFS,
5. 演算法介紹
樣本打亂&隨機分配
將人群shuffle打亂之后,對于人群的前2 * K(K是組數)的人進行隨機分組,保證每個組中至少有兩個樣本之后再開始進行Adaptive分組,
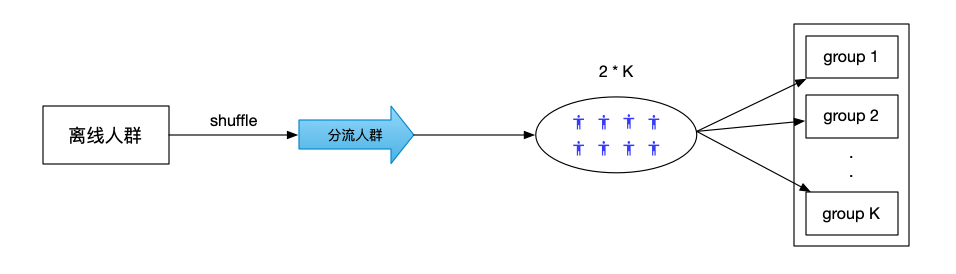
組引數初始化
根據實驗的組以及每個組的人群比例計算出各個組的直接分配概率和間接分配概率,每個組上的直接分配概率和間接分配概率,分別表示了在直接分配以及間接分配情況下,選中該組后,樣本分配到各個組的概率,根據已經分配的樣本資料,初始化觀測指標分布情況,
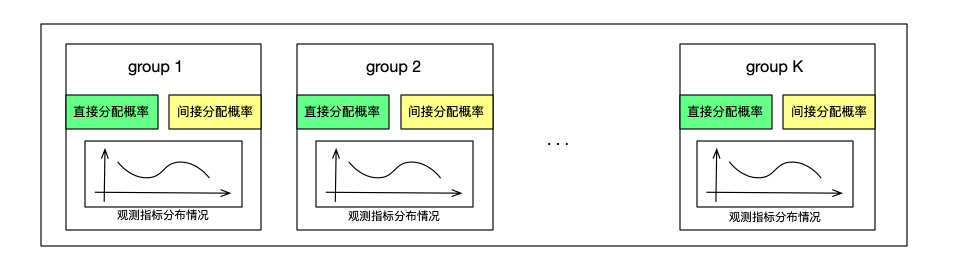
判斷直接或間接分配
計算各組已分配樣本數和組所占比例之間的關系,得到各個組的平衡系數BS,如果各個組的比例平衡系數相差較大,則進行直接分配,選用BS最小的組的直接分配概率來分配接下來的一個樣本,通過直接分配來粗粒度的調整各組的分配比例,如果平衡系數相差不大,則走接下來的指標分布計算,來決定使用哪個組的間接分配概率,
計算各組預分配得分
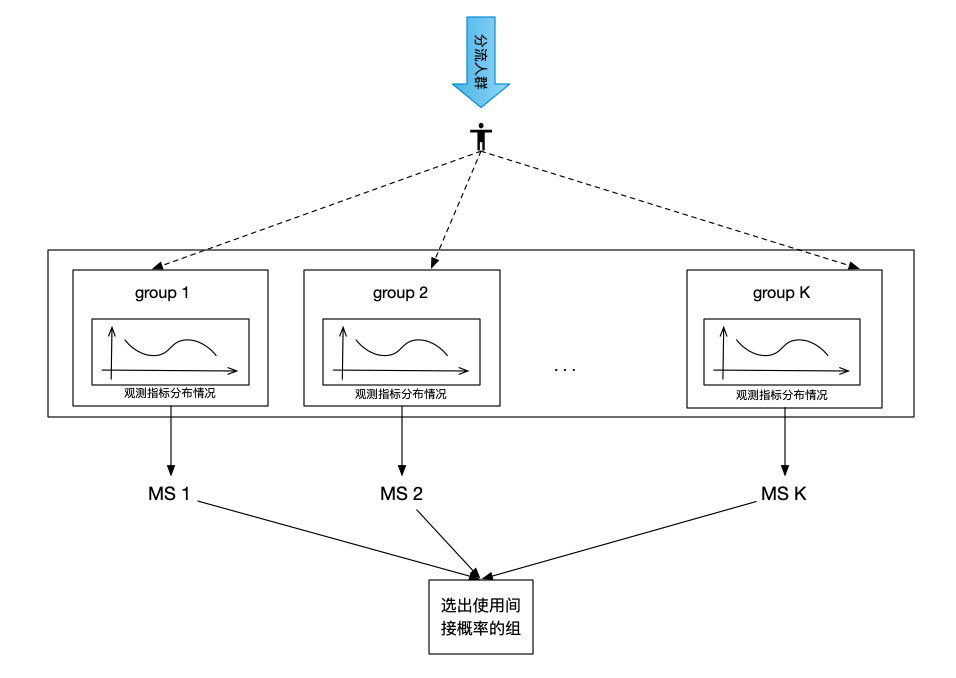
計算將要分配的一個樣本,如果分配到組k后,組k的指標分布得分MS k,MS是根據ANOVA模型計算出來的每個組在各個觀察指標上的均值,方差情況,通過比較各組的MS,選出向下偏離平均水平的組,以該組的間接分配概率作為各個組本樣本的分配概率,
更新指標分布
通過上述的流程,無論使用直接分配還是間接分配,最終得到一個樣本的實際分組后,用這個樣本在各個觀測指標上的資料更新分配到的組的指標分布資料,如此遍歷,直到分配完所有樣本,
6. 方案效果
使用Adaptive分組之后,1次分組得到符合要求的分組概率超過95%,
而不同演算法間對于組間差異的實際優化情況不僅是與演算法有關,也和進行分組的人群的大小,人群的分布特性相關,一般來說,人群大小越大,分布越均勻,使用隨機分組的分組結果就會越好,組間差異會越小,下面進行測驗的資料人群規模不大,所以直接隨機分組的差異會顯得比較大,并不代表所有情況,
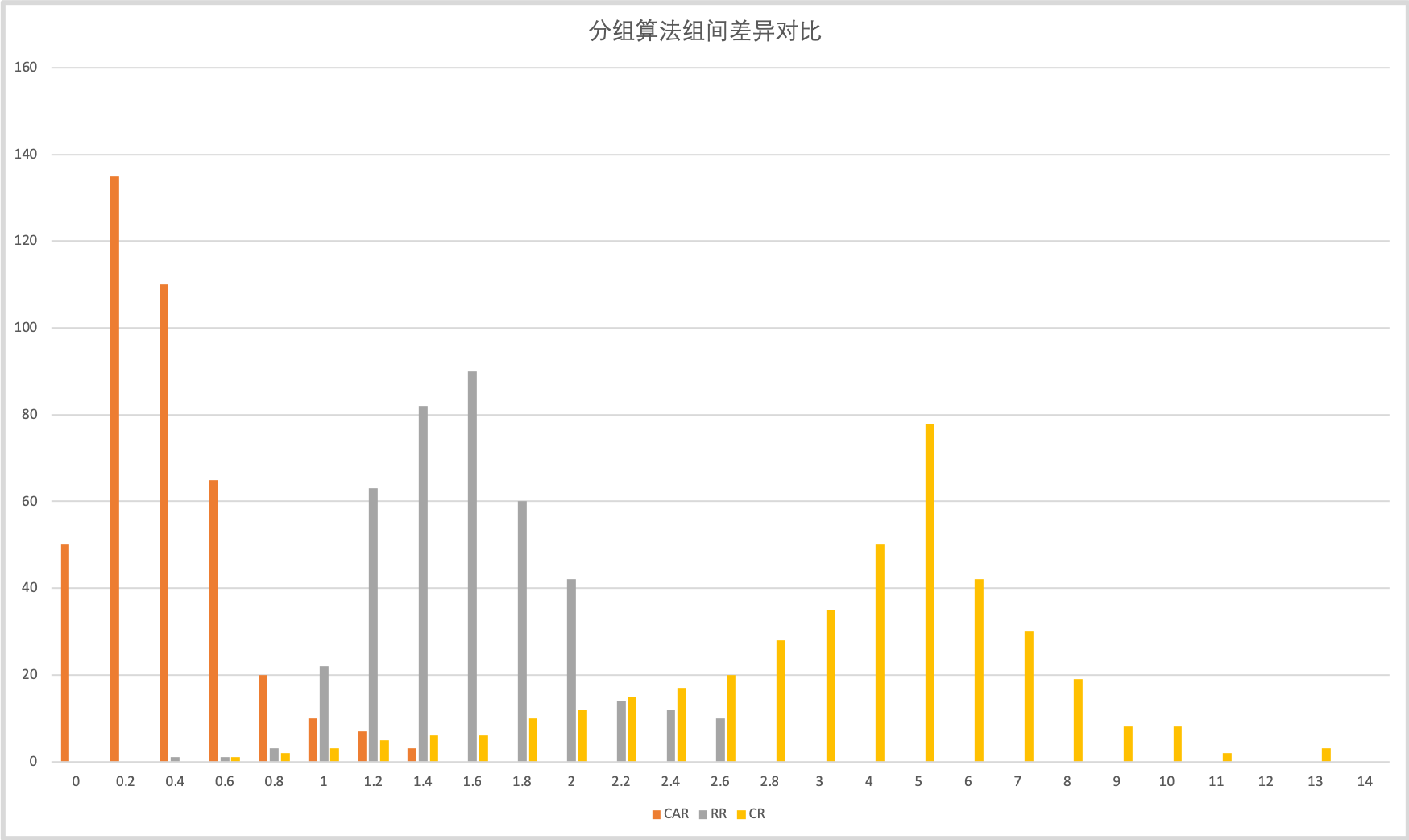
如上圖所示,是對一個大小為10000的司機人群進行分組測驗,并觀察分組后的結果在7日GMV,7日在線時長,全兼職三個指標上的分布情況,并取每次分組結果中三個指標上差異最大百分比作為本次分組的差異,其中CR(Complete Randomization)是指一次隨機分組,RR(每次是跑CR100次,取最優結果得到),CAR(Covariates Adaptive Randomization)是指一次Adaptive分組,圖中的縱坐標是該區間的次數,橫坐標是差異的百分比,
每種方式均執行了400次,統計指標的組間最大差異,CR方式的差異最大,最大差異可能達到14%以上,RR在CR的基礎上,通過時間換準確性,較大的降低了組間差異,最大組間差異能在2.7%以下,但是這個差異依然在實驗中不能被接受,CAR通過演算法的優化,進一步降低了組間的差異,95%的情況下能把差異控制在0.8%以下,
7. 總結
通過提供Adaptive自適應分組能力,我們極大的提高了隨機分組實驗的資料精度,降低了無效實驗的概率,縮短了實驗周期,然而,對于已經通過CR方式完成的隨機分流實驗,用上述的這一套方案已經無法重新均衡,如何從這種已經完成的實驗分組中抽取分布平衡的樣本進行效果評估是一個更大的挑戰,目前正在設計中,歡迎大家在本文留言,提寶貴意見,一起探討實驗相關問題,
團隊介紹

滴滴工程效能團隊肩負通過工程技術持續提升組織效能的使命,致力于建設世界一流的工程能力體系,為工程師提供極致的作業體驗,打造高效能研發組織,
作者介紹

2018年北郵碩士畢業加入滴滴,在工程效能團隊Apollo AB實驗專案組,從事實驗效果評估相關作業,負責實驗科學性相關的研究,
歡迎關注滴滴技術公眾號!

本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/4560.html
標籤:大數據
上一篇:Hive決議多重嵌套JSON陣列