ElasticSearch目前最新版是7.7.0,其中部署的細節和之前的6.x有很多的不同,所以這里單獨拉出來寫一下,希望對用7.x的童鞋有一些幫助,然后部署完ES后配套的kibana也是7.7.0,這個就簡單了放到最后說,下面先進入ES 7.7.0的部署.
首先是下載es的安裝包,官網下載即可,我這里的包是:elasticsearch-7.7.0-linux-x86_64.tar.gz,準備安裝位置:/opt/elasticsearch,其實每個節點操作都是一樣的,我這里不再詳細敘述每個機器的細節,而只是寫通用的配置,第一步就是解壓包到指定的位置:
tar -xvzf elasticsearch-7.7.0-linux-x86_64.tar.gz -C /opt cd /opt ln -s elasticsearch-7.7.0 elasticsearch cd elasticsearch
上面做個軟鏈接就是為了管理多個版本方便,老的版本不用洗掉,每次進目錄直接cd到/opt/elasticsearch就可以了,這個根據自己的習慣來就可以
進入目錄后首先還是修改ES的主組態檔:config/elasticsearch.yml,依次來看下面的配置項:
cluster.name這個和之前一樣配置集群名稱,我這里配置為:cluster.name: es-cluster
node.name 配置節點的名稱,一般和主機名一樣,或者自己定義一個集群中唯一的標識,我這和主機名不同,第一個節點配置為:node.name: cloud-1,后面的節點以此類推就是cloud-2,cloud-3等等
path.data 索引和資料存盤目錄,支持配置多個,一般情況下是1個,我這里配置為:path.data: /data/elasticsearch
path.logs 日志存盤目錄,我這里默認注釋,讓日志打在/opt/elasticsearch/logs下面,默認解壓出來就有這個logs目錄
bootstrap.memory_lock 是否鎖定記憶體,默認是注釋的,這里建議打開,讓es鎖定jvm heap不被搶占,我這里配置是:bootstrap.memory_lock: true,但是這里還要開啟另外的允許鎖定記憶體的內核引數,這個待會再說明
network.host 配置es系結主機的ip地址,可以設定為當前實際的ip,如果有多個網卡都想系結的話,可以設定為:0.0.0.0,這樣每個機器都一樣即可,network.host: 0.0.0.0
http.port 配置http的埠號,默認9200,如果不修改可以不打開
transport.port 配置tcp的埠號,默認是9300,這個配置項不存在,如果修改需要自己添加,這個在es 6.x中配置項為:transport.tcp.port注意這個變化
discovery.seed_hosts 這個配置集群中的主機串列,以便能夠在es啟動的時候進行通信,并且為主機發現提供種子,這個通信使用的埠為tcp埠也就是transport.port配置的埠,默認的話可以不加埠,可以配置多個ip地址或者主機名都可以,如果有多個網卡這里要配置帶寬高的,以便在集群中實作更快速的通信,官網給出的配置示例如下:
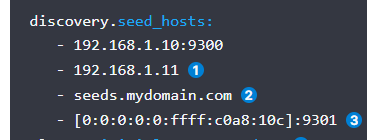
這個引數在6.x中的配置為:discovery.zen.ping.unicast.hosts,未來會被廢棄,要使用這個新的名稱,但是含義是一樣的
cluster.initial_master_nodes 這個配置啟動全新的集群時,那些節點可以作為master節點進行選票,其實默認不配置es也可以自動選舉,但是這樣是不安全的,所以需要配置一部分可以作為master節點的機器,之前的node.master其實可以不用配置了,另外防止腦裂的節點個數配置也去掉了,要注意:這里配置的不是主機名和ip,而是節點名稱,是前面node.name中配置的名稱,務必注意.
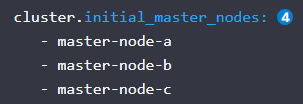
簡單地配置就是以上這些,具體還有很多配置需要根據需要參考檔案,下面將剛才的配置整理如下:
cluster.name: es-cluster
node.name: cloud-1
path.data: /data/elasticsearch
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["cloud1", "cloud2", "cloud3", "cloud4", "cloud5", "cloud6"]
cluster.initial_master_nodes: ["cloud-1", "cloud-2", "cloud-3"]
然后保存并退出,其實每個機器不同的地方只有node.name需要修改,如果network.host配置0.0.0.0則每個機器都不用改
然后配置jvm heap大小,組態檔:config/jvm.options
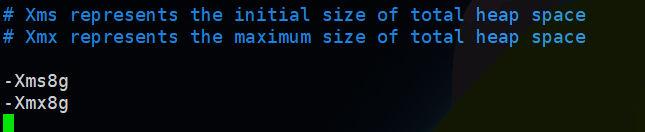
注意這里不要超過jvm長指標臨界空間的大小,最大不超過32G,但是實際上根據不同機器有所變化,正常最大配置26G是安全的,在啟動的時候日志中會有輸出:

只要上面顯示true則表示啟用了壓縮指標,對于實際的機器可以反復的修改除錯找到一個合理的臨界值.
修改完jvm配置后es就算基本配置完畢了,接下來就是要把整個安裝目錄發送到各個其他的節點并修改對應的node.name配置,
然后所有機器都要按照下面的操作配置內核引數:
1. 最大檔案數
es要求檔案數最小為65536,查看當前檔案數命令為: ulimit -n ,調大檔案數可以修改組態檔:/etc/security/limits.conf,添加如下配置:
* soft nofile 666666 * hard nofile 999999
保存配置后,重新登錄shell即可生效,可以再次通過上面的命令確認一下
2. 內核引數max_map_count
es要求max_map_count虛擬記憶體區域數量至少為262144,而默認作業系統的值都為:65536,因此也需要設定一下否則會報錯,臨時設定命令如下:
sysctl vm.max_map_count=2560000
這樣設定重啟機器引數值會還原所以還需要編輯/etc/sysctl.conf添加配置 vm.max_map_count=2560000 并且保存即可永久生效
3. 允許鎖定記憶體
剛才組態檔設定了bootstrap.memory_lock為true,但是默認作業系統不允許用戶程式鎖定記憶體,因此還需要配置解除限制,組態檔同樣是/etc/security/limits.conf,需要在其中添加:
elastic soft memlock unlimited
elastic hard memlock unlimited
第一列elastic是es的用戶,這個待會會創建,要保證和這里的一致,unlimited表示不限制鎖定記憶體的大小,保存配置待會切換到elastic用戶即可自動生效
4. 配置記憶體交換傾向
如果沒有交換磁區則可以忽略這個配置,如果有交換磁區的話并不建議完全禁用,因為在系統記憶體占用非常大的時候可以通過臨時交換到磁盤而避免系統崩潰,但是可以通過調整交換傾向讓系統盡可能的少使用交換磁區,這個引數通過vm.swappiness進行配置在redhat/centos 7.x中這個值默認為60,比較大建議設定為1~10,臨時修改同樣使用: sysctl vm.swappiness=1 ,永久修改同樣是改組態檔,這個引數在redhat/centos 8.x默認會根據機器配置調整,有可能已經就是10了,所以只需要看一下,有可能不用修改.
注意上面4個引數在每個節點都要配置,配置完引數下面需要在每個節點創建資料目錄和用戶并授權:
# 創建資料目錄 mkdir /data/elasticsearch # 創建用戶 useradd elastic # 設定密碼 根據提示輸入兩次 passwd elastic # 進入es安裝目錄修改權限 chown -R elastic:elastic jdk config logs /data/elasticsearch
值得注意的是7.7版本的es安裝包中已經有jdk環境了用的是AdoptOpenJDK,版本為最新的14,也就是說機器無需安裝jdk環境就可以使用es,上面四個目錄是必須要授權的,jdk目錄如果不授權啟動es的時候會提示無法執行檔案也就是沒有權限,為了方便也可以直接給整個目錄加上權限.
最后就是在每個節點啟動es了,
su - elastic cd /opt/elasticsearch bin/elasticsearch -d
啟動之后jps確定行程Elasticsearch正常存在,所有節點都啟動后通過 curl 'localhost:9200/_cat/nodes?v' 確認當前的節點串列是否正常
現在es集群就部署完畢了,接下來可以部署一下es常用的管理界面kibana,這個基本部署特別簡單,首先還是下載最新的7.7.0安裝包然后解壓:
tar -xvzf kibana-7.7.0-linux-x86_64.tar.gz mv kibana-7.7.0-linux-x86_64 /opt/kibana-7.7.0 cd /opt/kibana-7.7.0
然后編輯組態檔,這里簡單介紹一下基本的配置:
server.port kibana服務的埠號,默認是5601
server.host kibana系結的ip,這里可以寫實際的ip也可以寫0.0.0.0系結所有的網卡
server.name kibana的名稱,這個用于界面顯示,自定義即可
elasticsearch.hosts 需要連接的es集群主機串列,這個最好填寫完整的集群節點,每個節點內容是:http://host:port
kibana.index kibana進行相關的界面顯示需要將一些資料存放到es中,這個為es中創建索引名的前綴,默認為:.kibana
kibana.defaultAppId 默認的應用程式,默認是:home
基本的配置就是上面這些,另外還有更多詳細的引數配置,比如ES集群連接的超時引數等等,這些詳細的配置需要參考檔案調整,目前只是一個簡單地配置和使用,上面配置整理如下:
server.port: 5601 server.host: "0.0.0.0" server.name: "cloud1" elasticsearch.hosts: ["http://cloud1:9200", "http://cloud2:9200","http://cloud3:9200", "http://cloud4:9200", "http://cloud5:9200", "http://cloud6:9200"] kibana.index: ".kibana" kibana.defaultAppId: "home"
配置保存之后就可以啟動kibana服務了,需要注意kibana也需要用特定的用戶啟動,如果用root用戶直接啟動會給出提示,可以添加--allow-root強制啟動,啟動命令為: bin/kibana --allow-root ,啟動之后可能會有幾個警告,可以先不用關心,等啟動完畢可以通過瀏覽器輸入http://ip:5601進入kibana的界面,具體界面的使用這里就不再詳細的敘述了
上面就是ElasticSearch+kibana組合的簡單部署,如果覺得kibana太重量也可以嘗試一下cerebro這個輕量的es管理工具,github鏈接為:https://github.com/lmenezes/cerebro,另外有關于ES的其他問題歡迎一起交流.
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/4566.html
標籤:大數據