結合其他同學和自己的筆記總結如下
什么是hive?
- 基于Hadoop的開源的資料倉庫工具,用于處理海量結構化資料,
- Hive把HDFS中結構化的資料映射成表,
- Hive通過把HiveSQL進行決議和轉換,最終生成一系列在hadoop上運行的mapreduce任務,通過執行這些任務完成資料分析與處理,
Hive與傳統資料庫的比較
由于Hive采用了SQL的查詢語言HQL,因此很容易將Hive理解為資料庫,其實從結構上來看,Hive和資料庫除了擁有類似的查詢語言,再無類似之處,本文將從多個方面來闡述Hive和資料庫的差異,資料庫可以用在Online的應用中,但是Hive是為資料倉庫而設計的,清楚這一點,有助于從應用角度理解Hive的特性,
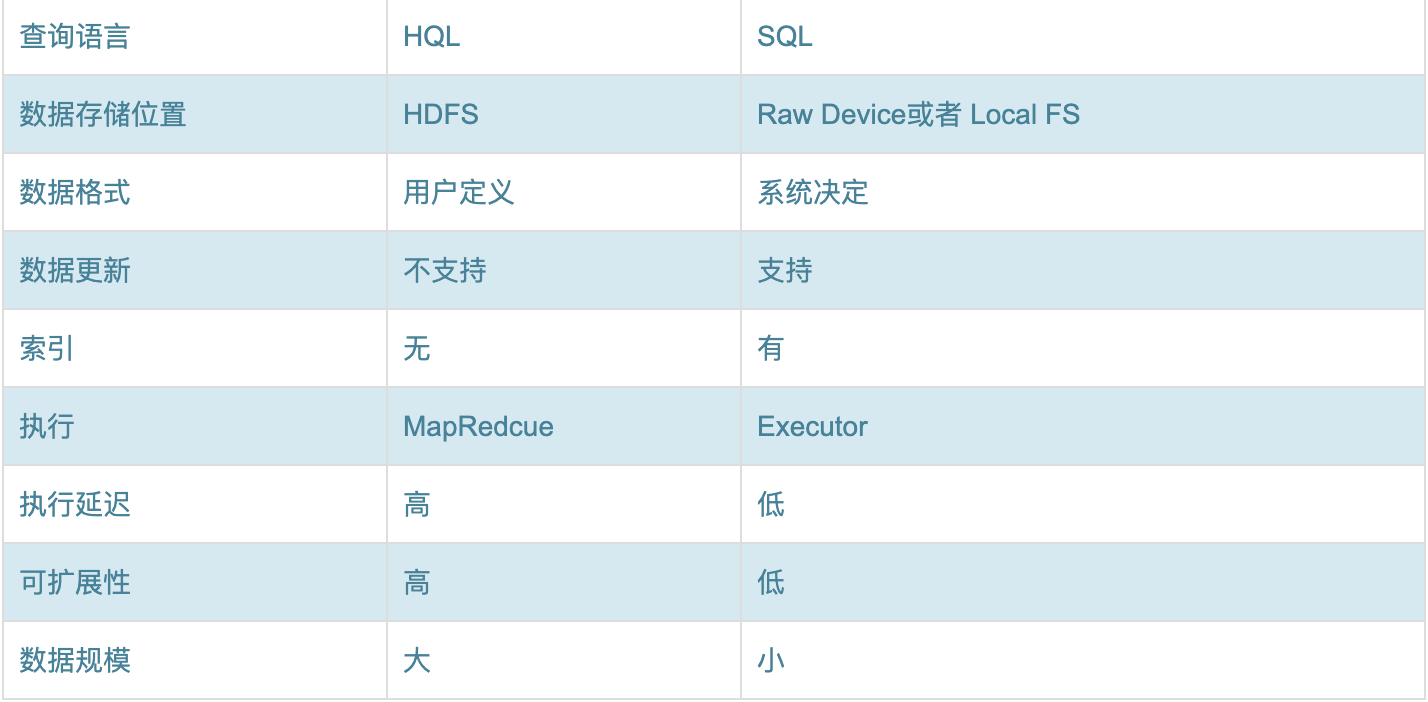
1.查詢語言
由于 SQL被廣泛的應用在資料倉庫中,因此,專門針對 Hive的特性設計了類 SQL的查詢語言 HQL,熟悉 SQL開發的開發者可以很方便的使用 Hive進行開發,
2.資料存盤位置
Hive 是建立在 Hadoop之上的,所有 Hive的資料都是存盤在 HDFS中的,而資料庫則可以將資料保存在塊設備或者本地檔案系統中,
3.資料格式
Hive 中沒有定義專門的資料格式,資料格式可以由用戶指定,用戶定義資料格式需要指定三個屬性:列分隔符(通常為空格、”\t”、”\x001″)、行分隔符(”\n”)以及讀取檔案資料的方法(Hive中默認有三個檔案格式TextFile,SequenceFile以及 RCFile),由于在加載資料的程序中,不需要從用戶資料格式到 Hive定義的資料格式的轉換,因此,Hive在加載的程序中不會對資料本身進行任何修改,而只是將資料內容復制或者移動到相應的 HDFS目錄中,而在資料庫中,不同的資料庫有不同的存盤引擎,定義了自己的資料格式,所有資料都會按照一定的組織存盤,因此,資料庫加載資料的程序會比較耗時,
4.資料更新
由于 Hive是針對資料倉庫應用設計的,而資料倉庫的內容是讀多寫少的,因此,Hive中不支持對資料的改寫和添加,所有的資料都是在加載的時候中確定好的,而資料庫中的資料通常是需要經常進行修改的,因此可以使用 INSERT INTO ... VALUES添加資料,使用 UPDATE ... SET修改資料,
5.索引
之前已經說過,Hive在加載資料的程序中不會對資料進行任何處理,甚至不會對資料進行掃描,因此也沒有對資料中的某些Key建立索引,Hive要訪問資料中滿足條件的特定值時,需要暴力掃描整個資料,因此訪問延遲較高,由于 MapReduce的引入, Hive可以并行訪問資料,因此即使沒有索引,對于大資料量的訪問,Hive仍然可以體現出優勢,資料庫中,通常會針對一個或者幾個列建立索引,因此對于少量的特定條件的資料的訪問,資料庫可以有很高的效率,較低的延遲,由于資料的訪問延遲較高,決定了 Hive不適合在線資料查詢,
6.執行
Hive 中大多數查詢的執行是通過 Hadoop提供的 MapReduce來實作的(類似 select * from tbl的查詢不需要MapReduce),而資料庫通常有自己的執行引擎,executor執行器,
7.執行延遲
之前提到,Hive在查詢資料的時候,由于沒有索引,需要掃描整個表,因此延遲較高,另外一個導致 Hive執行延遲高的因素是MapReduce框架,由于 MapReduce本身具有較高的延遲,因此在利用 MapReduce執行 Hive 查詢時,也會有較高的延遲,相對的,資料庫的執行延遲較低,當然,這個低是有條件的,即資料規模較小,當資料規模大到超過資料庫的處理能力的時候,Hive的并行計算顯然能體現出優勢,
8.可擴展性
由于 Hive是建立在 Hadoop之上的,因此 Hive的可擴展性是和 Hadoop的可擴展性是一致的,而資料庫由于 ACID語意的嚴格限制,擴展行非常有限,目前最先進的并行資料庫 Oracle在理論上的擴展能力也只有 100臺左右,
9.資料規模
由于 Hive建立在集群上并可以利用 MapReduce進行并行計算,因此可以支持很大規模的資料;對應的,資料庫可以支持的資料規模較小,
說明:
- 資料倉庫/資料湖主要是用來資料分析的,對企業中的決策起到關鍵性的作用,
- 資料倉庫本身不產生資料,也不消耗資料;其資料是從外部來的,并且主要提供給外部使用,
- 資料倉庫是面向主題性來構建的,一般一個數倉都有一個特定的目的,資料倉庫集成了眾多型別的資料,分成了許多不同的層次,
- 資料倉庫中的歷史資料一般不會改變,因為其主要用來記錄已經發生的事實的資料,
- 資料倉庫上層的分析是可能會發生變化的,體現了分析的靈活性,
- 面向事務的聯機事務處理OLTP vs 面向分析的聯機分析處理OLAP
Hive的優勢:
- 把海量資料存盤于 Hadoop 檔案系統,而不是資料庫,提供了一套類資料庫的資料存盤和處理機制,并采用 HQL (類 SQL )語言對這些資料進行自動化處理,
- 不僅提供了一個熟悉SQL的用戶所能熟悉的編程模型,還消除了大量的通用代碼,甚至那些那些Java撰寫的令人棘手的代碼,
- 學習成本低,可以通過類SQL陳述句快速實作簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統計分析,應用開發靈活而高效,
以下擴展慎用:
查看資料庫資訊
desc database extended 資料庫名;
洗掉資料庫
drop database if exists 庫名;
強制洗掉資料庫
drop database if exists 庫名 cascode;
參考鏈接:https://blog.csdn.net/shida1009/article/details/78789741
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/4571.html
標籤:大數據