我有以下熊貓資料框:
import numpy as np
import pandas as pd
import plotly.express as px
df1 = pd.DataFrame({'Name_City': ['Paris', 'Rio', 'Madri',
'Lisboa', 'Santiago', 'Toronto',
'Porto', 'Rio', 'Paris',
'Paris', 'Paris', 'Rio',
'Lisboa', 'Lisboa', 'Lisboa',
'Lisboa', 'Rio', 'Madri'],
'First': ['P', 'R', 'M', 'L', 'S', 'T', 'P', 'R', 'P',
'P', 'P', 'R', 'L', 'L', 'L', 'L', 'R', 'M']})
print(df1)
Name_City First
Paris P
Rio R
Madri M
Lisboa L
Santiago S
Toronto T
Porto P
Rio R
Paris P
Paris P
Paris P
Rio R
Lisboa L
Lisboa L
Lisboa L
Lisboa L
Rio R
Madri M
首先,我想計算每個城市在資料框中出現的次數,所以我做了:
series = df1['Name_City'].value_counts()
df_result = pd.DataFrame(series)
df_result = df_result.reset_index()
df_result.columns = ['City', 'Total']
print(df_result)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
Toronto 1
Porto 1
注意:第一部分按預期作業。
在第二部分中,我想構建一個(餅形)圖表來表示出現次數最多的五個城市。其他出現較少的城市我想在圖表上顯示為“其他”。
我嘗試執行以下操作:
df_result_part = df_result.head(5)
print(df_result_part)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
fig = px.pie(df_result_part,
values='Total',
names='City')
fig.show()
我需要將出現最少的那些分組并將它們命名為“其他”。我想問我怎樣才能自動做到這一點?
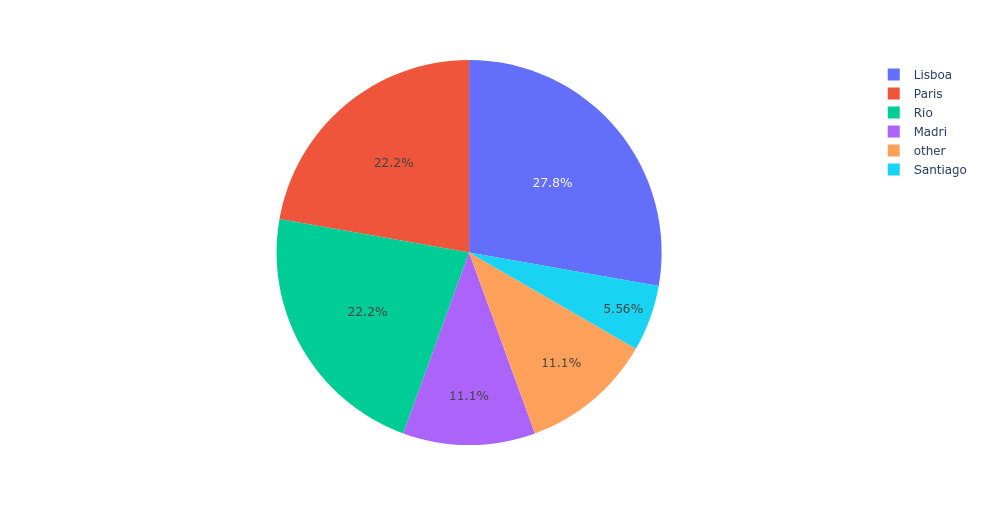
所需的輸出是:
print(df_desired)
City Total
Lisboa 5
Rio 4
Paris 4
Madri 2
Santiago 1
Others 2
fig = px.pie(df_desired,
values='Total',
names='City')
fig.show()
uj5u.com熱心網友回復:
從 開始df_result,您可以選擇第五行之后的行并將所有城市名稱替換為“其他”。這將始終有效,因為默認情況下value_counts回傳其輸出是排序順序(減少計數):
df_result.loc[5:, 'City'] = 'other'
import plotly.express as px
fig = px.pie(df_result,
values='Total',
names='City')
輸出:
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/459185.html