4.1 字典資料結構
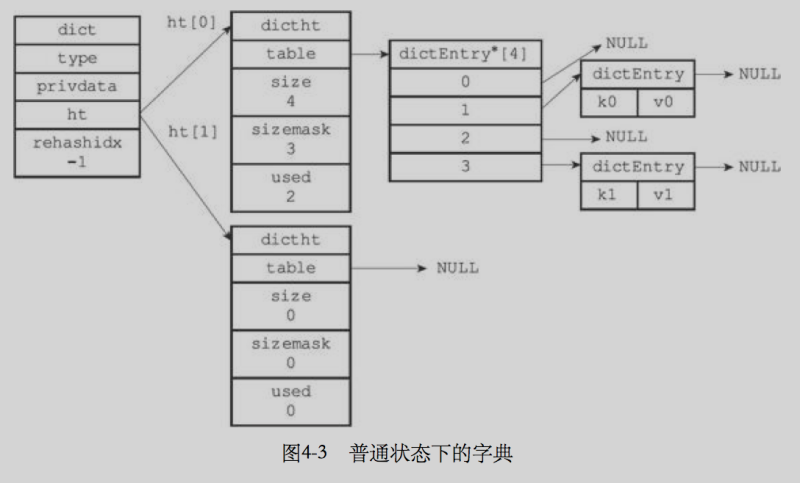
typedef struct dict{
//型別特定函式
dictType *type;
//私有資料
void *privateata;
//哈希表
dictht ht[2];
//rehash 索引,rehash未進行時,值為-1
int rehashidx;
}dict;
- 其中的type 是一個指向 dictType 結構的指標,每個 dictType 結構保存了一簇用于操作特定型別鍵值對的函式,Redis 會為用途不同的字典設定不同的型別特定函式,
typedef struct dictType{
//計算哈希值的函式
unsigned int (*hashFunction)(const void *key);
//復制鍵的函
void *(*keyDup)(void *privdata, const void *key);
//復制值的函式
void *(*valDup)(void *privdata, const void *obj);
//對比鍵的函
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
//銷毀鍵的函式
void (*keyDestructor)(void *privdata, void *key);
//銷毀值的函式
void (*valDestructor)(void *privdata, void *obj);
}dictType;
- privdata屬性則保存了需要傳給那些型別特定函式的可選引數,
- ht是一個包含兩個項的陣列,陣列中的每項都是dictht哈希表,一般情況下,字典只是用 ht[0]哈希表,ht{1]只有在對ht[0]哈希表進行rehash時使用
// Redis 字典使用的哈希表由 dict 標識,Redis的字典使用哈希表作為底層實作,
//一個哈希表里面可以有多個哈希表節點,而每個哈希表節點就保存了字典中的一個鍵值對,
typedef struct dictht {
//哈希表陣列
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩碼,用于計算索引值,總是等于size-1
unsigned long sizemask;
//該哈希表已有節點的數量
unsigned long used;
}dictht;
//哈希表節點用dictEntry標識,每個dictEntry保存了一個鍵值對
typedef struct dictEntry {
//鍵
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
} v;
//指向下個哈希表節點,形成鏈表,解決地址沖突問題
struct dictEntry *next;
} dictEntry;
-
rehashidx記錄了rehash目前的進度,如果目前沒有在進行rehash,那么它的值為-1,
4.2 哈希演算法
當要將一個新的鍵值對添加到字典時,程式需要根據鍵值對的鍵計算出哈希值和索引值,然后根據索引值,將包含鍵值對的哈希節點放到哈希表陣列的指定索引上,
Redis計算哈希值和索引值的方法如下:
#使用字典設定的哈希函式,計算哈希值
hash = dict -》 type -》 hashFunction(key)
#使用哈希表的sizemask 屬性和哈希值hash,計算出索引值
#根據情況不同,ht[x] 可以是 ht[0] 或 ht[1]
index = hash & dictht -> ht[x].sizemask
當字典被用作資料庫的底層實作或哈希鍵的底層實作時,Redis 使用的是 Murmurhash2 演算法來計算hash 值,
4.3 解決鍵沖突
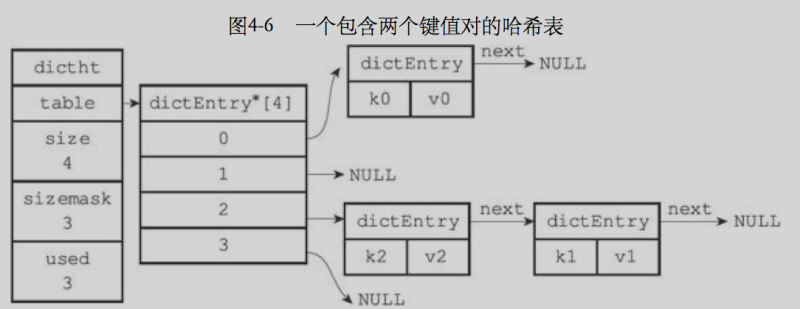
Redis 使用鏈地址法來解決鍵沖突,每個哈希表節點有一個next指標,多個哈希表節點通過next 指標構成一個單向鏈表,因為 dictEntry 節點組成的鏈表沒有指向鏈表表尾的指標,所以為了速度考慮,總是將新節點添加到鏈表的表頭位置(復雜度為O(1)),排在其他已有節點前面,(k2,v2)是新添加的節點,
4.4 rehash
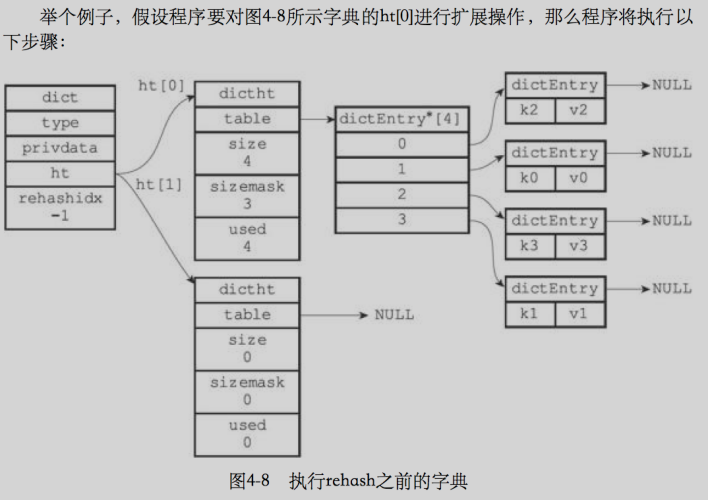
隨著操作的不斷執行,哈希表保存的鍵值對會逐漸的增多或減少,為了讓哈希表的負載因子維持在一個合理的閾值之內,當哈希表的鍵值對的數量太多或太少時,對哈希表進行相應的擴展或收縮,
擴展和收縮哈希表通過rehash(重新散列)進行,具體步驟如下
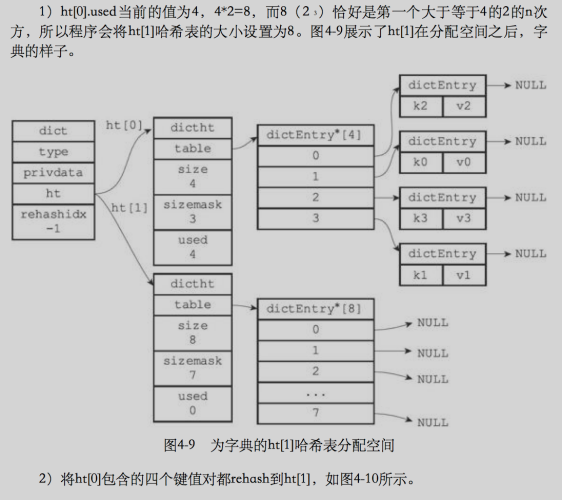
- 為字典ht[1]分配空間,這個哈希表空間大小取決于要執行的操作,以及ht[0]當前包含的鍵值對的數量(也就是ht[0].used屬性)
- 擴展操作:ht[1]的大小為第一個大于等于ht[0].used * 2 的 2^n(2的n次冪)
- 收縮操作:ht[1]的大小為第一個大于等于ht[0].used 的 2^n
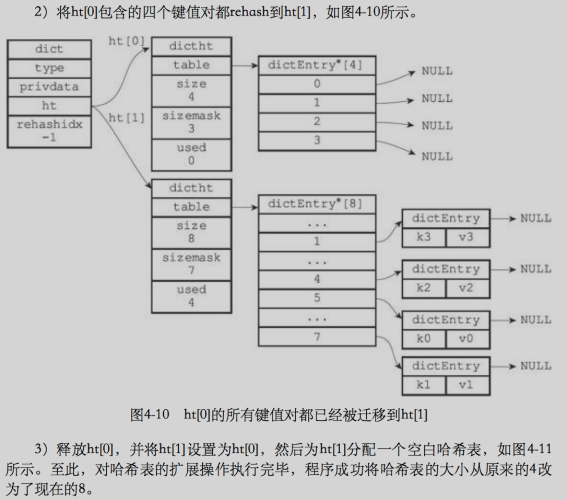
- 將保存在ht[0]中的所有鍵值對 rehash 到 ht[1]上面:rehash 是指重新計算鍵的哈希值和索引值,然后將鍵值對放到 ht[1]哈希表的指定位置
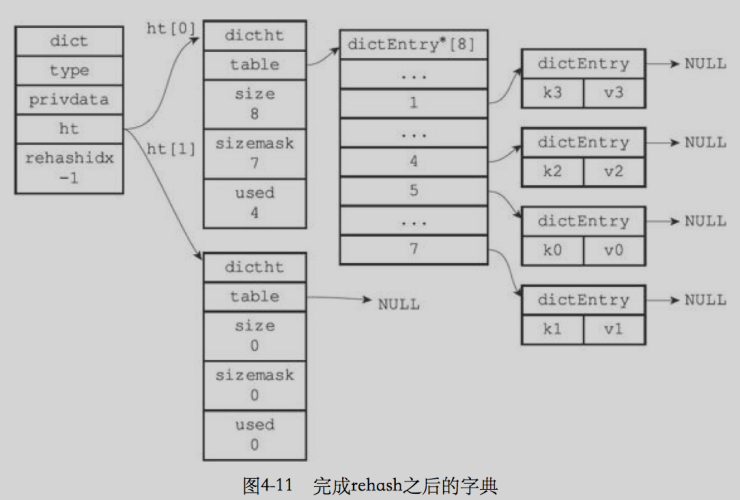
- 當ht[0]全部遷移到ht[1]后,釋放ht[0],將ht[1] 設定為 ht[0],并在 ht[1]上新建一個空白哈希表,為下一次 rehash 做準備,
4.5 漸進式rehash
為了避免鍵值對過多的 rehash(涉及到龐大的計算量) 對服務器性能造成影響,服務器不是一次將ht[0] 上的所有鍵值對 rehash 到 ht[1],而是分多次、漸進式的將 ht[0] 里所有的鍵值對進行遷移,
漸進式hash 的步驟:
- 為ht[1]分配空間,讓字典同時持有 ht[0] ht[1]
- 在字典中維持一個索引計數器變數 rehashidx,并將其設定為0,標識 rehash 開始
- 在 rehash 期間,每次對字典的添加、洗掉、查找或更新等,程式除了執行指定的操作外,還會將ht[0] 哈希表在 rehashidx 索引上的所有鍵值對 rehash 到 ht[1] 上,當rehash 完成后,程式將 rehashidx 值加一,
- 最終,ht[0]全部 rehash 到 ht[1] 上,這時程式將 rehashidx 值設定為 -1,標識 rehash 完成
漸進式rehash 將rehash 的作業均攤到每個添加、洗掉、查找和更新中,從而避免集中rehash帶來的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/4597.html
標籤:NoSQL
上一篇:redis 6.0 redis-cluster-proxy集群代理嘗試
下一篇:Mongodb 之 oplog