Cassandra是云原生和微服務化場景中最好的NoSQL資料庫,我信了~

1. Cassandra是什么
高可用性和可擴展的分布式資料庫
Apache Cassandra™是一個開源分布式資料,可提供當今最苛刻的應用程式所需的高可用性、高性能和線性可伸縮性,它提供了跨云服務提供商、資料中心和地理位置的操作簡便性和輕松的復制,并且可以在混合云環境中每秒處理PB級資訊和數千個并發操作,
在Hadoop關聯的專案中對Cassandra的解釋是:A scalable multi-master database with no single points of failure.
可以看出,高可用性和高可伸縮性是Cassandra最閃亮的特點,沒有單點故障,
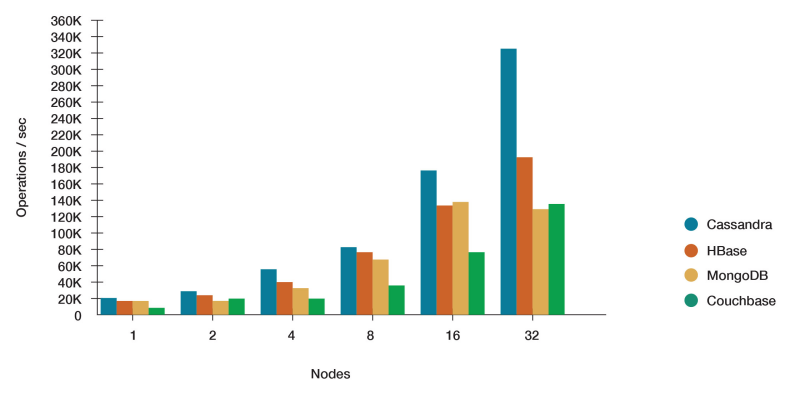
2. Cassandra vs. MongoDB vs. Couchbase vs. HBase
Apache Cassandra™在高負載下提供了更高的性能,在許多用場景中都超過了它的NoSQL資料庫競爭對手,
Apache Cassandra: 高度可伸縮、高性能的分布式資料庫,設計用于處理許多商用服務器上的大量資料,提供高可用性,沒有單點故障,
Apache HBase: 基于谷歌的BigTable的開源、非關系型、分布式資料庫,是用Java撰寫的,它是Apache Hadoop專案的一部分,在HDFS上運行,為Hadoop提供類似于BigTable的功能,
MongoDB: 跨平臺的面向檔案的資料庫系統,避開了傳統的基于表的關系資料庫結構,轉而使用具有動態模式的類JSON檔案,從而使資料在某些型別的應用程式中的集成更加容易和快捷,
Couchbase: 為互動式應用程式優化的分布式NoSQL面向檔案的資料庫,
3. 架構簡介
Cassandra被設計用來處理跨多個節點的大資料作業負載,沒有單點故障,Cassandra通過采用跨同構節點的對等分布式系統來解決故障問題,其中資料分布在集群中的所有節點中,每個節點使用點對點gossip通信協議頻繁地交換自己和集群中其他節點的狀態資訊,每個節點上按順序寫入的提交日志被捕獲寫入活動,以確保資料的持久性,然后,資料被編入索引并寫入記憶體結構,稱為memtable,它類似于回寫快取,每次記憶體結構滿了,資料就被寫到一個SSTables資料檔案的磁盤上,所有寫操作都會自動磁區并在整個集群中復制,Cassandra定期使用一個稱為壓縮的行程合并SSTables,丟棄用tombstone標記為要洗掉的過時資料,為了確保集群中的所有資料保持一致,需要使用各種修復機制,
Cassandra是一個磁區的行存盤資料庫,其中行被組織成具有所需主鍵的表,Cassandra的體系結構允許任何授權用戶連接到任何資料中心中的任何節點,并使用CQL語言訪問資料,為了易于使用,CQL使用與SQL類似的語法并處理表資料,通常,集群中的每個應用程式都有一個鍵空間,由許多不同的表組成,
客戶端讀或寫請求可以發送到集群中的任何節點,當客戶端使用請求連接到某個節點時,該節點充當該特定客戶端操作的協調器,協調器充當客戶端應用程式和擁有所請求資料的節點之間的代理,協調器根據集群的配置方式確定環形中的哪些節點應該獲得請求,
3.1. 核心結構
• Node
存盤資料的地方,它是Cassandra的基礎設施組件
• datacenter
相關節點的集合,資料中心可以是物理資料中心,也可以是虛擬資料中心,不同的作業負載應該使用單獨的資料中心,無論是物理的還是虛擬的,復制由資料中心設定,使用單獨的資料中心可以防止Cassandra事務受到其他作業負載的影響,并使請求彼此接近以降低延遲,根據復制因子,可以將資料寫入多個資料中心,資料中心絕不能跨越物理位置,
• Cluster
一個集群包含一個或多個資料中心,它可以跨越物理位置,
• Commit log
為了持久性,所有資料寫入之前都要首先寫入提交日志(日志寫入優先),所有資料都重繪到SSTables之后,就可以對其進行歸檔、洗掉或回收,
• SSTable(Sorted String Table)
一個SSTable是一個不可變的資料檔案,Cassandra定期將memtables寫入其中,僅追加SSTables并按順序存盤在磁盤上,并為每個Cassandra表維護SSTables,
• CQL Table
按表行獲取的有序列的集合,一張表由多列組成,并且有一個主鍵,
3.2. 核心組件
• Gossip
一種對等通信協議,用于發現和共享Cassandra集群中其他節點的位置和狀態資訊,Gossip息也由每個節點本地保存,以便在節點重新啟動時立即使用,
• Partitioner
磁區程式確定哪個節點將接收一段資料的第一個副本,以及如何跨集群中的其他節點分發其他副本,每一行資料都由一個主鍵唯一地標識,主鍵可能與其磁區鍵相同,但也可能包含其他集群列,Partitioner是一個哈希函式,它從一行的主鍵派生標記,磁區程式使用令牌值來確定集群中的哪些節點接收該行的副本,Murmur3Partitioner是新Cassandra集群的默認磁區策略,幾乎在所有情況下都是新集群的正確選擇,
• Replication factor
整個集群中的副本總數,副本因子1表示在一個節點上每一行只有一個副本,副本因子2表示每一行有兩個副本,其中每個副本位于不同的節點上,所有的副本都同樣重要,沒有主副本,你可以為每個資料中心定義副本因子,通常,應該將副本策略設定為大于1,但不超過集群中的節點數,
• Replica placement strategy
Cassandra將資料的副本存盤在多個節點上,以確保可靠性和容錯能力,副本策略決定將副本放在哪個節點上,資料的第一個副本就是第一個副本,它在任何意義上都不是唯一的,強烈建議使用NetworkTopologyStrategy策略,因為在將來需要擴展時,可以輕松擴展到多個資料中心,創建keyspace時,必須定義副本放置策略和所需的副本數,
• Snitch
snitch將一組機器定義為資料中心和機架(拓撲),副本策略使用這些資料中心和機架放置副本,
在創建集群時,必須配置一個snitch,所有的snitch都使用一個動態的snitch層,該層監視性能并選擇最佳副本進行讀取,它是默認啟用的,建議在大多數部署中使用,在cassandra.yaml組態檔中為每個節點配置動態snitch閾值,
• cassandra.yaml
用于設定集群的初始化屬性、表的快取引數、調優和資源利用率的屬性、超時設定、客戶端連接、備份和安全性的主要組態檔,
4. 安裝
將Cassandra倉庫添加到yum源中
新建檔案/etc/yum.repos.d/cassandra.repo 并粘貼以下內容:
[cassandra] name=Apache Cassandra baseurl=https://downloads.apache.org/cassandra/redhat/311x/ gpgcheck=1 repo_gpgcheck=1 gpgkey=https://downloads.apache.org/cassandra/KEYS
執行yum install命令:
yum install cassandra
安裝完以后就是cassandra服務了
# 啟動服務
service cassandra start|status|stop
systemctl start|status|stop cassandra
# 開機啟動
chkconfig cassandra on
命令列直接輸入cqlsh即可連接到本地cassandra資料庫,就像直接輸入mysql回車一樣
5. 資料磁區
Apache Cassandra是一個開源的分布式NoSQL資料庫,它提供了具有最終一致語意的磁區寬列存盤模型,
Cassandra的設計目標:
- 完全多主資料庫副本
- 低延遲的全域可用性
- 擴展到商用硬體
- 每增加一個處理器,線性吞吐量就會增加
- 在線負載平衡和集群增長
- 磁區key-oriented查詢
- 靈活的schema
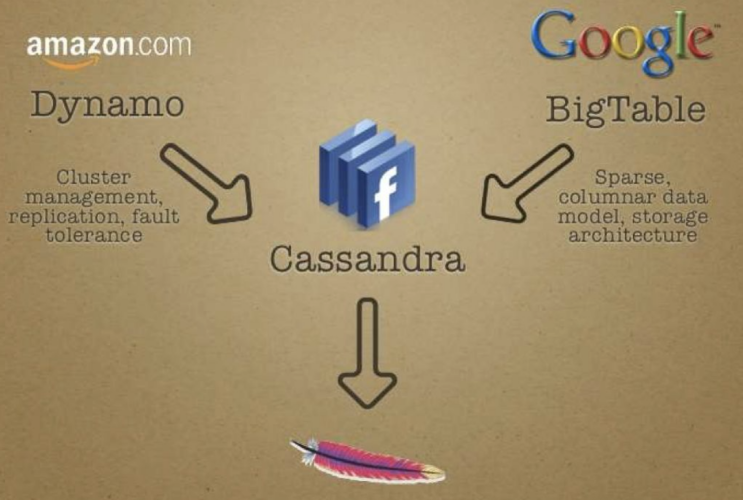
Apache Cassandra依賴于Amazon Dynamo分布式存盤鍵值系統的多種技術,Dynamo系統的每個節點有三個主要組成部分:
- 在磁區資料集上請求協調
- 環的成員和故障檢測
- 一個本地存盤引擎
Cassandra主要使用前兩個集群組件,同時使用基于日志結構合并樹(LSM)的存盤引擎,特別地,Cassandra使用Dynamo風格:
- 使用一致哈希的資料集磁區
- 使用版本化資料和可調一致性的多主(multi-master)復制
- 通過gossip協議進行分布式集群成員和故障檢測
- 商用硬體的增量橫向擴展
Cassandra以這種方式設計,可以滿足大規模(PB級資料)關鍵業務存盤要求,
Cassandra不僅吸收了Dynamo論文中的如何做分布式,如何做副本復制,故障容錯等方面成功的經驗,又吸取了Google Bigtable中的LSM單機引擎層面精華,理論扎實,工程實作靠譜,所以面世以來,不斷受到人們的追捧,
5.1. 資料集磁區:一致性哈希
Cassandra通過使用哈希函式對存盤在系統中的所有資料進行磁區來實作水平可伸縮性,每個磁區被復制到多個物理節點,通常跨機架甚至資料中心,
使用一個令牌環的一致性哈希
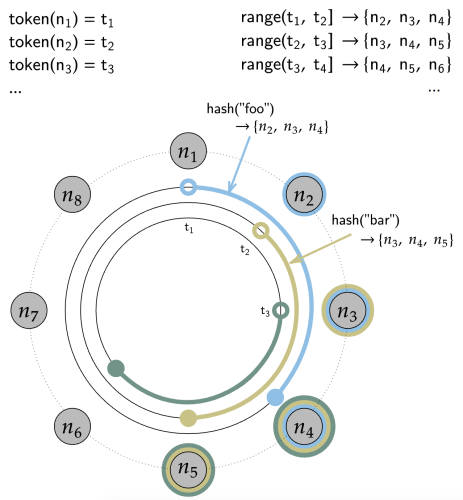
Cassandra將每個節點映射到連續哈希環上的一個或多個token(令牌),并通過將key哈希到環上然后沿一個方向“遍歷”環來決定key應該放在什么位置,類似于Chord演算法,一致性哈希與原始資料哈希的主要區別在于,當要哈希到的節點(桶)數量發生變化時,一致哈希只需移動一小部分key,
例如,如果我們有一個8個節點的集群,每個節點都有均勻間隔的token(令牌),并且副本因子(RF)為3,那么要找到一個key的所屬節點,我們首先對該key進行哈希以生成一個token(即key的hash),然后沿順時針方向“walk”(走,遍歷),直到遇到三個不同的節點,這時我們找到了該key的所有副本,這個程序可以用下圖表示:
每個物理節點有多個令牌
如果你許多物理節點來分散資料,則簡單的單令牌一致哈希可以很好地作業,但是如果令牌間隔均勻而物理節點數量很少,此時如果新增一個節點的話就沒有令牌可選,以使環保持平衡,Cassandra試圖避免令牌不平衡,因為令牌范圍不均衡會導致請求負載不均衡, 例如,在前面的示例中,無法在不引起不平衡的情況下添加第九個令牌,
Dynamo論文中提倡使用“虛擬節點”來解決這種不平衡問題,虛擬節點通過將令牌環中的多個令牌分配給每個物理節點來解決該問題,通過允許單個物理節點在環中占據多個位置,我們可以使小型集群看起來更大,因此即使添加單個物理節點,我們也可以使其看起來像我們添加了更多節點,
Cassandra引入了一些術語來處理這些概念:
- Token:dynamo風格的哈希環上的單個位置
- Endpoint:網路上的單個物理IP和埠
- Host ID:單個“物理”節點的唯一識別符號,通常存在于一個端點并包含一個或多個令牌
- Virtual Node:哈希環上的一個令牌,由具有相同的主機ID的相同的物理節點擁有
從Tokens到Endpoints的映射形成了Token Map,Cassandra以此來會跟蹤哪些環位置映射到哪些物理端點,
例如,在下圖中,通過為每個節點分配兩個令牌,我們可以僅使用4個物理節點來表示8個節點的集群:
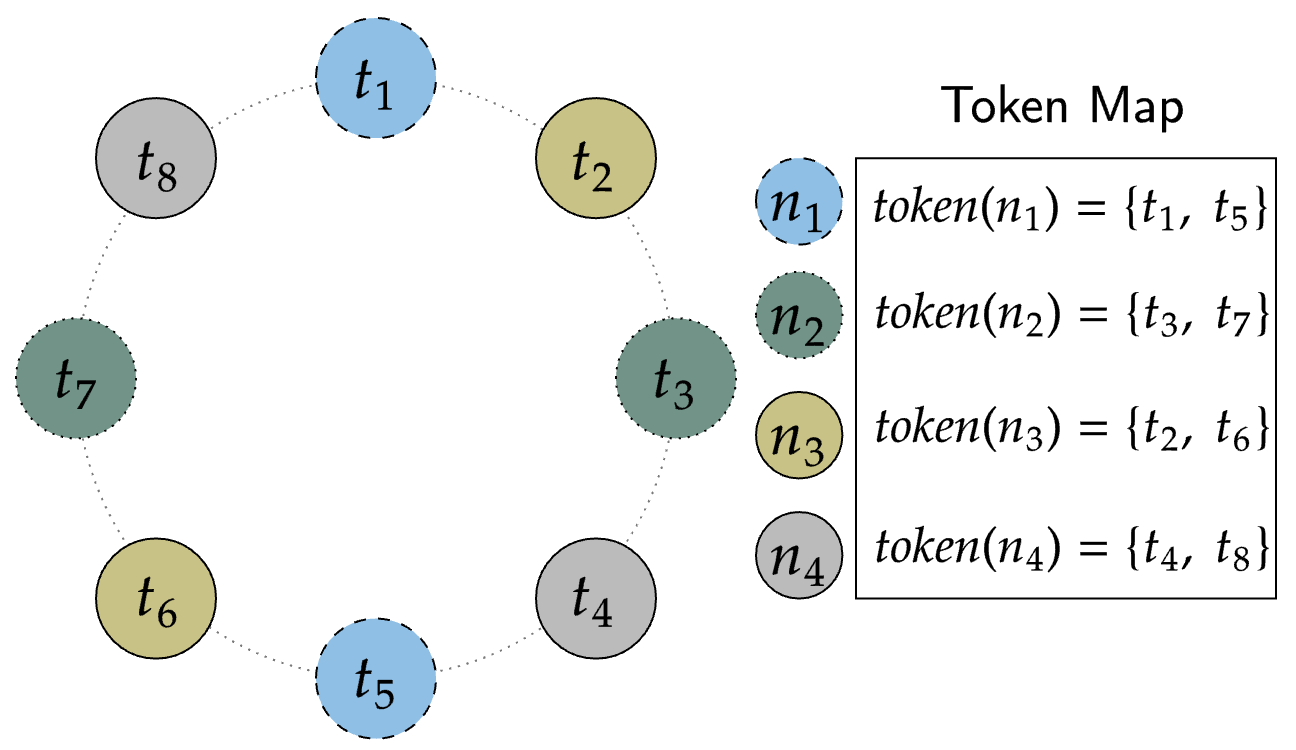
說了這么多,什么意思呢?簡單的回顧一下:
token代表哈希環(hash ring)上的一個位置,這這個環上,兩個token之間有一個區間范圍,這也是key的范圍或者理解為哈希值的區間范圍,從token到node的映射被稱之為Token Map,
上面第一幅圖中,描述的是假設你有足夠的物理機,再假設副本因子是3,那么1節點對應1個token,這樣就是8個節點8個token,形成了如下區間范圍:
(t1,t2] -> {n2,n3,n4}
(t2,t3] -> {n3,n4,n5}
(t3,t4] -> {n4,n5,n6}
(t4,t5] -> {n5,n6,n7}
(t5,t6] -> {n6,n7,n8}
(t6,t7] -> {n7,n8,n1}
(t7,t8] -> {n8,n1,n2}
(t8,t1] -> {n1,n2,n3}
假設hash("foo")落在了(t1,t2]區間,那么該key的3個副本放置的位置應該是n2,n3,n4
此時,如果我要新加一個節點n9,就沒有token可選了
如果物理機不夠怎么辦呢?
假設物理機只有4臺,但是token的范圍區間是固定的,那么4個節點8個token,為了保持平衡,必須1個節點對應2個token
為了保持平衡,只能將虛擬節點均勻分布在物理節點之間,因為是按順時針方向往前走的,資料最侄訓是要放到物理節點上的
于是形成了如下區間范圍:
(t1,t2] -> {n1,n2,n3}
(t2,t3] -> {n2,n3,n4}
(t3,t4] -> {n3,n4,n1}
(t4,t5] -> {n4,n1,n2}
(t5,t6] -> {n1,n2,n3}
(t6,t7] -> {n2,n3,n4}
(t7,t8] -> {n3,n4,n1}
(t8,t1] -> {n4,n1,n2}
每個物理節點對應兩個token的好處:
- 當添加一個新節點時,它從環中的其他節點接收大約相同數量的資料,從而使資料在集群中均勻分布,
- 當洗掉一個節點時,它丟失的資料與環中的其他成員丟失的資料大致相同,這再次保持了資料在集群中的均勻分布,
- 如果某個節點變得不可用,查詢負載(特別是支持令牌的查詢負載)將均勻地分布在許多其他節點上,
壞處:
- 每個令牌在令牌環上引入最多2 * (RF - 1)的其他鄰居,這意味著在令牌環的一部分失去可用性時,會出現更多的節點故障組合
- 集群范圍的維護操作通常會變慢, 例如,隨著每個節點令牌數量的增加,集群必須執行的離散修復操作的數量也會增加,
- 跨令牌范圍的操作性能可能會受到影響,
6. CAP
根據CAP定理,分布式資料存盤不可能同時提供兩個以上的以下保證:
- Consistency(一致性): 一致性意味著每次讀取都會收到最新的寫入或錯誤輸出
- Availability(可用性): 可用性意味著每個請求都會收到回應,不能保證回應中包含最新的寫入或資料,
- Partition tolerance(磁區容錯性): 磁區容錯是指存盤系統對網路磁區故障的容錯,即使某些訊息丟失或延遲,系統仍將繼續運行,
CAP定理表明,當使用網路磁區時,由于存在磁區故障的固有風險,因此必須在一致性和可用性之間進行選擇,并且不能同時保證兩者,
在基于web的應用程式中,高可用性是的優先級比較高的需求,為此,Cassandra從CAP保證中選擇可用性和磁區容錯性,在一定程度上犧牲資料一致性,
(PS:根據CAP定理,只能同時滿足兩個,而由網路磁區帶來的磁區錯誤風險是必然存在的,因此只能在CA中間選一個,Cassandra選擇了AP)
Cassandra提供以下保證:
- 高擴展性
- 高可用性
- 持久性
- 寫入單個表的最終一致性
- 具有可線性化一致性的輕量級事務
- 保證跨多個表的批量寫入完全成功或根本不成功
- 二級索引保證與其本地副本資料一致
高可擴展性
Cassandra是一個高度可擴展的存盤系統,可以根據需要添加/洗掉節點,使用基于gossip的協議,每個節點都保留一個統一且一致的成員串列,
高可用性
Cassandra通過實作容錯存盤系統來保證資料的高可用性,使用基于gossip的協議進行節點中的故障檢測,
持久性
Cassandra通過使用副本來保證資料的持久性,副本是存盤在集群中不同節點上的資料的多個拷貝,在多資料中心環境中,副本可以存盤在不同的資料中心,如果一個副本由于不可恢復的節點/資料中心故障而丟失,資料不會完全丟失,因為副本仍然可用,
最終一致性
在生產中,Cassandra滿足了性能、可靠性、可伸縮性和高可用性的要求,是一個最終一致的存盤系統,最終一致性意味著所有更新最侄訓到達所有副本,相同資料的不同版本可能暫時存在,但最侄訓協調成一致的狀態,最終的一致性是實作高可用性的折衷方案,它涉及一些讀寫延遲,
輕量級事務
資料必須按順序讀寫,Paxos協議實作了輕量級事務,能夠使用線性一致性處理并發操作,線性化一致性是與實時約束的順序一致性,它保證了比較和設定(CAS)事務的事務隔離,使用CAS副本比較資料,并將發現過期的資料設定為最一致的值,使用線性一致性讀取允許讀取資料的當前狀態(可能是未提交的),而不需要進行新的添加或更新,
批量寫入
跨多個表進行批處理寫操作的保證是,它們最侄訓成功,或者沒有成功,批處理資料首先寫入到批處理日志系統資料,當批處理資料成功地存盤在集群中時,批處理日志資料將被洗掉,批處理被復制到另一個節點,以確保在協調節點失敗的情況下完成完整的批處理,
二級索引
二級索引是列上的索引,用于查詢通常不可查詢的表,二級索引在構建時保證與它們的本地副本一致,
7. Docs
https://cassandra.apache.org/download/
https://cassandra.apache.org/doc/latest/architecture/index.html
https://www.datastax.com/products/compare/nosql-performance-benchmarks
https://docs.datastax.com/en/cassandra-oss/3.x/
https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/architecture/archDataDistributeHashing.html
https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/dml/dmlIntro.html
補充:寬表
寬表從字面意義上講就是欄位比較多的資料庫表,通常是指業務主題相關的指標、維度、屬性關聯在一起的一張資料庫表,由于把不同的內容都放在同一張表存盤,寬表已經不符合三范式的模型設計規范,隨之帶來的主要壞處就是資料的大量冗余,與之相對應的好處就是查詢性能的提高與便捷,(空間換時間)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/4606.html
標籤:NoSQL
下一篇:Redis 過期時間與記憶體管理