分享嘉賓:高大月@美團點評,Apache Kylin PMC成員,Druid Commiter
編輯整理:Druid中國用戶組 6th MeetUp
出品平臺:DataFunTalk
--
導讀: 長久以來,對SQL和權限的支持一直是Druid的軟肋,雖然社區早在0.9和0.12版本就分別添加了對SQL和Security的支持,但根據我們了解,考慮到功能的成熟度和穩定性,真正把SQL和Security用起來的用戶是比較少的,本次分享將介紹社區SQL和Security方案的原理,以及美團點評在落地這兩個功能的程序中所遇到的問題、做出的改進、和最終取得的效果,下面開始今天的分享:
我今天的分享內容包括四部分,首先,和大家介紹一下美團對Druid的使用現狀,以及我們在構建Druid平臺的程序中遇到的挑戰,第二部分,介紹Druid SQL的基本原理和使用方式,以及我們在使用Druid SQL的程序中遇到的問題和做的一些改進,第三部分,介紹Druid在資料安全上提供的支持,以及我們結合自身業務需求在Druid Security上的實踐經驗,最后,對今天的分享內容做一個總結,

--
01 Druid在美團的現狀和挑戰
1.Druid應用現狀
美團從16年開始使用Druid,集群版本從0.8發展到現在的0.12版本,線上有兩個Druid集群, 總共大概有70多個資料節點,
資料規模上,目前有500多張表,100TB的存盤,最大的表每天從Kafka攝入的訊息量在百億級別,查詢方面,每天的查詢量有1700多萬次,這里包括了一些程式定時發起的查詢,比如風控場景中定時觸發的多維查詢,性能方面,不同的應用場景會有不同的要求,但整體上TP99回應時間在一秒內的表占了80%,這和我們對Druid的定位——秒級實時OLAP引擎是一致的,
2.Druid平臺化挑戰
把Druid作為一個服務提供給業務使用的程序中,我們主要遇到了易用性、安全性、穩定性三方面的挑戰,
易用性:業務會關心Druid的學習和使用成本有多高,是否能很快接入,大家知道,Druid本身對資料寫入和查詢只提供了基于JSON的API介面,你需要去學習介面的使用方法,了解各種欄位的含義,使用成本是很高的,這是我們希望通過平臺化去解決的問題,

安全性:資料是很多業務的核心資產之一,業務非常關心Druid服務能否保障他們的資料安全,Druid較早的版本對安全的支持較弱,因此這一塊也是我們去年重點建設的部分,
穩定性:一方面需要解決開源系統落地程序中出現的各種穩定性問題,另一方面,如何在查詢邏輯不可控的情況下,在一個多租戶的環境中定位和解決問題,也是很大的挑戰,

--
02 Druid SQL的應用和改進
在Druid SQL出現之前,Druid查詢通過基于JSON的DSL來表達(下圖),這種查詢語言首先學習成本很高,用戶需要知道Druid提供了哪些queryType,每種queryType需要傳哪些引數,如何選擇合適的queryType等,其次是使用成本高,應用需要實作JSON請求的生成邏輯和回應JSON的決議邏輯,

通過Druid SQL,你可以將上面的復雜JSON寫成下面的標準SQL,SQL帶來的便利是顯而易見的,一方面對于程式員和資料分析師沒有額外的學習成本,另一方面可以使用類似JDBC的標準介面,大大降低了門檻,
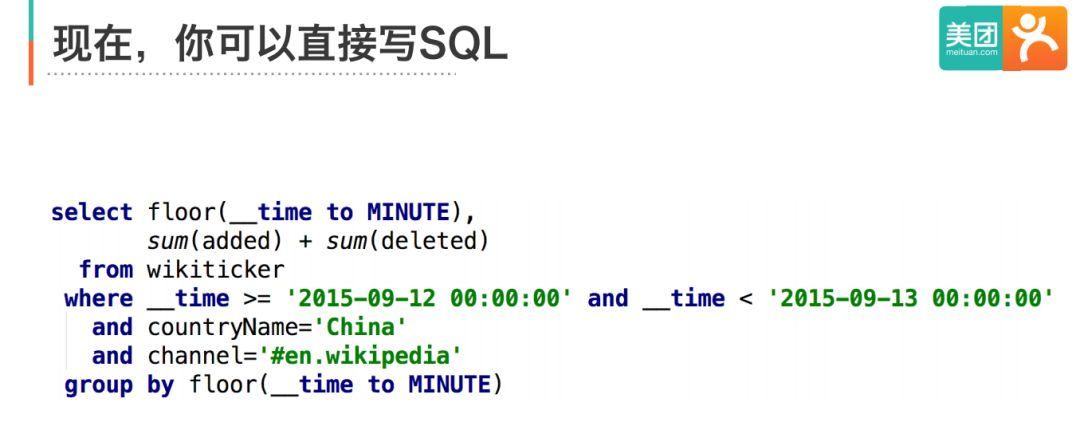
1.Druid SQL簡介
下面我簡單地介紹一下Druid SQL,

首先,Druid SQL是0.10版本新增的一個核心模塊,由Druid社區提供持續的支持和優化,因此不管是穩定性還是完善性,都會比其他給Druid添加SQL方言的專案更好,
從原理上看,Druid SQL主要實作了從SQL到原生JSON查詢語言的翻譯層,由于只是做了一層語言的翻譯,好處是Druid SQL對集群的穩定性和性能不會有很大影響,缺點是受限于原生JSON查詢的能力,Druid SQL只實作了SQL功能的一個子集,
呼叫方式上,Druid SQL提供了HTTP和JDBC兩種方式來滿足不同應用的需求,最后表達力上,Druid SQL幾乎能表達所有JSON查詢能實作的邏輯,并且它能自動幫你選擇最合適的queryType,
下面是三個Druid SQL的例子,

第一個例子是近似TopN查詢,對于根據某個指標分析單個維度TopN值的需求,原生的JSON查詢提供了一種近似TopN演算法的實作,Druid SQL能夠識別出這種模式,生成對應的近似TopN查詢,
第二個例子是半連接,我們知道Druid是不支持靈活JOIN的,但業務經常會有這樣的需求,就是以第一個查詢的結果作為第二個查詢的過濾條件,用SQL表達的話就是in subquery,或者半連接,Druid SQL對這種場景做了特殊支持,用戶不需要在應用層發起多個查詢,而是寫成in subquery的形式就行了,Druid SQL會先執行子查詢,將結果物化成外層查詢過濾條件,然后再執行外層的查詢,
最后是一個嵌套GroupBy的例子,Druid SQL能夠識別出這種多層的GroupBy結構,生成對應的原生嵌套GroupBy JSON ,
2.Druid SQL架構
下面介紹Druid SQL的整體架構,
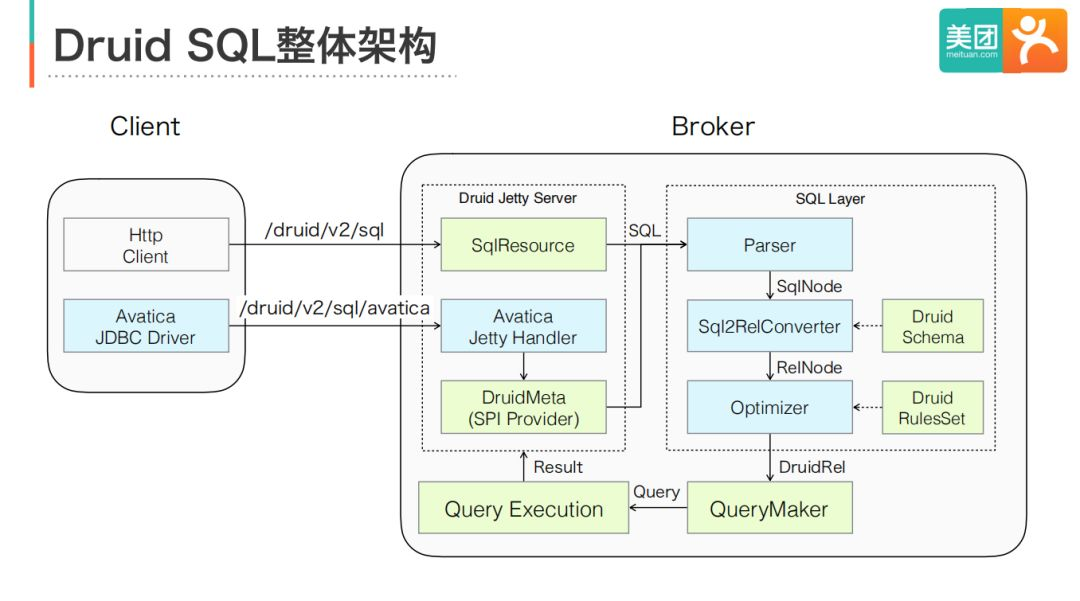
Druid SQL是在查詢代理節點Broker中實作的功能,主要包含Server和SQL Layer兩個模塊,
Server模塊負責接收和決議請求,包括HTTP和JDBC兩類 ,對于普通的HTTP請求,新增相應的REST Endpoint即可,對于JDBC,Druid復用了Avatica專案的JDBC Driver和RPC定義,因此只需要實作Avatica的SPI就行了,由于Avatica的RPC也是基于HTTP的,因此兩者可以使用同一個Jetty Server,
SQL Layer負責將SQL翻譯成原生的JSON查詢,是基于Calcite專案實作的,Calcite是一個通用的SQL優化器框架,能夠將標準SQL決議、分析、優化成具體的執行計劃,在大資料領域得到了廣泛的使用,圖中淺綠色的組件是Calcite提供的,淺藍色的組件是Druid實作的,主要包括三個,
首先,DruidSchema組件為Calcite提供查詢決議和驗證需要的元資料,例如集群中包含哪些表,每張表各個欄位的名稱和型別等資訊,RulesSet組件定義了優化器使用的轉換規則,由于Druid SQL只做語言翻譯,因此這里都是一些邏輯優化規則(例如投影消除、常量折疊等),不包含物理優化,通過RulesSet,Calcite會將邏輯計劃轉成DruidRel節點,DruidRel包含了查詢的所有資訊,最后,QueryMaker組件會嘗試將DruidRel轉成一個或多個原生JSON查詢,這些JSON查詢最終提交到Druid的QueryExecution模塊執行,
3.API選擇: HTTP or JDBC
Druid SQL提供了HTTP和JDBC兩種介面,我應該用哪個?我們的經驗是,HTTP適用于所有編程語言,Broker無狀態,運維較簡單;缺點是客戶端處理邏輯相對較多,JDBC對于Java應用更友好,但是會導致Broker變成有狀態節點,這點在做復雜均衡時需要格外注意,另外JDBC還有一些沒有解決的BUG,如果你使用JDBC介面,需要額外關注,

4.改進
下面介紹我們對Druid SQL做的一些改進,
第一個改進是關于Schema推導的性能優化,我們知道Druid是一個schema-less系統,它不要求所有的資料的schema相同,那如何定義Druid表的schema呢?社區的實作方式是:先通過SegmentMetadataQuery計算每個segment的schema,然后合并segment schema得到表的segment,最后在segment發生變化時重新計算整個表的schema,
社區的實作在我們的場景下遇到了三個問題,第一是Broker啟動時間過長,我們一個集群有60萬個segment,測驗發現光計算這些segment的schema就需要半小時,這會導致Broker啟動后,需要等半個小時才能提供服務,第二個問題是Broker需要在記憶體中快取所有Segment的元資料,導致常駐記憶體增加,另外schema重繪會帶來很大的GC壓力,第三個問題是,社區方案提交的元資料查詢量級與Broker和Segment個數的乘積成正比的,因此擴展性不好,

針對這個問題,我們分析業務需求和用法后發現:首先schema變更是一個相對低頻的操作,也就是說大部分segment的schema是相同的,不需要去重復計算,另外,絕大數情況業務都只需要用最新的schema來查詢,因此,我們的解決方案是,只使用最近一段時間,而不是所有的segment來推導schema,改造后,broker計算schema的時間從半小時降低到了20秒,GC壓力也顯著降低了,

第二個優化是關于日志和監控,請求日志和監控指標是我們在運維程序中重度依賴的兩個工具,比如慢查詢的定位、SLA指標的計算、流量回放測驗等都依賴日志和監控,但是0.12版本的SQL既沒有請求日志,也沒有監控指標,這是在上線前必須要解決的問題,我們的目標有兩個:首先能記錄所有SQL請求的基本資訊,例如請求時間、用戶、SQL內容,耗時等;其次能將SQL請求和原生的JSON查詢關聯起來,因為執行層面的指標都是JSON查詢粒度的,我們需要找到JSON查詢對應的原始SQL查詢,
我們的解決方案已經合并到0.14版本,首先,我們會給每個SQL請求分配唯一的sqlQueryId,然后我們擴展了RequestLogger介面,添加了輸出SQL日志的方法,下圖是一個例子,對于每個SQL請求,除了輸出SQL內容外,也會輸出它的sqlQueryId,可以用來與客戶端的日志做關聯,還會輸出SQL對應的每個JSON查詢的queryId,可以用來和JSON查詢做關聯分析,

第三個改進雖然比較小,但是對服務的穩定性很重要,我們知道,JSON查詢要求用戶指定查詢的時間范圍,Druid會利用這個范圍去做磁區裁剪,這對提高性能非常重要,但是Druid SQL并沒有這方面的限制,用戶寫SQL經常會忘記加時間范圍的限定,從而導致全表掃描,占用大量的集群資源,是一個很大的風險,所以我們添加了對where條件的檢查,如果用戶沒有指定時間戳欄位的過濾條件,查詢會直接報錯,

--
03 Druid Security的實踐經驗
首先介紹我們在資料安全上面臨的問題,當時使用的是0.10版本,這個版本在資料安全上沒有任何的支持,所有的API都沒有訪問控制,任何人都能訪問甚至洗掉所有的資料,這對業務的資料安全來說是一個非常大的隱患,
我們希望實作的目標有五點:所有API都經過認證、實作DB粒度的權限控制、所有資料訪問都有審計日志、業務能平滑升級到安全集群、對代碼的改動侵入性小,
為了實作這些目標,我們首先調研了Druid在后續版本中新增的安全功能,
1.Druid Security 功能和原理
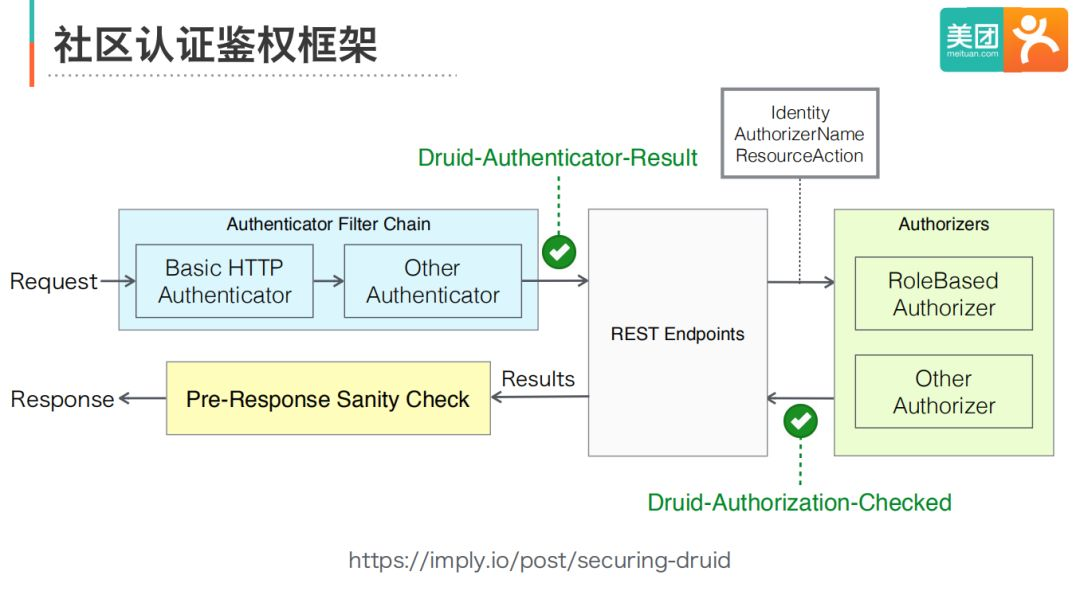
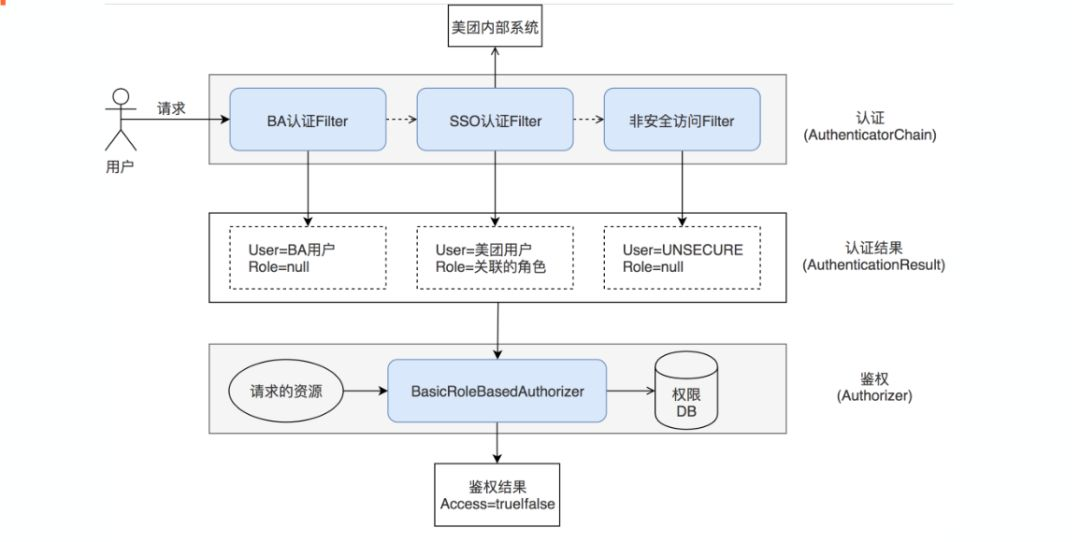
0.11版本支持了端到端的傳輸層加密(TLS),能夠實作客戶端到集群,以及集群各個節點之間的傳輸層安全,0.12版本引入了可擴展的認證和鑒權框架,并且基于這個框架,提供了BA和Kerberos等認證方式,以及一個基于角色的鑒權模塊,

下面這張圖介紹認證鑒權框架的原理和配置,

2.Druid Security社區方案缺點
社區方案能滿足我們大部分的需求,但還存在一些問題,

第一個問題是我們發現瀏覽器對BA認證的支持很差,因此對于Web控制臺,我們希望走統一的SSO認證,
第二個問題是為了支持業務平滑過渡到安全集群,上線初期必須兼容非認證的請求,當時我們使用的0.12版本沒有該功能,
第三個問題是社區基于角色的鑒權模塊只提供了底層的管理API,用戶直接使用這些API非常不方便,
最后一個問題是社區還不支持審計日志,
針對這些問題,我們做了三個主要的改進,
3.改進
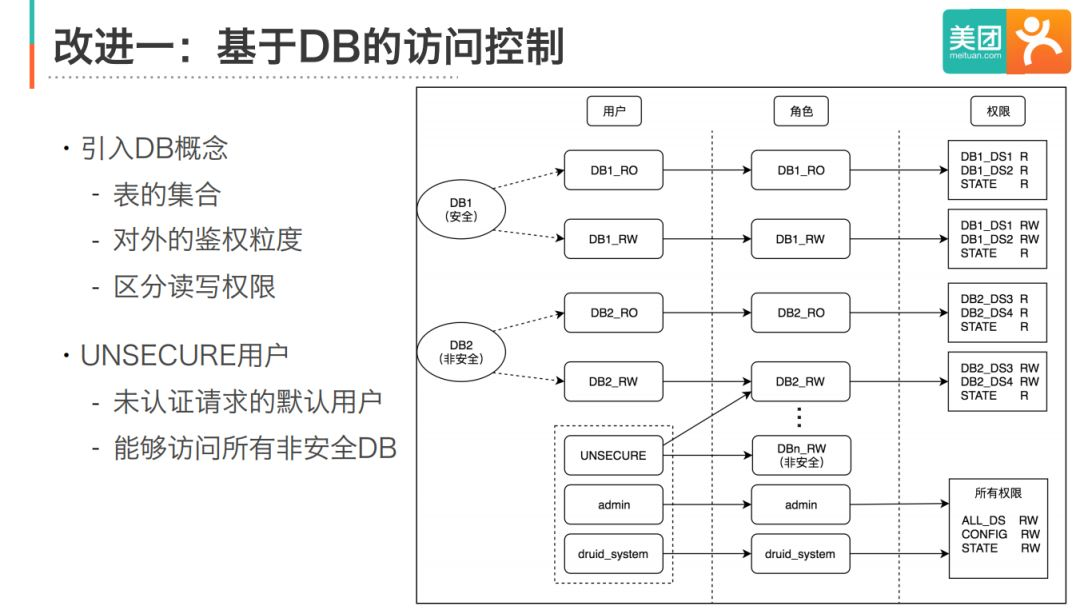
改進一:基于DB的訪問控制
首先,為了簡化權限的管理,我們引入了DB的概念,并實作了DB粒度的訪問控制,業務通過DB的讀寫賬號訪問DB中的表,
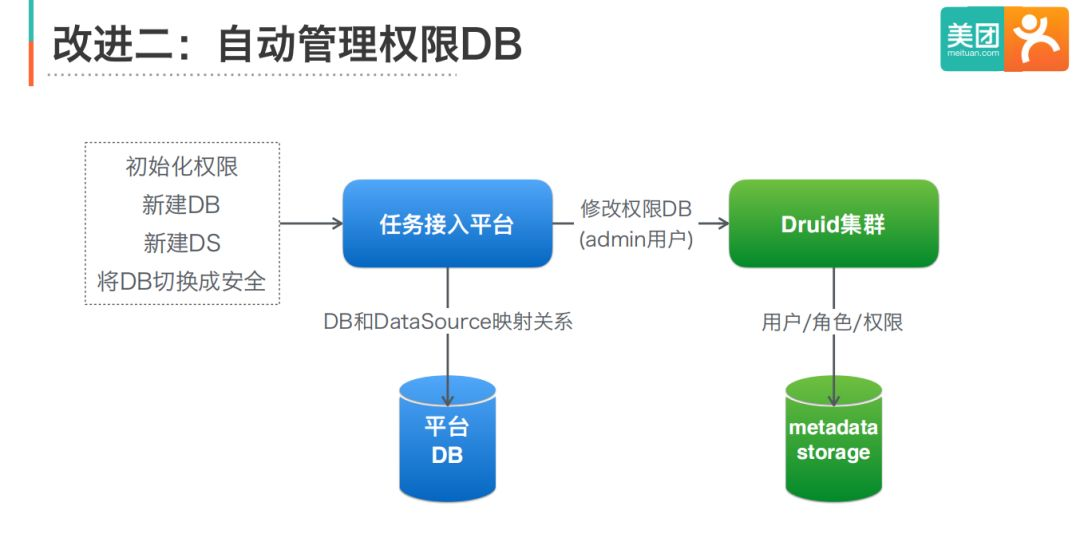
改進二:自動管理權限DB
通過任務接入平臺維護DB和DataSource的映射關系,并在DB和DataSource發生變化時,呼叫鑒權模塊介面更新權限DB,
改進三:支持SSO認證和非認證訪問
自定義認證鏈條,通過SSO認證Filter實作Web控制臺的SSO認證,通過非安全訪問Filter兜底,兼容非認證的請求,
注意事項
(1)使用0.13以上版本 (或者cherrypick高版本的bugfix)
(2)上線流程
- 啟用basic-security功能,用allowAll兜底
- 初始化權限DB,創建匿名用戶并授權
- 將allowAll替換為anonymous
- 逐步回收匿名用戶的權限
(3)上線順序:coordinator->overlord->broker->historical->middleManager
--
04 總結
1.關于SQL
(1)如果還在用原生的JSON查詢語言,強烈建議試一試
(2)社區在不斷改進SQL模塊,建議使用最新版本
(3)Druid SQL本質上是一個語言翻譯層
- 對查詢性能和穩定性沒有太大影響
- 受限于Druid本身的查詢處理能力,支持的SQL功能有限
(4) 要留意的坑
- 大集群的schema推導效率
- Broker需要等schema初始化后再提供服務(#6742)
2.關于Security
(1)Druid包含一下Security特性,建議升級到最新版本使用
- 傳輸層加密
- 認證鑒權框架
- BA和Kerberos認證
- RBAC鑒權
(2)認證鑒權框架足夠靈活,可根據自身需求擴展
(3)經歷生產環境考驗,完成度和穩定性足夠好
(4)上線前應充分考慮兼容性和節點更新順序
今天的分享就到這里,謝謝大家,
本文首發于微信公眾號“DataFunTalk”
嘉賓介紹:
高大月,Apache Kylin PMC成員,Druid Commiter,開源和資料庫技術愛好者,有多年的SQL引擎和大資料系統開發經驗,目前在美團點評負責OLAP引擎的內核開發、平臺化建設、業務落地等作業,
注:歡迎轉載,轉載請留言或私信,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/462962.html
標籤:大數據