簡介
mydumper 是一款開源的 MySQL 邏輯備份工具,主要由 C 語言撰寫,與 MySQL 自帶的 mysqldump 類似,但是 mydumper 更快更高效,
mydumper 的一些優點特性:
- 輕量級C語言開發
- 支持多執行緒備份資料,備份后按表生成多個備份檔案
- 支持事務性和非事務性表一致性備份
- 支持將匯出的檔案壓縮,節約空間
- 支持多執行緒恢復
- 支持已守護行程模式作業,定時快照和連續二進制日志
- 支持按指定大小將備份檔案切割
- 資料與建表陳述句分離
下載安裝
安裝方式非常多,以下介紹幾種常見的方式,
- Ubuntu 中自帶了 myloader
sudo apt-get install mydumper
- 使用 deb 包安裝,以 Ubuntu 為例
apt-get install libatomic1
wget https://github.com/mydumper/mydumper/releases/download/v0.11.5/mydumper_0.11.5-1.$(lsb_release -cs)_amd64.deb dpkg -i mydumper_0.11.5-1.$(lsb_release -cs)_amd64.deb
- 編譯安裝
- docker 安裝
根據實際平臺情況,可選擇不同的安裝方式,官方也提供了一些常見的安裝檔案,https://github.com/mydumper/mydumper
引數說明
mydumper 引數說明
-B, --database 要備份的資料庫,不指定則備份所有庫,一般建議備份的時候一個庫一條命令
-T, --tables-list 需要備份的表,名字用逗號隔開
-o, --outputdir 備份檔案輸出的目錄
-s, --statement-size 生成的insert陳述句的位元組數,默認1000000
-r, --rows 將表按行分塊時,指定的塊行數,指定這個選項會關閉 --chunk-filesize
-F, --chunk-filesize 將表按大小分塊時,指定的塊大小,單位是 MB
-c, --compress 壓縮輸出檔案
-e, --build-empty-files 如果表資料是空,還是產生一個空檔案(默認無資料則只有表結構檔案)
-x, --regex 是同正則運算式匹配 'db.table'
-i, --ignore-engines 忽略的存盤引擎,用都厚分割
-m, --no-schemas 不備份表結構
-d, --no-data 不備份表資料
-G, --triggers 備份觸發器
-E, --events 備份事件
-R, --routines 備份存盤程序和函式
-W, --no-views 不備份視圖
--where 只匯出符合條件的資料
-k, --no-locks 不使用臨時共享只讀鎖,使用這個選項會造成資料不一致
--less-locking 減少對InnoDB表的鎖施加時間(這種模式的機制下文詳解)
-l, --long-query-guard 設定阻塞備份的長查詢超時時間,單位是秒,默認是60秒(超時后默認mydumper將會退出)
--kill-long-queries 殺掉長查詢 (不退出)
-b, --binlogs 匯出binlog
-D, --daemon 啟用守護行程模式,守護行程模式以某個間隔不間斷對資料庫進行備份
-I, --snapshot-interval dump快照間隔時間,默認60s,需要在daemon模式下
-L, --logfile 使用的日志檔案名(mydumper所產生的日志), 默認使用標準輸出
--tz-utc 跨時區時使用的選項,允許備份timestamp,這樣會導致不同時區的備份還原出問題,默認關閉,
--skip-tz-utc 同上,默認值,
--use-savepoints 使用savepoints來減少采集metadata所造成的鎖時間,需要 SUPER 權限
--success-on-1146 Not increment error count and Warning instead of Critical in case of table doesn't exist
-h, --host 連接的主機名
-u, --user 備份所使用的用戶
-p, --password 密碼
-P, --port 埠
-S, --socket 使用socket通信時的socket檔案
-t, --threads 開啟的備份執行緒數,默認是4
-C, --compress-protocol 壓縮與mysql通信的資料
-V, --version 顯示版本號
-v, --verbose 輸出資訊模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默認為 2
myloader 引數說明
-d, --directory 備份檔案的檔案夾
-q, --queries-per-transaction 每次事物執行的查詢數量,默認是1000
-o, --overwrite-tables 如果要恢復的表存在,則先drop掉該表,使用該引數,需要備份時候要備份表結構
-B, --database 還原到的資料庫(目標庫)
-s, --source-db 被還原的資料庫(源資料庫),-s db1 -B db2,表示源庫中的db1資料庫,匯入到db2資料庫中,
-e, --enable-binlog 啟用還原資料的二進制日志
-h, --host 主機
-u, --user 還原的用戶
-p, --password 密碼
-P, --port 埠
-S, --socket socket檔案
-t, --threads 還原所使用的執行緒數,默認是4
-C, --compress-protocol 壓縮協議
-V, --version 顯示版本
-v, --verbose 輸出模式, 0 = silent, 1 = errors, 2 = warnings, 3 = info, 默認為2
常用案例
mydumper 匯出示例
# 個人實際中最常用的備份陳述句
mydumper -B test -o /home/mydumper/data/test -e -G -R -E -D -u root -p 123456 -h 192.168.0.191 -P 3306 -v 3 --long-query-guard 288000 --skip-tz-utc --no-locks --logfile /home/mydumper/log/test
# 備份全部資料庫
mydumper -u root -p 123456 -o /home/mydumper/data/all/
# 備份全部資料庫,排除系統庫,
mydumper -u root -p 123456 --regex '^(?!(mysql|sys|performance_schema|information_schema))' -o /home/mydumper/data/all/
# 備份全部資料庫,包含觸發器、事件、存盤程序及函式
mydumper -u root -p 123456 -G -R -E -o /home/mydumper/data/all/
# 備份指定庫
mydumper -u root -p 123456 -G -R -E -B db1 -o /home/mydumper/data/db1
# 備份指定表
mydumper -u root -p 123456 -B db1 -T tb1,tb2 -o /home/mydumper/data/db1
# 只備份表結構
mydumper -u root -p 123456 -B db1 -d -o /home/mydumper/data/db1
# 只備份表資料
mydumper -u root -p 123456 -B db1 -m -o /home/mydumper/data/db1
myloader 匯入案例
# 個人實際中最常用的匯入陳述句
myloader -h 192.168.0.192 -P 33306 -u root -p 123456 -t 1 -v 3 -d /home/mydumper/data/test/0/ -B test
# 從備份中恢復指定庫
myloader -u root -p 123456 -s db1 -o -d /home/mydumper/data/all/0/
# 匯入時開啟 binlog
myloader -u root -p 123456 -e -o -d /home/mydumper/data/db1/0/
# 將源庫的 db1 匯入到備庫的 db1_bak 庫中
myloader -u root -p 123456 -B db1_bak -s db1 -o -d /home/mydumper/data/db1/0/
# 匯入特定的某幾張表
## 先將 metadata 檔案和需要單獨匯入的表的結構檔案和資料檔案匯入到單獨的檔案夾中,此處默認庫已建好,否則還需要復制建庫相關陳述句,
cp /home/mydumper/data/db1/0/metadata /backup/db1/0/
cp /home/mydumper/data/db1/0/d1.t1-schema.sql /backup/db1/0/
cp /home/mydumper/data/db1/0/d1.t1.sql /backup/db1/0/
## 從新檔案夾中匯入資料
myloader -u root -p 123456 -B db1 -d /backup/db1/0/
## 以上就可以單獨匯入 db1.t1 表
關于 -e 引數,需要稍微注意下,默認情況下,myloader 是不開啟 binlog 的,這樣可以提高匯入速度,如果匯入實體有從庫,且需要匯入的結果同步到從庫上,則需要使用 -e 打開 binlog 記錄,
匯出之后的目錄如下,以資料庫 d1 ,其中有表 t1 為例:
-d1
-0
metadata 記錄備份時間點的Binlog資訊,日志檔案名和寫入位置
d1-schema-create.sql 建庫陳述句
d1-schema-post.sql 存盤程序,函式,事件創建陳述句
d1.t1-schema.sql 表結構檔案
d1.t1.sql 表資料檔案,若使用了分塊引數,大表的資料檔案會出現多個,以數字分開,
-1
以上為比較常見的匯出后的目錄結構,根據實際情況不同,可能還有會含有觸發器的檔案,含有視圖的檔案等,
常見問題與實踐經驗
- Error switching to database whilst restoring table
使用 myloader 匯入時會出現這類報錯,可以嘗試的解決方法如下:調大 wait_timeout 引數;調大 max_packet_size 引數;使用一個執行緒匯入, -t 1,
- (myloader:35671): CRITICAL **: Error restoring test.email_logger from file test.email_logger.sql: Cannot create a JSON value from a string with CHARACTER SET 'binary'.
MySQL 的一個 Bug,可以嘗試手動修改對應的備份檔案,將
/!40101 SET NAMES binary/;
修改為:
/!40101 SET NAMES utf8mb4/;
- (myloader:34726): CRITICAL **: Error restoring test.(null) from file test-schema-post.sql: Access denied; you need (at least one of) the SUPER privilege(s) for this operation
在匯入 AWS RDS 時部分存盤程序創建失敗,有比較嚴格的權限限制,需要匯入用戶有 SUPER 權限,但是 AWS RDS 用戶無法授予 SUPER 權限,針對這部分存盤程序,可以考慮手動在備份庫上創建,
- 大表匯出優化
使用 -r或-F引數,對匯出的資料檔案進行分片,
- 備份機器配置盡可能高
備份前先預估大小,避免機器磁盤不足,盡可能選用配置較高的機器,加快備份速度,
- 非必要資料不備份
備份前對于不用備份的資料可以提前進行一次洗掉,也可在匯出資料時添加正則引數等過濾部分表
- 備份盡量不跨網路
備份資料時盡量在內網中進行,若需要將資料遷移到外網,可以備份完之后,將備份檔案拷貝到外網服務器上,盡量減少匯出時網路不穩定的干擾,匯入時同理,
- 加快匯入速度的一些方法
選擇合適的執行緒數,根據實際情況和機器配置,選擇合適的執行緒引數,并非執行緒數越多越快,
匯入時關閉 MySQL 的 binlog 寫入,待匯入完成后再開啟,
在內網或較穩定的環境中進行匯入,
原理與架構
mydumper 作業流程
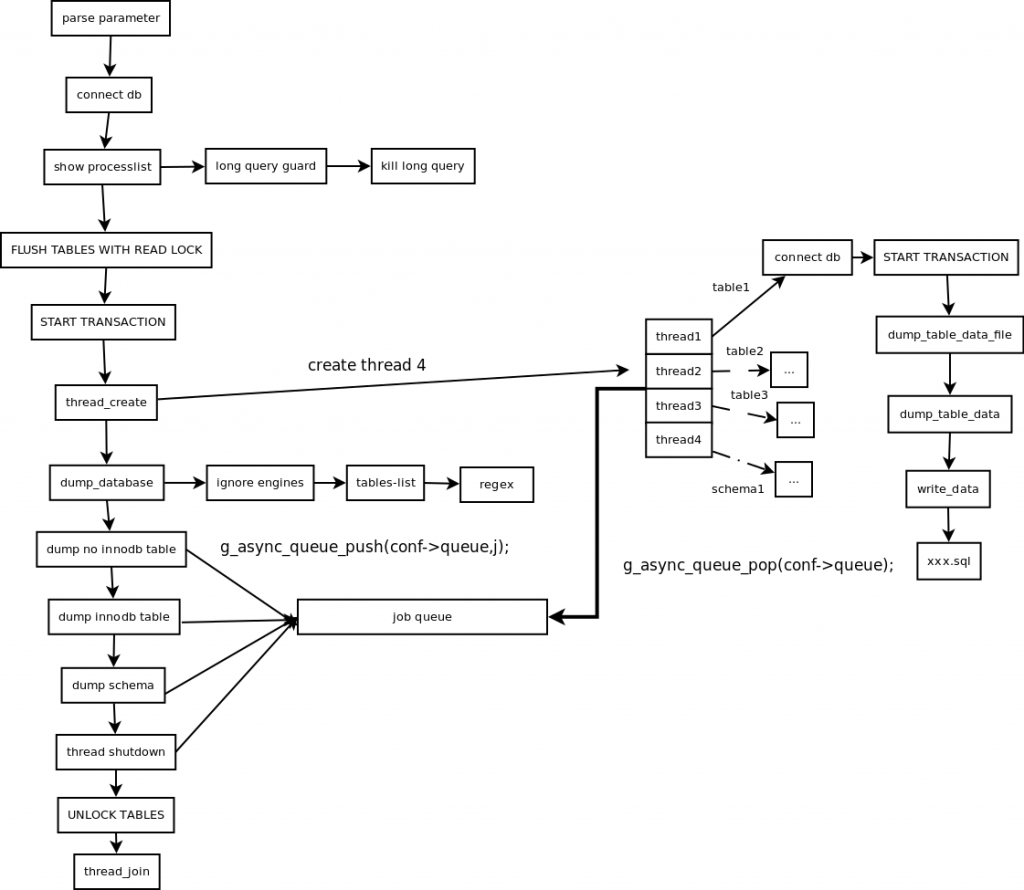
主要步驟概括
- 主執行緒 FLUSH TABLES WITH READ LOCK,施加全域只讀鎖,阻止DML陳述句寫入,保證資料的一致性,
- 讀取當前時間點的二進制日志檔案名和日志寫入的位置并記錄在metadata檔案中,
- N個dump執行緒 START TRANSACTION WITH CONSISTENT SNAPSHOT,開啟讀一致的事務,
- dump non-InnoDB tables, 首先匯出非事物引擎的表,
- 主執行緒 UNLOCK TABLES 非事物引擎備份完后,釋放全域只讀鎖,
- dump InnoDB tables,基于事物匯出InnoDB表,
- 事務結束,
myloader 作業原理
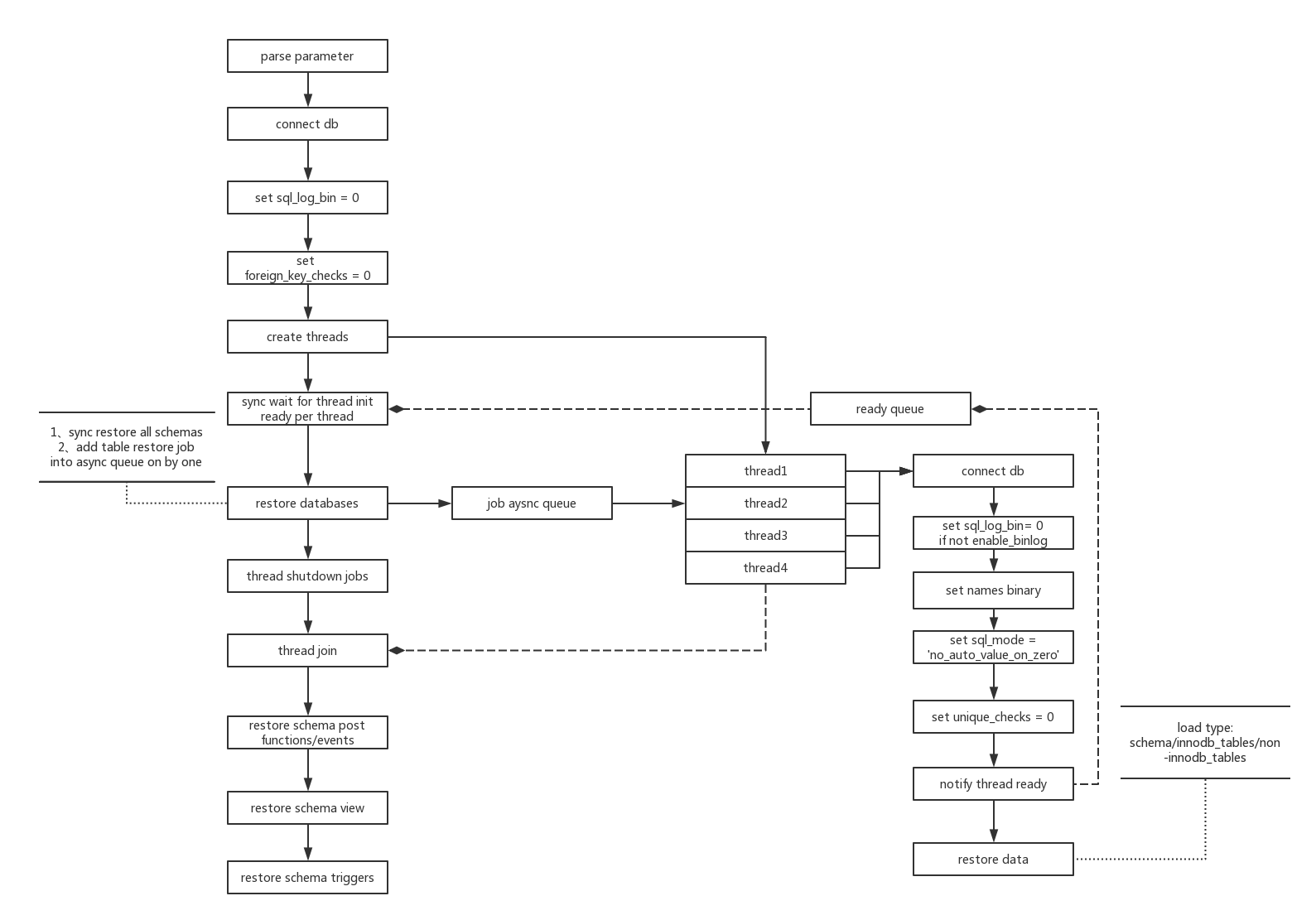
更多技術文章,請關注我的個人博客 www.immaxfang.com 和小公眾號 Max的學習札記,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/463552.html
標籤:其他
上一篇:mysql查詢優化