我想添加一個陣列的相鄰元素“3x3”并創建新陣列。使用嵌套回圈時,由于這段代碼將被呼叫數千次,因此需要時間。
import tensorflow as tf
import numpy as np
rows=6
cols=8
array1 = np.random.randint(10, size=(rows, cols))
print(array1)
array2=np.zeros((rows-2,cols-2))
for i in range(rows-2):
for j in range(cols-2):
array2[i,j]=np.sum(array1[i:i 3,j:j 3])# print()
print("output\n",array2)
##My output
[[9 4 9 6 1 4 9 0]
[2 3 4 2 0 0 9 0]
[2 8 9 7 6 9 4 8]
[6 3 6 7 7 0 7 5]
[2 1 4 1 7 6 9 9]
[1 1 2 6 3 8 1 4]]
output
[[50. 52. 44. 35. 42. 43.]
[43. 49. 48. 38. 42. 42.]
[41. 46. 54. 50. 55. 57.]
[26. 31. 43. 45. 48. 49.]]
通過矢量化,可以解決這個問題。然而,我嘗試了不同的技術,但從未有過任何運氣,例如重塑然后添加陣列,只使用一個具有大小行或列的回圈。
注意:在我的專案中,行和列的大小可能非常大。
它類似于帶有內核的 2D 卷積。問題是,有沒有在不使用回圈的情況下實作這一點?或至少將其降低為具有較小的時間復雜度“僅將行或列作為回圈的大小”。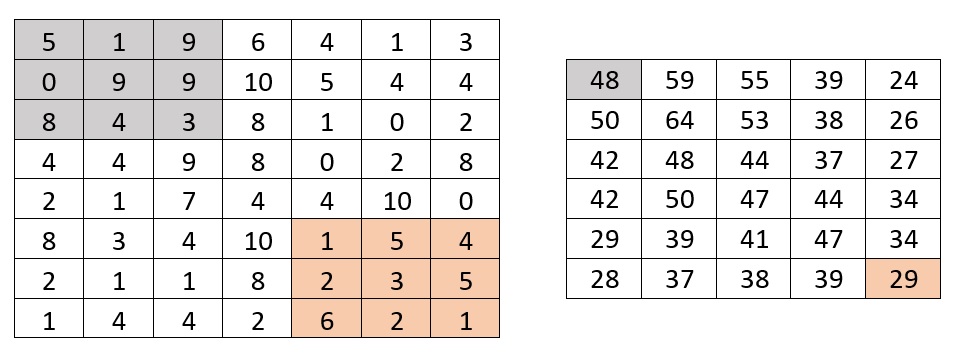
uj5u.com熱心網友回復:
我得到了我認為更適合這種情況的解決方案。使用 scipy.signal 模塊中的函式 convolve2d 我使用函式 np.ones 和 np.array 將輸入宣告為 numpy 陣列,并使用 convolve2d 將內核應用于影像的每個部分。這被稱為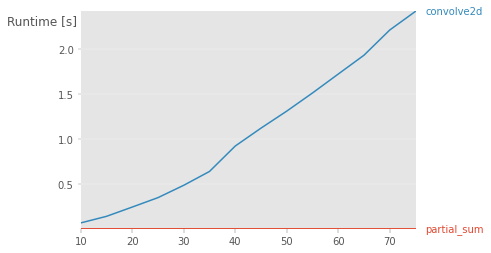
用于此基準測驗的代碼
import perfplot
perfplot.show(
setup=lambda n: (np.random.randint(10, size=(500, 500)), n),
kernels=[
lambda a, n: partial_sum(a, n),
lambda a, n: convolve2d(a, np.ones((n,n), int), 'valid')
],
labels=['partial_sum','convolve2d'],
n_range=[k for k in range(10,80,5)]
)
uj5u.com熱心網友回復:
在這里你應該使用部分總和。您可以在 1 次操作中找到任何一點。
如果您將其用于小數字。沒有太大的性能差異。但是如果你用大數字檢查它。您將看到性能差異。
行數 = 行數
cols = 列數
innerrow = 你的目標行。 *//in your example(3)*
innercol = 你的目標 col。 *//in your example(3)*
使用您的代碼:
O(rows x cols x innerrow x innercol)
O(2000 x 2000 x 200 x 2000)
但是您可以使用以下方法計算它:
O(rows x cols)
例子:O(2000 x 2000)
import numpy as np
rows = 1000
cols = 2000
array1 = np.random.randint(10, size=(rows, cols))
array0 = array1
print(array1)
array2 = np.zeros((rows-100, cols-100))
for i in range(0, rows):
for j in range(1, cols):
array1[i][j] = array1[i][j-1]
for i in range(0, cols):
for j in range(1, rows):
array1[j][i] = array1[j-1][i]
for i in range(rows-100):
for j in range(cols-100):
sm = array1[i 100][j 100]
if i-1 >= 0:
sm -= array1[i-1][j 100]
if j-1 >= 0:
sm -= array1[i 100][j-1]
if i-1 >= 0 and j-1 >= 0:
sm = array0[i-1][j-1]
array2[i, j] = sm
print("output\n", array2)
這是輸出
[[1 9 1 9 2 0 3 8]
[7 1 8 7 1 2 8 4]
[7 1 5 4 8 3 9 0]
[4 4 8 9 3 1 7 6]
[2 5 9 9 3 6 7 2]
[9 0 9 5 0 3 2 8]]
output
[[40. 45. 45. 36. 36. 37.]
[45. 47. 53. 38. 42. 40.]
[45. 54. 58. 46. 47. 41.]
[50. 58. 55. 39. 32. 42.]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/471425.html
上一篇:何時在numpy上使用xarray來處理中等級別的多維資料?
下一篇:如何替換多維陣列中的串列?