我有以下資料框:
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001L, 2020L, 'apples', 'CA', 100L),
(202002L, 2020L, 'apples', 'CA', 150L),
(202001L, 2020L, 'apples', 'USA', 400L),
(202002L, 2020L, 'apples', 'USA', 675L),
(202001L, 2020L, 'oranges', 'CA', 50L),
(202002L, 2020L, 'oranges', 'CA', 65L),
(202001L, 2020L, 'oranges', 'USA', 175L),
(202002L, 2020L, 'oranges', 'USA', 390L)],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
我需要:
a) 取 df1 并按國家/地區拆分...使用 df1 中的國家/地區名稱申請創建 df2_CA、df2_USA。
b) 生成另外 2 個 dfs,按產品按年顯示總銷售額(示例使用 2020 年,僅兩個月),使用后綴“_annual”...所以我們得到 df2_CA_annual、df2_USA_annual。
最終結果:
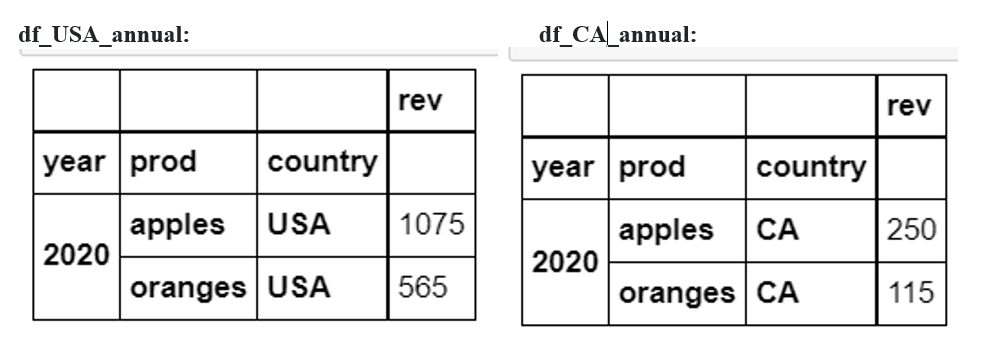
問題:我的實際用例有十幾個削減,我想保持編碼緊湊。我想我可以使用串列和 for 回圈來創建我想要的最終 dfs 來節省時間。如何修復下面的代碼?
# 1. Get dfs by country: CA and USA...df2_(country):
for x in df1['country'].unique():
locals()['df2_' x ] = df1[(df1['country'] == x ) ]
#2. Take dfs from step 1, calculate total revenue by year. Create frames df2_(country)_annual:
mylist=[df2_CA, df2_USA]
for x in mylist['country'].unique():
locals()[ 'df2_' x '_annual' ] = mylist[(mylist['country'] == x )]
x = x.groupby(['year', 'prod','country']).sum()[["rev"]]
uj5u.com熱心網友回復:
@VMSMani 答案的另一種方法是利用字典:
df_annual = {}
for c in df1['country'].unique():
df_annual[c] = df1.where(df1['country'] == c).groupby(['year', 'prod', 'country']).sum()[['rev']]
“唯一”的區別是您按鍵存盤所有資料幀,因此您可以稍后通過呼叫將它們取回df_annual[country],我認為這會使事情更整潔。
uj5u.com熱心網友回復:
如果您只需要 DF 串列,那么下面可能會有所幫助:
import pandas as pd
import numpy as np
from numpy import rec, nan
df1=pd.DataFrame.from_records(rec.array([(202001, 2020, 'apples', 'CA', 100),
(202002, 2020, 'apples', 'CA', 150),
(202001, 2020, 'apples', 'USA', 400),
(202002, 2020, 'apples', 'USA', 675),
(202001, 2020, 'oranges', 'CA', 50),
(202002, 2020, 'oranges', 'CA', 65),
(202001, 2020, 'oranges', 'USA', 175),
(202002, 2020, 'oranges', 'USA', 390)],
dtype=[('yyyymm', '<i8'), ('year', '<i8'), ('prod', 'O'), ('country', 'O'), ('rev', '<i8')]))
final_df_list = list()
for col in df1.country.unique():
final_df_list.append(df1.where(df1.country == col).groupby(['year', 'prod','country']).sum()[["rev"]])
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/471432.html
標籤:Python python-3.x 熊猫 数据框 麻木的