情景一
資料庫概述
基本術語
DB : 資料庫 ( Database )
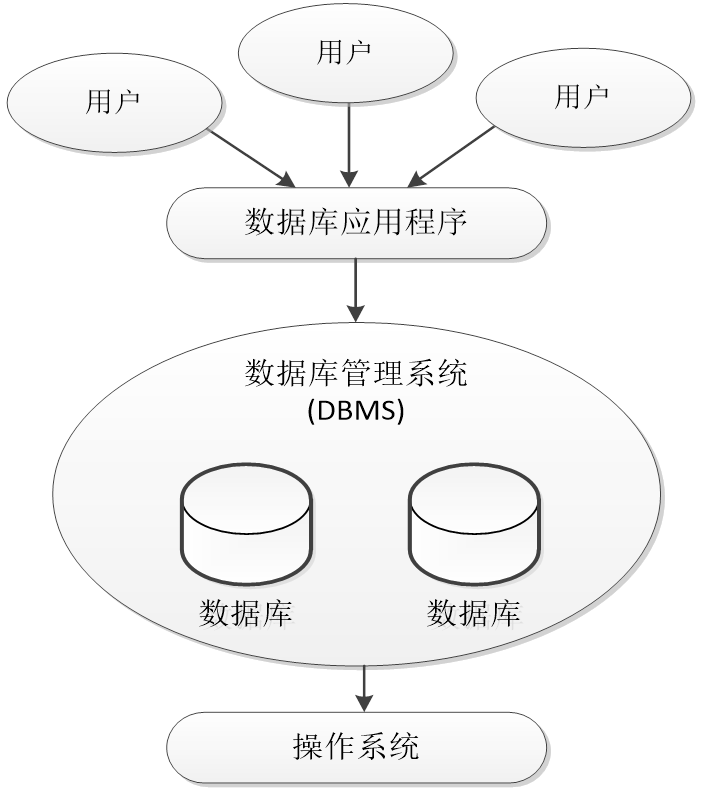
是按照資料結構來組織、存盤和管理資料的倉庫,其本身看作電子化的檔案柜,用戶可以對檔案中的資料進行增加、洗掉、修改、查找等操作
DBMS : 資料庫管理系統 ( Database Management System )
是一種操縱和管理資料庫的大型軟體,用于建立、使用和維護資料庫
DBS : 資料庫系統 ( Database System )
由資料庫 ( DB ) 、資料庫管理系統 ( DBMS ) 、資料庫應用程式和用戶等組成
DBA : 資料庫管理員 ( Database Administrator )
負責資料庫的總體資訊控制
資料庫系統結構圖:
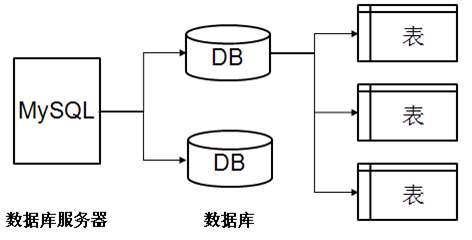
資料庫存盤結構:
資料庫是存盤和管理資料的倉庫,但資料并不能直接存盤資料,資料是存盤在表中的
在存盤資料的程序中一定會用到資料庫服務器,所謂的資料庫服務器就是指在據算計上安裝一個資料庫管理程式
什么是 SQL語言
SQL語言就是一種資料庫查詢語言和程式設計語言
它是一種關系型資料庫語言,主要用于管理資料庫中的資料,如
存取資料、查詢資料、更新資料等
關系型資料庫與語言由 4部分 組成:
資料定義語言 ( DDL ) create drop alter
資料操作語言 ( DML ) insert update delete
資料查詢語言 ( DQL ) select
資料控制語言 ( DCL ) grant revoke
SQL簡介
常用的商用資料庫
Oracle
MySQL
MS SQL Server
MongoDB
DB2
資料模型:
1.層次模型 - 樹形結構
2.網狀模型 - 網路結構
3.關系模型 - 二維表結構
4.面向物件模型 - 物件為單位,物件由屬性和方法組成,具有類和繼承等特點
MYSQL 關系型資料庫
為什么選擇 MySQL
開源
跨平臺
價格優勢
功能強大使用方便
Internet 流行網站架構方式 LAMP ( Linux + Apache + MySQL + PHP )
Linux作為作業系統,Apache作為Web服務器,MySQL作為資料庫,PHP作為服務器端腳本解釋器
版本
社區版
商業版
基于 Windows 有兩種安裝:
.msi 的二進制發行版,提供了圖形化的安裝向導
.zip 的壓縮檔案
關于版本號:
MySQL-5 ( 主版本號 ) .6 ( 次版本號 ) .16( 修訂版本號 )
安裝 MYSQL ; 熟悉運行環境
默認埠號 : 3306
情景二
MySQL常用命令
MySQL 目錄結構
MySQL 安裝完成后,會在磁盤上生成一個目錄,該目錄被成為 MySQL 安裝目錄
MySQL 安裝目錄中包含了啟動檔案、組態檔、資料庫檔案和命令檔案
Data目錄:用于放置一些日志資訊以及資料庫
Bin 目錄:用于放置一些可執行檔案,如mysql.exe
My.ini 檔案:mysql資料庫中使用的組態檔
MySQL啟動和登錄
啟動和停止 MySQL服務
1.通過 Windows服務管理器啟動mysql服務
自動:會隨系統一起啟動
手動:服務不會隨系統一起啟動,直到需要時才會被激活
已禁用:服務將不再啟動,即使是在需要它時,也不會被啟動,除非修改為上面的型別
2,通過DOS命令啟動mysql服務
net start mysql
net stop mysql
登錄和退出MySQL
- 通過DOS命令登錄MySQL服務
命令名 : mysql
機器名或機器的IP -h
賬戶 -u
密碼 -p
完整命令列: mysql -h localhost -u root -p
2.使用 MySQL Command Line Client 登錄 mysql服務
掌握MySQL的常用命令
從服務器獲取 MySQL 的狀態資訊
status 簡寫為 \s
選擇資料庫
use 簡寫為 \u 資料庫名作引數
執行一個 SQL腳本檔案
Source 簡寫 . 以一個檔案名做引數
首先,創建一個sql檔案
打開記事本,撰寫創建資料庫的代碼:
create database mysql_db;
保存為 .sql檔案
使用 show databases;
查看資料庫串列
執行sql檔案,再次查看有那些資料庫
退出MySQL
Quit 或 exit 簡寫為 \q
重新配置MySQL
1.通過命令重新配置MySQL
首先登錄到 MySQL資料庫,在該視窗中使用如下命令:
set character set client = gbk ( 僅針對當前視窗有效,只能暫時改變編碼 )
2.通過my.ini檔案重新配置MySQL
通過記事本,打開 my.ini檔案,進行修改 ( 長期有效 )
情景三
創建資料庫
創建資料庫是開發應用的起點
使用SQL簡單創建“圖書”管理資料庫
CREATE DATABASE book;
如何創建資料庫
創建資料庫book
CREATE DATABASE book;
執行結果
mysql>CREATE DATABASE book;
Query OK, 1 row affected
查看資料庫
SHOW DATABASES;
查看資料庫
使用SQL查看所有資料庫
SHOW DATABASES;
使用SQL查看創建好的資料庫
SHOW CREATE DATABASE <資料庫>;
查看當前資料庫
SELECT DATABASE();
修改、指定資料庫字符集
查看資料庫資訊
SHOW CREATE DATABASE book;
修改資料庫字符集
ALTER DATABASE book DEFAULT CHARACTER SET gbk;
字符集
Litan1 (安裝時默認)
Utf8
GBK
創建一個使用字符集GBK的book1資料庫
CREATE DATABASE book1 CHARACTER SET <字符集>;
創建一個使用字符GBK,并帶校對規則的book2資料庫
CREATE DATABSASE book2 CHARACTER SET <字符集>;
COLLATE <字符集>_bin;
洗掉資料庫
如何洗掉資料庫
洗掉資料庫是將資料庫系統中已經存在的資料庫洗掉
洗掉資料庫的基本語法:
DROP DATABASE <資料庫>;
洗掉資料庫
洗掉資料庫book1
DROP DATABASE book1;
執行
mysql>DROP DATABASE book1;
Query OK, 0 row affected
查看
SHOW DATABASES;
情景四
基本表
資料庫中的資料存盤在表中,表是資料庫中存盤資料的基本單位
MySQL中表的形式像日常使用的Excel,是按行和列的格式排布的
表頭——欄位名(屬性)
行——記錄
元組
列——欄位
域——該列的取值范圍
記錄:表中的一行,不能重復,沒有順序
欄位:表中的一列,體現資料的不同性質
域:欄位的取值范圍,域的特征依賴于欄位的特性,包括資料型別、資料長度和其他約束
表實際上是由結構和記錄組成的
表的結構就是表中應包含哪些欄位以及欄位的特性,創建表就是創建表的結構
p.s. 創建表之前一定要設計好表的結構!
數值型資料
數值型資料型別都用于存盤不同型別的數字值,有不同的長度或精度
整型資料
整數型別可分為5種:
TINYINT ( 1位元組 ) -128~127
SMALLINT ( 2位元組 )
MEDIUMINT
INT ( 4位元組 ) 10位整數
BIGINT ( 8位元組 )
不同整數型別的取值范圍可以根據位元組數計算出來
浮點數型別和定點數型別
小數由浮點數和定點數表示
浮點數型別有兩種:
單精度浮點數型別 FLOAT
雙精度浮點型別 DOUBLE
定點數型別只有 DECIMAL型別
其中,DECIMAL(M, D) 中M是長度,定義了總位數,包括小數點右邊的位數;
D是小數點右邊的位數,
字符型、時間日期型資料型別
常用
char(n) 長度n 固定(n個位元組)
varchar(n) 長度 n 位最大值,可根據資料的實際長度變化
text 長度較大,一般用于描述表中"說明"、“備注”之類的資訊
日期與時間型別
MySQL提供了表示日期和時間的資料型別
YEAR 年
DATA 年/月/日
TIME
DATETIME
TIMESTAMP 時間戳,記錄系統當前時間
其他型別
對于圖片、視頻、音頻等,MySQL提供了表示二進制大資料的資料型別
BLOB
情景五
創建基本表
CREATE TABLE <表>
(
欄位1, 資料型別[約束條件],
欄位2, 資料型別[約束條件],
...
欄位n, 資料型別[約束條件],
);
查看資料表
查看資料表
SHOW CREATE TABLE <表>;
查看所有表
SHOW TABLES;
查看表結構
DESCRIBE <表>;
P.S. 關鍵字 DESCRIBE 可以縮寫為 DESC
情景六
表的維護和修改
修改表名
ALTER TABLE <舊表> RENAME [TO] <新表>;
P.S. [to] 是可選的
修改資料型別
ALTER TABLE <表> MODIFY <欄位> <資料型別>;
添加欄位
ALTER TABLE <表> ADD <新欄位> <資料型別>
[約束條件] [first|after <已存在欄位>];
欄位名排列順序
ALTER TABLE <表名> change <舊欄位名> <新欄位名> <資料型別>;
P.S. 新資料型別不能留空,即使修改字符的資料型別相同也必須設定
洗掉字符、洗掉表
洗掉欄位
ALTER TABLE <表> DROP <欄位>;
洗掉表
DROP TABLE <表>;
溫馨提示:洗掉表時,可能會與其他表存在關聯
情景七
表記錄的插入
創建好資料庫和資料表后,想要操作資料表中的資料,首先得保證表中存在資料
MySQL使用 insert陳述句 向資料庫添加資料
向資料表中添加新的記錄應該包含表的所有欄位,即 為該表的所有欄位添加資料,
為該表所有欄位添加 insert陳述句
insert 陳述句中 指定所有欄位名
INSERT INTO <表>(<欄位1>, <欄位2>,...)
VALUES(<值1>, <值2>,...); # 欄位和值要匹配:順序和資料型別匹配
insert 陳述句不指定欄位名 ; 插入所有的欄位,給出的值需與定義時保持一致
INSERT INT <表> VALUES(<值1>, <值2>,...);
省略表名插入一條記錄
MySQL中,也可以在 insert陳述句 中只向 部分欄位 中添加值
insert陳述句還有一種語法格式,可以為表中指定的欄位或者全部欄位添加資料
INSERT INTO <表>
SET <欄位1> = <值1>[, <欄位2> = <值2>,......]; #最后一組不需要逗號
同時插入多條記錄
有時,需要一次向表中插入多條記錄
在MySQL中提供了一條insert陳述句同時添加多條記錄的功能
INSERT INTO <表>[(<欄位1>, <欄位2>,...)]
VALUES(<值1>, <值2>,...), (<值1>, <值2>,...),
...
(<值1>, <值2>,...);
情景八
表記錄的修改和洗掉
修改資料
UPDATE <表> SET <欄位1> = <值1>, <欄位2> = <值2>
[WHERE <條件運算式>]; # 指定更新資料需要的條件
注意:沒有使用 WHERE 子句,整個表格的所有記錄都會更新
洗掉記錄
DELETE FROM <表> [WHERE <條件運算式>];
注意:需要使用WHERE子句,來指定洗掉記錄的條件
洗掉表中所有記錄
TRUNCATE [TABLE]<表>;
注意:洗掉所有記錄前,應該備份
CREATE TABLE <備份表>
SELECT * FROM <表>;
比較
-
DELETE陳述句 是DML陳述句,TRUNCATE陳述句通常被認為是DDL陳述句
-
DELETE陳述句后可以跟WHERE子句中的條件運算式只洗掉滿足條件的部分記錄,而TRUNCATE陳述句只能用于洗掉表中的所有記錄
-
使用 TRUNCATE 陳述句洗掉表中的資料,再向表中添加記錄時,自動增加欄位的默認初始值重新由1開始;使用DELETE陳述句洗掉表中的所有記錄,再向表中添加記錄時,自動增加欄位的值為洗掉該欄位的最大值加一
4.使用DELETE陳述句時,每洗掉一條記錄都會在日志中記錄,而使用TRUNCATE陳述句時,不會在日志中記錄洗掉的內容,因此TRUNCATE陳述句的執行效率比DELETE陳述句高
情景九
表單無條件查詢
第一部分:復習與回顧
一、什么是SQL?
SQL : Structured Query Language,結構化查詢語言,是關系資料庫管理系統的標準語言
二、SQL 分類:
-
DML,資料操作語言,用于檢索或者修改資料
增、刪、改、查 -
DDL,資料定義語言,用于定義資料的結構
創建、修改、洗掉 -
DCL,資料控制語言,用于定義資料庫用戶的權限
授權、回收
舉例
SELECT * FROM emp; # DQL
CREATE TABLE s # DDL
第二部分:帶著問題學習新知
-
SELECT 陳述句的語法格式
SELECT <>
FROM <>
...
ORDER BY <> ASC|DESC
LIMIT n -
單表無條件查詢使用 通配符* 查詢所有列和指定列
-
distinct 消除查詢結果中的重復項
-
LIMIT top 限制查詢結果的數量
-
改變查詢顯示結果的列標題
<原名> <新名> | <原名> AS <新名> -
如何對查詢結果進行排序 ORDER BY
三、單表無條件查詢
SELECE陳述句
SELECE [DISTINCT] * | {<欄位1>, <欄位2>, ..., <欄位n>} # “ * ”表示表中的所有欄位 | <欄位>查詢的表中的指定欄位;“ DISTINCT ” 可選,用于剔除查詢結果中的重復的資料
FROM <表> # 從制動的表中查詢資料
[WHERE 條件運算式1] # “ WHERE ”可選引數,用于指定查詢條件
[GROUP BY <欄位> [HAVING <運算式2>]] # “ GROUP BY ” 可選,用于將查詢結果按照指定欄位進行分組; “ HAVING ” 可選,用于分組后的結果進行過濾
[ORDER BY <欄位> [ASC | DESC] # “ ORDER BY ” 可選,用于查詢結果按照指定欄位進行排序,排序方式由引數ASC(升序排序) 或引數DESC 控制(降序排序),默認升序
[LIMIT [OFFSET] <記錄>] # “ LIMIT ” 可選,用于限制查詢結果的數量,第一個引數“OFFSET”表示偏移量(如果偏移量為0則從查詢結果的第一條記錄開始類推),如果不指定OFFSET,其默認值為0,第二個引數“記錄數”表示回傳查詢的條數
查詢所有欄位
查詢表中所有欄位的資料,使用" * " 統配符查詢資料的語法格式
SELECE * FROM <表>;
指定欄位
查詢指定欄位是指在 SELETE陳述句 的欄位串列中指定要查詢的欄位,僅針對部分欄位
SELECE <欄位1>, ..., <欄位n>
FROM <表>;
帶計算的列
SELECT <欄位> * <數字>, ...
FROM <表>
消除重復項的查詢
SELECE DISTINCT <欄位>
FROM <表>;
DISTINCT作用于多個欄位
SELECE DISTINCT <欄位1>, <欄位2>, ...
只有關鍵字后指定的多個欄位都相同,才會被認作重復記錄
限制輸出結果集的查詢
SELECE <欄位1>, <欄位2>, ...
FROM <表>
LIMIT [OFFSET, ] <記錄> # 記錄表示回傳結果的條數
LIMIT可跟兩個引數,“ OFFSET ”,可選,表示偏移量,如果偏移量為0則查詢結果從第一條記錄開始如果不指定默認值為0
“記錄數”表示查詢記錄的數目
SQL Serve 使用 top關鍵字
查詢排序
從表中查詢出來的結果可能是無序的,或不是用戶所需要的,為了使查詢結果滿足用戶的需求,可以使用 ORDER BY 對查詢結果進行排序
SELECE <欄位1>, <欄位2>, ...
FROM <表>
ORDER BY <欄位1> [ASC|DESC],
<欄位2> [ASC|DESC],
...
你可以使用 ASC 或 DESC 關鍵字來設定查詢結果是按升序或降序排列,
默認情況下,它是按升序排列,
改變查詢顯示結果的列標題
在查詢結果時,如果表名或欄位名很長使用起來不太方便,這時可以為表和欄位取一個別名,這個別名可以替代其指定的表和欄位
改變格式
SELECE <欄位> [AS] <別名> [, 欄位 [AS] 別名, ...]
FROM <表>;
情景十
一、作業中的問題
- 表單的組成
SELECT 1+2;
3
SELECT DATABASE(); # 顯示所有資料庫
SELECT user() # 取得當前用戶
MySQL 最小
SQL Server
- 求年齡
兩個年份相減: 當前年份-出生日期的年份
2020-birthday
2020-year(birthday)
Year(now())-year(birthday)
SELECT <欄位>, Year(now())-year(birthday)
FROM <表>;
year # 提取日期中的年份
mouth # 提取月份
day # 提取日期
system() # 提取系統時間 MySQL
now() # 提取系統時間 MySQL
getdate() # 提取系統時間 SQL Server
- 運算式的書寫
score # 表示成績
score < 60 # 不及格
score = score+10 # 提高10分
score=60 # 60分
數值直接表示,不需要加引號
二、表單條件查詢
Where子句
SELECE * [<欄位1>, <欄位2>, ...]
FROM <表>
WHERE <條件> # 文字需要加單引號''
關系運算子
= 等于
<> 不等于
!= 不等于
< 小于
<= 小于等于
大于
= 大于等于
范圍判斷
用來查詢在某一指定范圍內的資料行,范圍內的資料行,包含兩端的值
小值在前,大值在后
BETWEEN..AND.. NOT BETWEEN..AND..
SELECT * [<欄位1>, <欄位2>, ...]
FROM <表>
WHERE <欄位> [NOT] BETWEEN <值1> AND <值2> # 數值小在前,數值大在后
串列判斷
判斷是否在指定集合中
SELECE * [<欄位1>, <欄位2>, ...]
FROM <表>
WHERE <欄位> [NOT] IN (<值1>, <值2>, ...)
邏輯運算子
使用邏輯表達符,可以將多個查詢條件連接起來
AND(與) 全真則真,一假則假
OR(或) 一真則真,全假則假
NOT(非) 否定其后運算式
SELECE * [<欄位1>, <欄位2>, ... ]
FROM <表>
WHERE <條件1> <邏輯運算>
情景十一
第一部分:作業中的問題
- limit子句
limit可以跟隨 1個引數,表示起始位置(從第幾條記錄開始,MySQL從中位序從0開始)
2個引數,表示記錄的個數
實際上,第一個引數是可以預設的,默認從0開始
LIMIT 3 = LIMIT 0, 3
- 邏輯運算子的優先級
not and or (由高到低)
第二部分
模糊查詢
帶LIKE關鍵字的查詢——判斷兩個字串是否匹配
SELECT * | {<欄位1>, <欄位2>, ...}
FROM <表>
WHERE <欄位> [NOT] LIKE '匹配字符';
通配符
LIKE語法格式中的“匹配字串”指定用來匹配的字串,其值可以是一個普通字串,也可以是包含百分號(%)和下劃線(_)的通配字串
百分號和下劃線統稱為通配符,它們在通配符中有特殊含義
百分號(%)通配符
以匹配任意的字串,包括空字串,任意多個,可以是0個
下劃線(_)通配符
下劃線通配符只匹配單個字符,如果要匹配多個字串,需要使用多個下劃線通配符
空值查詢
判斷某些列是否是NULL值或非空值
SELECT * | <欄位1>, <欄位2>, ...
FROM <表>
WHERE <欄位> IS [NOT] NULL;
NULL # 表示不確定的值,與0不同,不是空字符
=0 / ! =0 # 與0比較
空值一定不能用 = 或 !=
情景十二 資料庫設計——概念模型ER圖
一、資料庫設計步驟
1.需求分析—— 現實世界(資料庫設計的第一步,整個設計的基礎)
業務流程——得到資料流圖、資料字典描述系統
資訊需求
處理需求
安全性與完整性要求
需求分許不充分,會導致整個資料庫重新返工
2.概念結構設計——資訊世界(面向用戶面向客觀世界的模型是現實世界到資訊世界的第一次抽象)
常用的工具為:E-R模型——E-R圖
概念模型是與具體的DBMS無關的
系統分析 資料庫設計
顯示世界事物及聯系 ? 資訊世界概念模式 ? 計算機世界資料模型
資訊化 資料化
3.邏輯結構設計——機器世界(按計算機系統的觀點對資料建模,用于資料庫管理系統的實作,是對現實世界的第二次抽象)
邏輯模型是具體的和DBMS有關聯的
資料庫邏輯模型:
層次模型
網狀模型
關系模型
物件物件模型
4.物理結構設計——資料庫的存盤規劃(物理設備上的存盤結構與存取方法與給定的計算機系統相關
確定資料的存盤結構
確定資料的存取方法
5.資料庫實施——投入運行后,還需要DBA進行運行和維護(運用DBMS提供的資料語言及宿主語言,建立資料庫,編制與除錯應用程式,組織資料入庫,進行試運行)
資料庫運行與維護:通常由DBA完成,包括:
資料庫的備份與恢復
資料庫的安全性與完整性控制
資料庫性能的監督、分析和改進
資料庫的重組和重構造
二、概念模型
1.資訊世界的基本概念
(1)物體(Entity):現實世界中存在的可以區分的事物
(2)屬性(Attribute):描述物體的特征,與具體的事物有關
(3)關鍵字(Key):唯一可以標識出這個物體的屬性或是屬性的集合
(4)物體型(Entity Typr):用物體名和屬性名集合來抽象描述同類物體
(5)物體集(Entity Set):物體的集合
(6)聯系(Relationship):物體間或物體內部屬性之間的關聯,兩個物體之間的聯系
物體(Entity):客觀存在并且可以相互區別的事物成為物體,物體可以是具體的事物,也可以是抽象的事件,
屬性(Attribute):描述物體的特征稱為屬性,一個物體可以用若干個屬性來描述,
碼(key):唯一識別符號的屬性或屬性集
域(Domain):屬性的取值范圍
物體性(Entity Type):具有相同屬性的物體必然具有相同的特征和性質,用物體名及其屬性名的集合抽象和刻畫同類物體,
物體集(Entity Set):同類物體的集合稱為物體集
聯系(Relationship):在現實世界中,事物內部以及事物之間是有聯系的,這些聯系在資訊世界中,事物內部以及事物之間是有聯系的,這些聯系在資訊世界中反應為物體(型)內部的聯系和物體(型)之間的聯系,物體內部的聯系通常指組成物體的各屬性之間的聯系,物體內部的聯系通常是指組成物體的各屬性之間的聯系;物體之間的聯系通常是指不同物體集之間的聯系,
2.概念模型的表示方法
ER圖的繪制方法
概念模型的表示方法有很多,最常見的方法為物體-聯系方法,簡稱E-R方法,該方法使用E-R圖來描述現實世界的概念模型,
E-R方法 (Entity-Relationship Approach)
E-R圖 (Entity-Relationship Diagram)
(1)兩個物體之間的聯系型別通常有三種:
一對一聯系:從一端的物體集中一個物體到另一端只能找到唯一的物體與之對應,反之亦然
一對多聯系:從一段的物體集中一個物體到另一端找到多個物體與之對應,相反從另一端中的一個物體只能找到一個相對應
多對多聯系:從一端的物體集中集中一個物體到另一端找到多個物體與之對應,反之亦然
(2)ER圖的繪制方法
物體:用矩形表示,在矩形內寫物體名
屬性:用橢圓內注明聯系
聯系:用菱形表示,在菱形框內部寫聯系名,
區域ER圖設計
構造E-R圖的方法
1.確定物體
2.除去重復的物體
3.確定物體結構
4.確定主關鍵字
5.定義聯系
情景十三 資料庫設計——合并區域ER圖
一、資料庫設計程序
ER圖設計步驟
對資料進行抽象并設計區域ER圖
將各區域ER圖進行合并,形成初步ER圖
消除不必要的冗余,形成基本ER圖
設計區域ER圖:對需求分析階段收集到的資料分類、組織,形成物體型、屬性和碼,確定物體型之間的練習型別,
兩個準則:
屬性是不可分的資料項
屬性不能與其他物體型有聯系
二、沖突
合并區域ER圖:在合并中通常有這三類沖突,
屬性沖突,屬性域沖突即屬性值的型別、取值范圍不同,
列的問題
命名沖突,同名異義或異名同義
結構沖突,同一物件在不同區域應用中有不同抽象或同一物體在不同區域ER圖中的屬性個數和排列順序不同,
同一個物件中屬性或物體的差異
三、冗余
消除掉不必要的冗余:
冗余的資料,由基本資料匯出的資料
冗余的聯系,由其他聯系匯出的聯系
并不是所有的冗余都要消除,有時為了提高效率是可以允許冗余的存在,要根據用戶的整體需求決定
情景十四 關系模型
〇、復習
1.需求分析——現實世界
業務流程
得到資料流圖、資料字典描述系統
2.概念設計——資訊世界
概念設計與具體的DBMS無關
常用的ER模型,ER圖
3.邏輯設計——機器世界
邏輯模型與具體的DBMS有關聯
資料庫邏輯資料模型:層次模型、網狀模型、關系模型、面對物件模型
4.物理模型
資料庫的存盤規劃
5.資料庫的實施
入庫、試運營
6.資料庫的運行和維護
投入運營后,并沒有結束,DBA進行轉儲、恢復、安全性控制、性能監督等
一、關系模型
1.資料結構——關系、二維表
2.資料集合——資料的插入、洗掉、修改、查詢(增刪改)
3.資料完整性
(1)物體完整性
(2)域完整性
(3)參照完整性
二、關系術語
關系(relation):一個關系對應著一張二維表
元組(tuple):表中的一行就是一個元組,也稱記錄
屬性(attribute):表中的一列稱為一個屬性,也稱欄位
域(domain):列的值就是屬性值,屬性值的取值范圍為域
關系模式:對關系的描述稱為關系模式,表示為,關系名(屬性1, 屬性2, ..., 屬性n)
候選鍵或候選碼:關系中能唯一標識該關系的元組的多個屬性或屬性集
拿出一個屬性(屬性的集合),就能唯一標識出該元組
一個關系模式中可以擁有多個候選鍵
主鍵或主碼:在候選鍵中能唯一標識該關系的元組的多個屬性或屬性集
每個關系中只能有一個主鍵
主屬性和非主屬性:包含在任何一個候選鍵中的屬性為主屬性,不包含任何一個候選鍵中的屬性稱為非主屬性
外鍵或外碼:關系中的某個屬性或屬性集時別的關系的主鍵,稱為關系的外鍵
三、概念模型
一個物體集轉換為一個關系模式,物體集的名稱為關系名,物體集的屬性稱為關系的屬性,物體集的碼就是關系的主碼
將 1:1 聯系轉換為關系模型 / 與任意一端對應的關系模式合并
方案一:單獨為一個關系模式
物體名(矩形)作為關系名,將每個集合的主鍵寫到一起
方案二:將一端合并到另一端 (推薦)
物體名(矩形)作為關系名,把其中一個集合的全部元素寫出,把另一個表的主鍵添加到集合的后面
將 1:n 聯系轉換為獨立的關系模式 / 與n端對應的關系模式
方案一:獨立的關系模式
物體名(矩形)作為關系名,將每個集合的主鍵寫到一起
方案二:將一端合并到多端(推薦)
物體名(矩形)作為關系名,把其中一個集合的全部元素寫出,把另一個表的主鍵添加到集合的后面
將 m:n聯系轉換為獨立的關系模式
聯系(菱形)作為關系名,將每個添加主鍵,后面添加聯系的
具有相同碼的關系模式可以合并
物體集之中的物體之間有關聯,將一端添加到多端中
物體名(矩形)作為關系名,寫出物體中的全部屬性,后面添加其他物體集的主鍵
將多元聯系轉換為獨立的關系模式
聯系(菱形)作為關系名,先寫出所有物體集的主鍵然后添加與聯系相連的屬性
1:1,將一端的碼合并到另一端;1:n,將1端的碼合并到多端;m:n,形成新的關系模式,將兩端的碼與聯系本身的屬性合在一起,
情景十六 物體完整性和域完整性
一、資料完整性
1、物體完整性——對行的要求
每個物體的每一條記錄都是唯一的
不能有一模一樣的兩條記錄
對應的約束:primary key unique(主鍵約束,唯一約束)
2、域完整性——對列的要求
域—屬性值的取值范圍
對應的約束:not null default check(非空默認檢查)
3、參照完整性----兩個表之間的關系
二、約束
1、主鍵約束 PRIMARY KEY
建表時創建主鍵約束
后期加入主鍵約束
2、唯一約束 UNIQUE
(前2個實作物體完整性)
3、非空約束 NOT NULL(列的值)
4、默認約束 DEFAULT
5、檢查約束 CHECK
(后3個實作域完整性)
三、操作—在已創建的表中設定約束
1、主鍵約束
ALTER TABLE 表名
ADD CONSTRAINT 約束名 PRIMARY KEY(欄位名);
練習:對book表設定主鍵約束(對borrow表設定主鍵約束,誰是該表的主鍵?)
Alter table borrow
Add constraint PK_br primary key(r_id,b_id);
注意:一個表有且只有一個主鍵,可以是單一屬性,也可以是多個屬性,
2、唯一性約束
ALTER TABLE 表名
ADD CONSTRAINT 約束名 UNIQUE(欄位名);
將reader表的phone設定為唯一約束
Alter table reader
Add constraint un_r unique(phone);
主鍵約束和唯一約束的區別是主鍵約束的欄位不允許為NULL,而唯一性約束的欄位可以為NULL,
主鍵約束一個表中只能有一個,而唯一約束一個表中可以有多個,
3、非空約束
SQL Server的語法:
ALTER TABLE 表名
ALTER column 列名 資料型別 NOT NULL;
將reader表的r_name設定為非空
Alter table reader
Alter column r_name varchar(16) not null;
MySQL的語法:
ALTER TABLE 表名
MODIFY column 列名 資料型別 NOT NULL
例如:
Alter table reader
MODIFY column r_name varchar(16) not null;
4、默認值約束
SQL sever的語法格式
ALTER TABLE 表名
ADD constraint 約束名 DEFAULT(‘默認值’) for 列名;
將reader表的sex默認值設定為‘男’
Alter table reader
Add constraint de_sex default('男') for sex;
MySQL語法:
5、檢查約束(SQL Server)
ALTER TABLE 表名
ADD constraint 約束名 CHECK(運算式);
將reader表的性別設定檢查約束,值僅能為‘男’或“女”,
Alter table reader
Add constraint ck_sex check(sex='男' or sex='女');
情景十七 參照完整性
〇、復習
1.物體完整性——對行的要求
每個物體的每一條記錄都是唯一的,即不能出現兩條相同的資料
對應的約束:primary key 、unique
2.域完整性——對列的要求
域是指屬性值的取值范圍
對應的約束:not null 、default 、check
3.參照完整性——兩個表之間的關系
主表和從表的關系:從表某個欄位要依賴主表的主鍵,
外鍵(外碼):關系中的某個屬性或屬性集時別的關系的主鍵,稱為關系的外鍵
一、外鍵約束 FOREIGN KEY
語法格式:
ALTER TABLE 表名
ADD CONSTRAINT 名字 FOREIGN KEY(欄位名) REFERENCES 主表(主鍵);
二、操作——在已經創建的表中設定外鍵約束
首先要保證主表的主鍵設定完成,才能設定外鍵約束
三、外鍵約束的作用
參照完整性將防止用戶執行下列非法操作
在主表中沒有關聯的記錄時,將記錄添加或更改到相關表中
更改主表中的值,導致相關表中產生孤立記錄
從主表中洗掉記錄,但仍然會存在與該記錄匹配的相關記錄
四、管理約束
1.查看約束
SHOW CREATE TABLE 表名;
2.洗掉約束
(1)洗掉主鍵約束
ALTER TABLE 表名
DROP PRIMARY KEY;
(2)洗掉外鍵約束
ALTER TABLE 表名
DROP FOREIGN KEY 約束名;
(3)洗掉唯一約束
唯一約束也是約束,洗掉唯一約束,即洗掉索引
DROP INDEX 約束名或索引名 ON 表名;
SQL Sever
1.查看約束
EXEC sp_helpconstraint 表名
2.洗掉約束
ALTER TABLE 表名
DROP CONSTRAINT 約束名
情景十八 創建表的同時建立約束
一、創建表的同時創建約束
創建順序:先主表,后從表
二、約束型別
1.列級約束
對某一列設定的約束:可以有primary key、not null、default、check
列名 資料型別 NOT NULL
列名 資料型別 NOT NULL PRIMARY KEY 或 PRIMARY KEY (列名)
列名 資料型別 UNIQUE 或 CONSTRAINT 約束名 UNIQUE (列名)
2.表級約束
對多個列或者多個表設定的約束:可以有primary key、check、foreign key
列名 資料型別 DEFAULT '默認值'
列名 資料型別 CHECK (運算式)
列名 資料型別 FOREIGN KEY(外鍵) REFERENCES 主表 (主鍵)
三、級聯
當有了外鍵約束,表與表之間就建立了聯系,洗掉主表的記錄,如果從表有相關聯的記錄時,這時,不能直接洗掉記錄,必須先洗掉從表記錄,再洗掉主表記錄,
CASCADE——洗掉包含與已洗掉鍵值有參照關系的所有記錄
在建立外鍵時添加ON DELETE CASCADE
四、小結
創建約束時,分為兩種情況:
1.在已經創建完成的表中創建約束
2.在創建表的同時創建約束
情景十九 復雜查詢——聚合函式的使用
一、常用的聚合函式
常用的統計函式有6個:
1、COUNT(*):統計記錄個數
2、COUNT(列名):按列名統計非空記錄個數
3、SUM(列名):求和
4、AVG(列名):求平均值
5、MAX(列名):求最大值
6、MIN(列名):求最小值
二、使用聚合函式對“教務管理”資料庫進行統計
1、查詢學生總數,
Select count(*) 學生數,count(學號) AS 學生總數
From 學生;
2、查詢有幾個專業,
SELECT count(distinct 專業)
FROM 學生;
3、在選課表中查詢成績的最高分、最低分,
Select max(成績) 最高分,min(成績) 最低分
From 選課;
4、在選課表中查詢成績的成績的總分、平均分,
Select sum(成績),avg(成績)
FROM 選課;
5、查詢選修了課程的學生人數,
Select count(distinct 學號)
From 選課;
6、計算C01號課程的學生平均成績,
SELECT avg(成績)
FROM 選課
WHERE 課程號='c01';
7、查詢選修了C01號課程的學生最高分和最低分,
SELECT max(成績),min(成績)
FROM 選課
WHERE 課程號='c01';
8、查詢學號為“20050101”的學生的總成績及平均成績,
SELECT sum(成績),avg(成績)
FROM 選課
WHERE 學號='20160101';
9、查詢有考試成績的學生人數,
Select count(distinct 學號)
From 選課
Where 成績 is not null;
二、使用聚合函式的注意事項
(1)除了COUNT(*)函式外,其他的統計函式都不考慮回傳值或運算式為NULL的情況,集合函式
(2)統計函式只能出現在目標列運算式、ORDER BY子句、HAVING子句中,不能出現在WHERE子句和GROUP BY 子句中,
(3)默認對所有的回傳行進行統計,包括重復的行;如果要統計不重復的行資訊,則可以使用DISTINCT選項,
(4)如果對查詢結果進行了分組,則統計函式的作用范圍為各個組,否則統計函式作用于整個查詢結果,
情景二十——分組
一、分組
關鍵字: GROUP BY 欄位名
顯示組內所有的欄位:GROUP_CONCAT(列)
GROUP BY 和 聚合函式一起使用
1.在表中統計出版社出版圖書的平均價格和數量
SELECT publish 出版社,COUNT(*) 數量, AVG(price) 平均價格
FROM book
GROUP BY publish;
2.統計表中各種型別的圖書的數量
SELECT b_type, count(*)
FROM book
GROUP BY b_type;
3.統計表中每個系的讀者人數
SELECT dept, COUNT(*)
FROM reader
GROUP BY dept;
GROUP BY 與 HAVING 子句一起使用
4.查詢表中平均價格在20元以上的出版社
SELECT publish 出版社,count(*) 數量,AVG(price) 平均價格
FROM book
HAVING AVG(price)>20;
5.查詢表中平均價格在20元并且圖書數量大于3的圖書
SELECT publish 出版社,COUNT() 數量,AVG(price) 平均價格
FROM book
GROUP BY publish
HAVING AVG(price)>20 AND COUNT()>=3;
6.統計每個系讀者的人數并且只顯示讀者人數大于3的記錄
SELECT dept, count()
FROM reader
GROUP BY dept
HAVING COUNT()>=3;
7.檢索表中價格在30元以上的圖書資訊,并且按照價格降序輸出
SELECT *
FROM book
WHERE price>30
ORDER BY price desc;
8.檢索borrow表 2017年借出的圖書資訊,要求借出日期升序輸出
SELECT *
FROM borrow
WHERE year(outdate)=2017
ORDER BY outdate ASC;
SELECT *
FROM borrow
WHERE outdate like'2017%'
ORDER BY outdate ASC;
9.檢索表中所有的圖書資訊,按出版社升序排列輸出,出版社相同價格的圖書繼續按照價格降序輸出
SELECT *
FROM book
ORDER BY publish asc, price desc;
10.在"book"表中查詢圖書型別,平均價格在20元以上并且圖書數量在兩本以上的圖書出版社,要求查詢結果按平均價格的降序排序
SELECT *
FROM book
WHERE b_type='計算機類';
SELECT publish, AVG(price), COUNT(*)
FROM book
WHERE b_type='計算機類'
GROUP BY publish;
SELECT publish, AVG(price), COUNT()
FROM book
WHERE b_type='計算機類'
HAVING AVG(price)>=20 AND COUNT()>=2;
SELECT publish, AVG(price), COUNT()
FROM book
WHERE b_type='計算機類'
GROUP BY publish
HAVING AVG(price)>=20 AND COUNT()
ORDER BY AVG(price) DESC;
注意:
WHERE 是執行 GROUP BY操作之前進行的過濾,表示全部資料中篩選出部分符合條件的資料
在WHERE子句中不能使用統計函式
HAVING 是在 GROUP BY 分組之后的再次過濾,可以使用統計函式
三、總結
SELECT 列 FROM 表 [WHERE 條件 ] [GROUP BY 欄位 ] [HAVING 條件 ] [ORDER BY 欄位 ] [LIMIT 記錄 ]
SELECT 目標串列 --欄位名,計算式(sal*12),聚合函式
FROM 表名 --從哪個表查詢,可以是多個表
[WHERE 查詢條件]
[GROUP BY 欄位名] --按某個欄位進行分組
[HAVING 查詢條件] --對分組的結果再次篩選
[ORDER BY 欄位名] --對查詢結果按欄位進行升序(降序)排序
[LIMIT 偏移,記錄數] --輸出指定的記錄
情景二十一——鏈接查詢
一、基本概念
當需要提取資料的完整資訊時,需要同時從多個表中獲取相關的資料,這種從多個表中提取資料的操作,稱為多表查詢,
二、笛卡爾積
笛卡爾乘積是指在數學中,兩個集合X和Y的笛卡爾積(Cartesian product),又稱直積,表示為X×Y,第一個物件是X的成員而第二個物件是Y的所有可能有序對的其中一個成員
1.使用交叉鏈接查詢
SELECT *
FROM book,borrow;
消除無意義資料,找關聯欄位——兩表均有 b_id
關聯條件:兩者相等,Book.B_id = borrow.b_id
SELECT b_name, r_id, outdate, indate
FROM book, borrow
WHERE Book.B_id = borrow.b_id;
-- 別名
SELECT b_name, r_id, outdate, indate
FROM book B, borrow bo
WHERE B.B_id = bo.b_id;
三、內連接
2.查詢"杰哥"的借閱,顯示姓名、圖書編號和借閱日期
首先,確定關聯幾個表:reader r 和 borrow bo
接著,找出關聯欄位和關聯條件:r.r_id = bo.r_id
最后寫代碼
SELECT r.r_name, bo.b_id, bo.outdate
FROM reader r, borrow bo
WHERE r.r_id = bo.r_id AND r_name='杰哥'
3.通過表book、reader和borrow查詢借書人的姓名、圖書、名稱和借閱時間
確定表:book b, reader r, borrow bo
確定關聯欄位和條件:b.b_id = bo.b_id AND r.r_id = bo.r_id
寫代碼
SELECT r.r_name, b.b_name, bo.outdate
FROM book b, reader r, borrow bo
WHERE b.b_id = bo.b_id AND r.r_id = bo.r_id
4.查閱同時借閱了圖書編號為 ‘2737’ 和 ‘2738’ 的學生編號
首先確定表:
對 borrow表 做了2遍查詢,邏輯上的兩張表,此時稱為 自鏈接,必須起別名
borrow bo1 borrow bo2
接著:確定關聯欄位以及關聯條件
bo1.r_id = bo2.r_id
最后寫代碼:
SELECT bo1.r_id
FROM borrow bo1, borrow bo2
WHERE bo1.r_id = bo2.r_id AND bo1.b_id=2737 AND bo2.b_id=2738;
5.從 ‘’ 和 ‘’ 兩個資料表中查詢所有讀者的借書情況,查詢結果顯示讀者姓名、所在系部、圖書編號、借閱時間
首先:確定表 borrow bo reader r
接著:關聯欄位和關聯條件 r.r_id=bo.r_id
最后:寫代碼
SELECT r.r_name, r.dept, bo.b_id, bo.outdate
FROM borrow bo, reader r
WHERE r.r_id = bo.r_id;
四、外連接
型別
左外連接
表 left join 表2 on 條件
右外連接
表 right join 表2 on 條件
全外連接
表 full join 表2 on 條件
6.使用左外連接從 ‘borrow’ 和 ‘reader’ 兩個資料表中查詢所有讀者的借書情況,查詢結果顯示讀者姓名、所在系部、圖書編號、借閱時間,沒有借閱記錄的讀者也要顯示出來
SELECT r.r_name,r.dept,bo.b_id,bo.outdate
FROM reader r left join borrow bo on r.r_id=bo.r_id;
7.使用右外連接從 ‘borrow’ 和 ’reader‘ 兩個資料表中查詢所有讀者的借書情況,查詢結果顯示讀者姓名、系部、圖書編號、借閱時間,沒有記錄的讀者也要顯示出來
SELECT r.r_name,r.dept,bo.b_id,bo.outdate
FROM borrow bo right join reader r on r.r_id=bo.r_id;
8.使用完全外連接從 ‘borrow’ 和 ‘book’ 兩個資料表中查詢所有的借書資訊及圖書資訊,包括未借出的圖書,內連接的另一種語法:
SELECT r.r_name,r.dept,bo.b_id,bo.outdate
FROM borrow bo join reader r on r.r_id=bo.r_id;
五、注意事項
進行多表查詢時,經常為表起別名(一旦起別名就不能使用原名)
可以使用表別名作為前綴用來限定列
通過使用表別名可以提高性能
使用表別名可以區分來自不同表但是名字相同的列
只要表關聯,肯定又關聯欄位用于消除笛卡爾積,只是這種關聯欄位需要根據情況使用不相同的限定符
等值連接
非等值連接
情景二十二——子查詢
一、子查詢概念
嵌套在其他SQL陳述句中的SELECT陳述句,也成為內部查詢
執行程序:由內向外,先處理子查詢,再將子查詢的回傳值結果用于父陳述句(外部陳述句)的執行
范例:查詢與張山在同一個系學習的學生的姓名和所在系
主查詢:誰和張山在一個系
子查詢:張山的系部編號時多少?
第一步:查詢張山的系編號
SELECT 系編號
FROM 學生
WHERE 姓名='張山'
第二步:查詢系編號是 d10 的學生的姓名和所在系
SELECT 姓名,系編號
FROM 學生
WHERE 系編號='d10'
將上面兩步合起來:
SELECT 姓名,系編號
FROM 學生
WHERE 系編號=(SELECT 系編號
FROM 學生
WHERE 姓名='張山')
查找次數為:6+6 ,12次
一般可以在 WHERE子句、HAVING子句、FROM子句中使用子查詢
根據回傳結果的不同,嵌套子查詢可以分為回傳單個值,回傳值串列
二、回傳單個值
查詢出生日期最晚的學生的姓名、性別和出生日期,排序思路:
SELECT 姓名,性別,出生日期
FROM 學生
ORDER BY 出生日期 DESC
LIMIT 1;
子查詢:
第一步,查詢出生日期最晚的
SELECT max(出生日期)
FROM 學生;
第二步,查找誰的出生日期是該值,說明誰的年齡就是最小的
SELECT 姓名,性別,出生日期
FROM 學生
WHERE 出生日期=(SELECT MAX(出生日期)
FROM 學生);
分組:
SELECT 姓名,性別,出生日期
FROM 學生
GROUP BY 性別
HAVING 出生日期=MAX(出生日期);
查詢所有年齡大于平均年齡的學生姓名
第一步:求平均值
SELECT avg(year(now()-year(出生日期))
FROM 學生;
第二步:年齡大于該值 的學生姓名
SELECT 姓名
FROM 學生
WHERE year(now())-year(出生日期)
(SELECT avg(year(now())-year(出生日期))
FROM 學生)
查詢與王武在同一個專業的學生
第一步:查詢王武的專業
SELECT 專業
FROM 學生
WHERE 專業=(SELECT 專業
FROM 學生
WHERE 姓名='王武');
第二步:查詢專業是該專業的學生資訊,
Select *
From 學生
Where 專業=( Select 專業
From 學生
Where 姓名='王武') ;
三、回傳多個值(值串列)
IN運算子
查詢所有選修了 C01 號 課程的學生姓名
第一步:查詢所有選修了 C01 號 課程的學生姓名
SELECT 學號
FROM 選課
WHERE 課程號='C01'
第二步:從學生表中查詢是這些學號的學生的姓名
SELECT 姓名
FROM 學生
WHERE 學號 IN(SELECT 學號
FROM 選課
WHERE 課程號='C01');
用IN運算子改寫查詢與張山在同一個系學習的學生
SELECT 系編號 in (SELECT 系編號
FROM 學生
WHERE 姓名='張山');
查詢選修了課程的學生姓名、專業
第一步:查詢選課中的學號
SELECT DISTINCT 學號
FROM 選課
第二步:從學生表中查學號是這些學生的姓名和專業
SELECT 姓名,專業
FROM 學生
WHERE 學號 in(SELECT DISTINCT 學號
FROM 選課);
查詢沒選修課的學生姓名、專業
SELECT 姓名,專業
FROM 學生
WHERE 學號 NOT IN(SELECT DISTINCT 學號
FROM 選課);
選修高數的學生學號和姓名
第一步:查詢高數的課程號
Select 課程號
From 課程
Where 課程名='高數';
第二步:查選修了該課程的學號
Select 學號
From 選課
Where 課程號=( Select 課程號
From 課程
Where 課程名='高數');
第三步:查詢這些學生的學號和姓名
Select 學號,姓名
From 學生
Where 學號 in(Select 學號
From 選課
Where 課程號=( Select 課程號
From 課程
Where 課程名='高數'));
NOT IN 運算子
查詢時領導的員工的姓名(HR資料庫)
第一步:查詢mgr是什么?
Select distinct mgr
From emp;
第二步:查詢員工表,看empno在不在該集合中,顯示這樣的姓名
Select ename
From emp
Where empno in(Select distinct mgr
From emp);
查詢不是領導的員工的姓名(HR資料庫)
NOT IN操作:如果子查詢中有NULL,則不會查詢出任何的結果,
Select ename
From emp
Where empno not in(Select distinct mgr
From emp
Where mgr is not null);
NOT IN 操作:如果子查詢中有NULL,則不會查詢任何結果
ANY 運算子
查詢其他專業中計算機網路專業某一學生年齡的學生姓名和年齡
SELECT 姓名,year(now())-year(出生日期) 年齡
FROM 學生
WHERE 專業!='計算機網路' AND
year(now())-year(出生日期) in (select year(now())-year(出生日期)
FROM 學生 WHERE 專業='計算機網路');
現在,將IN運算子替換成: >ANY、<ANY、=ANY
-
=ANY:與in等價
Select 姓名,year(now())-year(出生日期) 年齡
From 學生
Where 專業!='計算機網路' and
year(now())-year(出生日期) =any(select year(now())-year(出生日期)
From 學生 where 專業='計算機網路'); -
ANY:大于最小值
Select 姓名,year(now())-year(出生日期) 年齡
From 學生
Where 專業!='計算機網路' and
year(now())-year(出生日期) >any(select year(now())-year(出生日期)
From 學生 where 專業='計算機網路'); -
<ANY:小于最大值
Select 姓名,year(now())-year(出生日期) 年齡
From 學生
Where 專業!='計算機網路' and
year(now())-year(出生日期) <any(select year(now())-year(出生日期)
From 學生 where 專業='計算機網路');
查詢其他專業中比計算機網路專業某一學生年齡小(大)的學生、姓名和年齡——ALL運算子
與每個內容相匹配,有兩種形式:
-
ALL: 大于最大值
SELECT 姓名,YEAR(NOW())-YEAR(出生日期) 年齡
FROM 學生
WHERE 專業!='計算機網路' AND
YEAR(NOW())-YEAR(出生日期) >ALL(SELECT YEAR(NOW())-YEAR(出生日期)
FROM 學生 WHERE 專業='計算機網路'); -
<ALL: 小于最小值
SELECT 姓名, YEAR(NOW())-YEAR(出生日期) 年齡
FROM 學生
WHERE 專業!='計算機網路' AND
YEAR(NOW())-YEAR(出生日期) <all(SELECT YEAR(NOW())-YEAR(出生日期)
FROM 學生 WHERE 專業='計算機網路');
二十三——利用子查詢進行更新操作
資料的更新操作:增加、修改、洗掉資料
考慮到學生表以后還要繼續使用,可以先將學生表復制一份:
CREATE TABLE xuesheng
AS SELECT * FROM 學生;
一、資料增加
INSERT INTO 表名稱[(欄位1,欄位2,…)]
VALUES(值1,值2,…)
利用子查詢插入資料
范例:把平均成績大于80分的學生的學號和平均成績存入另一個已知的基本表S_GRADE(SNO,
AVG_GRADE)中,(假設該表已創建)
Create table s_grade
( sno int not null,
Avg_grade float
);
把平均成績大于80分的學生的學號和平均成績
Select 學號,avg(成績)
From 選課
Group by 學號
Having avg(成績)>80;
插入:
Insert into s_grade
Select 學號,avg(成績)
From 選課
Group by 學號
Having avg(成績)>80;
二、資料修改
UPDATE 表名稱
SET 更新欄位1=更新值1,更新欄位2=更新值2,...
[WHERE 更新條件]
范例:將計算機網路專業全體學生的成績提高5分,
最終改什么?改選課表的成績
UPDATE 選課
SET 成績=成績+5
WHERE 學號 in (select 學號
From 學生
Where 專業='計算機網路');
將英語成績不及格的改為60分,
Update 選課
Set 成績=60
Where 成績<60 and 課程號=(select 課程號
From 課程
Where 課程名='英語');
三、資料洗掉
DELETE FROM 表名稱
[WHERE 洗掉條件]
在系統開發時,一般在洗掉操作之前,先給出一個確認的提示框,以防止用戶誤洗掉,
在DELETE中使用子查詢
范例:洗掉“王武”的所有成績記錄,
明確洗掉哪個表中的記錄?
DELETE FROM 選課
WHERE 學號 in(select 學號
From 學生
Where 姓名='王武');
洗掉“數控”專業的學生所有成績記錄,
明確洗掉哪個表中的記錄?
Delete from 選課
Where 學號 in ( select 學號
From 學生
Where 專業='數控');
二十四——子查詢回傳值為單行單列
二十五——子查詢回傳值為多行單列
二十六——索引
索引的概念與型別
索引是一個單獨的、物理的資料結構,在這個結構中保存了索引值及其相應記錄的物理地址,并且按照索引值進行排序,
資料庫的索引是對資料表中一列或多列的值進行排序后的一種結構,作用是提高表中資料的查詢速度
索引型別
(1)按索引值是否惟一
惟一索引 unique
非惟一索引
(2)索引基于的列數
單列索引
復合索引
創建索引
CREATE INDEX 索引名稱 ON 表名稱(列名稱);
唯一關鍵字UNIQUE,默認情況就是非惟一索引
查看索引
Show index from 表名;
索引不是越多越好?
占存盤空間
表如果需要頻繁更新,先洗掉索引,再更新
洗掉索引
DROP INDEX 索引名稱 ON 表名;
五、創建索引的原則
索引是占存盤空間的,并且需要系統進行維護,換言之,增加了系統開銷,因此,是否創建索引和創建什么樣的索引需要遵循一定的原則,
1、適合創建索引:
表中資料量很大
要查詢的結果集很小,占表中資料的2%--4%
經常用來做WHERE條件中的列或多表連接的列
查詢列的資料范圍分布很廣
查詢列中包含大量的NULL值
2、不適合創建索引:
資料量很小的表
查詢中不常用來作為查詢條件的列
頻繁更新的表
索引列作為運算式的一部分被使用,則創建索引是沒有效果的,例如查詢條件是sal*12>20000,此時在sal上創建索引沒有效果
查詢條件有單行函式
六、索引和約束
(1)創建主鍵約束的時候自動創建唯一性索引
Alter table emp
Add constraint pk_empno primary key(empno);
(2)對于外鍵列,MYSQL將自動創建索引
二十七——視圖
視圖是從一個或多個表中提取出來的資料的一種表現形式,是一個命名的查詢,用于改變基礎表中資料的顯示,
一、創建視圖
創建視圖的語法:
CREATE VIEW 視圖名稱 AS 子查詢;
二、洗掉視圖
洗掉視圖的語法:
DROP VIEW 視圖名稱;
三、修改視圖
修改視圖的語法:
CREATE OR REPLACE 視圖名稱 AS 子查詢;
二十八——事務和鎖
一、事務的概念
事務,也稱作業單元,是由一個或多個SQL陳述句組成的操作序列,這些SQL陳述句作為一個完整的作業單元,要么全部執行成功,要么全部執行失敗,
二、事務開啟
START TRANSACTION; // 開啟事務
... // 多條SQL陳述句構成事務,此時并沒有真正提交到資料庫中即沒真正執行
COMMIT; // 提交事務,即上面的SQL陳述句真正生效
ROLLBACK; // 回滾事務,取消事務,但只能在commit前才有效
三、事務的特性 ( ACID )
-
原子性 ( 不可分隔 )
指一個事務必須被視為一個不可分隔的最小作業單位,只有事務中所有的資料庫操作都執行成功,才算整個事務執行成功,事務中如果有任何一個SQL陳述句執行失敗,已經執行成功的SQL陳述句也必須撤銷,資料庫的狀態退回到執行事務前的狀態, -
一致性
指事物將資料庫從一種狀態轉變為下一種一致的狀態,
例如,表中有一個欄位為姓名,具有唯一性約束,即姓名不能重復,如果一個事物對姓名進行了修改,使姓名變得不唯一了,這就破壞了事物的一致性要求,如果事務中的某個動作失敗了,系統可以自動撤銷事物,回傳起始化狀態 -
隔離性
隔離性還可以稱為并發控制、可串行化、鎖等,當多個用戶并發訪問資料庫時,資料庫為每一個用戶開啟的事物,不能被其他事物的操作資料開鎖干擾,多個并發事務之間要相互隔離 -
持久性
事務一旦提交,所作的修改就會永久保存到資料庫中,即使資料庫發生故障也不應該有任何影響,需要注意的是,事務的持久性不能做到100%的持久,只能從事務本身的角度來保證永久性,而一些外部原因導致資料庫發生故障,比如硬碟損壞,那么所有提交的資料可能都會丟失,
四、鎖
實體分析:
1)如果兩個事務并發的修改:必須加鎖,
2)如果兩個事務并發的查詢:不需要加鎖
3)如果一個事務修改,另一個事務查詢:看具體的應用情境,設定隔離級別
1)臟讀:一個事務讀取到另一個事務未提交的資料
隔離級別:
Read uncommitted --不做任何隔離
Read committed --可以防止臟讀
查詢當前隔離級別:
Select @@tx_isolation;
設定當前的隔離級別:
Set transaction isolation level 級別;
2)不可重復讀:一個事務多次讀取同一條記錄,讀取的結果不相同(一個事務讀取到另一個事務已經提交的資料)
隔離級別:
Repeatable read --可以防止臟讀、不可重復讀
3)幻讀(虛讀):一個事務多次查詢整表的資料,由于其他事務新增(洗掉)記錄造成多次查詢出的記錄條數不同(一個事務讀取到另一個事務已經提交的事務)
隔離級別:
Serializable --串行化,所有問題都沒有,但性能非常低
五、隔離級別
資料庫的使用者自己根據情況決定是否隔離,mysql提供了四種隔離級別:
-
READ UNCOMMITTED
READ UNCOMMITTED (未讀提交) 是事務中級別最低的,該級別下的事務可以讀取到另一個事務中未提及的資料,也被稱作臟讀(Dirty Read),這是相當危險的,由于該級別最低,在實際開發中避免不了任何情況,所以一般很少使用, -
READ COMMITTED
大多數的資料庫默認的隔離級別就是 READ COMMITTED(讀提交)該級別下的事務只能讀取到其他事務已經提交的資料,可以避免臟讀,但不能避免重復讀和幻讀的情況
重復讀就是在事務內重復讀取了別的執行緒已經提交的資料,但兩次讀取的結構不一致,原因是查詢的程序中其他事務做更新的操作
幻讀指一個事務內兩次查詢中資料條數不一致,原因是查詢的程序中其他事務做了添加操作,這兩種情況并不算錯誤,但有些是不符合實際需求的
-
REPEATABLE READ
REPEATABLE READ(可重復讀)是MySQL默認的事務隔離級別,它可以避免臟讀、不可重復讀的問題,確保同一事物的多個實體在并發讀取資料時,會看到同樣的資料行,但理論上,該級別會出現幻讀的情況,不過MySQL的存盤引擎通過多版本并發控制級制解決了該問題,因此該級別是可以避免幻讀的 -
SERIALIZABLE
SERIALIZABLE(可串行化)是事務的最高隔離級別,它會強制對事務進行排序,使之不會發生沖突,從而可以解決臟讀、幻讀、重復讀的問題,實際上,就是在每個讀的資料行上加鎖,這個級別可能會導致大量的超時現象和鎖競爭,實際運用中很少是使用
Mysql默認是repeatable read這個隔離級別,
如何選擇隔離級別?
我們應該在使用資料庫的時候,根據自己想要防止的問題,選擇一個能夠想要防止的問題的隔離級別中性能盡量高的一個,
二十九——創建存盤程序及變數的使用
一、什么是存盤程序
存盤程序是一潭訓多條SQL陳述句的集合,它將這些陳述句封裝起來成為一個代碼塊,以便重復使用,這樣就可以大大減少資料庫開發人員的作業量,
二、創建存盤程序
Create procedure 存盤程序名(引數串列)
Begin
……
……
End
mysql默認結束符是;
所以需要人工修改結束符:
Delimiter //
三、呼叫存盤程序
語法格式:
Call 存盤程序名(引數串列)
Call p1()
四、變數的使用
區域變數—以字母、下劃線、數字組成 server sql @開頭
全域變數—以@開頭 server sql@@開頭
1、 如何定義一個變數
語法格式:
Declare 變數名 型別 [default 默認值];
2、 為變數賦值
方法一:
Set 變數名=運算式;
方法二:
利用查詢方式,將查詢結果值賦給變數
Select 列名 into 變數名 from 表名 where 條件;
三十——流程控制
一、選擇結構
1、IF陳述句
語法結構:
IF 條件運算式 THEN SQL陳述句
ELSEIF 條件運算式 THEN SQL陳述句
ELSE SQL陳述句
END IF;
2、CASE陳述句
語法格式:
CASE 運算式
WHEN 值1 THEN SQL陳述句1
[WHEN 值2 THEN SQL陳述句2]
……
[ELSE SQL陳述句n]
END CASE;
二、回圈結構
1、LOOP 陳述句和 LEAVE 陳述句
Loop實作的是無條件的跳轉
標簽名:
LOOP
陳述句
END LOOP 標簽名;
在寫回圈時,回圈變數、回圈體、回圈條件這些要考慮清楚
2、ITERATE 陳述句
3、REPEAT陳述句 直到型回圈,先執行,后判斷條件
語法格式:
REPEAT
陳述句
UNTIL 條件運算式
END REPEAT;
4、WHILE陳述句 當型回圈,先判斷回圈條件,再執行
語法格式:
WHILE 條件運算式 DO
陳述句
END WHILE;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/472324.html
標籤:其他
上一篇:離線自動化部署CDH