目錄
- 一、window 概念
- 二、 時間視窗(Time Window)
- 1)滾動視窗(Tumbling Windows)
- 2)滑動視窗(Sliding Windows)
- 3)會話視窗(Session Windows)
- 三、window API
- 四、視窗分配器(window assigner)
- 1)增量聚合函式(incremental aggregation functions)
- 2)全視窗函式(full window functions)
- 3)其它可選window API
- 五、Flink 中的時間語意
- 六、設定 Event Time
- 七、水位線(Watermark)
- 1)為什么需要水位線(Watermark)
- 2)如何利用Watermark處理亂序資料問題?
- 3)watermark 的特點
- 4)watermark 的傳遞
- 5)watermark 策略與應用
- 1)Watermark 策略簡介
- 2)使用 Watermark 策略應用
- 3)使用場景
- 4)TimestampAssigner
- 1、AssignerWithPeriodicWatermarks
- 2、AssignerWithPunctuatedWatermarks
- 5)WatermarkStrategy(重點)
- 1、固定亂序長度策略(forBoundedOutOfOrderness)
- 2、單調遞增策略(forMonotonousTimestamps)
- 3、不生成策略(noWatermarks)
一、window 概念
視窗(window)是處理無限流的核心,視窗將流分割成有限大小的“桶”,我們可以在桶上應用計算,本檔案重點介紹如何在Flink中執行視窗操作,以及程式員如何從其提供的功能中獲得最大的好處,
一個有視窗的Flink程式的一般結構如下所示,第一個片段指的是鍵控流,而第二個片段指的是非鍵控流,可以看到,唯一的區別是keyBy(…)呼叫鍵流,而window(…)呼叫非鍵流的windowwall(…),這也將作為頁面其余部分的路標,
Keyed Windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
一般真實的流都是無界的,怎樣處理無界的資料?
在自然環境中,資料的產生原本就是流式的,無論是來自 Web 服務器的事件資料,證券交易所的交易資料,還是來自工廠車間機器上的傳感器資料,其資料都是流式的,但是當你 分析資料時,可以圍繞 有界流(bounded)或 無界流(unbounded)兩種模型來組織處理資料,當然,選擇不同的模型,程式的執行和處理方式也都會不同,
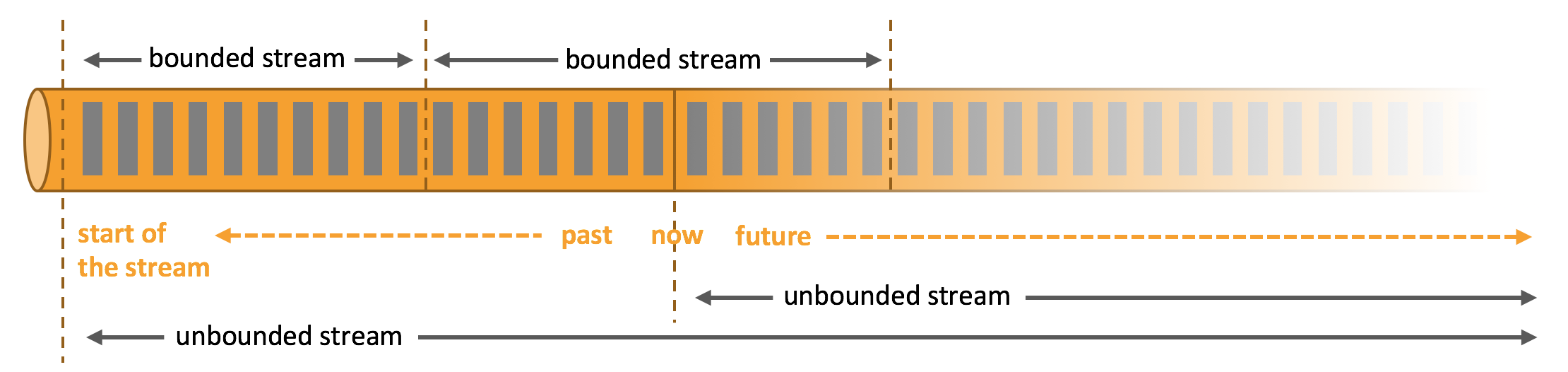
上面圖片來源:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/learn-flink/overview/
- 可以把無限的資料流進行切分,得到有限的資料集進行處理 —— 也
就是得到有界流 - 視窗(window)就是將無限流切割為有限流的一種方式,它會將流
資料分發到有限大小的桶(bucket)中進行分析
二、 時間視窗(Time Window)
官方檔案
1)滾動視窗(Tumbling Windows)
翻轉視窗賦值器將每個元素賦值給一個指定視窗大小的視窗,滾動的視窗有固定的尺寸,而且不重疊,例如,如果您指定一個大小為5分鐘的滾動視窗,則當前視窗將被評估,并每5分鐘啟動一個新視窗,如下圖所示:
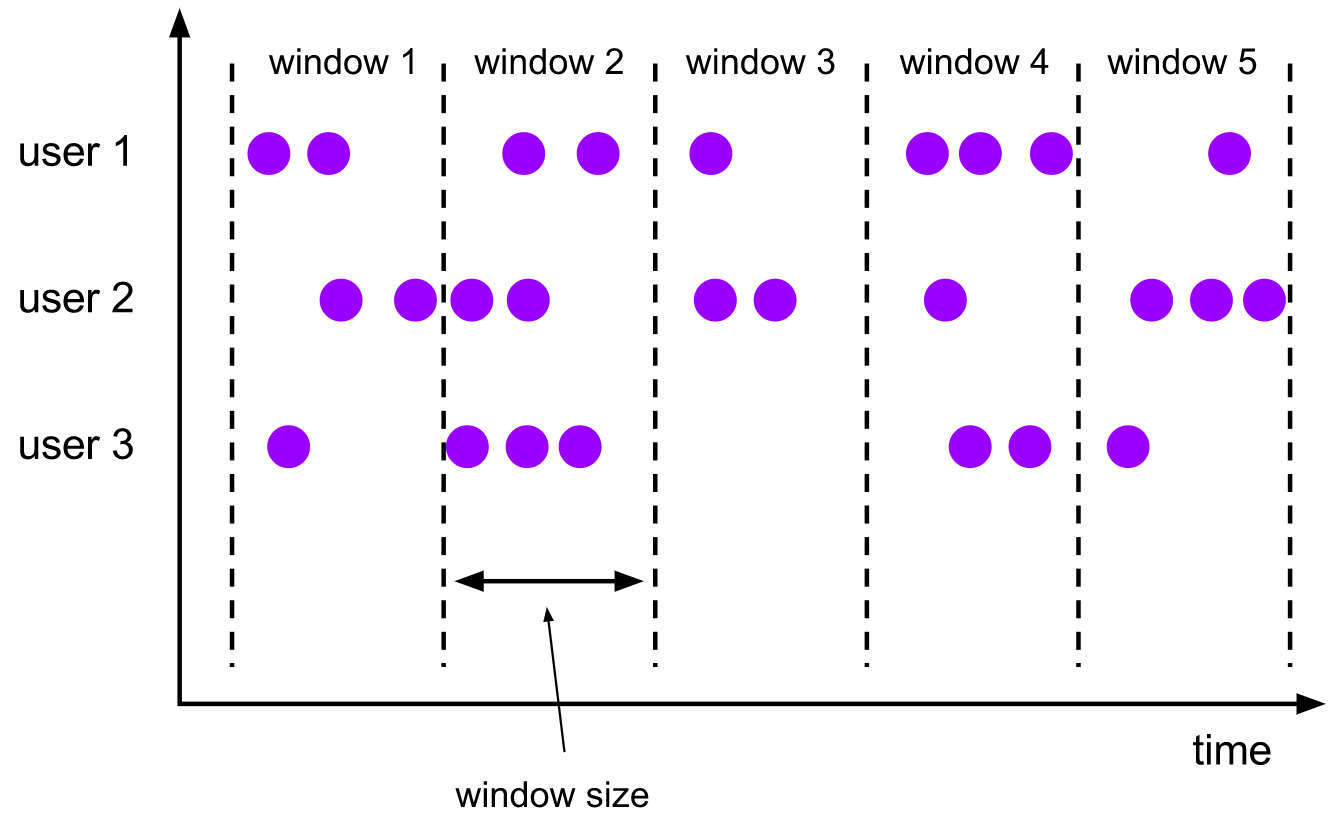
【特點】
- 將資料依據固定的視窗長度對資料進行切分
- 時間對齊,視窗長度固定,沒有重疊
【示例代碼】
TumblingEventTimeWindows:滾動事件時間視窗
TumblingProcessingTimeWindows:滾動處理時間視窗
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// tumbling processing-time windows
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>)
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
2)滑動視窗(Sliding Windows)
滑動視窗賦值器將元素賦值給固定長度的視窗,類似于滾動視窗賦值器,視窗的大小由視窗大小引數配置,另外一個視窗滑動引數控制滑動視窗啟動的頻率,因此,如果滑動視窗小于視窗大小,則滑動視窗可以重疊,在這種情況下,元素被分配給多個視窗,
例如,您可以將大小為10分鐘的視窗滑動5分鐘,這樣,每隔5分鐘就會出現一個視窗,其中包含在最后10分鐘內到達的事件,如下圖所示:
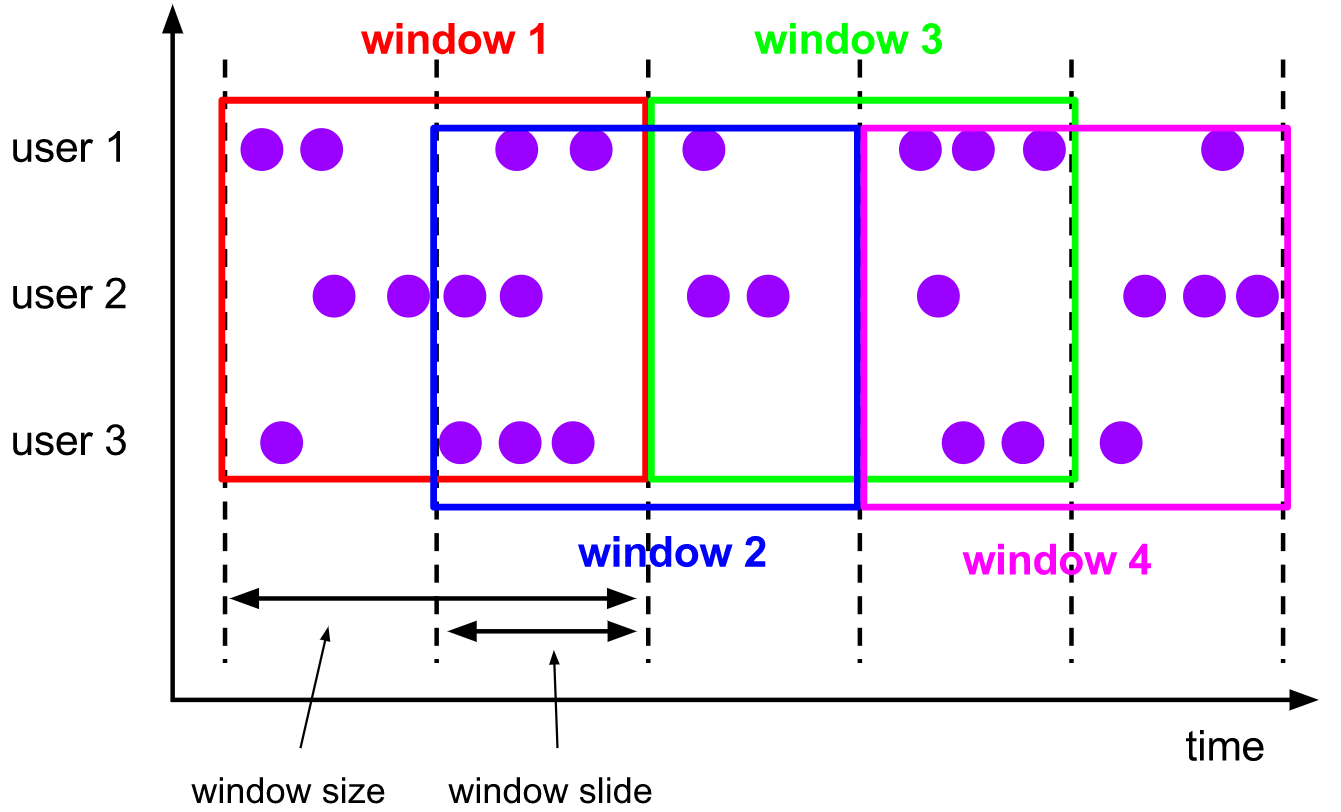
【特點】
- 滑動視窗是固定視窗的更廣義的一種形式,滑動視窗由固定的視窗
長度和滑動間隔組成 - 視窗長度固定,可以有重疊
【示例代碼】
SlidingEventTimeWindows:滑動事件時間視窗
SlidingProcessingTimeWindows:滑動處理時間視窗
val input: DataStream[T] = ...
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>)
// sliding processing-time windows offset by -8 hours
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.<windowed transformation>(<window function>)
3)會話視窗(Session Windows)
會話視窗分配器根據活動的會話對元素進行分組,與滑動視窗不同,會話視窗沒有重疊,也沒有固定的開始和結束時間,相反,當會話視窗在一段時間內沒有接收到元素時,即當一個不活動間隙發生時,會話視窗將關閉,會話視窗分配器可以配置一個靜態會話間隙,也可以配置一個會話間隙提取器函式,該函式定義了不活動的時間長度,當這段時間到期時,當前會話關閉,隨后的元素被分配到一個新的會話視窗,
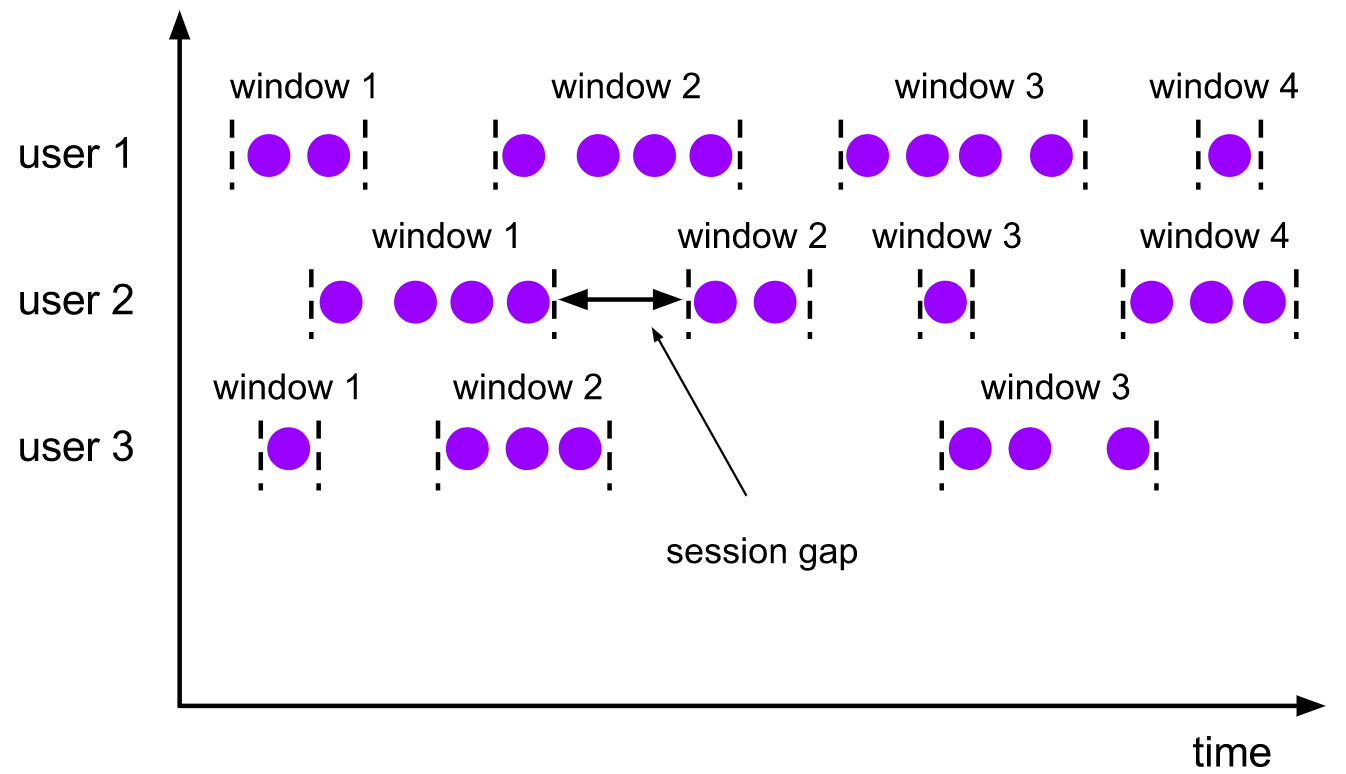
【特點】
- 由一系列事件組合一個指定時間長度的 timeout 間隙組成,也就是
一段時間沒有接收到新資料就會生成新的視窗 - 時間無對齊
- 視窗長度不固定,也不會重疊
【示例代碼】
EventTimeSessionWindows:會話事件時間視窗
SlidingProcessingTimeWindows:會話處理時間視窗
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>)
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// determine and return session gap
}
}))
.<windowed transformation>(<window function>)
三、window API
視窗分配器 —— window() 方法
- 我們可以用
.window()來定義一個視窗,然后基于這個 window 去做一些聚
合或者其它處理操作,注意 window () 方法必須在keyBy之后才能用, - Flink 提供了更加簡單的三種型別時間視窗用于定義時
間視窗,也提供了countWindowAll來定義計數視窗,
TumblingEventTimeWindows:滾動事件時間視窗
TumblingProcessingTimeWindows:滾動處理時間視窗
SlidingEventTimeWindows:滑動事件時間視窗
SlidingProcessingTimeWindows:滑動處理時間視窗
EventTimeSessionWindows:會話事件時間視窗
SlidingProcessingTimeWindows:會話處理時間視窗
四、視窗分配器(window assigner)
window function 定義了要對視窗中收集的資料做的計算操作,可以分為兩類,
1)增量聚合函式(incremental aggregation functions)
- 每條資料到來就進行計算,保持一個簡單的狀態
- ReduceFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
- AggregateFunction
val input: DataStream[(String, Long)] = ...
input
.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(new AverageAggregate)
2)全視窗函式(full window functions)
- 先把視窗所有資料收集起來,等到計算的時候會遍歷所有資料
- ProcessWindowFunction
一個ProcessWindowFunction可以這樣定義和使用:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
3)其它可選window API
- .trigger() —— 觸發器,定義 window 什么時候關閉,觸發計算并輸出結果
- .evictor() —— 移除器,定義移除某些資料的邏輯
- .allowedLateness() —— 允許處理遲到的資料
- .sideOutputLateData() —— 將遲到的資料放入側輸出流
- .getSideOutput() —— 獲取側輸出流
五、Flink 中的時間語意
官方檔案
Flink 明確支持以下三種時間語意:
-
事件時間(event time): 事件產生的時間,記錄的是設備生產(或者存盤)事件的時間
-
攝取時間(ingestion time): 資料進入Flink的時間,Flink 讀取事件時記錄的時間
-
處理時間(processing time):執行操作算子的本地系統時間,與機器相關
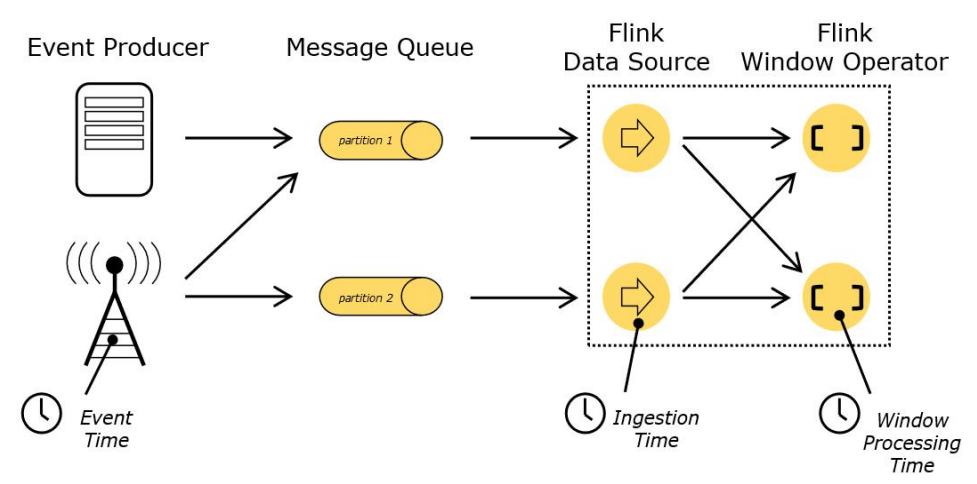
上面圖片來源:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/concepts/time/
六、設定 Event Time
我們可以直接在代碼中,對執行環境呼叫
setStreamTimeCharacteristic
方法,設定流的時間特性,具體的時間,還需要從資料中提取時間戳(timestamp)
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
var env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
七、水位線(Watermark)
官方檔案
1)為什么需要水位線(Watermark)
當 Flink 以 Event Time 模式處理資料流時,它會根據資料里的時間戳來
處理基于時間的算子,由于網路、分布式等原因,會導致亂序資料的產生,亂序資料會讓視窗計算不準確,Watermark正是處理亂序資料而來的,
2)如何利用Watermark處理亂序資料問題?
遇到一個時間戳達到了視窗關閉時間,不應該立刻觸發視窗計算,而是等
待一段時間,等遲到的資料來了再關閉視窗,
- Watermark 是一種衡量 Event Time 進展的機制,可以設定延遲觸發;
- Watermark 是用于處理亂序事件的,而正確的處理亂序事件,通常用
Watermark 機制結合 window 來實作; - 資料流中的 Watermark 用于表示 timestamp 小于 Watermark 的資料,
都已經到達了,因此,window 的執行也是由 Watermark 觸發的; - watermark 用來讓程式自己平衡延遲和結果正確性,
3)watermark 的特點
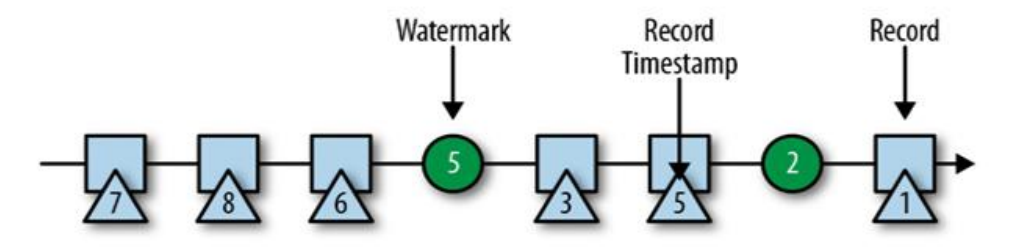
- watermark 是一條特殊的資料記錄
- watermark 必須單調遞增,以確保任務的事件時間時鐘在向前推進,而不
是在后退 - watermark 與資料的時間戳相關
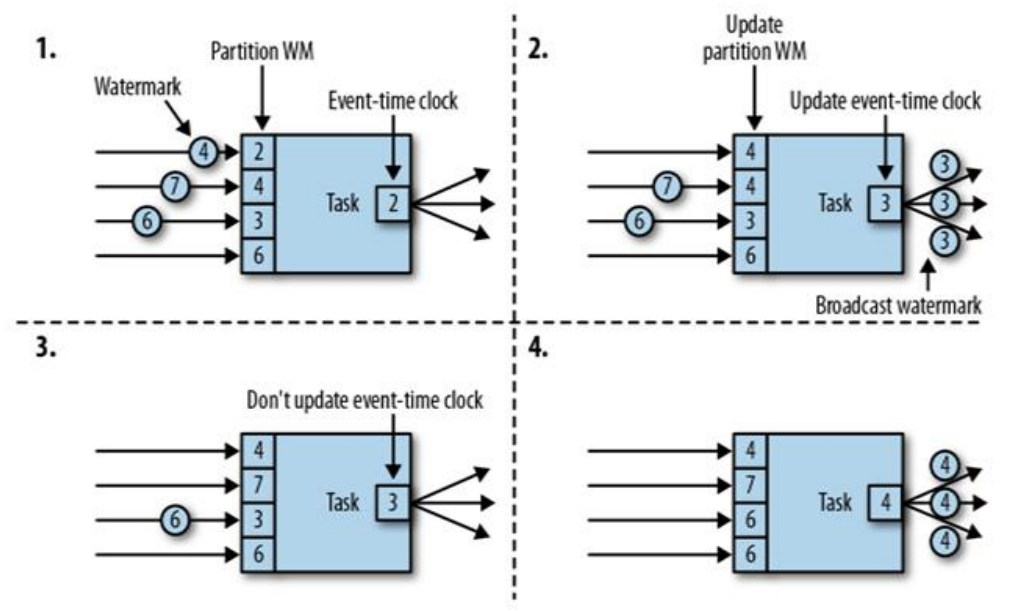
4)watermark 的傳遞
5)watermark 策略與應用
1)Watermark 策略簡介
時間戳的分配與 watermark 的生成是齊頭并進的,其可以告訴 Flink 應用程式事件時間的進度,其可以通過指定
WatermarkGenerator來配置 watermark 的生成方式,
使用 Flink API 時需要設定一個同時包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy,WatermarkStrategy 工具類中也提供了許多常用的 watermark 策略,并且用戶也可以在某些必要場景下構建自己的 watermark 策略,WatermarkStrategy 介面如下:
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{
/**
* 根據策略實體化一個可分配時間戳的 {@link TimestampAssigner},
*/
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
/**
* 根據策略實體化一個 watermark 生成器,
*/
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
通常情況下,你不用實作此介面,而是可以使用
WatermarkStrategy工具類中通用的watermark策略,或者可以使用這個工具類將自定義的TimestampAssigner與WatermarkGenerator進行系結,
【例如】你想要要使用有界無序(bounded-out-of-orderness)watermark 生成器和一個 lambda 運算式作為時間戳分配器,那么可以按照如下方式實作:
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner[(Long, String)] {
override def extractTimestamp(element: (Long, String), recordTimestamp: Long): Long = element._1
})
【溫馨提示】其中 TimestampAssigner 的設定與否是可選的,大多數情況下,可以不用去特別指定,
2)使用 Watermark 策略應用
WatermarkStrategy 可以在 Flink 應用程式中的兩處使用:
- 第一種是直接在資料源上使用
- 第二種是直接在非資料源的操作之后使用,
【溫馨提示】第一種方式相比會更好,因為資料源可以利用 watermark 生成邏輯中有關分片/磁區(shards/partitions/splits)的資訊,使用這種方式,資料源通常可以更精準地跟蹤 watermark,整體 watermark 生成將更精確,
【示例】僅當無法直接在資料源上設定策略時,才應該使用第二種方式(在任意轉換操作之后設定 WatermarkStrategy):
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream: DataStream[MyEvent] = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter())
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream
.filter( _.severity == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>)
withTimestampsAndWatermarks
.keyBy( _.getGroup )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) => a.add(b) )
.addSink(...)
【示例】處理空閑資料源
如果資料源中的某一個磁區/分片在一段時間內未發送事件資料,則意味著 WatermarkGenerator 也不會獲得任何新資料去生成 watermark,我們稱這類資料源為空閑輸入或空閑源,在這種情況下,當某些其他磁區仍然發送事件資料的時候就會出現問題,由于下游算子 watermark 的計算方式是取所有不同的上游并行資料源 watermark 的最小值,則其 watermark 將不會發生變化,
WatermarkStrategy
.forBoundedOutOfOrderness[(Long, String)](Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1))
3)使用場景
- 對于排好序的資料,不需要延遲觸發,可以只指定時間戳就行了,
// 注意時間是毫秒,所以根據時間戳不同,可能需要乘以1000
dataStream.assignAscendingTimestamps(_.timestamp * 1000)
- Flink 暴露了 TimestampAssigner 介面供我們實作,使我們可以自定義如
何從事件資料中抽取時間戳和生成watermark,
// MyAssigner 可以有兩種型別,都繼承自 TimestampAssigner
dataStream.assignAscendingTimestamps(new MyAssigner())
4)TimestampAssigner
定義了抽取時間戳,以及生成 watermark 的方法,有兩種型別
1、AssignerWithPeriodicWatermarks
- 周期性的生成 watermark:系統會周期性的將 watermark 插入到流中
- 默認周期是200毫秒,可以使用 ExecutionConfig.setAutoWatermarkInterval()
方法進行設定 - 升序和前面亂序的處理 BoundedOutOfOrderness ,都是基于周期性
watermark 的,
2、AssignerWithPunctuatedWatermarks
- 沒有時間周期規律,可打斷的生成 watermark
可以棄用 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 了
在 Flink 新的
WatermarkStrategy,TimestampAssigner和WatermarkGenerator的抽象介面之前,Flink 使用的是 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks,你仍可以在 API 中看到它們,但建議使用新介面,因為其對時間戳和 watermark 等重點的抽象和分離很清晰,并且還統一了周期性和標記形式的 watermark 生成方式,
5)WatermarkStrategy(重點)
flink1.11版本后 建議用
WatermarkStrategy(Watermark生成策略)生成Watermark,當創建DataStream物件后,使用如下方法指定策略:assignTimestampsAndWatermarks(WatermarkStrategy<T>)
通常情況下,你不用實作此介面,而是可以使用
WatermarkStrategy工具類中通用的 watermark 策略,或者可以使用這個工具類將自定義的 TimestampAssigner 與 WatermarkGenerator 進行系結,
1、固定亂序長度策略(forBoundedOutOfOrderness)
通過呼叫WatermarkStrategy物件上的forBoundedOutOfOrderness方法來實作,接收一個Duration型別的引數作為最大亂序(out of order)長度,WatermarkStrategy物件上的withTimestampAssigner方法為從事件資料中提取時間戳提供了介面,
【示例】
- ForBoundedOutOfOrderness.java
package com.com.streaming.watermarkstrategy;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
import java.time.LocalDateTime;
//在assignTimestampsAndWatermarks中用WatermarkStrategy.forBoundedOutOfOrderness方法抽取Timestamp和生成周期性水位線示例
public class ForBoundedOutOfOrderness {
public static void main(String[] args) throws Exception{
//創建流處理環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//設定EventTime語意
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//設定周期生成Watermark間隔(10毫秒)
env.getConfig().setAutoWatermarkInterval(10L);
//并行度1
env.setParallelism(1);
//演示資料
DataStreamSource<ClickEvent> mySource = env.fromElements(
new ClickEvent(LocalDateTime.now(), "user1", 1L, 1),
new ClickEvent(LocalDateTime.now(), "user1", 2L, 2),
new ClickEvent(LocalDateTime.now(), "user1", 3L, 3),
new ClickEvent(LocalDateTime.now(), "user1", 4L, 4),
new ClickEvent(LocalDateTime.now(), "user1", 5L, 5),
new ClickEvent(LocalDateTime.now(), "user1", 6L, 6),
new ClickEvent(LocalDateTime.now(), "user1", 7L, 7),
new ClickEvent(LocalDateTime.now(), "user1", 8L, 8)
);
//WatermarkStrategy.forBoundedOutOfOrderness周期性生成水位線
//可更好處理延遲資料
//BoundedOutOfOrdernessWatermarks<T>實作WatermarkGenerator<T>
SingleOutputStreamOperator<ClickEvent> streamTS = mySource.assignTimestampsAndWatermarks(
//指定Watermark生成策略,最大延遲長度5毫秒
WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofMillis(5))
.withTimestampAssigner(
//SerializableTimestampAssigner介面中實作了extractTimestamp方法來指定如何從事件資料中抽取時間戳
new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent event, long recordTimestamp) {
return event.getDateTime(event.getEventTime());
}
})
);
//結果列印
streamTS.print();
env.execute();
}
}
- ClickEvent.java
package com.com.streaming.watermarkstrategy;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
public class ClickEvent {
private String user;
private long l;
private int i;
private LocalDateTime eventTime;
public ClickEvent(LocalDateTime eventTime, String user, long l, int i) {
this.eventTime = eventTime;
this.user = user;
this.l = l;
this.i = i;
}
public LocalDateTime getEventTime() {
return eventTime;
}
public void setEventTime(LocalDateTime eventTime) {
this.eventTime = eventTime;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public long getL() {
return l;
}
public void setL(long l) {
this.l = l;
}
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public long getDateTime(LocalDateTime dt) {
ZoneOffset zoneOffset8 = ZoneOffset.of("+8");
return dt.toInstant(zoneOffset8).toEpochMilli();
}
}
2、單調遞增策略(forMonotonousTimestamps)
通過呼叫WatermarkStrategy物件上的forMonotonousTimestamps方法來實作,無需任何引數,相當于將forBoundedOutOfOrderness策略的最大亂序長度outOfOrdernessMillis設定為0,
- ForMonotonousTimestamps.java
package com.com.streaming.watermarkstrategy;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
import java.time.LocalDateTime;
public class ForMonotonousTimestamps {
public static void main(String[] args) throws Exception{
//創建流處理環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//設定EventTime語意
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//設定周期生成Watermark間隔(10毫秒)
env.getConfig().setAutoWatermarkInterval(10L);
//并行度1
env.setParallelism(1);
//演示資料
DataStreamSource<ClickEvent> mySource = env.fromElements(
new ClickEvent(LocalDateTime.now(), "user1", 1L, 1),
new ClickEvent(LocalDateTime.now(), "user1", 2L, 2),
new ClickEvent(LocalDateTime.now(), "user1", 3L, 3),
new ClickEvent(LocalDateTime.now(), "user1", 4L, 4),
new ClickEvent(LocalDateTime.now(), "user1", 5L, 5),
new ClickEvent(LocalDateTime.now(), "user1", 6L, 6),
new ClickEvent(LocalDateTime.now(), "user1", 7L, 7),
new ClickEvent(LocalDateTime.now(), "user1", 8L, 8)
);
//WatermarkStrategy.forMonotonousTimestamps周期性生成水位線
//相當于延遲outOfOrdernessMillis=0
//繼承自BoundedOutOfOrdernessWatermarks<T>
SingleOutputStreamOperator<ClickEvent> streamTS = mySource.assignTimestampsAndWatermarks(
WatermarkStrategy.<ClickEvent>forMonotonousTimestamps()
.withTimestampAssigner((event, recordTimestamp) -> event.getDateTime(event.getEventTime()))
);
//結果列印
streamTS.print();
env.execute();
}
}
3、不生成策略(noWatermarks)
WatermarkStrategy.noWatermarks()
- 當一個算子從多個上游算子中獲取資料時,會取上游最小的Watermark作為自身的Watermark,并檢測是否滿足視窗觸發條件,當達不到觸發條件,視窗會在記憶體中快取大量視窗資料,導致記憶體不足等問題,
- flink提供了設定流狀態為空閑的
withIdleness方法,在設定的超時時間內,當某個資料流一直沒有事件資料到達,就標記這個流為空閑,下游算子不需要等待這條資料流產生的Watermark,而取其他上游激活狀態的Watermark,來決定是否需要觸發視窗計算,
上面代碼設定超時時間5毫秒,超過這個時間,沒有生成Watermark,將流狀態設定空閑,當下次有新的Watermark生成并發送到下游時,重新設定為活躍,
WatermarkStrategy.withIdleness(Duration.ofMillis(5))
未完待續~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/472327.html
標籤:其他
上一篇:一文讀懂資料庫發展史