目錄
- 一、Flink中的狀態
- 1)鍵控狀態(Keyed State)
- 1、控制元件狀態特點
- 2、鍵控狀態型別
- 3、狀態有效期 (TTL)
- 1)過期資料的清理
- 2)全量快照時進行清理
- 3)增量資料清理
- 4)在 RocksDB 壓縮時清理
- 4、鍵控狀態的使用
- 2)算子狀態(Operatior State)
- 1、算子狀態特點
- 2、算子狀態型別
- 3)廣播狀態 (Broadcast State)
- 1)鍵控狀態(Keyed State)
- 二、狀態后端(State Backends)
- 1)三種狀態存盤方式
- 2)配置方式
- 1、【第一種方式】基于代碼方式進行配置
- 2、【第二種方式】基于 flink-conf.yaml 組態檔的方式進行配置
- 三、容錯機制(checkpoint)
- 1)一致性
- 2)檢查點(checkpoint)
- 1、開啟與配置 Checkpoint
- 2、Checkpoint 屬性
- 3)從檢查點恢復狀態
- 4)檢查點的實作演算法
- 5)檢查點演算法
- 1、檢查點分界線(Checkpoint Barrier)
- 2、Barrier對齊
- 3、執行一次檢查點步驟
- 6)保存點(savepoint)
- 1、概述
- 2、savepoint觸發的三種方式
- 7)檢查點(checkpoint)與 保存點(savepoint)的區別與聯系
一、Flink中的狀態
官方檔案
有狀態的計算是流處理框架要實作的重要功能,因為稍復雜的流處理場景都需要記錄狀態,然后在新流入資料的基礎上不斷更新狀態,下面的幾個場景都需要使用流處理的狀態功能:
- 資料流中的資料有重復,想對重復資料去重,需要記錄哪些資料已經流入過應用,當新資料流入時,根據已流入過的資料來判斷去重,
- 檢查輸入流是否符合某個特定的模式,需要將之前流入的元素以狀態的形式快取下來,比如,判斷一個溫度傳感器資料流中的溫度是否在持續上升,
- 對一個時間視窗內的資料進行聚合分析,分析一個小時內某項指標的75分位或99分位的數值,
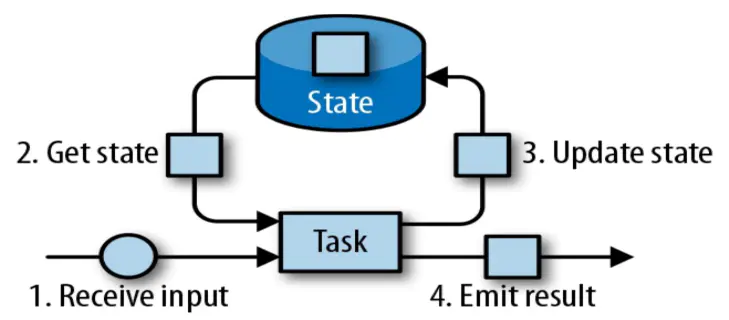
個狀態更新和獲取的流程如下圖所示,一個算子子任務接收輸入流,獲取對應的狀態,根據新的計算結果更新狀態,
1)鍵控狀態(Keyed State)
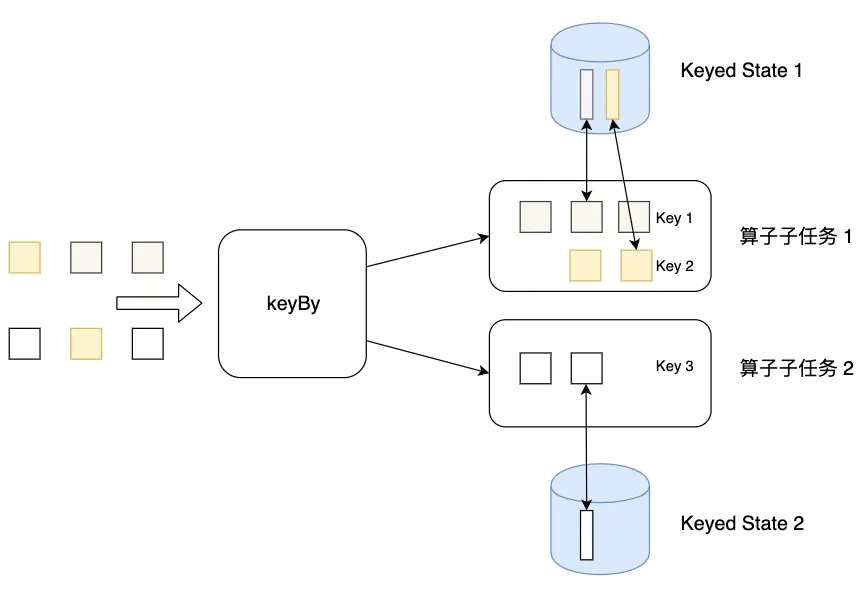
keyed state 介面提供不同型別狀態的訪問介面,這些狀態都作用于當前輸入資料的 key 下,換句話說,這些狀態僅可在 KeyedStream 上使用,在Java/Scala API上可以通過
stream.keyBy(...)得到 KeyedStream,在Python API上可以通過stream.key_by(...)得到 KeyedStream,
1、控制元件狀態特點
- 鍵控狀態是根據輸入資料流中定義的鍵(key)來維護和訪問的
- Flink 為每個 key 維護一個狀態實體,并將具有相同鍵的所有資料,都磁區到同一個算子任務中,這個任務會維護和處理這個 key 對應的狀態
- 當任務處理一條資料時,它會自動將狀態的訪問范圍限定為當前資料的 key
2、鍵控狀態型別
| 鍵控狀態型別 | 說明 | 方法 |
|---|---|---|
| ValueState[T] | 值狀態,保存一個可以更新和檢索的值 | ValueState.update(value: T) ValueState.value() |
| ListState[T] | 串列狀態,保存一個元素的串列可以往這個串列中追加資料,并在當前的串列上進行檢索, | ListState.add(value: T) ListState.addAll(values: java.util.List[T]) ListState.update(values: java.util.List[T]) ListState.get()(注意:回傳的是Iterable[T]) |
| ReducingState |
聚合狀態,保存一個單值,表示添加到狀態的所有值的聚合,介面與 ListState 類似,但使用 add(T) 增加元素,會使用提供的 ReduceFunction 進行聚合, | ReducingState.add(value: T) ReducingState.get() |
| AggregatingState<IN, OUT> | 聚合狀態,保留一個單值,表示添加到狀態的所有值的聚合,和 ReducingState 相反的是, 聚合型別可能與 添加到狀態的元素的型別不同, 介面與 ListState 類似,但使用 add(IN) 添加的元素會用指定的 AggregateFunction 進行聚合, | AggregatingState.add(value: T) AggregatingState.get() |
| MapState<UK, UV> | 映射狀態,維護了一個映射串列,保存Key-Value對, | MapState.get(key: K) MapState.put(key: K, value: V) MapState.contains(key: K) MapState.remove(key: K) |
【溫馨提示】所有型別的狀態還有一個
clear()方法,清除當前 key 下的狀態資料,也就是當前輸入元素的 key,
3、狀態有效期 (TTL)
任何型別的 keyed state 都可以有 有效期 (TTL),所有狀態型別都支持單元素的 TTL, 這意味著串列元素和映射元素將獨立到期,
【官網示例】
package com
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.state.ValueStateDescriptor
import org.apache.flink.api.common.time.Time
object StateTest001 {
def main(args: Array[String]): Unit = {
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build
val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String])
stateDescriptor.enableTimeToLive(ttlConfig)
}
}
TTL 配置有以下幾個選項:
- newBuilder 的第一個引數表示資料的有效期,是【必選項】,
- TTL 的更新策略(默認是 OnCreateAndWrite)
- StateTtlConfig.UpdateType.OnCreateAndWrite - 僅在創建和寫入時更新
- StateTtlConfig.UpdateType.OnReadAndWrite - 讀取時也更新
1)過期資料的清理
默認情況下,過期資料會在讀取的時候被洗掉,例如 ValueState#value,同時會有后臺執行緒定期清理(如果 StateBackend 支持的話),可以通過 StateTtlConfig 配置關閉后臺清理:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground
.build
2)全量快照時進行清理
可以啟用全量快照時進行清理的策略,這可以減少整個快照的大小,當前實作中不會清理本地的狀態,但從上次快斬訓復時,不會恢復那些已經洗掉的過期資料, 該策略可以通過 StateTtlConfig 配置進行配置:
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot
.build
【溫馨提示】這種策略在 RocksDBStateBackend 的增量
checkpoint模式下無效,
3)增量資料清理
另外可以選擇增量式清理狀態資料,在狀態訪問或/和處理時進行,如果某個狀態開啟了該清理策略,則會在存盤后端保留一個所有狀態的惰性全域迭代器, 每次觸發增量清理時,從迭代器中選擇已經過期的數進行清理,
4)在 RocksDB 壓縮時清理
如果使用 RocksDB state backend,則會啟用 Flink 為 RocksDB 定制的壓縮過濾器,RocksDB 會周期性的對資料進行合并壓縮從而減少存盤空間, Flink 提供的 RocksDB 壓縮過濾器會在壓縮時過濾掉已經過期的狀態資料,該特性可以通過 StateTtlConfig 進行配置:
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build
【注意】
- 如果沒有 state 訪問,也沒有處理資料,則不會清理過期資料,
- 增量清理會增加資料處理的耗時,
- 現在僅 Heap state backend 支持增量清除機制,在 RocksDB state backend 上啟用該特性無效,
- 如果 Heap state backend 使用同步快照方式,則會保存一份所有 key 的拷貝,從而防止并發修改問題,因此會增加記憶體的使用,但異步快照則沒有這個問題,
- 對已有的作業,這個清理方式可以在任何時候通過 StateTtlConfig 啟用或禁用該特性,比如從 savepoint 重啟后,
4、鍵控狀態的使用
除了上面描述的介面之外,Scala API 還在 KeyedStream 上對 map() 和 flatMap() 訪問 ValueState 提供了一個更便捷的介面
mapWithState, 用戶函式能夠通過 Option 獲取當前 ValueState 的值,并且回傳即將保存到狀態的值,
val stream: DataStream[(String, Int)] = ...
val counts: DataStream[(String, Int)] = stream
.keyBy(_._1)
.mapWithState((in: (String, Int), count: Option[Int]) =>
count match {
case Some(c) => ( (in._1, c), Some(c + in._2) )
case None => ( (in._1, 0), Some(in._2) )
})
2)算子狀態(Operatior State)
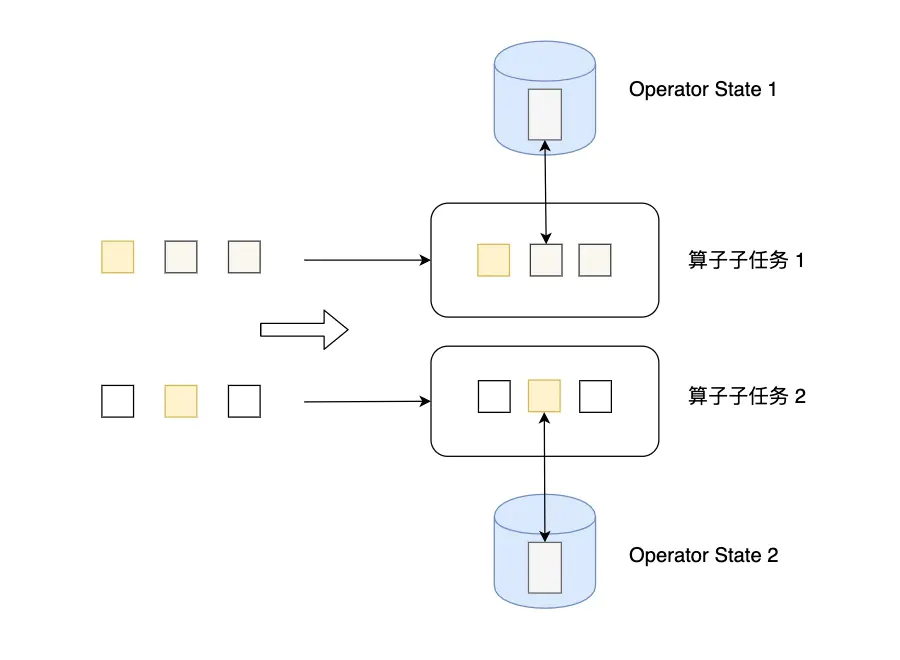
算子狀態(或者非 keyed 狀態)是系結到一個并行算子實體的狀態,Kafka Connector 是 Flink 中使用算子狀態一個很具有啟發性的例子,Kafka consumer 每個并行實體維護了 topic partitions 和偏移量的 map 作為它的算子狀態,
【溫馨提示】 Python DataStream API 仍無法支持算子狀態,
1、算子狀態特點
- 算子狀態的作用范圍限定為算子任務,由同一并行任務所處理的所有資料都可以訪問到相同的狀態
- 狀態對于同一子任務而言是共享的
- 算子狀態不能由相同或不同算子的另一個子任務訪問
2、算子狀態型別
| 鍵控狀態型別 | 說明 |
|---|---|
| 串列狀態(ListState) | 將狀態表示為一組資料的串列 |
| 聯合串列狀態(UnionListState) | 也將狀態表示為資料的串列,它與常規串列狀態的區別在于,在發生故障時,或者從保存點(savepoint)啟動應用程式時如何恢復 |
| 廣播狀態(BroadcastState) | 如果一個算子有多項任務,而它的每項任務狀態又都相同,那么這種特殊情況最適合應用廣播狀態, |
3)廣播狀態 (Broadcast State)
廣播狀態是一種特殊的算子狀態,引入它的目的在于支持一個流中的元素需要廣播到所有下游任務的使用情形,在這些任務中廣播狀態用于保持所有子任務狀態相同, 該狀態接下來可在第二個處理記錄的資料流中訪問,廣播狀態和其他算子狀態的不同之處在于:
- 它具有 map 格式,
- 它僅在一些特殊的算子中可用,這些算子的輸入為一個廣播資料流和非廣播資料流,
- 這類算子可以擁有不同命名的多個廣播狀態 ,
【溫馨提示】 Python DataStream API 仍無法支持算子狀態,
二、狀態后端(State Backends)
狀態的存盤、訪問以及維護,由一個可插入的組件決定,這個組件就
叫做狀態后端(state backend) ,狀態后端主要負責兩件事:本地的狀態管理,以及將檢查點(checkpoint)狀態寫入遠程存盤,
1)三種狀態存盤方式
| 存盤方式 | 說明 |
|---|---|
| MemoryStateBackend | 【默認模式】狀將鍵控狀態作為記憶體中的物件進行管理,將它們存盤在TaskManager的JVM堆上,將checkpoint存盤在JobManager的記憶體中,主要適用于本地開發和除錯, |
| FsStateBackend | 基于檔案系統進行存盤,可以是本地檔案系統,也可以是 HDFS 等分布式檔案系統, 需要注意而是雖然選擇使用了 FsStateBackend ,但正在進行的資料仍然是存盤在 TaskManager 的記憶體中的,只有在 checkpoint 時,才會將狀態快照寫入到指定檔案系統上, |
| RocksDBStateBackend | 將所有狀態序列化后,存入本地的RocksDB中存盤, |
【溫馨提示】特別在
MemoryStateBackend內使用HeapKeyedStateBackend時,Checkpoint 序列化資料階段默認有最大 5 MB資料的限制,
對于HeapKeyedStateBackend,有兩種實作:
- 支持異步 Checkpoint(默認):存盤格式 CopyOnWriteStateMap
- 僅支持同步 Checkpoint:存盤格式 NestedStateMap
2)配置方式
Flink 支持使用兩種方式來配置后端管理器:
1、【第一種方式】基于代碼方式進行配置
【溫馨提示】只對當前作業生效
// 配置 FsStateBackend
env.setStateBackend(new FsStateBackend("hdfs://namenode:port/flink/checkpoints"));
// 配置 RocksDBStateBackend
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:port/flink/checkpoints"));
配置 RocksDBStateBackend 時,需要額外匯入下面的依賴:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.9.0</version>
</dependency>
2、【第二種方式】基于 flink-conf.yaml 組態檔的方式進行配置
【溫馨提示】對所有部署在該集群上的作業都生效
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:port/flink/checkpoints
三、容錯機制(checkpoint)
checkpoint是Flink容錯的核心機制,它可以定期地將各個Operator處理的資料進行快照存盤( Snapshot ),如果Flink程式出現宕機,可以重新從這些快照中恢復資料,
1)一致性
談到容錯性,就沒法避免一致性這個概念,所謂一致性就是:成功處理故障并恢復之后得到的結果與沒有發生任何故障是得到的結果相比,前者的正確性,換句大白話,就是故障的發生是否影響得到的結果,在流處理程序,一致性分為3個級別:
at-most-once:至多一次,故障發生之后,計算結果可能丟失,就是無法保證結果的正確性;at-least-once:至少一次,計算結果可能大于正確值,但絕不會小于正確值,就是計算程式發生故障后可能多算,但是絕不可能少算;exactly-once:精確一次,系統保證發生故障后得到的計算結果的值和正確值一致;
Flink的容錯機制保證了exactly-once,也可以選擇at-least-once,Flink的容錯機制是通過對資料流不停的做快照(snapshot)實作的,
2)檢查點(checkpoint)
Flink 中的每個方法或算子都能夠是有狀態的,為了讓狀態容錯,Flink 需要為狀態添加
checkpoint(檢查點),Checkpoint 使得 Flink 能夠恢復狀態和在流中的位置,從而向應用提供和無故障執行時一樣的語意,官方檔案
1、開啟與配置 Checkpoint
默認情況下 checkpoint 是禁用的,通過呼叫
StreamExecutionEnvironment的enableCheckpointing(n)來啟用 checkpoint,里面的 n 是進行 checkpoint 的間隔,單位毫秒,
2、Checkpoint 屬性
| 屬性 | 說明 |
|---|---|
| 精確一次(exactly-once) | 你可以選擇向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中傳入一個模式來選擇保證等級級別, |
| checkpoint 超時 | 如果 checkpoint 執行的時間超過了該配置的閾值,還在進行中的 checkpoint 操作就會被拋棄, |
| checkpoints 之間的最小時間 | 該屬性定義在 checkpoint 之間需要多久的時間,以確保流應用在 checkpoint 之間有足夠的進展,如果值設定為了 5000, 無論 checkpoint 持續時間與間隔是多久,在前一個 checkpoint 完成時的至少五秒后會才開始下一個 checkpoint, |
| checkpoint 可容忍連續失敗次數 | 該屬性定義可容忍多少次連續的 checkpoint 失敗,超過這個閾值之后會觸發作業錯誤 fail over, 默認次數為“0”,這意味著不容忍 checkpoint 失敗,作業將在第一次 checkpoint 失敗時fail over, |
| 并發 checkpoint 的數目 | 默認情況下,在上一個 checkpoint 未完成(失敗或者成功)的情況下,系統不會觸發另一個 checkpoint,這確保了拓撲不會在 checkpoint 上花費太多時間,從而影響正常的處理流程, 不過允許多個 checkpoint 并行進行是可行的,對于有確定的處理延遲(例如某方法所呼叫比較耗時的外部服務),但是仍然想進行頻繁的 checkpoint 去最小化故障后重跑的 pipelines 來說,是有意義的, |
| externalized checkpoints | 你可以配置周期存盤 checkpoint 到外部系統中,Externalized checkpoints 將他們的元資料寫到持久化存盤上并且在 job 失敗的時候不會被自動洗掉, 這種方式下,如果你的 job 失敗,你將會有一個現有的 checkpoint 去恢復,更多的細節請看 Externalized checkpoints 的部署檔案, |
【官網示例】
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// 每 1000ms 開始一次 checkpoint
env.enableCheckpointing(1000)
// 高級選項:
// 設定模式為精確一次 (這是默認值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 確認 checkpoints 之間的時間會進行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必須在一分鐘內完成,否則就會被拋棄
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 允許兩個連續的 checkpoint 錯誤
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2)
// 同一時間只允許一個 checkpoint 進行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使用 externalized checkpoints,這樣 checkpoint 在作業取消后仍就會被保留
env.getCheckpointConfig().enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// 開啟實驗性的 unaligned checkpoints
env.getCheckpointConfig.enableUnalignedCheckpoints()
3)從檢查點恢復狀態
- 【第一步】遇到故障之后,第一步就是重啟應用
- 【第二步】是從 checkpoint 中讀取狀態,將狀態重置,從檢查點重新啟動應用程式后,其內部狀態與檢查點完成時的狀態完全相同
- 【第三步】開始消費并處理檢查點到發生故障之間的所有資料,這種檢查點的保存和恢復機制可以為應用程式狀態提供
“精確一次”(exactly- once)的一致性,因為所有算子都會保存檢查點并恢復其所有狀態,這樣一來所有的輸入流就都會被重置到檢查點完成時的位置
4)檢查點的實作演算法
- 【一種簡單的想法】:暫停應用,保存狀態到檢查點,再重新恢復應用
- 【Flink 的改進實作】:
- 基于 Chandy-Lamport 演算法的分布式快照
- 將檢查點的保存和資料處理分離開,不暫停整個應用
5)檢查點演算法
基于Chandy-Lamport演算法實作的分布式快照
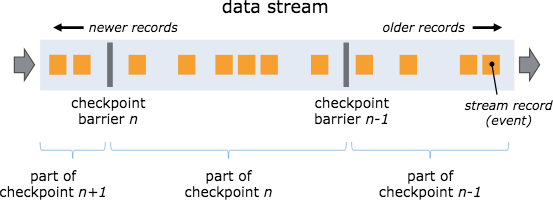
1、檢查點分界線(Checkpoint Barrier)
-
將barrier插入到資料流中,作為資料流的一部分和資料一起向下流動,Barrier不會干擾正常資料,資料流嚴格有序,
-
一個barrier把資料流分割成兩部分:一部分進入到當前快照,另一部分進入到下一個快照,
-
每一個barrier都帶有快照ID,并且barrier之前的資料都進入了此快照,Barrier不會干擾資料流處理,所以非常輕量,
-
多個不同快照的多個barrier會在流中同時出現,即多個快照可能同時創建,
2、Barrier對齊

當一個opeator有多個輸入流的時候,checkpoint barrier n 會進行對齊,就是已到達的會先快取到buffer里等待其他未到達的,一旦所有流都到達,則會向下游廣播,exactly-once 就是利用這一特性實作的,at least once 因為不會進行對齊,就會導致有的資料被重復處理,
3、執行一次檢查點步驟
- jobManager會向每個source任務發送一條帶有新檢查點ID的訊息,通過這種方式來啟動檢查點,
- 資料源將他們各自的狀態寫入檢查點后,并向下游所有磁區發出一個檢查點barrier,狀態后端在狀態存入檢查點之后,會回傳通知給source任務,source任務再向jobmanager確認檢查點完成,
- barrier向下游傳遞,下游任務會等待所有輸入磁區的barrier的到達后再做狀態保存通知jobmanager狀態保存完成,并再向下游所有磁區發送收到的檢查點barrier,
【溫馨提示】對于barrier已經到達的磁區,繼續到達的資料會被快取;對于barrier未到達的磁區,資料會被正常處理所有barrier都到達后,做完狀態保存且向下游發送檢查點barrier后,當前任務繼續處理快取的資料和后面到來的資料,
- sink任務向jobmanager確認狀態保存到checkpoint完成,即所有任務都確認已成功將狀態保存到檢查點時,檢查點就真正完成了,
6)保存點(savepoint)
1、概述
- Flink 還提供了可以自定義的鏡像保存功能,就是保存點(savepoints);
- 原則上,創建保存點使用的演算法與檢查點完全相同,因此保存點可以認為就是具有一些額外元資料的檢查點;
- Flink不會自動創建保存點,因此用戶(或者外部調度程式)必須明確地觸發創建操作;
- 保存點是一個強大的功能,除了故障恢復外,保存點可以用于:有計劃的手動備份,更新應用程式,版本遷移,暫停和重啟應用,等等,
2、savepoint觸發的三種方式
-
使用 flink savepoint 命令觸發 Savepoint,其是在程式運行期間觸發 savepoint,
-
使用 flink cancel -s 命令,取消作業時,并觸發 Savepoint,
-
使用 Rest API 觸發 Savepoint,格式為:/jobs/:jobid /savepoints
7)檢查點(checkpoint)與 保存點(savepoint)的區別與聯系
- checkpoint的側重點是“容錯”,即Flink作業意外失敗并重啟之后,能夠直接從早先打下的checkpoint恢復運行,且不影響作業邏輯的準確性,而savepoint的側重點是“維護”,即Flink作業需要在人工干預下手動重啟、升級、遷移或A/B測驗時,先將狀態整體寫入可靠存盤,維護完畢之后再從savepoint恢復現場,
- savepoint是“通過checkpoint機制”創建的,所以savepoint本質上是特殊的checkpoint,
- checkpoint面向Flink Runtime本身,由Flink的各個TaskManager定時觸發快照并自動清理,一般不需要用戶干預;savepoint面向用戶,完全根據用戶的需要觸發與清理,
- checkpoint的頻率往往比較高(因為需要盡可能保證作業恢復的準確度),所以checkpoint的存盤格式非常輕量級,但作為trade-off犧牲了一切可移植(portable)的東西,比如不保證改變并行度和升級的兼容性,savepoint則以二進制形式存盤所有狀態資料和元資料,執行起來比較慢而且“貴”,但是能夠保證portability,如并行度改變或代碼升級之后,仍然能正常恢復,
未完待續,請耐心等待~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/472404.html
標籤:其他