假設我有 N 個點,例如:
A = [2, 3]
B = [3, 4]
C = [3, 3]
等(實際上有很多,這就是為什么numpy)
他們持有numpy.array = [A, B, C,...]其中的結構:arr = np.array([[2, 3], [3, 4], [3, 3]])
combination我需要它們的距離作為輸出,BFS (Breadth First Search)以便跟蹤它的距離,例如:在這種情況下,對于上面的示例資料,A->B, A->C, B->C如果會有第二個浮點或純整數,它們將如何四舍五入并不重要,floor結果看起來像:[1.41, 1.0, 1.0]。
到目前為止,我嘗試了許多使用np.linalg.norm,np.sqrt np.square arr.reshape等math.hypot的方法......我得到了迭代解決方案,但是,這在 numpy 中效率不高,有沒有想法如何使用 numpy 來處理它以防止迭代解決方案?
我可以轉換我的資料,但是有必要,形成兩個陣列,其中一個包含X cords,第二個Y cords,但使用 numpy 特性執行非線性方法是我現在的心理瓶頸。歡迎任何建議,我不僅要求現成的解決方案,而且這些也將受到歡迎:)
@Edit:我必須使用 numpy 或核心庫來完成它。
uj5u.com熱心網友回復:
這是一個僅限 numpy 的解決方案(公平警告:它需要大量記憶體,不像pdist)...
dists = np.triu(np.linalg.norm(arr - arr[:, None], axis=-1)).flatten()
dists = dists[dists != 0]
演示:
In [4]: arr = np.array([[2, 3], [3, 4], [3, 3], [5, 2], [4, 5]])
In [5]: pdist(arr)
Out[5]:
array([1.41421356, 1. , 3.16227766, 2.82842712, 1. ,
2.82842712, 1.41421356, 2.23606798, 2.23606798, 3.16227766])
In [6]: dists = np.triu(np.linalg.norm(arr - arr[:, None], axis=-1)).flatten()
In [7]: dists = dists[dists != 0]
In [8]: dists
Out[8]:
array([1.41421356, 1. , 3.16227766, 2.82842712, 1. ,
2.82842712, 1.41421356, 2.23606798, 2.23606798, 3.16227766])
計時(上面的解決方案包含在一個名為 的函式中triu):
In [9]: %timeit pdist(arr)
7.27 μs ± 738 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
In [10]: %timeit triu(arr)
25.5 μs ± 4.58 μs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
uj5u.com熱心網友回復:
如果你可以使用它,SciPy 有一個功能:
In [2]: from scipy.spatial.distance import pdist
In [3]: pdist(arr)
Out[3]: array([1.41421356, 1. , 1. ])
uj5u.com熱心網友回復:
作為替代方法,但類似于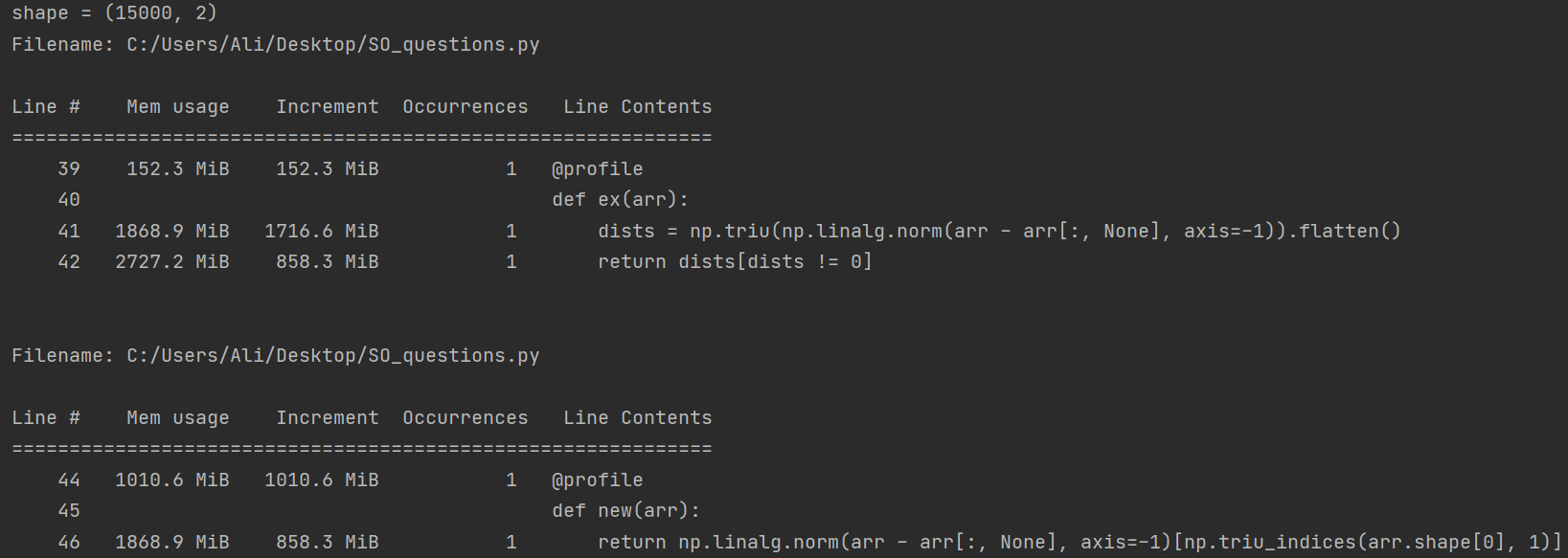
更新:
我試圖將計算限制在上三角形,這樣可以將測驗陣列上的代碼速度提高 2 到 3 倍。隨著陣列大小的增長,此回圈與之前的方法之間的性能差異np.triu_indices或np.triu增長并且更加明顯:
ind = np.arange(arr.shape[0] - 1)
sub_ind = ind 1
result = np.zeros(sub_ind.sum())
j = 0
for i in range(ind.shape[0]):
result[j:j ind[-1-i] 1] = np.linalg.norm(arr[ind[i]] - arr[sub_ind[i]:], axis=-1)
j = ind[-1-i] 1
而且,通過這種方式,至少減少了記憶體消耗~x4。因此,這種方法可以更快地處理更大的陣列。
基準:
# arr = np.random.rand(100, 2)
100 loops, best of 5: 459 μs per loop (ddejohns --> np.triu & np.flatten)
100 loops, best of 5: 528 μs per loop (mine --> np.triu_indices)
100 loops, best of 5: 1.42 ms per loop (This method)
--------------------------------------
# arr = np.random.rand(1000, 2)
10 loops, best of 5: 49.9 ms per loop
10 loops, best of 5: 49.7 ms per loop
10 loops, best of 5: 30.4 ms per loop (~x1.7) The fastest
--------------------------------------
# arr = np.random.rand(10000, 2)
2 loops, best of 5: 4.56 s per loop
2 loops, best of 5: 4.6 s per loop
2 loops, best of 5: 1.85 s per loop (~x2.5) The fastest
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/473562.html
標籤:Python 数组 python-3.x 麻木的 大数据
上一篇:chrome控制臺上的vanillajs錯誤“無法設定未定義的屬性”
下一篇:將資料網格中的值決議為按鈕名稱