我需要從資料框中找到連續的天數,但我在試圖找到它們時遇到了一些麻煩。我嘗試了 R、Excel 和 Python,但仍然找不到解決方案。
我的資料看起來像這樣
Date PRECTOT
1982/2/1 0.1
1982/2/2 0.14
1982/2/3 0
1982/2/6 0
1982/2/7 0
1982/2/8 0
1982/2/10 0
1982/2/11 0
1982/2/12 0
1982/2/15 0.18
1982/2/16 0
1982/2/20 0.08
1982/2/21 0
1982/2/22 0
1982/2/23 0
1982/2/24 0.03
1982/2/25 0
1982/2/26 0
1982/2/27 0
1982/2/28 0
1982/3/4 0
1982/3/5 0.05
1982/3/8 0.16
1982/3/9 0
我的預期輸出:
Date PRECTOT Consecutive
1982/2/1 0.1 3
1982/2/2 0.14
1982/2/3 0
1982/2/6 0 3
1982/2/7 0
1982/2/8 0
1982/2/10 0 3
1982/2/11 0
1982/2/12 0
1982/2/15 0.18 2
1982/2/16 0
1982/2/20 0.08 9
1982/2/21 0
1982/2/22 0
1982/2/23 0
1982/2/24 0.03
1982/2/25 0
1982/2/26 0
1982/2/27 0
1982/2/28 0
1982/3/4 0 2
1982/3/5 0.05
1982/3/8 0.16 2
1982/3/9 0
或者
Date PRECTOT Consecutive
1982/2/1 0.1 1
1982/2/2 0.14 2
1982/2/3 0 3
1982/2/6 0 1
1982/2/7 0 2
1982/2/8 0 3
1982/2/10 0 1
1982/2/11 0 2
1982/2/12 0 3
1982/2/15 0.18 1
1982/2/16 0 2
1982/2/20 0.08 1
1982/2/21 0 2
1982/2/22 0 3
1982/2/23 0 4
1982/2/24 0.03 5
1982/2/25 0 6
1982/2/26 0 7
1982/2/27 0 8
1982/2/28 0 9
1982/3/4 0 1
1982/3/5 0.05 2
1982/3/8 0.16 1
1982/3/9 0 2
可以格式化連續值,我只需要找出連續值。我想找到一個解決方案,但我不知道該怎么做。(R/Python/Excel)
uj5u.com熱心網友回復:
您可以嘗試使用 R 方法dplyr:
library(dplyr)
df %>%
group_by(grp = cumsum(c(0, diff(as.Date(Date, "%Y/%m/%d"))) > 1)) %>%
mutate(Consecutive = row_number()) %>%
ungroup() %>%
select(-grp)
這回傳
# A tibble: 24 x 3
Date PRECTOT Consecutive
<chr> <dbl> <int>
1 1982/2/1 0.1 1
2 1982/2/2 0.14 2
3 1982/2/3 0 3
4 1982/2/6 0 1
5 1982/2/7 0 2
6 1982/2/8 0 3
7 1982/2/10 0 1
8 1982/2/11 0 2
9 1982/2/12 0 3
10 1982/2/15 0.18 1
11 1982/2/16 0 2
12 1982/2/20 0.08 1
13 1982/2/21 0 2
14 1982/2/22 0 3
15 1982/2/23 0 4
16 1982/2/24 0.03 5
17 1982/2/25 0 6
18 1982/2/26 0 7
19 1982/2/27 0 8
20 1982/2/28 0 9
21 1982/3/4 0 1
22 1982/3/5 0.05 2
23 1982/3/8 0.16 1
24 1982/3/9 0 2
要將其匯出到 excel,您可以使用以下openxlsx包:
library(openxlsx)
library(dplyr)
df %>%
group_by(grp = cumsum(c(0, diff(as.Date(Date, "%Y/%m/%d"))) > 1)) %>%
mutate(Consecutive = row_number()) %>%
ungroup() %>%
select(-grp) %>%
write.xlsx("my_excel_file.xlsx")
這會給你一個這樣的 Excel 檔案:
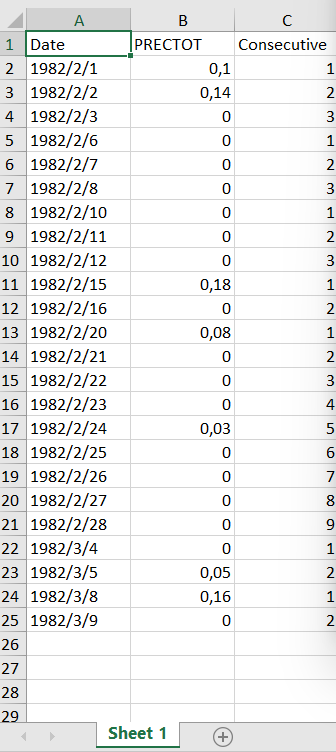
uj5u.com熱心網友回復:
我會用pandas.
假設df您有一個輸入表,并且Date列具有pd.Timestamp型別。我想應用于rolling列Date,它只支持數字型別的操作,所以我先將它轉換為納秒:
from operator import attrgetter
date_ns = df.Date.apply(attrgetter("value")) # df.Date.dt.value will not work :(
然后對于列中的每個日期,Date我將映射列中1的前一個日期Date是否是實際日歷中的前一天:
ONE_DAY = pd.Timedelta(days=1).value
def apply_func(x):
if len(x) == 2 and x[1] - x[0] == ONE_DAY:
return 1
return 0
prev_is_prev = date_ns.rolling(2, min_periods=1).apply(apply_func)
我們現在需要的是cumsum:
df["Consecutive"] = prev_is_prev.cumsum() 1
uj5u.com熱心網友回復:
Excel 365 Pro Plus 與 Power Pivot 和 Power Query。按連續天數分析。使用表格、資料透視表和資料透視圖。使用 DAX 和 M。沒有公式。 https://www.mediafire.com/file/fokbov6iyc3d6m4/05_14_22.xlsx/file https://www.mediafire.com/file/qitua9ipzcaxnoy/05_14_22.pdf/file
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/474373.html