如果有這樣的資料框:
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']
})
我有一本名為 tag_dict 的字典:
{'1': {'Granted'},
'3': {'Granted'}}
字典的鍵與資料框 ID 列中的一些 ID 匹配。現在,我想在 Dataframe 中創建一個新列“Tag”,這樣
- 如果 ID 列中的值與字典的鍵匹配,那么我們必須將該鍵的值放在字典中,否則在該欄位中放置“-”
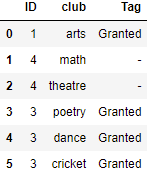
輸出應如下所示:
df = PD.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket'],
'tag':['Granted','-','-','Granted','Granted','Granted']
})
uj5u.com熱心網友回復:
我不確定大括號的用途是什么,Granted但您可以使用 apply:
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']
})
tag_dict = {'1': 'Granted',
'3': 'Granted'}
df['tag'] = df['ID'].apply(lambda x: tag_dict.get(x, '-'))
print(df)
輸出:
ID club tag
0 1 arts Granted
1 4 math -
2 4 theatre -
3 3 poetry Granted
4 3 dance Granted
5 3 cricket Granted
uj5u.com熱心網友回復:
解決方案.map:
df["tag"] = df["ID"].map(dct).apply(lambda x: "-" if pd.isna(x) else [*x][0])
print(df)
印刷:
ID club tag
0 1 arts Granted
1 4 math -
2 4 theatre -
3 3 poetry Granted
4 3 dance Granted
5 3 cricket Granted
uj5u.com熱心網友回復:
import pandas as pd
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']})
# I've removed the {} around your items. Feel free to add more key:value pairs
my_dict = {'1': 'Granted', '3': 'Granted'}
# use .map() to match your keys to their values
df['Tag'] = df['ID'].map(my_dict)
# if required, fill in NaN values with '-'
nan_rows = df['Tag'].isna()
df.loc[nan_rows, 'Tag'] = '-'
df
最終結果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/477309.html
上一篇:為什么我的字典資料被覆寫?