索引是一種資料結構,用于幫助我們在大量資料中快速定位到我們想要查找的資料,
索引最形象的比喻就是圖書的目錄了,注意這里的大量,資料量大了索引才顯得有意義,如果我想要在 [1,2,3,4] 中找到 4 這個資料,直接對全資料檢索也很快,沒有必要費力氣建索引再去查找,
索引在 MySQL 資料庫中分三類:
- B+ 樹索引
- Hash 索引
- 全文索引
我們今天要介紹的是作業開發中最常接觸到的 InnoDB 存盤引擎中的 B+ 樹索引,要介紹 B+ 樹索引,就不得不提二叉查找樹,平衡二叉樹和 B 樹這三種資料結構,B+ 樹就是從他們仨演化來的,
二叉查找樹
首先,讓我們先看一張圖:
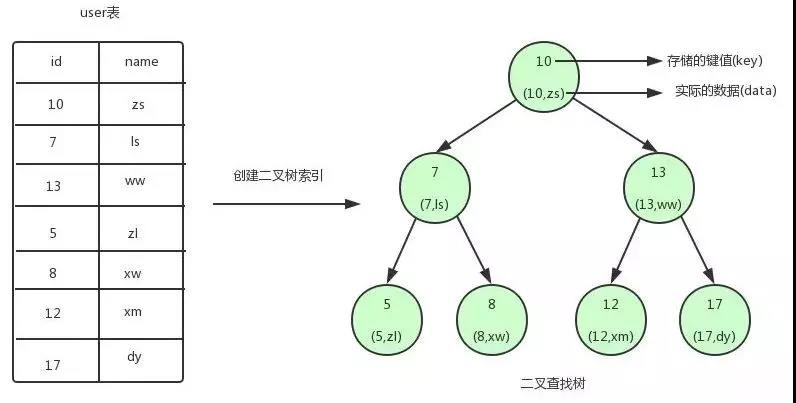
從圖中可以看到,我們為 user 表(用戶資訊表)建立了一個二叉查找樹的索引,
圖中的圓為二叉查找樹的節點,節點中存盤了鍵(key)和資料(data),鍵對應 user 表中的 id,資料對應 user 表中的行資料,
二叉查找樹的特點就是任何節點的左子節點的鍵值都小于當前節點的鍵值,右子節點的鍵值都大于當前節點的鍵值,頂端的節點我們稱為根節點,沒有子節點的節點我們稱之為葉節點,
如果我們需要查找 id=12 的用戶資訊,利用我們創建的二叉查找樹索引,查找流程如下:
- 將根節點作為當前節點,把 12 與當前節點的鍵值 10 比較,12 大于 10,接下來我們把當前節點>的右子節點作為當前節點,
- 繼續把 12 和當前節點的鍵值 13 比較,發現 12 小于 13,把當前節點的左子節點作為當前節點,
- 把 12 和當前節點的鍵值 12 對比,12 等于 12,滿足條件,我們從當前節點中取出 data,即 id=12,name=xm,
利用二叉查找樹我們只需要 3 次即可找到匹配的資料,如果在表中一條條的查找的話,我們需要 6 次才能找到,
平衡二叉樹
上面我們講解了利用二叉查找樹可以快速的找到資料,但是,如果上面的二叉查找樹是這樣的構造:
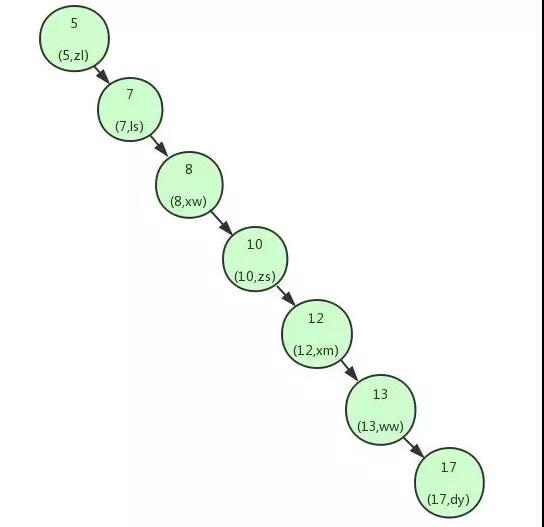
這個時候可以看到我們的二叉查找樹變成了一個鏈表,如果我們需要查找 id=17 的用戶資訊,我們需要查找 7 次,也就相當于全表掃描了, 導致這個現象的原因其實是二叉查找樹變得不平衡了,也就是高度太高了,從而導致查找效率的不穩定,為了解決這個問題,我們需要保證二叉查找樹一直保持平衡,就需要用到平衡二叉樹了, 平衡二叉樹又稱 AVL 樹,在滿足二叉查找樹特性的基礎上,要求每個節點的左右子樹的高度差不能超過 1, 下面是平衡二叉樹和非平衡二叉樹的對比:
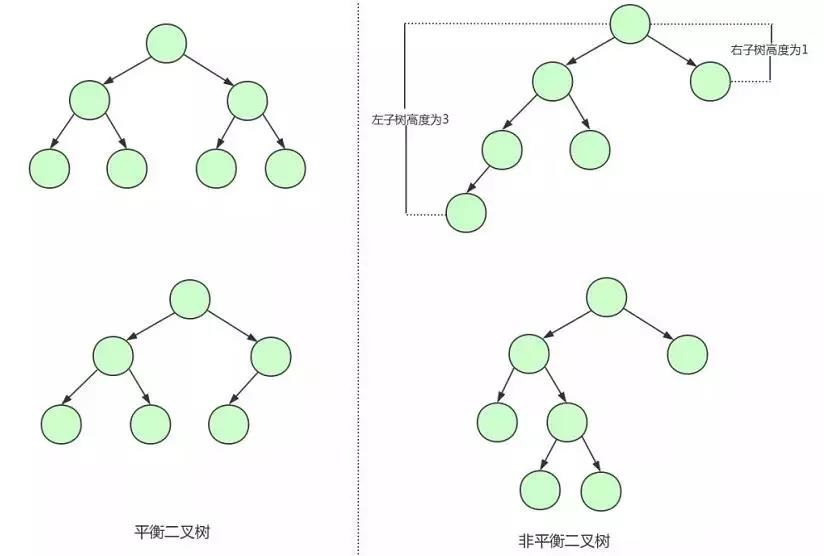
由平衡二叉樹的構造我們可以發現第一張圖中的二叉樹其實就是一棵平衡二叉樹,
平衡二叉樹保證了樹的構造是平衡的,當我們插入或洗掉資料導致不滿足平衡二叉樹不平衡時,平衡二叉樹會進行調整樹上的節點來保持平衡,具體的調整方式這里就不介紹了,平衡二叉樹相比于二叉查找樹來說,查找效率更穩定,總體的查找速度也更快,
B 樹
因為記憶體的易失性,一般情況下,我們都會選擇將 user 表中的資料和索引存盤在磁盤這種外圍設備中,但是和記憶體相比,從磁盤中讀取資料的速度會慢上百倍千倍甚至萬倍,所以,我們應當盡量減少從磁盤中讀取資料的次數,另外,從磁盤中讀取資料時,都是按照磁盤塊來讀取的,并不是一條一條的讀,如果我們能把盡量多的資料放進磁盤塊中,那一次磁盤讀取操作就會讀取更多資料,那我們查找資料的時間也會大幅度降低,如果我們用樹這種資料結構作為索引的資料結構,那我們每查找一次資料就需要從磁盤中讀取一個節點,也就是我們說的一個磁盤塊,我們都知道平衡二叉樹可是每個節點只存盤一個鍵值和資料的,那說明什么?說明每個磁盤塊僅僅存盤一個鍵值和資料!那如果我們要存盤海量的資料呢?
可以想象到二叉樹的節點將會非常多,高度也會極其高,我們查找資料時也會進行很多次磁盤 IO,我們查找資料的效率將會極低!
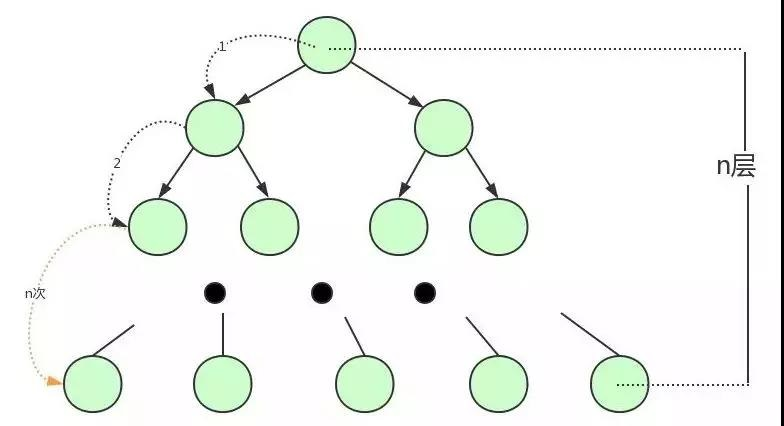
為了解決平衡二叉樹的這個弊端,我們應該尋找一種單個節點可以存盤多個鍵值和資料的平衡樹,也就是我們接下來要說的 B 樹,
B 樹(Balance Tree)即為平衡樹的意思,下圖即是一棵 B 樹:
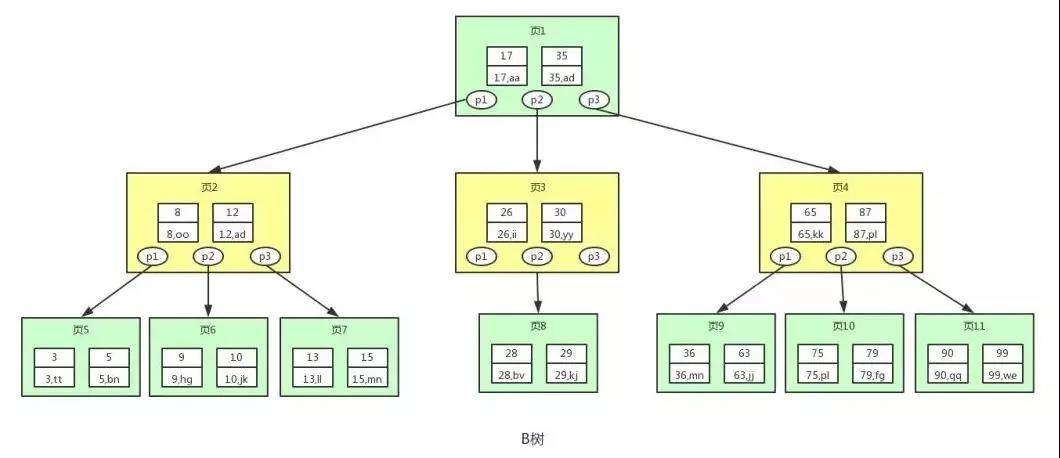
圖中的 p 節點為指向子節點的指標,二叉查找樹和平衡二叉樹其實也有,因為圖的美觀性,被省略了,
圖中的每個節點稱為頁,頁就是我們上面說的磁盤塊,在 MySQL 中資料讀取的基本單位都是頁,所以我們這里叫做頁更符合 MySQL 中索引的底層資料結構,
從上圖可以看出,B 樹相對于平衡二叉樹,每個節點存盤了更多的鍵值(key)和資料(data),并且每個節點擁有更多的子節點,子節點的個數一般稱為階,上述圖中的 B 樹為 3 階 B 樹,高度也會很低,
基于這個特性,B 樹查找資料讀取磁盤的次數將會很少,資料的查找效率也會比平衡二叉樹高很多,
假如我們要查找 id=28 的用戶資訊,那么我們在上圖 B 樹中查找的流程如下:
- 先找到根節點也就是頁 1,判斷 28 在鍵值 17 和 35 之間,那么我們根據頁 1 中的指標 p2 找到頁 3,
- 將 28 和頁 3 中的鍵值相比較,28 在 26 和 30 之間,我們根據頁 3 中的指標 p2 找到頁 8,
- 將 28 和頁 8 中的鍵值相比較,發現有匹配的鍵值 28,鍵值 28 對應的用戶資訊為(28,bv),
B+ 樹
B+ 樹是對 B 樹的進一步優化,讓我們先來看下 B+ 樹的結構圖:
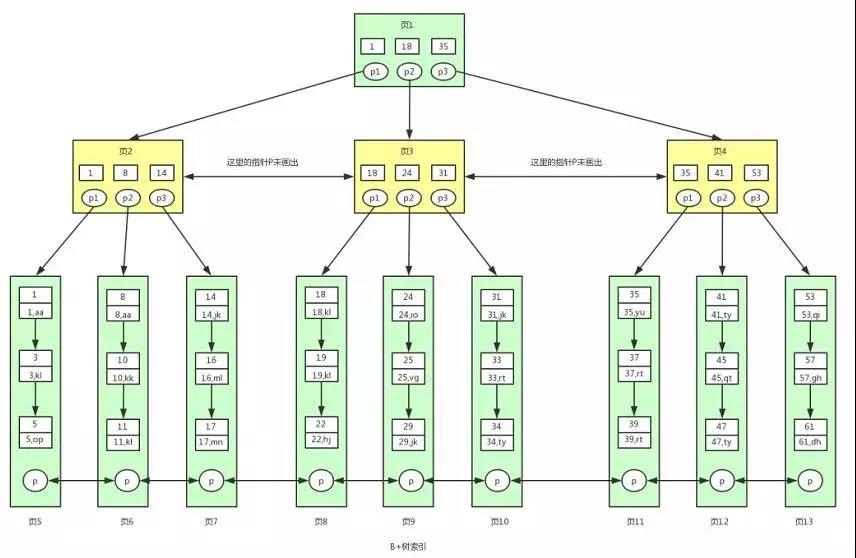
根據上圖我們來看下 B+ 樹和 B 樹有什么不同:
①B+ 樹非葉子節點上是不存盤資料的,僅存盤鍵值,而 B 樹節點中不僅存盤鍵值,也會存盤資料,
之所以這么做是因為在資料庫中頁的大小是固定的,InnoDB 中頁的默認大小是 16KB,
如果不存盤資料,那么就會存盤更多的鍵值,相應的樹的階數(節點的子節點樹)就會更大,樹就會更矮更胖,如此一來我們查找資料進行磁盤的 IO 次數又會再次減少,資料查詢的效率也會更快,
另外,B+ 樹的階數是等于鍵值的數量的,如果我們的 B+ 樹一個節點可以存盤 1000 個鍵值,那么 3 層 B+ 樹可以存盤 1000×1000×1000=10 億個資料,
一般根節點是常駐記憶體的,所以一般我們查找 10 億資料,只需要 2 次磁盤 IO,
②因為 B+ 樹索引的所有資料均存盤在葉子節點,而且資料是按照順序排列的,
那么 B+ 樹使得范圍查找,排序查找,分組查找以及去重查找變得例外簡單,而 B 樹因為資料分散在各個節點,要實作這一點是很不容易的,
有心的讀者可能還發現上圖 B+ 樹中各個頁之間是通過雙向鏈表連接的,葉子節點中的資料是通過單向鏈表連接的,
其實上面的 B 樹我們也可以對各個節點加上鏈表,這些不是它們之前的區別,是因為在 MySQL 的 InnoDB 存盤引擎中,索引就是這樣存盤的,
也就是說上圖中的 B+ 樹索引就是 InnoDB 中 B+ 樹索引真正的實作方式,準確的說應該是聚集索引(聚集索引和非聚集索引下面會講到),
通過上圖可以看到,在 InnoDB 中,我們通過資料頁之間通過雙向鏈表連接以及葉子節點中資料之間通過單向鏈表連接的方式可以找到表中所有的資料,
MyISAM 中的 B+ 樹索引實作與 InnoDB 中的略有不同,在 MyISAM 中,B+ 樹索引的葉子節點并不存盤資料,而是存盤資料的檔案地址,
聚集索引 VS 非聚集索引
在上節介紹 B+ 樹索引的時候,我們提到了圖中的索引其實是聚集索引的實作方式,
那什么是聚集索引呢?在 MySQL 中,B+ 樹索引按照存盤方式的不同分為聚集索引和非聚集索引,
這里我們著重介紹 InnoDB 中的聚集索引和非聚集索引:
①聚集索引(聚簇索引):以 InnoDB 作為存盤引擎的表,表中的資料都會有一個主鍵,即使你不創建主鍵,系統也會幫你創建一個隱式的主鍵,
這是因為 InnoDB 是把資料存放在 B+ 樹中的,而 B+ 樹的鍵值就是主鍵,在 B+ 樹的葉子節點中,存盤了表中所有的資料,
這種以主鍵作為 B+ 樹索引的鍵值而構建的 B+ 樹索引,我們稱之為聚集索引,
②非聚集索引(非聚簇索引):以主鍵以外的列值作為鍵值構建的 B+ 樹索引,我們稱之為非聚集索引,
非聚集索引與聚集索引的區別在于非聚集索引的葉子節點不存盤表中的資料,而是存盤該列對應的主鍵,想要查找資料我們還需要根據主鍵再去聚集索引中進行查找,這個再根據聚集索引查找資料的程序,我們稱為回表,
明白了聚集索引和非聚集索引的定義,我們應該明白這樣一句話:資料即索引,索引即資料,
利用聚集索引和非聚集索引查找資料
前面我們講解 B+ 樹索引的時候并沒有去說怎么在 B+ 樹中進行資料的查找,主要就是因為還沒有引出聚集索引和非聚集索引的概念,
下面我們通過講解如何通過聚集索引以及非聚集索引查找資料表中資料的方式介紹一下 B+ 樹索引查找資料方法,
利用聚集索引查找資料
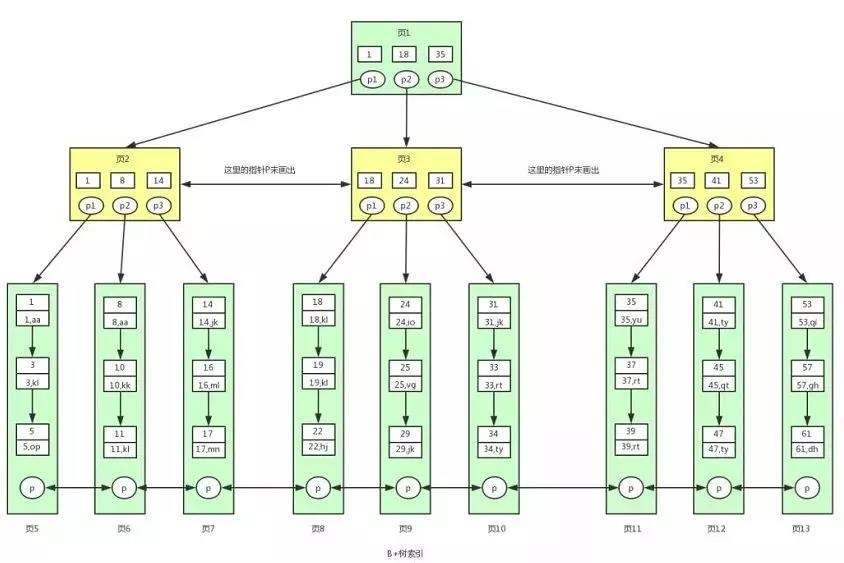
還是這張 B+ 樹索引圖,現在我們應該知道這就是聚集索引,表中的資料存盤在其中,
現在假設我們要查找 id>=18 并且 id<40 的用戶資料,對應的 sql 陳述句為:
select * from user where id>=18 and id <40
其中 id 為主鍵,具體的查找程序如下:
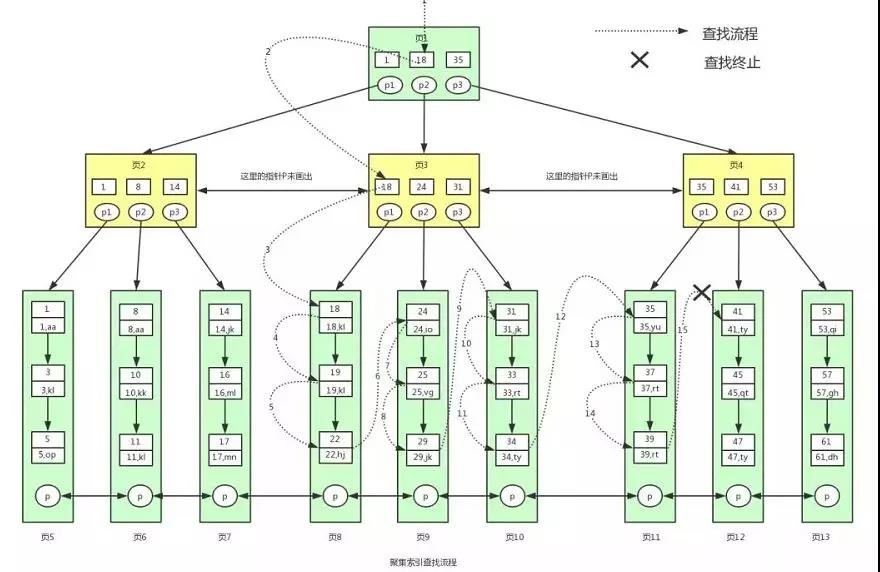
①一般根節點都是常駐記憶體的,也就是說頁 1 已經在記憶體中了,此時不需要到磁盤中讀取資料,直接從記憶體中讀取即可,
從記憶體中讀取到頁 1,要查找這個 id>=18 and id <40 或者范圍值,我們首先需要找到 id=18 的鍵值,
從頁 1 中我們可以找到鍵值 18,此時我們需要根據指標 p2,定位到頁 3,
②要從頁 3 中查找資料,我們就需要拿著 p2 指標去磁盤中進行讀取頁 3,
從磁盤中讀取頁 3 后將頁 3 放入記憶體中,然后進行查找,我們可以找到鍵值 18,然后再拿到頁 3 中的指標 p1,定位到頁 8,
③同樣的頁 8 頁不在記憶體中,我們需要再去磁盤中將頁 8 讀取到記憶體中,
將頁 8 讀取到記憶體中后,因為頁中的資料是鏈表進行連接的,而且鍵值是按照順序存放的,此時可以根據二分查找法定位到鍵值 18,
此時因為已經到資料頁了,此時我們已經找到一條滿足條件的資料了,就是鍵值 18 對應的資料,
因為是范圍查找,而且此時所有的資料又都存在葉子節點,并且是有序排列的,那么我們就可以對頁 8 中的鍵值依次進行遍歷查找并匹配滿足條件的資料,
我們可以一直找到鍵值為 22 的資料,然后頁 8 中就沒有資料了,此時我們需要拿著頁 8 中的 p 指標去讀取頁 9 中的資料,
④因為頁 9 不在記憶體中,就又會加載頁 9 到記憶體中,并通過和頁 8 中一樣的方式進行資料的查找,直到將頁 12 加載到記憶體中,發現 41 大于 40,此時不滿足條件,那么查找到此終止,
最終我們找到滿足條件的所有資料,總共 12 條記錄:
(18,kl), (19,kl), (22,hj), (24,io), (25,vg) , (29,jk), (31,jk) , (33,rt) , (34,ty) , (35,yu) , (37,rt) , (39,rt) ,
下面看下具體的查找流程圖
利用非聚集索引查找資料
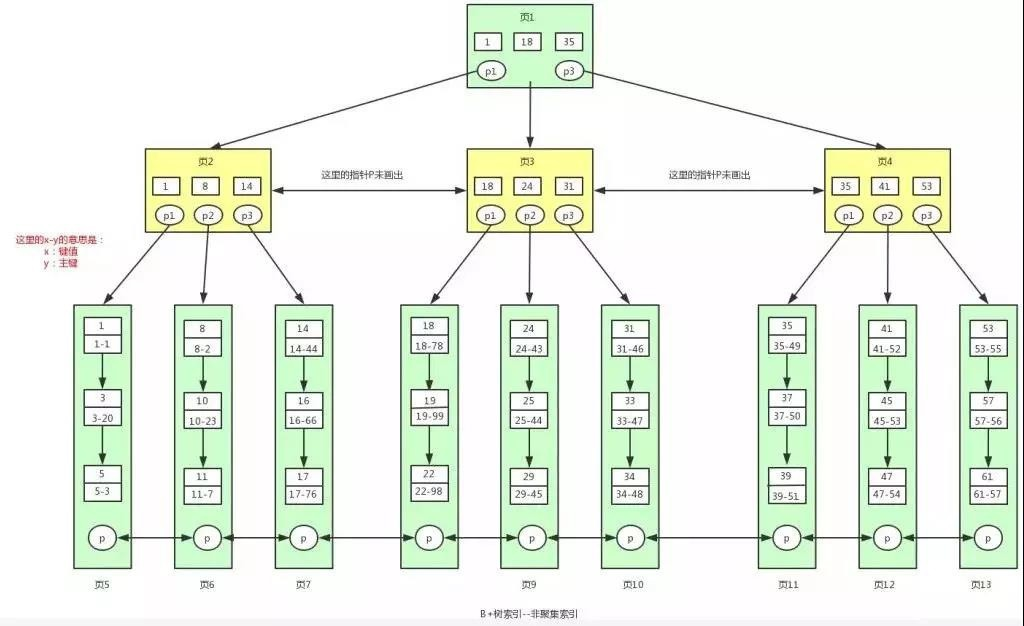
讀者看到這張圖的時候可能會蒙,這是啥東西啊?怎么都是數字,如果有這種感覺,請仔細看下圖中紅字的解釋,
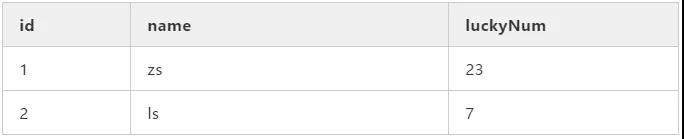
什么?還看不懂?那我再來解釋下吧,首先,這個非聚集索引表示的是用戶幸運數字的索引(為什么是幸運數字?一時興起想起來的:-)),此時表結構是這樣的,
在葉子節點中,不再存盤所有的資料了,存盤的是鍵值和主鍵,對于葉子節點中的 x-y,比如 1-1,左邊的 1 表示的是索引的鍵值,右邊的 1 表示的是主鍵值,
如果我們要找到幸運數字為 33 的用戶資訊,對應的 sql 陳述句為:
select * from user where luckNum=33
查找的流程跟聚集索引一樣,這里就不詳細介紹了,我們最侄訓找到主鍵值 47,找到主鍵后我們需要再到聚集索引中查找具體對應的資料資訊,此時又回到了聚集索引的查找流程,
下面看下具體的查找流程圖:
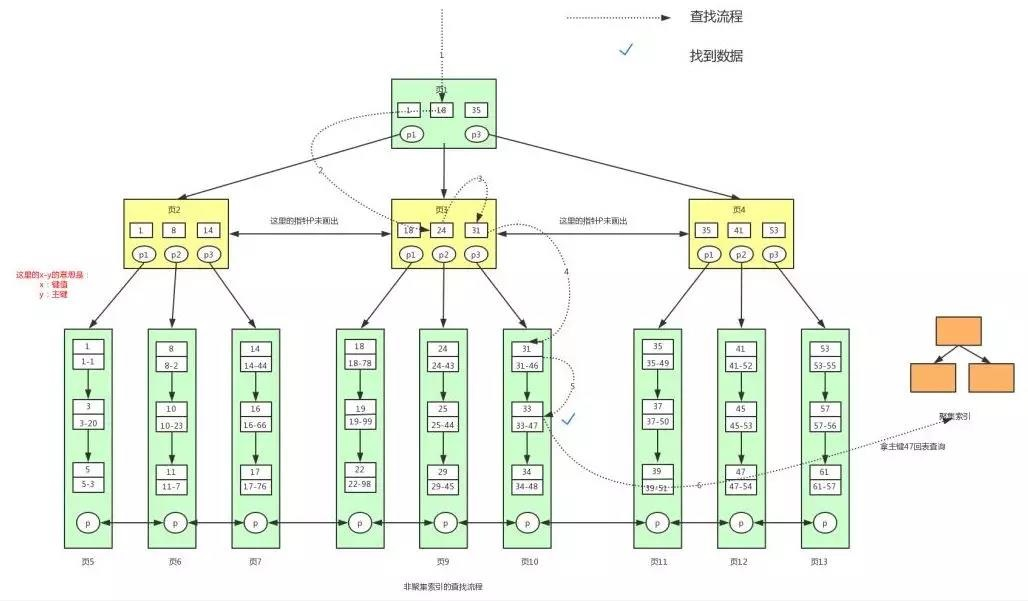
在 MyISAM 中,聚集索引和非聚集索引的葉子節點都會存盤資料的檔案地址,
總結
本篇文章從二叉查找樹,詳細說明了為什么 MySQL 用 B+ 樹作為資料的索引,以及在 InnoDB 中資料庫如何通過 B+ 樹索引來存盤資料以及查找資料,我們一定要記住這句話:資料即索引,索引即資料,
原文地址:http://www.liuzk.com/410.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/47822.html
標籤:MySQL
上一篇:mysql 回傳欄位型別轉換問題
下一篇:上傳檔案到服務器