這篇文章看起來很長,但實際上并不長,因為我不擅長解釋事情:)
我正在嘗試制作一個分類O和X字母的NN。每個字母都是6x6像素(36 個輸入),我2x2使用卷積層將字母最大池化為像素(4 個輸入)。在我的 NN 架構中,我只有 1 個輸出節點,如果輸出接近0則字母為"O",如果更接近1則字母為"X"。
- 第一個 NN 架構:
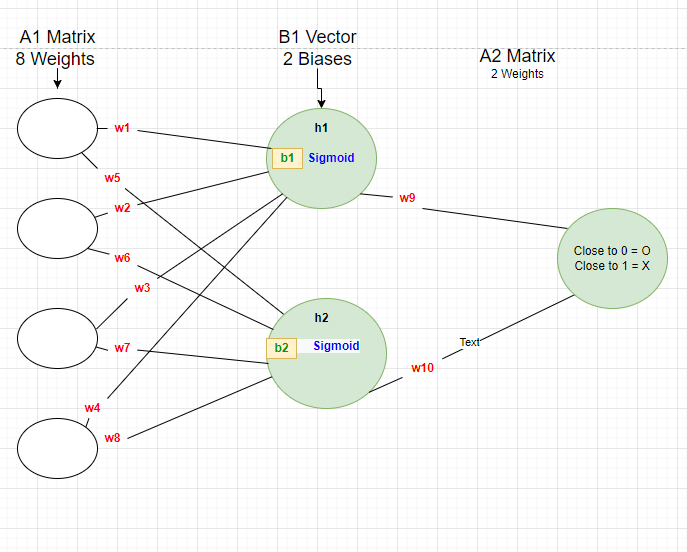
我的第一個 NN 架構的訓練資料:
x= [[0.46931818, 0.44129729, 0.54988949, 0.54295118], #O Letter Max Pooled from 6x6 to 2x2
[0.54976771, 0.54295118, 0.50129169, 0.54988949]] #X Letter Max Pooled from 6x6 to 2x2
y=[[0],[1]]
如上所示,O 字母的標簽為零,X 字母的標簽為 1。因此,如果輸出更接近 0,則將輸入分類為O Letter,如果更接近 1,則將輸入分類為X Letter。這對我來說作業得很好,但是當我決定將我的架構更改為 2 個輸出時,我開始遇到問題,所以我閱讀了有關 Softmax 的資訊,但我認為我實作它是錯誤的。這是我的新NN的照片:
- 第二個NN架構
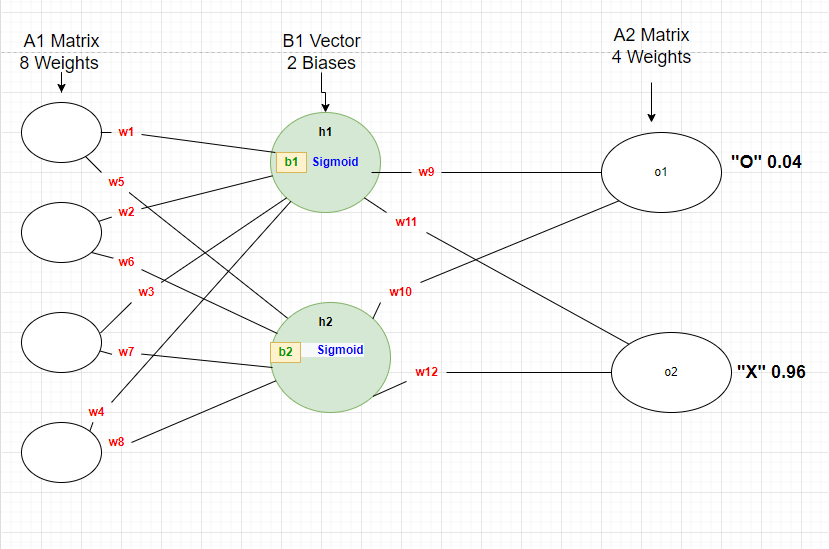
以下是我的問題:
1. 我是否應該更改我的y變數,y=[[0],[1]]因為我認為我的新架構沒有將它分類為接近 0 或 1,因為每個字母都有自己的輸出節點。
2.我的代碼怎么知道o1節點是O字母,
o2節點是X字母
3. 我是否在前饋時在我的代碼中實作了 yPred?在第一個架構中,我的 y_pred 是這樣的:y_pred = o1
因為我只有一個輸出節點。我應該將 o1 和 o2 作為勝利者發送到 softmax 函式并獲得最高值嗎?(我真的認為我正在接近這個錯誤)這是我寫的代碼:
sum_o1 = (self.w9 * h1 self.w10 * h2)
o1 = sigmoid(sum_o1)
sum_o2 = (self.w11 * h1 self.w12 * h2)
o2 = sigmoid(sum_o2)
#Check this later, might be implemented wrong ######################
y_pred = softmax([o1, o2])
y_pred = max(y_pred)
我認為我實施它的原因是錯誤的,因為我loss rate有時會變得更高,有時即使經過40000時代它也不會改變!這是我檢查損失的方法:
if epoch % 1000 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
- 在第一個 NN 架構中,我曾經這樣計算偏導數:
d_L_d_ypred = -2 * (y_true - y_pred),我應該如何用我的新架構計算它?因為現在我認為我的 y_true 不再是 0 和 1 了。因為我已經有 2 個節點(o1 和 o2),每個節點代表一個字母。
我知道我有一些誤解,因為我是初學者,但我希望有人能給我解釋一下。
即使我不希望有人回答這個問題(因為這是stackoverflow有時的作業方式,這讓我很惱火),但真的非常感謝幫助!提前致謝!
注意:添加代碼以使我關于形狀問題的問題更加清晰:
class OurNeuralNetwork:
def __init__(self):
# Weights for h1 (First Node in the Hidden Layer)
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
# Weights for h2 (Second Node in the Hidden Layer)
self.w5 = np.random.normal()
self.w6 = np.random.normal()
self.w7 = np.random.normal()
self.w8 = np.random.normal()
# Biases in the hidden layer
self.b1 = np.random.normal() #First Node
self.b2 = np.random.normal() #Second Node
self.w9 = np.random.normal()
self.w10 = np.random.normal()
self.w11 = np.random.normal()
self.w12 = np.random.normal()
def testForward(self, x):
h1 = sigmoid(self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1)
h2 = sigmoid(self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2)
o1 = sigmoid(self.w9 * h1 self.w10 * h2)
o2 = sigmoid(self.w11 * h1 self.w12 * h2)
output = softmax([o1, o2])
return output
def feedforward(self, x):
h1 = sigmoid(self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1)
h2 = sigmoid(self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2)
o1 = sigmoid(self.w9 * h1 self.w10 * h2)
o2 = sigmoid(self.w11 * h1 self.w12 * h2)
output = softmax([o1, o2])
return output
def train(self, data, all_y_trues):
learn_rate = 0.01
epochs = 20000
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
#Feedforward
sum_h1 = self.w1 * x[0] self.w2 * x[1] self.w3 * x[2] self.w4 * x[3] self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w5 * x[0] self.w6 * x[1] self.w7 * x[2] self.w8 * x[3] self.b2
h2 = sigmoid(sum_h2)
sum_o1 = (self.w9 * h1 self.w10 * h2)
o1 = sigmoid(sum_o1)
sum_o2 = (self.w11 * h1 self.w12 * h2)
o2 = sigmoid(sum_o2)
#Check this later, might be implemented wrong ######################
y_pred = softmax([o1, o2])
## Partial Derivates ->
d_L_d_ypred = -2 * (y_true - y_pred)
# Node o1
d_ypred_d_w9 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w10 = h2 * deriv_sigmoid(sum_o1)
#Node o2
d_ypred_d_w11 = h1 * deriv_sigmoid(sum_o2)
d_ypred_d_w12 = h2 * deriv_sigmoid(sum_o2)
d_ypred_d_h1_o1 = self.w9 * deriv_sigmoid(sum_o1)
d_ypred_d_h2_o1 = self.w10 * deriv_sigmoid(sum_o1)
d_ypred_d_h1_o2 = self.w11 * deriv_sigmoid(sum_o2)
d_ypred_d_h2_o2 = self.w12 * deriv_sigmoid(sum_o2)
# Node h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_w3 = x[2] * deriv_sigmoid(sum_h1)
d_h1_d_w4 = x[3] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Node h2
d_h2_d_w5 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w6 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_w7 = x[2] * deriv_sigmoid(sum_h2)
d_h2_d_w8 = x[3] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# Update weights and biases
# Node h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_w4
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1_o1 * d_h1_d_b1
# Node h2
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w6
self.w7 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w7
self.w8 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_w8
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2_o2 * d_h2_d_b2
# Node o1
self.w9 -= learn_rate * d_L_d_ypred * d_ypred_d_w9
self.w10 -= learn_rate * d_L_d_ypred * d_ypred_d_w10
#Node o2
self.w11 -= learn_rate * d_L_d_ypred * d_ypred_d_w11
self.w12 -= learn_rate * d_L_d_ypred * d_ypred_d_w12
#Check this later after fixing the softmax issue #################################
if epoch % 10000 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
uj5u.com熱心網友回復:
1. 我是否應該更改我的 y 變數,即 y=[[0], 1 ],因為我認為我的新架構沒有將它分類為接近 0 或 1,因為每個字母都有自己的輸出節點。
Ans你應該從y=[[0],[1]]one-hot 矢量 likes更改y=[[1,0],[0,1]]。這意味著如果輸入影像為 0,我們希望索引 0(您的第一個輸出節點)處的輸出為 1。如果輸入影像為 x,則索引 1(您的第二個輸出節點)處的輸出為 1。
2.我的代碼怎么知道o1節點是O字母,o2節點是X字母
Ans您的模型將從 onehot 標簽中學習y=[[1,0],[0,1]]。在模型訓練程序中,你的模型會意識到如果要最小化損失函式,當輸入影像為 0 時,它應該1從第一個輸出節點激發值,反之亦然。
3. 我是否在前饋時在我的代碼中實作了 yPred?在第一個架構中,我的 y_pred 是這樣的:y_pred = o1 因為我只有一個輸出節點。我應該將 o1 和 o2 作為勝利者發送到 softmax 函式并獲得最高值嗎?(我真的認為我正在接近這個錯誤)這是我寫的代碼:
Ans在訓練期間,我們只需要類概率0并x進行反向傳播以更新權重。所以,y_pred = max(y_pred)不需要。
4. 在第一個NN架構中,我曾經這樣計算偏導數:d_L_d_ypred = -2 * (y_true - y_pred),我應該如何用我的新架構計算它?因為現在我認為我的 y_true 不再是 0 和 1 了。因為我已經有 2 個節點(o1 和 o2),每個節點代表一個字母。
Ans也許這個執行緒可以幫助你
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/482346.html