MapReduce詳細作業流程之Map階段
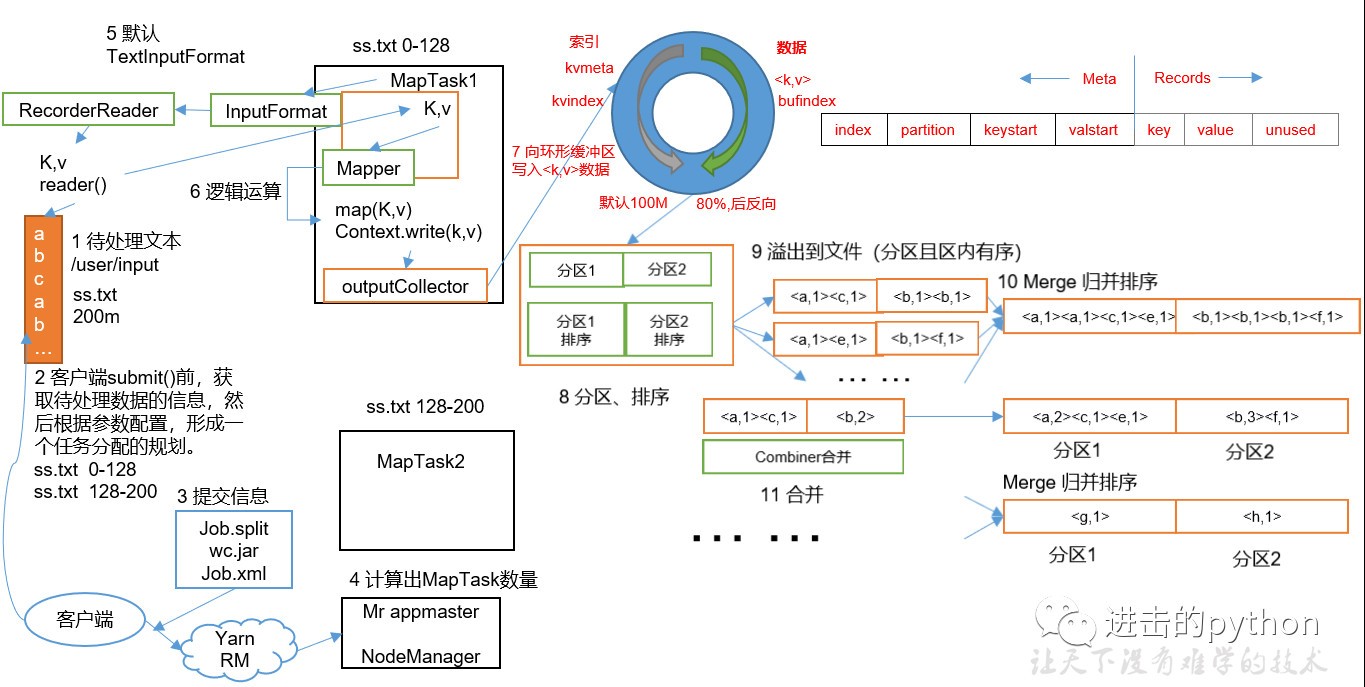
如上圖所示
- 首先有一個200M的待處理檔案
- 切片:在客戶端提交之前,根據引數配置,進行任務規劃,將檔案按128M每塊進行切片
- 提交:提交可以提交到本地作業環境或者Yarn作業環境,本地只需要提交切片資訊和xml組態檔,Yarn環境還需要提交jar包;本地環境一般只作為測驗用
- 提交時會將每個任務封裝為一個job交給Yarn來處理(詳細見后邊的Yarn作業流程介紹),計算出MapTask數量(等于切片數量),每個MapTask并行執行
- MapTask中執行Mapper的map方法,此方法需要k和v作為輸入引數,所以會首先獲取kv值;
- 首先呼叫InputFormat方法,默認為TextInputFormat方法,在此方法呼叫createRecoderReader方法,將每個塊檔案封裝為k,v鍵值對,傳遞給map方法
- map方法首先進行一系列的邏輯操作,執行完成后最后進行寫操作
- map方法如果直接寫給reduce的話,相當于直接操作磁盤,太多的IO操作,使得效率太低,所以在map和reduce中間還有一個shuffle操作
- map處理完成相關的邏輯操作之后,首先通過outputCollector向環形緩沖區寫入資料,環形緩沖區主要兩部分,一部分寫入檔案的元資料資訊,另一部分寫入檔案的真實內容
- 環形緩沖區的默認大小是100M,當緩沖的容量達到默認大小的80%時,進行反向溢寫
- 在溢寫之前會將緩沖區的資料按照指定的磁區規則進行磁區和排序,之所以反向溢寫是因為這樣就可以邊接收資料邊往磁盤溢寫資料
- 在磁區和排序之后,溢寫到磁盤,可能發生多次溢寫,溢寫到多個檔案
- 對所有溢寫到磁盤的檔案進行歸并排序
- 在9到10步之間還可以有一個Combine合并操作,意義是對每個MapTask的輸出進行區域匯總,以減少網路傳輸量
- Map階段的行程數比Reduce階段要多,所以放在Map階段處理效率更高
- Map階段合并之后,傳遞給Reduce的資料就會少很多
- 但是Combiner能夠應用的前提是不能影響最終的業務邏輯,而且Combiner的輸出kv要和Reduce的輸入kv型別對應起來
整個MapTask分為Read階段,Map階段,Collect階段,溢寫(spill)階段和combine階段
- Read階段:MapTask通過用戶撰寫的RecordReader,從輸入InputSplit中決議出一個個key/value
- Map階段:該節點主要是將決議出的key/value交給用戶撰寫map()函式處理,并產生一系列新的key/value
- Collect收集階段:在用戶撰寫map()函式中,當資料處理完成后,一般會呼叫OutputCollector.collect()輸出結果,在該函式內部,它會將生成的key/value磁區(呼叫Partitioner),并寫入一個環形記憶體緩沖區中
- Spill階段:即“溢寫”,當環形緩沖區滿后,MapReduce會將資料寫到本地磁盤上,生成一個臨時檔案,需要注意的是,將資料寫入本地磁盤之前,先要對資料進行一次本地排序,并在必要時對資料進行合并、壓縮等操作
MapReduce詳細作業流程之Reduce階段
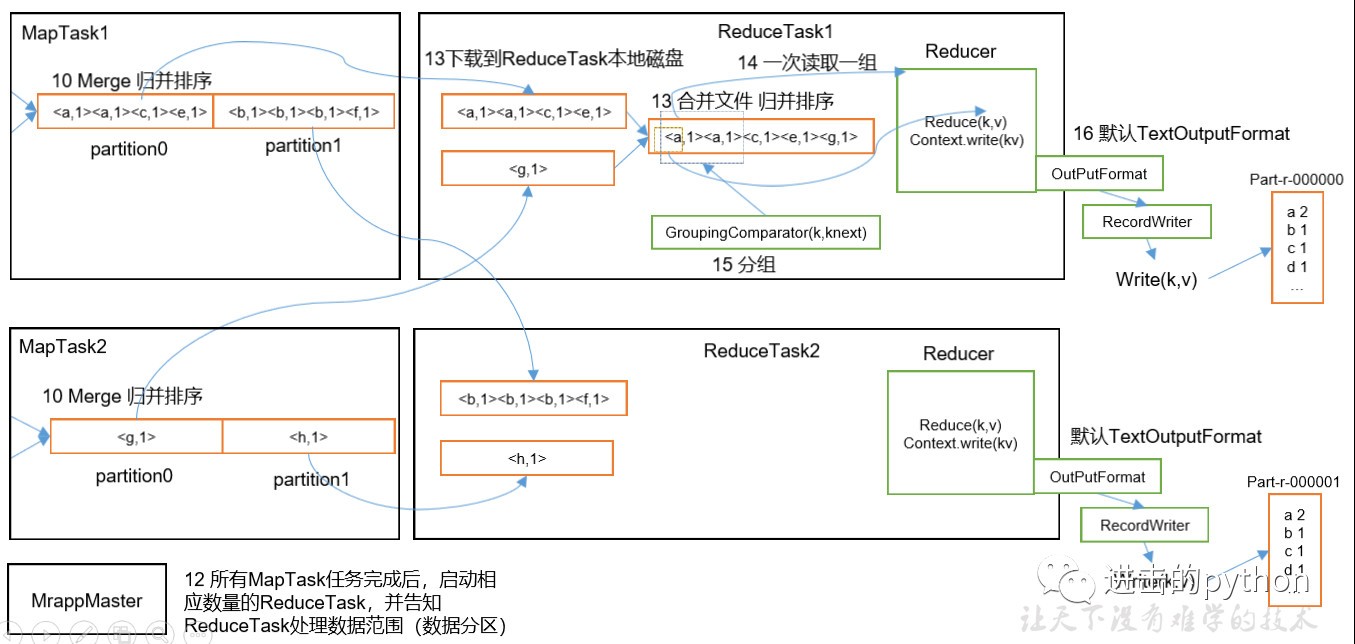
如上圖所示
- 所有的MapTask任務完成后,啟動相應數量的ReduceTask(和磁區數量相同),并告知ReduceTask處理資料的范圍
- ReduceTask會將MapTask處理完的資料拷貝一份到磁盤中,并合并檔案和歸并排序
- 最后將資料傳給reduce進行處理,一次讀取一組資料
- 最后通過OutputFormat輸出
整個ReduceTask分為Copy階段,Merge階段,Sort階段(Merge和Sort可以合并為一個),Reduce階段,
- Copy階段:ReduceTask從各個MapTask上遠程拷貝一片資料,并針對某一片資料,如果其大小超過一定閾值,則寫到磁盤上,否則直接放到記憶體中
- Merge階段:在遠程拷貝資料的同時,ReduceTask啟動了兩個后臺執行緒對記憶體和磁盤上的檔案進行合并,以防止記憶體使用過多或磁盤上檔案過多
- Sort階段:按照MapReduce語意,用戶撰寫reduce()函式輸入資料是按key進行聚集的一組資料,為了將key相同的資料聚在一起,Hadoop采用了基于排序的策略,由于各個MapTask已經實作對自己的處理結果進行了區域排序,因此,ReduceTask只需對所有資料進行一次歸并排序即可
- Reduce階段:reduce()函式將計算結果寫到HDFS上
Shuffle機制
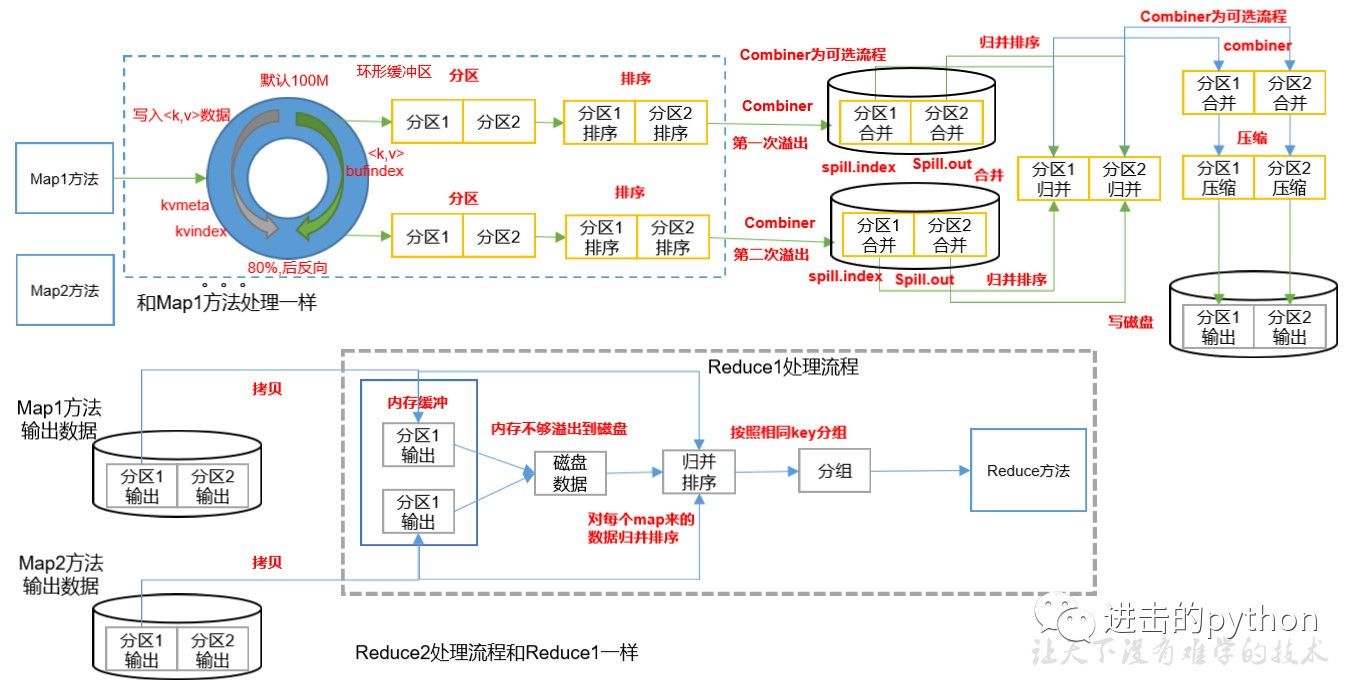
Map方法之后,Reduce方法之前的資料處理程序稱之為Shuffle,shuffle流程詳解如下:
- MapTask收集map()方法輸出的kv對,放到環形緩沖區中
- 從環形緩沖區不斷溢位到本地磁盤檔案,可能會溢位多個檔案
- 多個溢位檔案會被合并成大的溢位檔案
- 在溢位程序及合并的程序中,都要呼叫Partitioner進行磁區和針對key進行排序
- ReduceTask根據自己的磁區號,去各個MapTask機器上取相應的結果磁區資料
- ReduceTask將取到的來自同一個磁區不同MapTask的結果檔案進行歸并排序
- 合并成大檔案后,shuffle程序也就結束了,進入reduce方法
Yarn作業機制
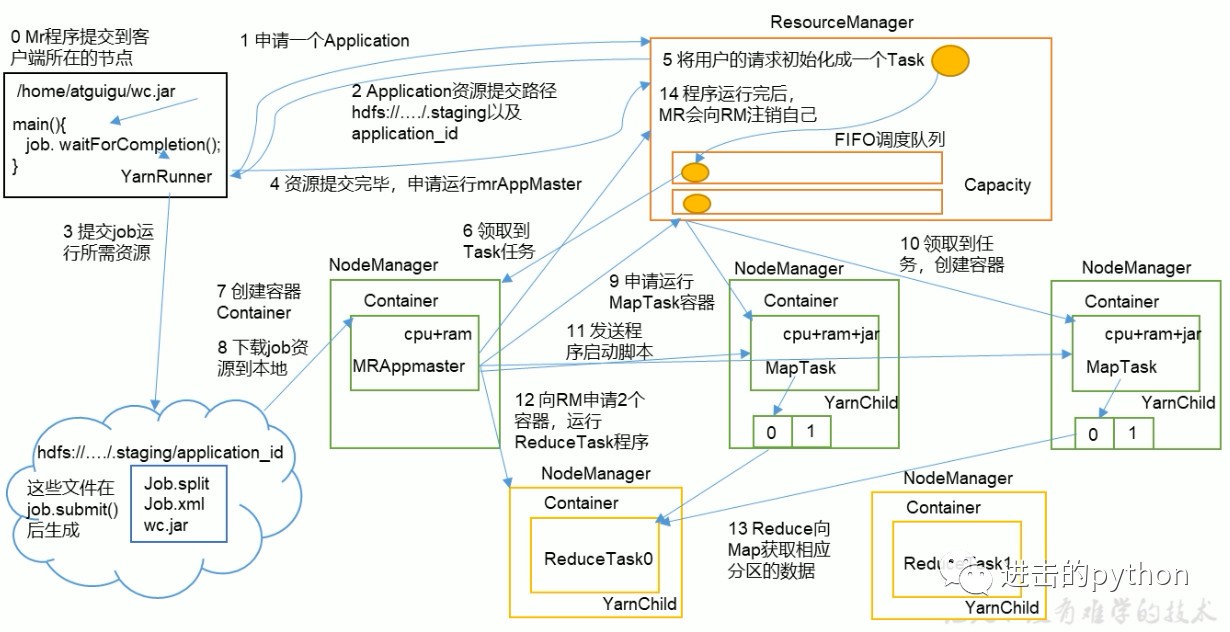
job提交全程序
- MR程式提交到客戶端所在的節點,YarnRunner向ResourceManager申請一個Application
- RM將該Application的資源路徑和作業id回傳給YarnRunner
- YarnRunner將運行job所需資源提交到HDFS上
- 程式資源提交完畢后,申請運行mrAppMaster
- RM將用戶的請求初始化成一個Task
- 其中一個NodeManager領取到Task任務
- 該NodeManager創建容器Container,并產生MRAppmaster
- Container從HDFS上拷貝資源到本地
- MRAppmaster向RM 申請運行MapTask資源
- RM將運行MapTask任務分配給另外兩個NodeManager,另兩個NodeManager分別領取任務并創建容器
- MR向兩個接收到任務的NodeManager發送程式啟動腳本,這兩個NodeManager分別啟動MapTask,MapTask對資料磁區排序
- MrAppMaster等待所有MapTask運行完畢后,向RM申請容器,運行ReduceTask
- ReduceTask向MapTask獲取相應磁區的資料
- 程式運行完畢后,MR會向RM申請注銷自己
進度和狀態更新:
YARN中的任務將其進度和狀態(包括counter)回傳給應用管理器, 客戶端每秒(通過mapreduce.client.progressmonitor.pollinterval設定)向應用管理器請求進度更新, 展示給用戶
作業完成:
除了向應用管理器請求作業進度外, 客戶端每5秒都會通過呼叫waitForCompletion()來檢查作業是否完成,時間間隔可以通過mapreduce.client.completion.pollinterval來設定,作業完成之后, 應用管理器和Container會清理作業狀態,作業的資訊會被作業歷史服務器存盤以備之后用戶核查
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/48442.html
標籤:大數據
上一篇:來一位熟悉資料庫的大佬幫忙解答一下下面這段函式的意思,感激不盡
下一篇:A機器上運行MySQL5.7,想把它的binlog檔案,實時(注意:是實時)同步到B機器上,需要怎么做?想用rsync