隨著移動互聯網的發展,萬物互聯成為了可能,這種互聯所產生的資料也在爆發式地增長,而這些資料恰好可以作為分析關系的有效原料,如果說以往的智能分析專注在每一個個體上,在移動互聯網時代則除了個體,這種個體之間的關系也必然成為我們需要深入分析的很重要一部分,在一項任務中,只要有關系分析的需求,知識圖譜就“有可能”派的上用場,
說到關系的重要性,我們先來看一個有意思的理論,六度分隔理論(英語:Six Degrees of Separation),相信大家也都聽說過,這個理論認為世界上任何互不相識的兩人,只需要很少的中間人就能夠建立起聯系,
哈佛大學心理學教授斯坦利·米爾格拉姆于1967年根據這個概念做過一次連鎖信實驗,嘗試證明平均只需要6步就可以聯系任何兩個互不相識的美國人,這種現象,并不是說任何人與人之間的聯系都必須要經過6步才會達到,而是表達了這樣一個重要的概念:在任何兩位素不相識的人之間,通過一定的聯系方式,總能夠產生必然聯系或關系,知識圖譜為我們打開了一個全新的認識事物的思維方式,
知識圖譜是什么
知識圖譜用一句話說就是用圖的形式去存盤和表示知識,知識圖譜本質上是語意網路,是一種基于圖的資料結構,由節點(Point)和邊(Edge)組成,在知識圖譜里,每個節點表示現實世界中存在的“物體”,每條邊為物體與物體之間的“關系”,
知識圖譜是關系的最有效的表示方式,它用圖的形式描繪了我們的現實世界,下面我用知識圖譜表示了日本著名影片導演宮崎駿和他的作品以及他的作品和演員之間的關系,從圖中可以看出,宮崎駿導演了包括《龍貓》在內的多部電影,而電影《龍貓》的演員有高木均等,這樣千千萬萬個導演,演員和電影聯系在一起,就形成了一個電影的知識圖譜,
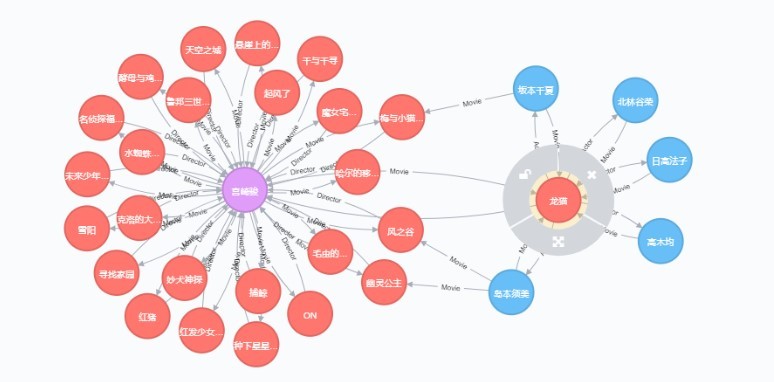
該圖是用Neo4j展示的
知識圖譜的由來
知識圖譜是由Google公司在2012年提出來的一個新的概念,知識圖譜,即一種特殊的語意網路,它利用物體、關系、屬性這些基本單位,以符號的形式描述了物理世界中不同的概念和概念之間的相互關系,
知識圖譜旨在通過建立資料之間的關聯鏈接,將碎片化的資料有機的組織起來, 讓資料更加容易被人和機器理解和處理,并為搜索、挖掘、分析等提供便利,為人工智能的實作提供知識庫基礎,
Google為了提升搜索引擎回傳的答案質量,推出了知識圖譜概念,有知識圖譜的輔助,搜索引擎能夠根據用戶查詢背后的語意資訊,回傳更準確、更結構化的資訊,Google知識圖譜的宣傳語“things not strings”道出了知識圖譜的精髓:不要無意義的字串,需要文本背后的物件或事物,
以羅納爾多為例,當用戶以“羅納爾多”作為關鍵詞進行搜索,沒有知識圖譜的情況下,我們只能得到包含這個關鍵詞的網頁,然后不得不點擊進入相關網頁查找需要的資訊,有了知識圖譜,搜索引擎在回傳相關網頁的同時,還會回傳一個包含查詢物件基本資訊的”知識卡片“,如果我們需要的資訊就在卡片中,就無需進一步操作了,也就是說,知識圖譜能夠提升查詢效率,讓我們獲得更精準、更結構化的資訊,
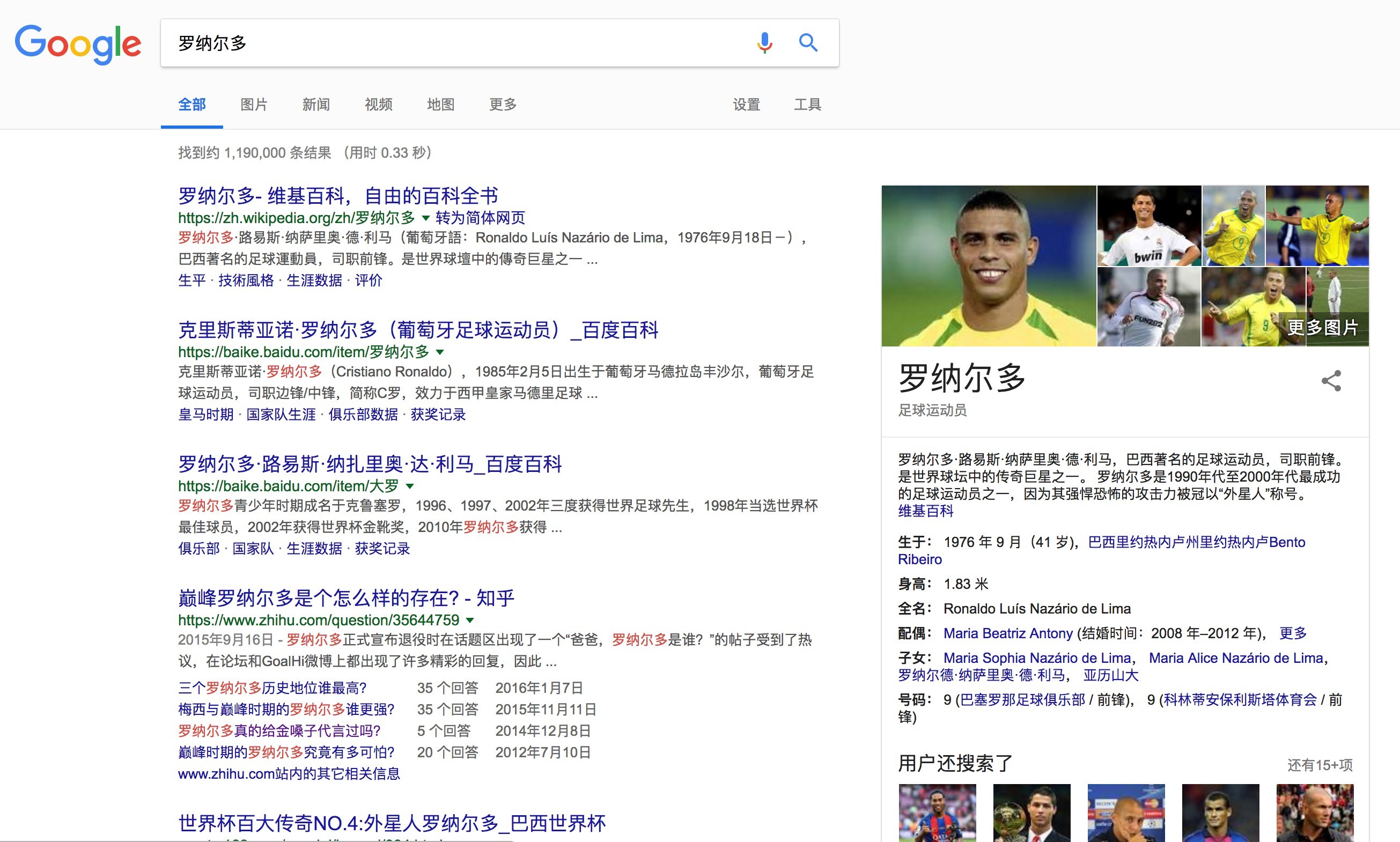
當然,這只是知識圖譜在搜索引擎上的一部分應用場景,舉這個例子也是為了表明,知識圖譜這樣一種概念或者技術,它的誕生是符合計算機科學、互聯網發展潮流的,
知識圖譜的存盤
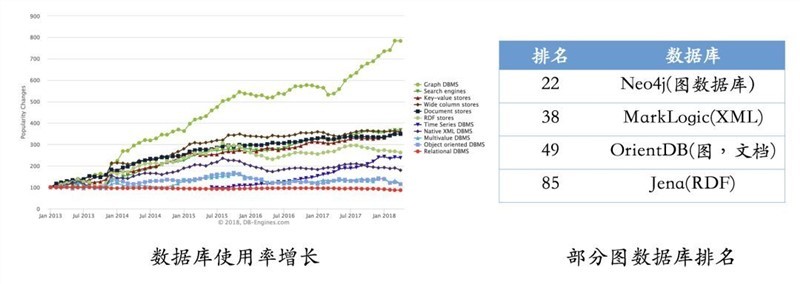
知識圖譜主要有兩種存盤方式:一種是基于RDF的存盤;另一種是基于圖資料庫的存盤,它們之間的區別如下圖所示,RDF一個重要的設計原則是資料的易發布以及共享,圖資料庫則把重點放在了高效的圖查詢和搜索上,其次,RDF以三元組的方式來存盤資料而且不包含屬性資訊,但圖資料庫一般以屬性圖為基本的表示形式,所以物體和關系可以包含屬性,這就意味著更容易表達現實的業務場景,

根據最新的統計(2018年上半年),圖資料庫仍然是增長最快的存盤系統,相反,關系型資料庫的增長基本保持在一個穩定的水平,同時,我們也列出了常用的圖資料庫系統以及他們最新使用情況的排名, 其中Neo4j系統目前仍是使用率最高的圖資料庫,它擁有活躍的社區,而且系統本身的查詢效率高,但唯一的不足就是不支持準分布式,相反,OrientDB和JanusGraph(原Titan)支持分布式,但這些系統相對較新,社區不如Neo4j活躍,這也就意味著使用程序當中不可避免地會遇到一些刺手的問題,如果選擇使用RDF的存盤系統,Jena或許一個比較不錯的選擇,
知識圖譜的應用
從一開始的Google搜索,到現在的聊天機器人、大資料風控、證券投資、智能醫療、自適應教育、推薦系統,無一不跟知識圖譜相關,它在技術領域的熱度也在逐年上升,下面我們簡單介紹下幾個典型的應用,
反欺詐
知識圖譜在反欺詐作用非常大,反欺詐最終目的是識別壞人,把壞人跟其他的未知人群的關系找出來,從而認定其他未知人群是否是壞人,這個跟信用模型是很不一樣的,如果原來只能看一層的關系,現在可以看兩層三層四層,效果就完全不一樣了,很多團伙、中介實際上是要看很大規模的一張網,看很多層關系,關系之間還有強關系、弱關系,
下圖是我們將知識圖譜應用于反欺詐中的示例圖:
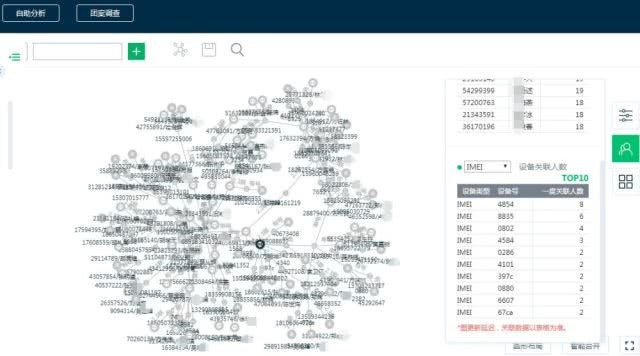
目前將用戶資訊,設備資訊及社交關系構建了一個異構網路,并將該異構網路圖應用在用戶關聯分析及反欺詐檢測場景,根據資料圖我們可以對用戶做以下調查分析,來確定特定的用戶是不是欺詐用戶或者是不是與欺詐用戶有關聯:
- 通過特定規則篩選可疑用戶
- 查看與可疑用戶有特定關聯的用戶
- 查看與可疑用戶有特定關聯的所有用戶組成的子網的網路特征及用戶特征
- 分析特定用戶可以通過什么樣的關聯關系關聯在一起
- 可分析多層關聯關系的資料
通過該方式,我們大大減少了調查程序中的作業量,整體提升效率,
智能搜索
智能搜索的功能類似于知識圖譜在Google, Baidu上的應用,也就是說,對于每一個搜索的關鍵詞,我們可以通過知識圖譜來回傳更豐富,更全面的資訊,
推薦引擎
通過知識圖譜,查詢某節點的消費情況可為其推薦關聯度高的可能消費的商品,
精準營銷
一個聰明的企業可以比它的競爭對手以更為有效的方式去挖掘其潛在的客戶,在互聯網時代,營銷手段多種多樣,但不管有多少種方式,都離不開一個核心——分析用戶和理解用戶,知識圖譜可以結合多種資料源去分析物體之間的關系,從而對用戶的行為有更好的理解,比如一個公司的市場經理用知識圖譜來分析用戶之間的關系,去發現一個組織的共同喜好,從而可以有針對性的對某一類人群制定營銷策略,
總結
本文主要介紹了下知識圖譜相關概念和在大資料分析中的一些應用,知識圖譜為互聯網上大資料表達、組織、管理以及利用提供了一種更為有效的方式,使得網路的智能化水平更高,更加接近于人類的認知思維,塑造出了反欺詐、智能營銷、商品推薦等應用場景,給我們提供了更多思考和分析問題的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/48456.html
標籤:大數據