作為一名應用系統開發人員,為什么要關注資料內部的存盤和檢索呢?首先,你不太可能從頭開始實作一套自己的存盤引擎,往往需要從眾多現有的存盤引擎中選擇一個適合自己應用的存盤引擎,因此,為了針對你特定的作業負載而對資料庫調優時,最好對存盤引擎的底層機制有一個大概的了解,
今天我們就先來了解下關系型資料庫MySQL和NoSQL存盤引擎HBase的底層存盤機制,對于一個資料庫的性能來說,其資料的組織方式至關重要,眾所周知,資料庫的資料大多存盤在磁盤上,而磁盤的訪問相對記憶體的訪問來說是一項很耗時的操作,對比如下,因此,提高資料庫資料的查找速度的關鍵點之一便是盡量減少磁盤的訪問次數,
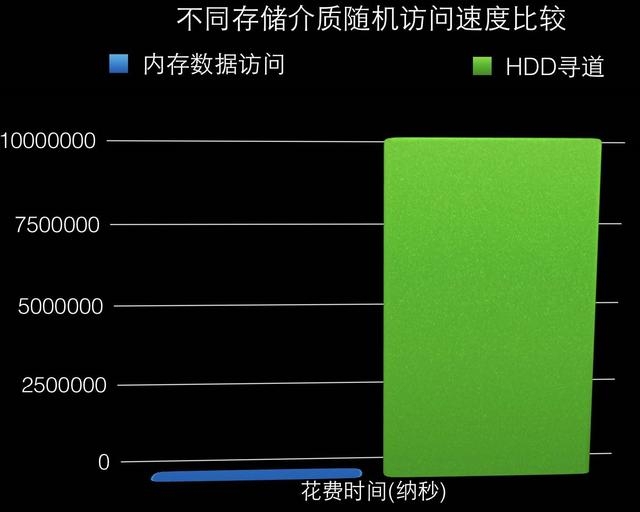
磁盤與記憶體的訪問速度對比
為了加速資料庫資料的訪問,大多傳統的關系型資料庫都會使用特殊的資料結構來幫助查找資料,這種資料結構叫作索引( Index),對于傳統的關系型資料庫,考慮到經常需要范圍查找某一批資料,因此其索引一般不使用 Hash演算法,而使用樹( Tree)結構,然而,樹結構的種類很多,卻不一定都適合用于做資料庫索引,
二叉查找樹與平衡二叉樹
最常見的樹結構是二叉查找樹( Binary Search Tree),它就是一棵二叉有序樹:保證左子樹上所有節點的值都小于根節點的值,而右子樹上所有節點的值都大于根節點的值,其優點在于實作簡單,并且樹在平衡的狀態下查找效率能達到 O(log n);缺點是在極端非平衡情況下查找效率會退化到 O(n),因此很難保證索引的效率,
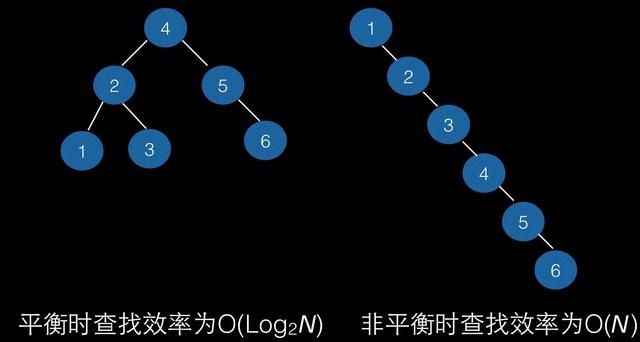
二叉查找樹的查找效率
針對上述二叉查找樹的缺點,人們很自然就想到是否能用平衡二叉樹( Balanced Binary Tree)來解決這個問題,但是平衡二叉樹依然有個比較大的問題:它的樹高為 log n——對于索引樹來說,樹的高度越高,意味著查找所要花費的訪問次數越多,查詢效率越低,
況且,主存從磁盤讀資料一般以頁為單位,因此每次訪問磁盤都會讀取多個扇區的資料(比如 4KB大小的資料),遠大于單個二叉樹節點的值(位元組級別),這也是造成二叉樹相對索引樹效率低下的原因,正因如此,人們就想到了通過增加每個樹節點的度來提高訪問效率,而 B+樹(B+-tree)便受到了更多的關注,
B+樹
在傳統的關系型資料庫里, B+樹( B+-tree)及其衍生樹是被用得比較多的索引樹,
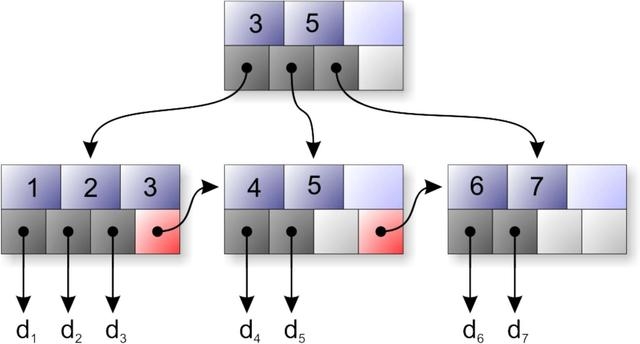
B+樹
B+樹的主要特點如下,
每個樹節點只存放鍵值,不存放數值,而由葉子節點存放數值,這樣會使樹節點的度比較大,而樹的高度就比較低,從而有利于提高查詢效率,
葉子節點存放數值,并按照值大小順序排序,且帶指向相鄰節點的指標,以便高效地進行區間資料查詢;并且所有葉子節點與根節點的距離相同,因此任何查詢的效率都很相似,
與二叉樹不同, B+樹的資料更新操作不從根節點開始,而從葉子節點開始,并且在更新程序中樹能以比較小的代價實作自平衡,
正是由于 B+樹的上述優點,它成了傳統關系型資料庫的寵兒,當然,它也并非無懈可擊,它的主要缺點在于隨著資料插入的不斷發生,葉子節點會慢慢分裂——這可能會導致邏輯上原本連續的資料實際上存放在不同的物理磁盤塊位置上,在做范圍查詢的時候會導致較高的磁盤 IO,以致嚴重影響到性能,
日志結構合并樹
眾所周知,資料庫的資料大多存盤在磁盤上,而無論是傳統的機械硬碟( HardDiskDrive, HDD)還是固態硬碟( Solid State Drive, SSD),對磁盤資料的順序讀寫速度都遠高于隨機讀寫,
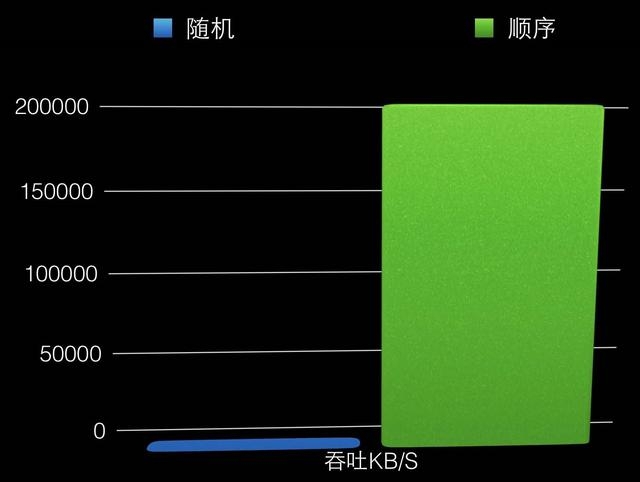
磁盤順序與隨機訪問吞吐對比
然而,基于 B+樹的索引結構是違背上述磁盤基本特點的——它會需要較多的磁盤隨機讀寫,于是, 1992年,名為日志結構( Log-Structured)的新型索引結構方法便應運而生,日志結構方法的主要思想是將磁盤看作一個大的日志,每次都將新的資料及其索引結構添加到日志的最末端,以實作對磁盤的順序操作,從而提高索引性能,不過,日志結構方法也有明顯的缺點,隨機讀取資料時效率很低,
1996年,一篇名為 Thelog-structured merge-tree(LSM-tree)的論文創造性地提出了日志結構合并樹( Log-Structured Merge-Tree)的概念,該方法既吸收了日志結構方法的優點,又通過將資料檔案預排序克服了日志結構方法隨機讀性能較差的問題,盡管當時 LSM-tree新穎且優勢鮮明,但它真正聲名鵲起卻是在 10年之后的 2006年,那年谷歌的一篇使用了 LSM-tree技術的論文 Bigtable: A Distributed Storage System for Structured Data橫空出世,在分布式資料處理領域掀起了一陣旋風,隨后兩個聲名赫赫的大資料開源組件( 2007年的 HBase與 2008年的 Cassandra,目前兩者同為 Apache頂級專案)直接在其思想基礎上破繭而出,徹底改變了大資料基礎組件的格局,同時也極大地推廣了 LSM-tree技術,
LSM-tree最大的特點是同時使用了兩部分類樹的資料結構來存盤資料,并同時提供查詢,其中一部分資料結構( C0樹)存在于記憶體快取(通常叫作 memtable)中,負責接受新的資料插入更新以及讀請求,并直接在記憶體中對資料進行排序;另一部分資料結構( C1樹)存在于硬碟上 (這部分通常叫作 sstable),它們是由存在于記憶體快取中的 C0樹沖寫到磁盤而成的,主要負責提供讀操作,特點是有序且不可被更改,
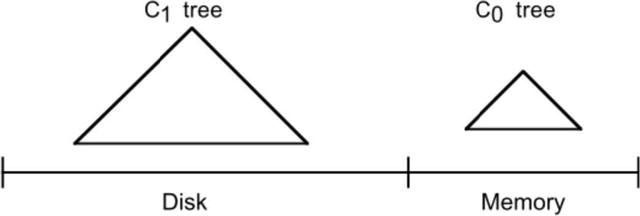
LSM-tree的 C0與 C1部分
LSM-tree的另一大特點是除了使用兩部分類樹的資料結構外,還會使用日志檔案(通常叫作 commit log)來為資料恢復做保障,這三類資料結構的協作順序一般是:所有的新插入與更新操作都首先被記錄到 commit log中——該操作叫作 WAL(Write Ahead Log),然后再寫到 memtable,最后當達到一定條件時資料會從 memtable沖寫到 sstable,并拋棄相關的 log資料; memtable與 sstable可同時供查詢;當 memtable出問題時,可從 commit log與 sstable中將 memtable的資料恢復,
我們可以參考 HBase的架構來體會其架構中基于 LSM-tree的部分特點,按照 WAL的原則,資料首先會寫到 HBase的 HLog(相當于 commit log)里,然后再寫到 MemStore(相當于 memtable)里,最后會沖寫到磁盤 StoreFile(相當于 sstable)中,這樣 HBase的 HRegionServer就通過 LSM-tree實作了資料檔案的生成,HBase LSM-tree架構示意圖如下圖,
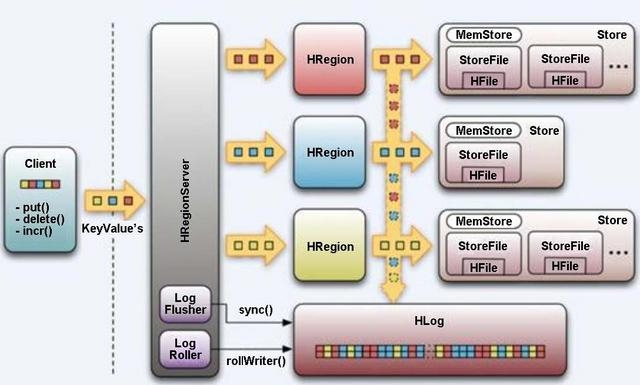
HBase LSM-tree架構示意圖
LSM-tree的這種結構非常有利于資料的快速寫入(理論上可以接近磁盤順序寫速度),但是不利于讀——因為理論上讀的時候可能需要同時從 memtable和所有硬碟上的 sstable中查詢資料,這樣顯然會對性能造成較大的影響,為了解決這個問題, LSM-tree采取了以下主要的相關措施,
- 定期將硬碟上小的 sstable合并(通常叫作 Merge或 Compaction操作)成大的 sstable,以減少 sstable的數量,而且,平時的資料更新洗掉操作并不會更新原有的資料檔案,只會將更新洗掉操作加到當前的資料檔案末端,只有在 sstable合并的時候才會真正將重復的操作或更新去重、合并,
- 對每個 sstable使用布隆過濾器( Bloom Filter),以加速對資料在該 sstable的存在性進行判定,從而減少資料的總查詢時間,
總結
LSM樹和B+樹的差異主要在于讀性能和寫性能進行權衡,在犧牲的同時尋找其余補救方案,
B+樹存盤引擎,不僅支持單條記錄的增、刪、讀、改操作,還支持順序掃描(B+樹的葉子節點之間的指標),對應的存盤系統就是關系資料庫,但隨著寫入操作增多,為了維護B+樹結構,節點分裂,讀磁盤的隨機讀寫概率會變大,性能會逐漸減弱,LSM樹(Log-Structured MergeTree)存盤引擎和B+樹存盤引擎一樣,同樣支持增、刪、讀、改、順序掃描操作,而且通過批量存盤技術規避磁盤隨機寫入問題,當然凡事有利有弊,LSM樹和B+樹相比,LSM樹犧牲了部分讀性能,用來大幅提高寫性能,
訂閱關注微信公眾號《大資料技術進階》,及時獲取更多大資料架構和應用相關技術文章!

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/48482.html
標籤:大數據