import requests
from bs4 import BeautifulSoup
result = requests.get(f"https://www.indeed.com/jobs?q=web development&start=0")
source = result.content
soup = BeautifulSoup(source, "lxml")
job_posted = soup.find("div", {"id": "searchCountPages"}).text.strip()
job_posted = job_posted[10:-5].replace(",", "")
job_posted = int(job_posted)
print(job_posted)
從網站上抓取字串后,我嘗試將字串轉換為整數,當我運行該程式時,有時它可以作業,而其他時候卻不行!我收到此錯誤:ValueError: int() 的無效文字,基數為 10: 's | ' 第 1 頁
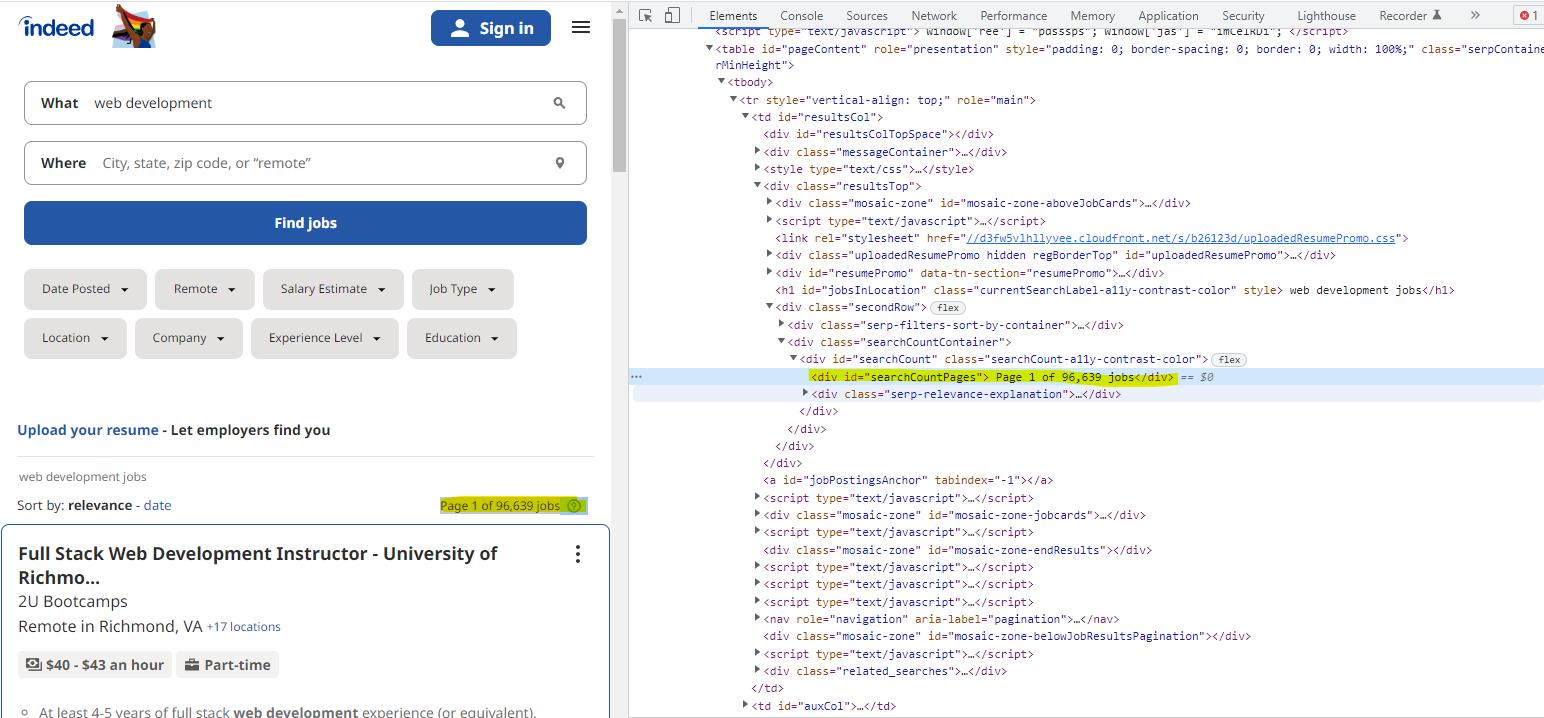
這是我想報廢的黃色
uj5u.com熱心網友回復:
如前所述,正則運算式在這里是合適的:
import re
p = re.compile(r"Page (\d*) of (\d*) jobs")
job_posted = soup.find("div", {"id": "searchCountPages"}).text.strip().replace(",", "")
page_num, page_count = map(int, p.match(job_posted).groups())
請注意,如果找不到確切的模式,這將出錯。
輸出:
In [3]: page_num, page_count = map(int, p.match(job_posted).groups())
In [4]: page_num
Out[4]: 1
In [5]: page_count
Out[5]: 96575
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/489017.html
下一篇:試圖抓取網頁的內容