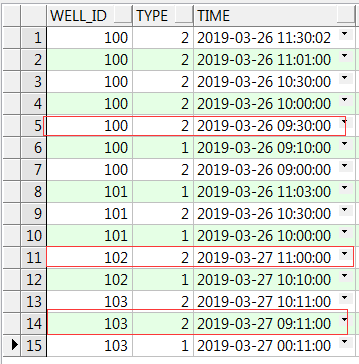
請問大家,按ID分組,按時間倒序,最新一條type值為2時,查找連續為2的資料,當type值不連續為非2時,取2的第一條資料的時間;若最新一條不為2,則不查出該ID,例如下圖資料,如何撰寫sql陳述句可以使最后的查詢結果為紅框中資料?謝謝~
uj5u.com熱心網友回復:
思路:1、首先去掉每個well_id最大時間且type = '1'的資料select * from table where well_id in
(select b.well_id from table b,
(select well_id,max(time) time from table group by well_id) a
where b.type = '2' and b.time = a.time and b.well_id = a.well_id
)
2、取每個well_id最大時間且type = '1'的資料以及這條資料的rownum
3、上面的rownum-1的資料就是我們所需要的資料
uj5u.com熱心網友回復:
with tab1 as (
select 1 id, 1 type, 11 ord from dual union all
select 1 id, 2 type, 10 ord from dual union all
select 1 id, 2 type, 9 ord from dual union all
select 1 id, 2 type, 8 ord from dual union all
select 1 id, 2 type, 7 ord from dual union all
select 1 id, 1 type, 6 ord from dual union all
select 2 id, 2 type, 10 ord from dual union all
select 2 id, 1 type, 9 ord from dual union all
select 3 id, 2 type, 10 ord from dual union all
select 3 id, 2 type, 9 ord from dual union all
select 3 id, 1 type, 8 ord from dual
)
, tab2 as (
select t1.id,
t1.type,
t1.ord,
row_number() over(partition by t1.id order by t1.ord desc) rn
from tab1 t1
order by t1.id, ord desc
)
select distinct
t1.id,
first_value(t1.ord) over(partition by t1.id order by level desc) time
from tab2 t1
start with t1.rn = 1
connect by prior t1.id = t1.id
and prior t1.rn + 1 = t1.rn
and not (t1.type != 2 and prior t1.type = 2)
;
uj5u.com熱心網友回復:
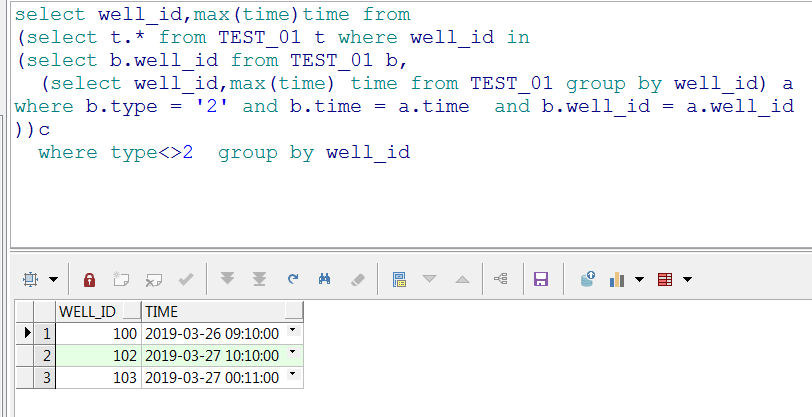
感謝,取到了非2資料的最大時間,但rownum怎么取,試了一下好像不能做-1操作?
uj5u.com熱心網友回復:
我這里沒有oracle資料庫,寫個sql你參考下,不知道對不對。1、取rownum:
select t.well_id,t.rn,max(t.time) as time
(
select well_id,type,time,rownum as rn from table where well_id in
(select b.well_id from table b,
(select well_id,max(time) time from table group by well_id) a
where b.type = '2' and b.time = a.time and b.well_id = a.well_id
)
) t where type = '1' group by t.well_id,t.rn;
2、再從上面的t表取well_id=t.well_id and and rn=t.rn - 1的資料
uj5u.com熱心網友回復:
with tab1 as (
select 1 well_id, 1 type, 11 time from dual union all
select 1 id, 2 type, 10 ord from dual union all
select 1 id, 2 type, 9 ord from dual union all
select 1 id, 2 type, 8 ord from dual union all
select 1 id, 2 type, 7 ord from dual union all
select 1 id, 1 type, 6 ord from dual union all
select 2 id, 2 type, 10 ord from dual union all
select 2 id, 1 type, 9 ord from dual union all
select 3 id, 2 type, 10 ord from dual union all
select 3 id, 2 type, 9 ord from dual union all
select 3 id, 2 type, 8 ord from dual
)
, tab2 as (
select t1.*,
sum(decode(t1.type, 1, 0, 1)) over(partition by t1.well_id order by t1.time desc) sm,
row_number() over(partition by t1.well_id order by t1.time desc) rn
from tab1 t1
)
, tab3 as (
select t1.*,
decode(1, first_value(t1.type) over(partition by t1.well_id order by decode(t1.type, 1, 1, 2, 2), t1.rn)
,first_value(t1.rn) over(partition by t1.well_id order by decode(t1.type, 1, 1, 2, 2), t1.rn) - 1
,max(t1.rn) over(partition by t1.well_id )) fv
from tab2 t1
where t1.sm != 0
order by t1.well_id, t1.time desc
)
select * from tab3 t1 where t1.rn = fv
;
;
排在所有2前面的1可能不止1個,直接max應該不行吧。如果所有type都是2,這種情況下也不能直接-1 。
關鍵是多次訪問資料表很可能會嚴重降低效率,應該運用分析函式,盡可能只訪問一次資料表。
uj5u.com熱心網友回復:
你說得對,確實實際專案資料很多,兩分鐘更新一條,需求是找到當前時間往前的連續為2的最早時間,可能實際專案除了1還有其他值,你的這個sql看起來挺復雜,我明天上班研究一下,謝謝~轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/49714.html
標籤:開發