我試圖找出如何使用Mojo::DOMUTF8(和其他格式......不僅僅是 UTF8)。它似乎弄亂了編碼:
my $dom = Mojo::DOM->new($html);
$dom->find('script')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
$dom->find('style')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
$dom->find('script')->reverse->each(sub {
#print "$_->{id}\n";
$_->remove;
});
my $html = "$dom"; # pass back to $html, now we have cleaned it up...
這是我在保存檔案而不通過 Mojo 運行它時得到的結果:
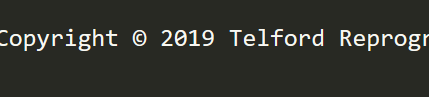
...然后通過 Mojo:
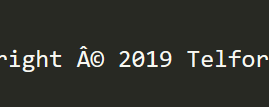
FWIW,我正在使用Path::Tiny, 抓取 HTML 檔案:
my $utf8 = path($_[0])->slurp_raw;
據我了解,應該已經將字串解碼為位元組以供 Mojo 使用?
更新:根據 Brians 的建議,我研究了如何找出正確解碼的編碼型別。我嘗試了 Encode::Guess 和其他一些,但他們似乎在很多方面都弄錯了。這個似乎可以解決問題:
my $enc_tmp = `encguess $_[0]`;
my ($fname,$type) = split /\s /, $enc_tmp;
my $decoded = decode( $type||"UTF-8", path($_[0])->slurp_raw );
uj5u.com熱心網友回復:
您正在吞食原始八位位元組,但沒有解碼它們(將原始八位位元組存盤在 中$utf8)。然后你把它當作你已經解碼它,所以結果是 mojibake。
- 如果您閱讀原始八位位元組,請在使用之前對其進行解碼。您最終會得到正確的 Perl 內部字串。
slurp_utf8將為您解碼。- 同樣,您必須在再次輸出時進行編碼。在這個
open例子中,pragma 就是這樣做的。 - Mojolicious 已經必須
Mojo::File->slurp獲取原始八位位元組,因此您可以減少依賴串列。
use v5.10;
use utf8;
use open qw(:std :utf8);
use Path::Tiny;
use Mojo::File;
use Mojo::Util qw(decode);
my $filename = 'test.txt';
open my $fh, '>:encoding(UTF-8)', $filename;
say { $fh } "Copyright ? 2022";
close $fh;
my $octets = path($filename)->slurp_utf8;
say "===== Path::Tiny::slurp_raw, no decode";
say path($filename)->slurp_raw;
say "===== Path::Tiny::slurp_raw, decode";
say decode( 'UTF-8', path($filename)->slurp_raw );
say "===== Path::Tiny::slurp_utf8";
say path($filename)->slurp_utf8;
say "===== Mojo::File::slurp, decode";
say decode( 'UTF-8', Mojo::File->new($filename)->slurp );
輸出:
===== Path::Tiny::slurp_raw, no decode
Copyright ?? 2022
===== Path::Tiny::slurp_raw, decode
Copyright ? 2022
===== Path::Tiny::slurp_utf8
Copyright ? 2022
===== Mojo::File::slurp, decode
Copyright ? 2022
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/498066.html