測驗環境:
GTID的主從復制,主庫(9900)——》備庫(9909),存在測驗庫表:
9900_db1庫:t1、t2、t3、t4、t5表
9900_db2庫:t6、t7、t8、t9、t10表
1、replicate-do-db引數:
--replicate-do-db=name,只同步指定的資料庫,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_DB來創建,比如現在只同步9900_db1庫,需要在從庫執行:
mysql> stop slave sql_thread;
Query OK, 0 rows affected (0.01 sec)
mysql> change replication filter replicate_do_db=(9900_db1); //(9900_db1,...)可指定多個
Query OK, 0 rows affected (0.01 sec)
mysql> start slave sql_thread;
Query OK, 0 rows affected (0.04 sec)
也可以寫入到引數檔案永久生效(若要指定多個,需要多次指定該引數),
此時在主庫9900_db2庫中的表插入資料的話,將不會同步到備庫,在9900_db1庫中的表插入資料的話,是可以同步到備庫的,
但是需要注意的如下:
①該引數不能再group replication架構中使用,因為可能會使組無法達到一致的狀態,
②在binlog為statement格式下(row不會有下面問題):
sql執行緒會將replicate-do-db限制的資料庫為use使用的資料庫,
如果在主庫執行如下操作,備庫將不會復制(不單單是insert,這里只是用insert舉例,只要涉及到復制庫和未復制庫的跨庫操作就不會復制):
mysql> use 9900_db2;
Database changed
mysql> insert into 9900_db1.t1(name) values('gg');
Query OK, 1 row affected (0.63 sec)
產生這種行為的原因是:僅通過陳述句很難判斷是否該復制(比如跨庫update和delete多個表),如果沒有必要,只檢查默認庫比檢查所有庫要快,
③在binlog為row格式下,以下操作不會同步到備庫:
mysql> use 9900_db1;
Database changed
mysql> insert into 9900_db2.t6(name) values('gg');
Query OK, 1 row affected (0.50 sec)
這個也很好理解,因為沒有同步9900_db2即便跨同步的庫也沒用,
總之,在statement格式下的binlog,只要涉及到同步庫和未同步庫的跨庫操作就不會同步;在row格式下的binlog只要涉及到未同步庫的操作,都不會同步,
④以下操作在statement格式下和row格式下有區別:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1,9900_db2.t6 set 9900_db1.t1.name='aaa',9900_db2.t6.name='bbb' where 9900_db1.t1.name='aa' and 9900_db2.t6.name='bb';
Query OK, 2 rows affected (3.23 sec)
Rows matched: 2 Changed: 2 Warnings: 0
使用的是replicate-do-db指定的庫,在binlog為statement格式下會同步到備庫,如果不是使用的replicate-do-db庫的話將不會同步,
使用的是replicate-do-db指定的庫,在binlog為row格式下不論是不是使用的replicate-do-db庫,都會只同步9900_db1的操作,
總之,修改操作涉及到同步的庫和未同步的庫的時候,在binlog為statement格式下如果使用的是(這里使用指的是use dbname)同步的庫操作都會同步到備庫,如果使用未同步的庫的話操作不會同步;在row格式的binlog下無論使用的哪個庫都只會同步,replicate-do-db指定的庫的操作,
2、replicate-ignore-db引數:
--replicate-ignore-db=name,不同步指定的資料庫,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_DB來創建,和replicate-do-db一樣,不過多解釋了,
這里CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB=(9900_db1);
需要注意的如下:
①該引數不能再group replication架構中使用,因為可能會使組無法達到一致的狀態,同replicate-do-db,
②在binlog為statement格式下,只要use的是replicate-ignore-db的資料庫那么將不會復制到備庫,use的其他資料庫是可以復制到備庫的,比如如下操作是可以被復制的,因為use的不是replicate-ignore-db庫:
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa'; //因為這里是顯示指定的9900_db1庫基于statement格式下不會進行過濾,
Query OK, 1 row affected (1.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
在binlog為row格式下,無論use的是不是ignore的資料庫,都不會更新ignore庫中的表,
其實和replicate-do-db大同小異只不過這里是不同步的庫,
對于上面的④步中的:
如果為statement格式的話,use的是ignore庫,那么不會同步ignore庫中的表,其他的表可以同步;如果use的不是ignore庫,那么都會同步,
如果為row格式的話,無論use的是不是ignore的庫,都不會同步ignore庫中的表的操作,
3、replicate-do-table引數:
--replicate-do-table=db_name.tbl_name,只同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_TABLE=(9900_db1.t1,9900_db2.t6);進行過濾,也可寫入到引數檔案,如果要過濾多個表的話,需要指定多次該引數,
測驗指定的是只同步9900_db1.t1,9900_db2.t6這兩個表,replicate-do-table指定該引數后不管use的是哪個資料庫都會進行同步(和binlog格式無關),測驗如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2; //使用其他資料庫也是如此
Database changed
mysql> update 9900_db1.t1 set name='aa' where name='a';
Query OK, 1 row affected (1.10 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④進行多個更新,也是無論use哪個資料庫都會進行更新(不分binlog格式),當更新操作中既包含db table表又包含不能同步的表時,statement格式時都會同步到備庫,但是如果備庫不存在其他表的話主從將會報錯(與use資料庫無關);row格式的時候備庫只同步db table的表(與use資料庫無關),
4、replicate-ignore-table引數:
--replicate-ignore-table=db_name.tbl_name,不同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE=(9900_db1.t1,9900_db2.t6);進行過濾,也可寫入到引數檔案,如果要過濾多個表的話,需要指定多次該引數,
測驗指定的是不同步9900_db1.t1,9900_db2.t6這兩個表,replicate-ignore-table指定該引數后不管use的是哪個資料庫都不會進行同步,測驗如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.17 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.09 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④進行多個更新,也是無論use哪個資料庫備庫都不會進行更新(不分binlog格式),對于操作中包含既然包含ignore table表又包含可以同步的表的時候,那么在statement格式下replicate-ignore-table指定的表和可以同步的表都不會同步(與use資料庫無關);在row格式下replicate-ignore-table指定的表不同步外其他的表示可以同步的(與use資料庫無關),
5、replicate-wild-do-table引數:
--replicate-wild-do-table=db_name.tbl_name,只同步指定的表,可以包含%和_通配符,它們與LIKE模式匹配運算子的含義相同,可以使用CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=('9900_db1.t1','9900_db2.t6')進行過濾(注意庫名表名的引號),也可以寫入引數檔案如果不使用通配符等的話,想要同步多個表,需要在引數檔案寫多次,
測驗指定的是只同步9900_db1.t1,9900_db2.t6這兩個表,replicate-wild-do-table指定該引數后不管use的是哪個資料庫都會進行同步(和binlog格式無關),測驗如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2; //使用其他資料庫也是如此
Database changed
mysql> update 9900_db1.t1 set name='aa' where name='a';
Query OK, 1 row affected (1.10 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④進行多個更新,也是無論use哪個資料庫都會進行更新(不分binlog格式),當更新操作中既包含db table表又包含不能同步的表時,statement格式時都會同步到備庫,但是如果備庫不存在其他表的話主從將會報錯(與use資料庫無關);row格式的時候備庫只同步db table的表(與use資料庫無關),
replicate-wild-do-table和replicate-do-table效果是一樣的,不同的是replicate-wild-do-table可以使用通配符等,
該選項適用于表、視圖和觸發器,不適用于存盤程序和函式等事件,
例如:replication -wild-do-table=foo%.Bar%.只復制使用資料庫名稱以foo開頭、表名稱以Bar開頭的表的更新,如果表名模式是%,那么它將匹配任何表名,
該選項不適用隱式更新表,比如授權陳述句grant會隱式更新mysql.user表,備庫不受該引數限制,
6、replicate-wild-ignore-table引數:
--replicate-wild-ignore-table=db_name.tbl_name,不同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE=('9900_db1.t1','9900_db2.t6');進行過濾,也可寫入到引數檔案,如果要過濾多個表的話,需要指定多次該引數,
測驗指定的是不同步9900_db1.t1,9900_db2.t6這兩個表,replicate-wild-ignore-table指定該引數后不管use的是哪個資料庫都不會進行同步( 和binlog格式無關),測驗如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.17 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.09 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④進行多個更新,也是無論use哪個資料庫備庫都不會進行更新(和binlog格式無關),對于操作中包含既然包含ignore table表又包含可以同步的表的時候,那么在statement格式下replicate-wild-ignore-table指定的表和可以同步的表都不會同步(與use資料庫無關);在row格式下replicate-ignore-table指定的表不同步外其他的表示可以同步的(與use資料庫無關),
因為row格式的binlog中將陳述句拆分了兩個:
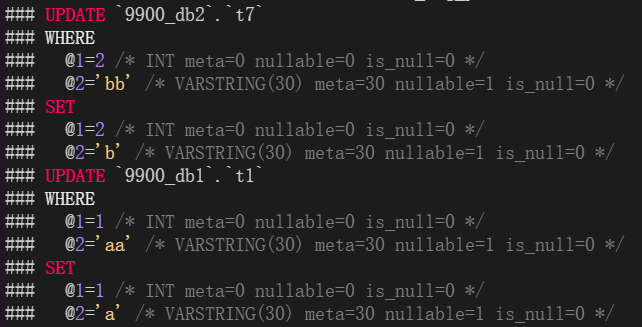
replicate-wild-ignore-table和replicate-ignore-table效果是一樣的,不同的是replicate-wild-ignore-table可以使用通配符等,
例如:replication-wild-ignore-table=foo%.Bar%.不會復制使用資料庫名稱以foo開頭、表名稱以Bar開頭的表的更新,如果表名模式是%,那么它將匹配任何表名,
該選項不適用隱式更新表,比如授權陳述句grant會隱式更新mysql.user表,備庫不受該引數限制,如果需要過濾掉GRANT陳述句或其他管理陳述句,可能的解決方法是使用--replication-ignore-db引數,
例如:
USE nonreplicated;
GRANT SELECT, INSERT ON replicated.t1 TO 'someuser'@'somehost';
上面的陳述句序列會導致GRANT陳述句被忽略,
7、replicate-rewrite-db:
--replicate-rewrite-db=from_name->to_name將主庫的資料庫名from_name轉換為從庫的to_name,要指定多個需要多次使用該引數,或者寫入引數檔案,例如:
mysqld --replicate-rewrite-db="olddb->newdb"
也可以通過CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB來創建,
這里使用主庫的9900_db1和從庫的test:CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB=((9900_db1,test));
對于binlog為statement和row格式該引數的效果是不同的:
①statement格式下,需改陳述句中指定庫名(比如update dbname.tblname)這樣的話無論use的哪個庫都不會同步到test庫(如果備庫也有和主庫同名的庫9900_db1,那么會同步到該庫),如果陳述句中不指定庫名,use 引數指定的主庫的庫名(也就是9900_db1)的話直接寫表名更新是可以同步到備庫test庫的,
②row格式下,無論use的是哪個庫,也無論更新的時候有沒有指定庫名,都會同步到備庫的test庫,而如果備庫中9900_db1庫也不會同步,
DDL的話不論binlog格式如何,都是根據use的庫來進行的,也就是說,指定庫名(比如update dbname.tblname)這樣的話無論use的哪個庫都DDL不會同步到test庫(如果備庫也有和主庫同名的庫9900_db1,那么會同步到該庫),有可能sql thread會報錯;如果陳述句中不指定庫名,use 引數指定的主庫的庫名(也就是9900_db1)的話直接寫表名更新是可以同步到備庫test庫的,
為確保重寫產生預期的結果,尤其是與其他復制篩選選項結合使用時,請在使用選項--replicate-rewrite-db時遵循以下建議:
①在源和具有不同名稱的副本上手動創建from_name 和 to_name 資料庫,
②如果您使用基于陳述句的或混合的二進制日志記錄格式,請不要使用跨資料庫查詢,也不要在查詢中指定資料庫名稱,對于 DDL 和 DML陳述句,都依賴use陳述句指定的當前資料庫,并且在查詢中僅使用table名
③如果僅對 DDL 陳述句使用基于row格式的binlog,依靠use陳述句指定當前資料庫,并且在查詢中使用table名,對于DML陳述句,可以根據需要使用完全限定的table名(db.table),
如果遵循這些 建議,則可以安全的將--replicate-rewrite-db選項與table級復制過濾選項(例如--replicate-do-table)結合使用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499009.html
標籤:MySQL