Redis 的 Java 客戶端
- Jedis
- 優點:以 Redis 命令作為方法名稱,學習成本低廉,簡單且實用
- 缺點:Jedis 的實體是執行緒不安全的,在多執行緒的環境下需要基于執行緒池來使用
- lettuce(spring 官方默認)
- 基于 Netty 實作的,支持同步、異步和回應式編程方式,并且是執行緒安全的,支持 Redis 的哨兵模式、集群模式、管道模式
- Redisson(適用于分布式的環境)
- 基于 Redis 實作的分布式、可伸縮的 Java 資料結構的集合,包含 Map、Queue、Lock、Semaphore、AtomicLong等強大的功能
Jedis
Jedis 基本使用步驟
- 引入依賴
- 創建Jedis物件,建立連接
- 使用Jedis,方法名與Redis命令一致
- 釋放資源
測驗 Jedis 相關方法
如果 @BeforeEach報錯,記得在 pom 檔案里面引入 Junit API 包的依賴
<!-- junit-jupiter-api -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.8.2</version>
<scope>test</scope>
</dependency>
(這里以 String 和 Hash 兩種型別為例)
package com.lcha.test;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp(){
//1.建立連接
jedis = new Jedis("xxxxxxxxxx",6379);
//2.設定密碼
jedis.auth("xxxxxxxxx");
//3.選擇庫
jedis.select(0);
}
@Test
void testStr(){
//4.存入資料
String result = jedis.set("name", "胡歌");
System.out.println("result = " + result);
//5.獲取資料
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash(){
jedis.hset("user:1","name","Jack");
jedis.hset("user:1","age","21");
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
@AfterEach
void tearDown(){
//6.釋放連接
if(jedis != null){
jedis.close();
}
}
}
Jedis連接池
Jedis本身是執行緒不安全的,并且頻繁的創建和銷毀連接會有性能損耗,因此我們推薦大家使用Jedis連接池代替Jedis的直連方式,
首先創建一個 Jedis 連接池工具類
package com.lcha.jedis.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisConnectionFactory {
private static final JedisPool jedisPool;
static {
//配置連接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8); //最大連接數:8
poolConfig.setMaxIdle(8); //最大空閑連接
poolConfig.setMinIdle(0);
poolConfig.setMaxWaitMillis(1000);
//創建連接池物件
jedisPool = new JedisPool(poolConfig,"xxxx",6379,
1000,"xxxx");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
更改之前 Jedis 的連接方式,采用連接池連接的方式
package com.lcha.test;
import com.lcha.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import java.util.Map;
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp(){
//1.建立連接
//jedis = new Jedis("xxxx",6379);
jedis = JedisConnectionFactory.getJedis();
//2.設定密碼
jedis.auth("xxxx");
//3.選擇庫
jedis.select(0);
}
@Test
void testStr(){
//4.存入資料
String result = jedis.set("name", "胡歌");
System.out.println("result = " + result);
//5.獲取資料
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash(){
jedis.hset("user:1","name","Jack");
jedis.hset("user:1","age","21");
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
@AfterEach
void tearDown(){
if(jedis != null){
jedis.close();
}
}
}
注意:當使用連接池連接時,代碼最后的 if(jedis != null){jedis.close();}不會真正的銷毀連接,而是將本連接歸還到連接池中
原始碼如下:
public void close() {
if (this.dataSource != null) {
Pool<Jedis> pool = this.dataSource;
this.dataSource = null;
if (this.isBroken()) {
pool.returnBrokenResource(this);
} else {
pool.returnResource(this); //注意這里!!!!
}
} else {
this.connection.close();
}
}
SpringDataRedis
SpringData是Spring中資料操作的模塊,包含對各種資料庫的集成,其中對Redis的集成模塊就叫做SpringDataRedis
官網地址:https://spring.io/projects/spring-data-redis
- 提供了對不同Redis客戶端的整合(Lettuce和Jedis)
- 提供了RedisTemplate統一API來操作Redis
- 支持Redis的發布訂閱模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的回應式編程
- 支持基于JDK、JSON、字串、Spring物件的資料序列化及反序列化
- 支持基于Redis的JDKCollection實作
RedisTemplate 工具類
| API | 回傳值型別 | 說明 |
|---|---|---|
| RedisTemplate.opsForValue() | ValueOperations | 操作 String 型別資料 |
| RedisTemplate.opsForHash() | HashOperations | 操作 Hash 型別資料 |
| RedisTemplate.opsForList() | ListOperations | 操作 List 型別資料 |
| RedisTemplate.opsForSet() | SetOperations | 操作 Set 型別資料 |
| RedisTemplate.opsForZSet() | ZSetOperations | 操作 SortedSort 型別資料 |
| RedisTemplate | 通用命令 |
使用步驟
-
引入 spring-boot-starter-data-redis 依賴
<!-- redis依賴 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <!-- common-pool --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> </dependency> -
在 application.yml 檔案中配置 Redis 資訊
spring: redis: host: xxxx port: 6379 password: xxxx lettuce: pool: max-active: 8 max-idle: 8 min-idle: 0 max-wait: 100ms -
注入 RedisTemplate 并使用
package com.lcha;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class RedisDemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString() {
//寫入一條String資料
redisTemplate.opsForValue().set("name", "胡歌");
//獲取string資料
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}
序列化問題
RedisTemplate可以接收任意Object作為值寫入Redis,只不過寫入前會把Object序列化為位元組形式,默認是采用JDK序列化,得到的結果是這樣的:
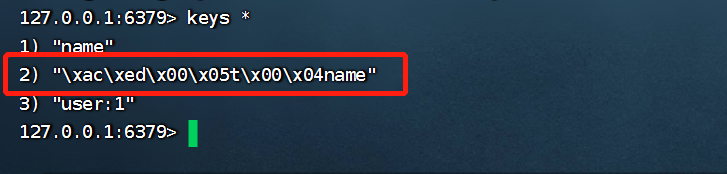
缺點:
- 可讀性差
- 記憶體占用較大
解決方法:改變序列化器
自定義 RedisTemplate 序列化方式
package com.lcha.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
//創建 RedisTemplate 物件
RedisTemplate<String, Object> template = new RedisTemplate<>();
//設定連接工廠
template.setConnectionFactory(connectionFactory);
//創建 JSON 序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//設定 Key 的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//設定 Value 的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
//回傳
return template;
}
}
重新運行剛才的代碼,結果如下圖所示:

存盤物件資料時也是一樣的
-
創建一個物件類
package com.lcha.redis.pojo; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @NoArgsConstructor @AllArgsConstructor public class User { private String name; private Integer age; } -
撰寫測驗方法
-
@Test void testSaveUser(){ redisTemplate.opsForValue().set("user:100", new User("胡歌",21)); User o = (User) redisTemplate.opsForValue().get("user:100"); System.out.println("o = " + o); } -
列印結果
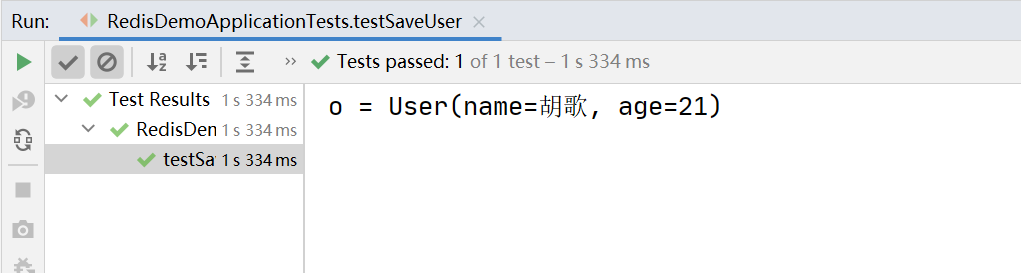
JSON方式依然存在的缺陷
盡管 JSON 的序列化方式可以滿足我們的需求,但是依然存在一些問題,

為了在反序列化時知道物件的型別,JSON序列化器會將類的class型別寫入json結果中,存入Redis,會帶來額外的記憶體開銷,
如何解決
為了節省記憶體空間,我們并不會使用JSON序列化器來處理value,而是統一使用String序列化器,要求只能存盤String型別的key和value,當需要存盤Java物件時,手動完成物件的序列化和反序列化,
-
直接使用 StringRedisTemplate 即可
package com.lcha; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import com.lcha.redis.pojo.User; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.StringRedisTemplate; @SpringBootTest class RedisStringTests { @Autowired private StringRedisTemplate stringRedisTemplate; @Test void testString() { //寫入一條String資料 stringRedisTemplate.opsForValue().set("name", "胡歌"); //獲取string資料 Object name = stringRedisTemplate.opsForValue().get("name"); System.out.println("name = " + name); } private static final ObjectMapper mapper = new ObjectMapper(); @Test void testSaveUser() throws JsonProcessingException { //創建物件 User user = new User("虎哥",21); //手動序列化 String json = mapper.writeValueAsString(user); //寫入資料 stringRedisTemplate.opsForValue().set("user:200", json); //獲取資料 String jsonUser = stringRedisTemplate.opsForValue().get("user:200"); User user1 = mapper.readValue(jsonUser, User.class); System.out.println("user1 = " + user1); } } -
結果如下
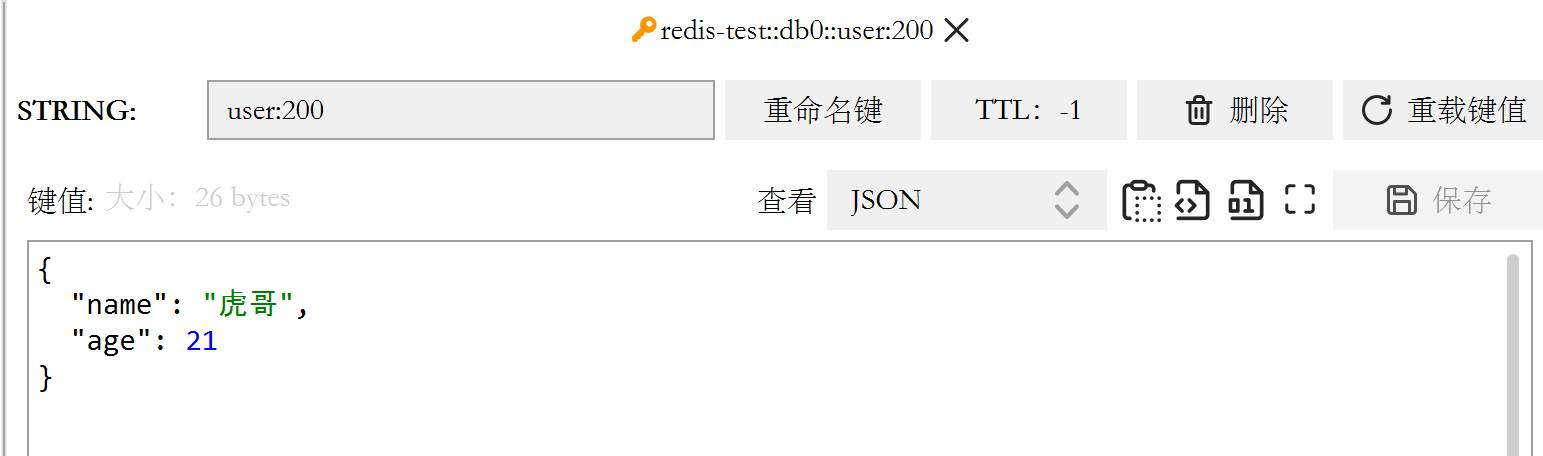
對 Hash 型別的操作
-
撰寫方法
@Test void testHash(){ stringRedisTemplate.opsForHash().put("user:300", "name", "張三"); stringRedisTemplate.opsForHash().put("user:300", "age", "18"); Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:300"); System.out.println("entries = " + entries); } -
結果如下
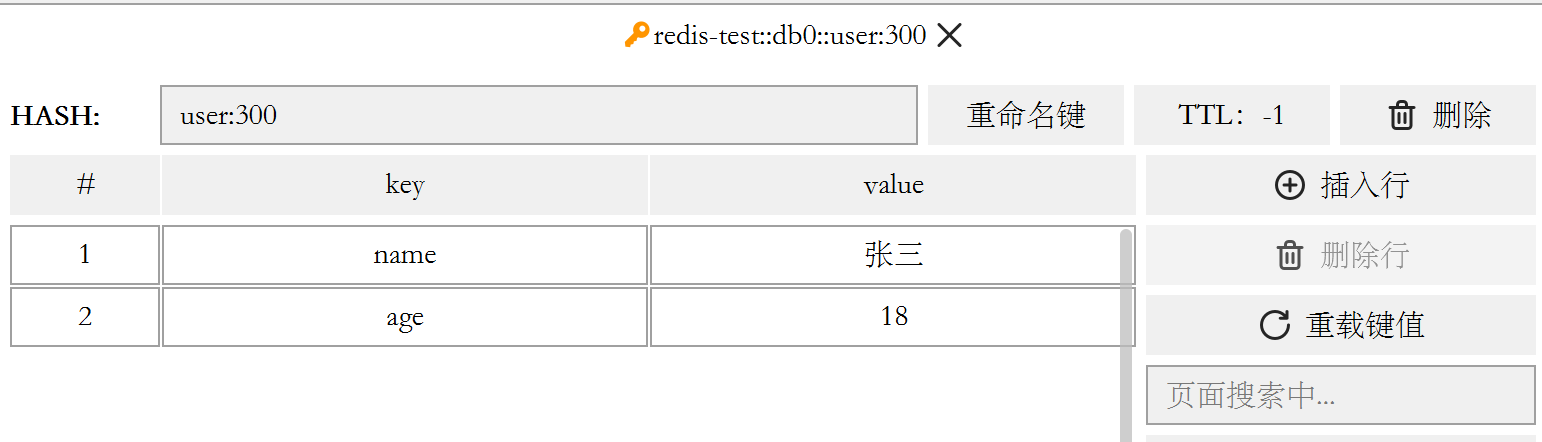
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499124.html
標籤:NoSQL
上一篇:Redis概述及基本資料結構
下一篇:Redis常見使用場景