騰訊云資料庫TDSQL與中國人民大學最新聯合研究成果被SIGMOD 2022接收并將通過長文形式發表,SIGMOD是國際資料管理與資料庫領域頂尖的學識訓議之一,騰訊云資料庫TDSQL論文已連續多年入選VLDB、SIGMOD、ICDE等國際頂級會議,
本次入選論文題目為:CompressDB: Enabling Efficient Compressed Data Direct Processing for Various Databases,論文針對壓縮資料的直接操作與處理,提出一項新型資料庫處理技術——CompressDB,**本研究提出并實作了新型資料庫技術,利用背景關系無關文法來壓縮資料,通過新的資料結構和演算法設計實作對語法規則進行決議,CompressDB支持直接對壓縮后的資料進行資料查詢和操作,并且支持各種資料庫系統, **
SIGMOD評委對CompressDB的創新性給予了高度評價:在本文中,作者提出了一個支持直接對壓縮資料進行更新和計算的系統CompressDB,是一個優秀的系統作業,其作為檔案系統層實作,可以被現有的資料庫系統直接使用,作者通過在其上運行一系列關系資料庫和 NoSQL 資料庫來證明了這一點,同時作者在實作中表明,啟用CompressDB可以讓資料庫系統實作更高的吞吐量和更低的延遲,同時減少存盤空間,
一、論文概述
在如今的資料管理系統中,處理大資料時直接在壓縮資料上進行操作被證明是一種很成功的方式,這類系統展示了較大的壓縮優勢和性能提升,但是,當前此類系統只關注資料查詢,而一個完整的大資料管理系統必須支持資料查詢和資料操作,我們開發了一個新型存盤引擎CompressDB,CompressDB 支持壓縮資料上的直接資料處理,有以下優點:
第一,CompressDB 利用 context-free 語法來壓縮資料,并且同時支持資料查詢和資料操作,
第二,我們將CompressDB 集成到檔案系統中,使很多資料庫系統可以在不做任何改變的情況下使用CompressDB,
第三,我們將算子操作下推到存盤層,使得可以直接在存盤系統中執行資料查詢和資料操作,而不需要把大資料轉移到記憶體中,這提高了系統效率,
我們驗證了 CompressDB 可以支持多種型別的資料庫系統,包括 SQLite、LevelDB、MongoDB 和ClickHouse,我們用真實應用中的資料集測驗了 CompressDB 在單機和分布式環境下的性能,這些資料集有不同的資料量大小、結構和內容,實驗表明 CompressDB 平均帶來 40% 的吞吐量提升和 44% 的延遲縮短,并實作 1.81 倍的壓縮比,
二、研究動機
現代大資料系統面臨指數級增長的資料量,并使用資料壓縮來減少存盤空間,為了避免頻繁的壓縮和解壓縮操作的開銷,現有的研究探索了直接對壓縮資料執行大資料操作,這些系統在資料分析應用程式中表現出優秀的壓縮效率和性能提升,由于大資料通常存盤在磁盤中,我們的想法是基于規則在存盤層對壓縮資料進行隨機更新,
三、現有技術的局限性
現有的壓縮技術在只讀的查詢處理方面顯示出巨大潛力,但功能完整的大資料系統必須同時支持資料的讀和寫,這就需要系統支持隨機更新以及資料的插入和洗掉,現有的壓縮技術并不支持在壓縮資料上直接修改資料,因此每次修改時都必須解壓縮和重新壓縮相對較大的資料塊,從而導致巨大的開銷,
四、重要發現
本研究希望開發一種高效的技術來填補現有技術的不足,以支持直接對壓縮資料進行更新、插入和洗掉,從而實作一個支持資料查詢和資料操作的高效的大資料系統,這是一項具有挑戰性的任務,因為現有的壓縮技術大多僅針對壓縮效率或讀資料操作進行了優化,此外,現有技術的壓縮資料結構不能修改,例如,一些壓縮技識訓于索引和后綴陣列,其中壓縮元素相互依賴,如果一小部分資料需要更新,則效率極低,
五、系統設計
本研究開發了一個新的存盤引擎CompressDB,支持直接對壓縮資料進行資料查詢和資料操作,并且支持各種資料庫系統,我們發現,如果基于規則的壓縮方法的DAG(directed acyclic graph,有向無環圖)深度被限制在較小的數值,那么這種壓縮方法開銷較小,并適用于資料操作,基于此,CompressDB采用基于規則的壓縮技術并限制其規則生成深度,同時,CompressDB可以通過操作語法規則對資料進行實時壓縮和操作,與之前基于規則的壓縮方法相比,我們開發了一系列新的設計:在元素級別,我們提出了一種新的資料結構——資料洞(block hole),在規則級別,我們為隨機更新啟用了有效的規則定位和規則拆分方案,在 DAG 級別,我們降低了規則的深度以提高效率,通過利用新的資料結構和演算法設計,CompressDB無需解壓即可高效處理資料,
5.1 系統設計
圖1展示了CompressDB 的系統結構,CompressDB由三大模塊組成:1)資料結構模塊,2)壓縮模塊,3)運算模塊,這三個模塊支持基于CompressDB的資料庫系統,資料結構模塊為壓縮模塊和運算模塊提供必要的資料結構,包括三種:blockHashTable表示資料內容到塊位置的映射關系,blockRefCount記錄塊被參考次數,blockHole是更新操作引起的存盤空洞,壓縮模塊支持檔案系統中的分層壓縮,可應用于各種基于塊的檔案系統,操作模塊可以將用戶操作下推到檔案系統,
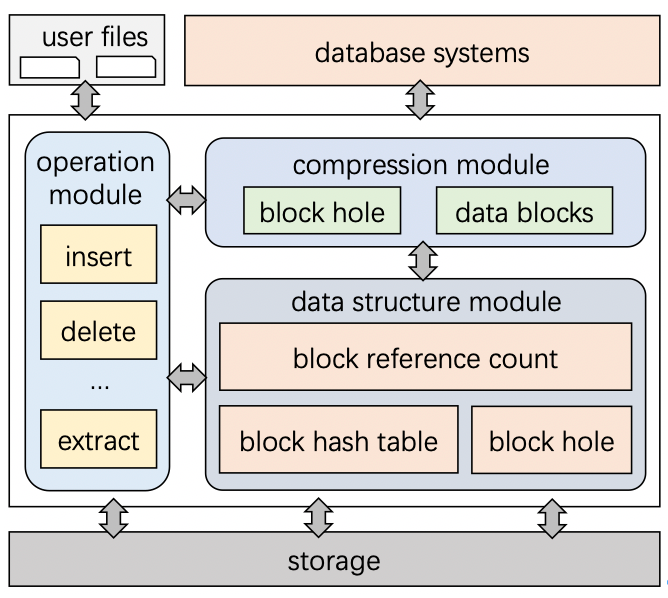
圖 : CompressDB系統結構
5.2 操作下推
為了降低資料傳輸成本,本研究將算子操作下推到存盤層,算子下推是指資料處理直接發生在檔案系統層(較低的軟體層),使處理操作發生在更接近資料的地方,基于這種技術,CompressDB可以顯著減少對磁盤的資料訪問量,并加速所有上層資料庫應用程式,
5.3 與資料庫系統的互動
為了使CompressDB能夠支持各種資料庫,本研究在檔案系統中開發CompressDB,在檔案系統層,CompressDB 可以處理讀取和寫入等系統呼叫,因為它們可以通過“提取”“替換”“添加”等操作實作,因此,CompressDB 可以支持在檔案系統上運行的不同型別的資料庫系統(例如,SQLite、MySQL、MongoDB 等),這些資料庫系統依賴于 CompressDB 提供的系統呼叫,因此,CompressDB 可以支持資料庫系統的各種資料型別(例如,整數、浮點數、字串等)和操作(例如,連接、選擇、插入等),此外,我們為CompressDB開發了一些檔案系統不支持的操作,例如“插入”和“洗掉”,因為這些操作沒有對應的POSIX介面,我們提供了一組單獨的 API,可以有效地使用,
5.4 適用性
CompressDB是一個存盤引擎,主要應用是支持各種資料庫系統,而無需修改代碼,用戶唯一需要做的就是將系統存盤目錄設定為 CompressDB 的存盤目錄,通常來說,CompressDB 適用于有大量冗余資料,并需要進行資料分析和操作的資料庫系統,對于其他應用場景,它可能仍然有效,但尚未驗證,
六、主要成果和貢獻
為了驗證 CompressDB 的性能,本研究使用CompressDB支持多個資料庫系統,包括 SQLite、LevelDB、MongoDB和ClickHouse,本研究分別在單節點和集群環境中,使用多個具有不同尺寸、結構和內容的真實資料集來評估性能,集群環境中的實驗使用五節點集群和一種高性能網路分布式檔案系統MooseFS,MooseFS 在集群中傳輸資料并提供對資料的高吞吐量訪問,與 MooseFS 的原始版本相比,CompressDB平均帶來了 40% 的吞吐量提升、44% 的延遲減少和 1.81 的壓縮比,這證明了本研究的有效性,本研究做出以下主要貢獻:
? 本研究直接在壓縮資料上開發高效的資料操作,例如插入、洗掉和更新,除了隨機訪問,本研究還支持資料查詢和資料操作,
? 本研究開發了CompressDB,這是一種集成到檔案系統中的存盤引擎,CompressDB可以無縫支持各種資料庫系統,而無需修改資料庫,
? 本研究將資料算子操作下推到存盤系統,避免了記憶體和磁盤之間不必要的資料移動,從而提高了壓縮資料的處理效率,
七、本次研究成果面向的領域
本研究成果面向同時支持資料查詢和資料操作的大資料管理系統,CompressDB提供的壓縮能力使資料管理系統能夠存盤較大的資料量,同時支持壓縮資料上高效的資料查詢和操作,存盤效率和資料查詢、操作效率在當今大資料時代是至關重要的性能指標,CompressDB可以幫助現有的資料庫系統同時提升這些指標的性能,
福利來啦!為幫助廣大資料庫愛好者更加詳細地了解本篇論文內容,我們邀請到了中國人民大學副教授、博士生導師、騰訊犀牛鳥基金獲得者張峰老師來到直播間深度解讀,6 月 21 日 15:00,一起來直播間學習吧!

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499146.html
標籤:其它