云原生時代需要什么樣的資料庫?如何構建資料庫服務?騰訊云資料庫技術負責人程彬認為,云資料庫未來趨勢會從以托管為核心升級到以極致效率為核心,助力業務降本增效,從資料庫管理和應用角度來看,云廠商、資源、客戶三角關系背后包含了三個維度的效率:系統效率、運營效率、業務效率,當這些效率都做到極致,成本會大幅下降,騰訊云資料庫是如何圍繞這三個緯度,打造極致效率來賦能業務的呢?
本期帶來騰訊云資料庫技術負責人程彬在第四屆云原生產業大會主論壇的分享實錄:
視頻完整版:《云原生時代的資料庫技術沿革》
大家好,我是騰訊云資料庫工程師程彬,代表團隊和大家談談對云原生時代資料庫技術的思考和騰訊云在云原生資料庫領域的落地實踐,
業務背景

我們觀察到,在IT架構領域,云原生已經取代云計算,迎來了一個新階段,在騰訊內部,每個業務系統會去看自己系統的云原生成熟度得分,不斷地去優化和提升,云原生相比云計算,有三個變化,應用場景上,從泛互聯網行業進入到了一個全行業數字化,進而帶來了資料規模的進一步的增大,基礎設施上,也發生了變化,云上IaaS PaaS變得更加成熟,創業公司、獨角獸、頭部上市公司乃至關乎民生的應用,他們的IT架構都構建在云上,
這些變化引起了我們團隊的思考,云原生時代需要什么樣的資料庫呢?我們怎么去構建資料庫服務?
我們認為,云資料庫應該從以托管為核心升級到以極致效率為核心,
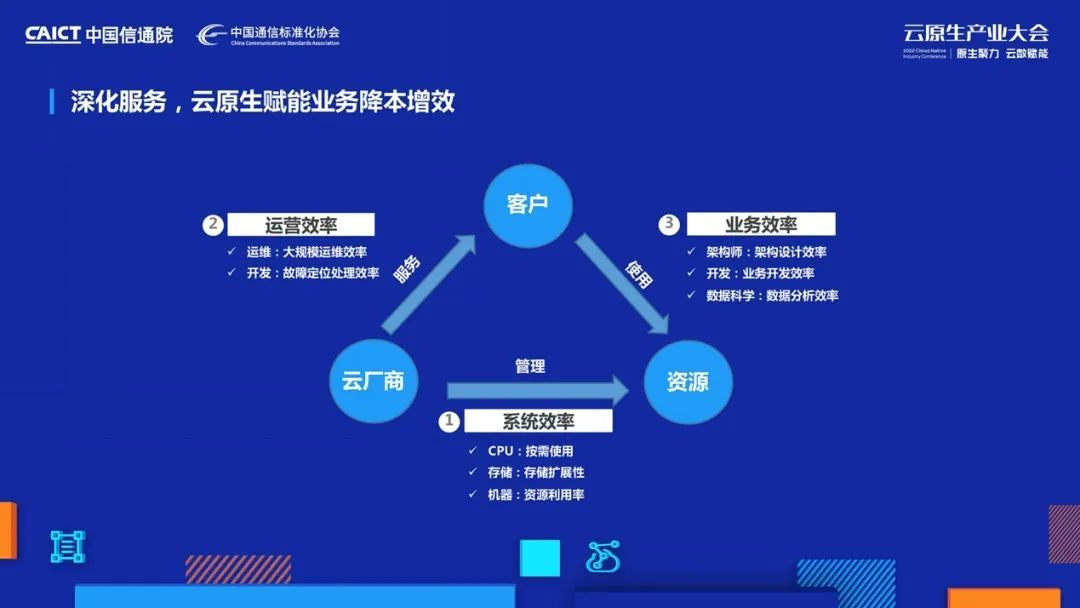
在講極致效率之前,我們先看看云資料庫背后的一個三角關系,這個三角關系就是云廠商利用和管理硬體資源,為客戶提供服務,客戶使用服務背后的資源來開展業務活動,它背后有三個效率,系統效率、運營效率和業務效率,
第一個系統效率,系統效率說的是兩個層面的事情,一個層面就是把CPU記憶體、硬碟這些資源全部用出去,不要閑置;另外一個層面是,用相同的資源能處理更多的請求,
第二個運營效率是說云廠商線上規模化運營效率,比較常見的就是資料庫調優,1w個實體1個DBA可以搞定,10w個實體或是100w個實體時,DBA人數就需要10個、100個嗎?
第三個業務效率是指怎么幫助業務提升開發效率,舉個例子,游戲出海需要全球同服,之前非常考驗業務架構師的水平,如果資料庫能提供低延時全球化部署能力,是不是能大大簡化業務架構呢?
大家仔細想想,這三個效率背后又指向了同一個詞“成本”,
系統效率
接下來,我就和大家分享,騰訊云資料庫怎么打造極致效率來幫助業務降本增效,
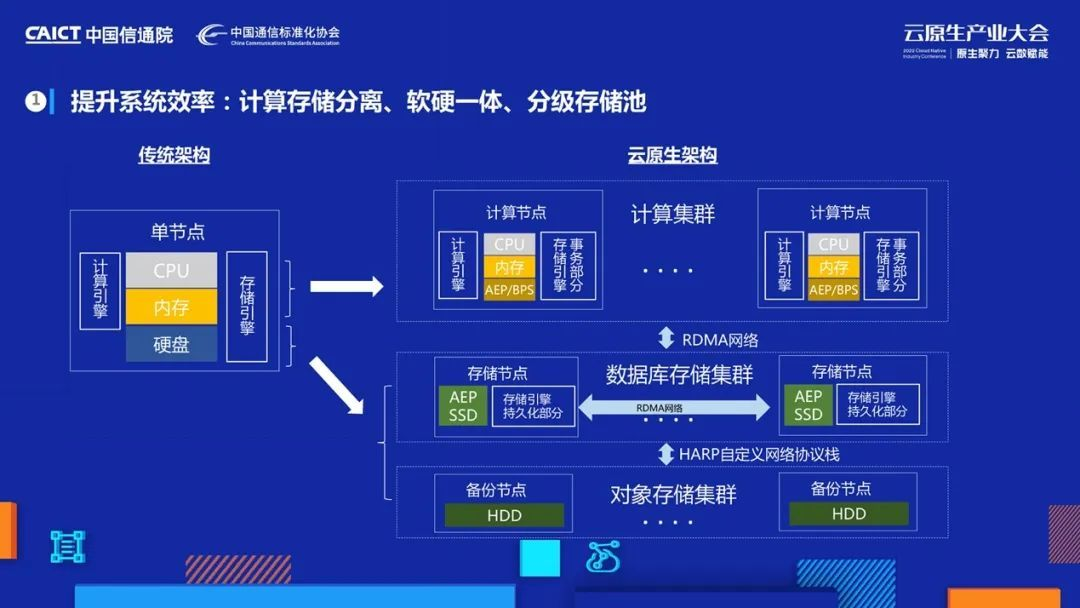
傳統資料庫架構都是基于資源一體化來進行設計的,這種設計在延時上帶來好處,但失去了靈活性和彈性,嚴重影響到了系統的效率,
我們設計了計算存盤分離的云原生架構,將存盤池化,計算無狀態化,大幅提升系統資源利用率,架構的變化當然會引入很多新的問題,比如計算存盤分離的網路延時問題,除了引入RDMA網路降低網路延時之外,我們還創新性地引入了多層存盤:在計算節點中加入了二級快取,把熱資料快取在本地,減少遠程IO,存盤上,除了多副本機制,我們還實作了糾刪碼+壓縮功能,在不降低資料可靠性的前提下,提供了低于1副本的低成本存盤能力,
做好系統效率一定先要保證架構效率,什么是架構效率呢?舉個例子,同樣是計算存盤分離架構,插入一條1KB記錄,需要傳輸多少資料到后端存盤呢?很多產品要傳輸16KB,放大了15倍,而我們架構設計只需要1KB加幾個位元組就可以了,
很多時候,架構上帶來的量級gap,很難靠軟體工程去彌補,所以,我們特別追求架構上的極致效率,因為產品需要有一個優秀基因,
運營效率
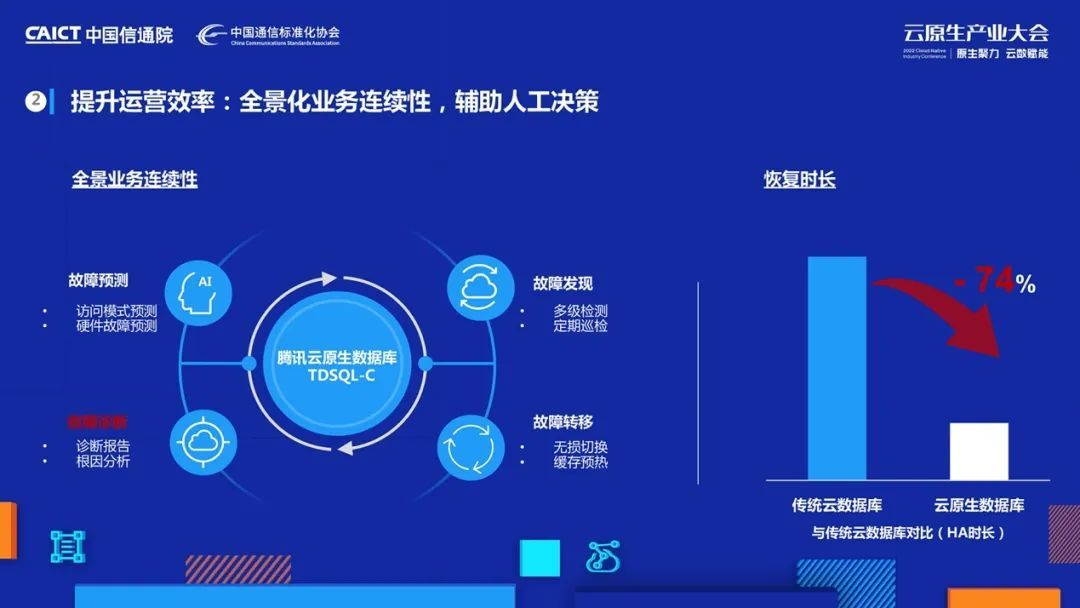
關于運營效率,主要和大家分享兩個點,業務連續性和自治,
針對業務連續性,我們提出了全景化的業務連續性方案,引入了故障預測機制來提前主動處理潛在隱患,在故障切換時,我們通過快取預熱來做到對業務的無損切換,
在故障診斷能力上,結合客戶負載變化和多級檢測資訊,生成全鏈路診斷報告和根因分析,提升運維效率并持續發現優化更多例外場景,
相比傳統資料庫架構,我們把業務連續故障場景切換耗時降低了74%,
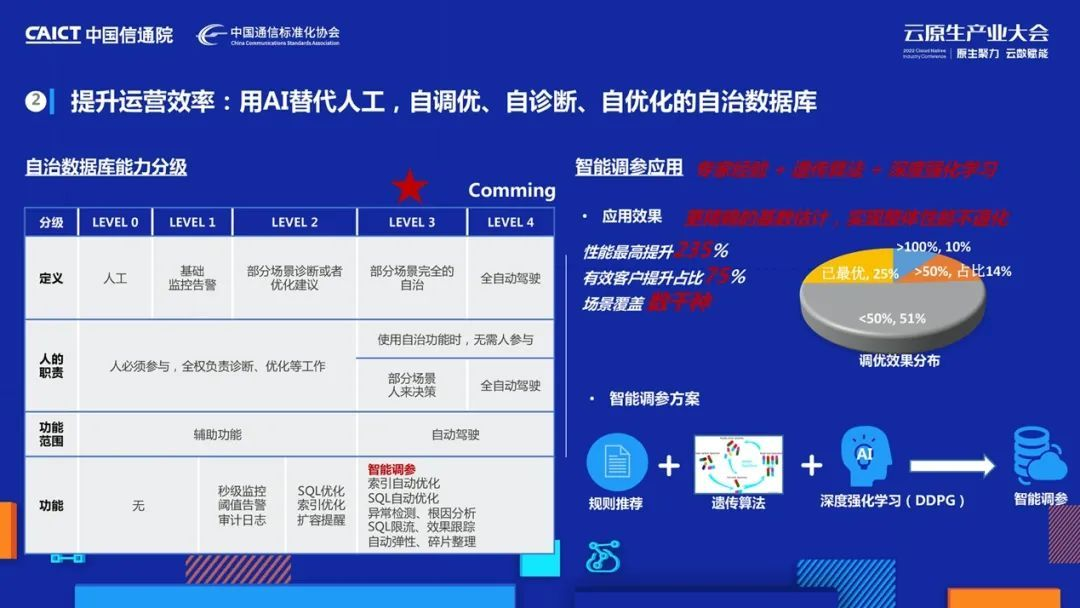
隨著業務規模快速增長,客戶多樣化,不合理使用資料庫的案例越來越多,資料庫問題分析和調優作業給我們帶來了極大挑戰,
怎么解決這個問題呢?我們走上了AI for system這條路,通過DB結合AI,用AI替代人工調優、診斷、優化,
我們先從資料庫調參開始,通過深度強化學習等AI演算法實作調參無需人為介入,在此基礎上,通過沉淀內部專家經驗和結合多種Al演算法,做到了調優速度可以通過增加并發度實作準線性的降低,
目前我們支持數千種調參場景、線上應用性能最高提升235%,調優時效從原來人工花費幾個小時縮短到幾分鐘,節省人力的同時,也大大降低了調優時長,
以上智能調參成果也被資料庫頂會SIGMOD兩次錄用,點擊延伸閱讀《三篇論文入選國際頂會SIGMOD,厲害了騰訊云資料庫》,
業務效率
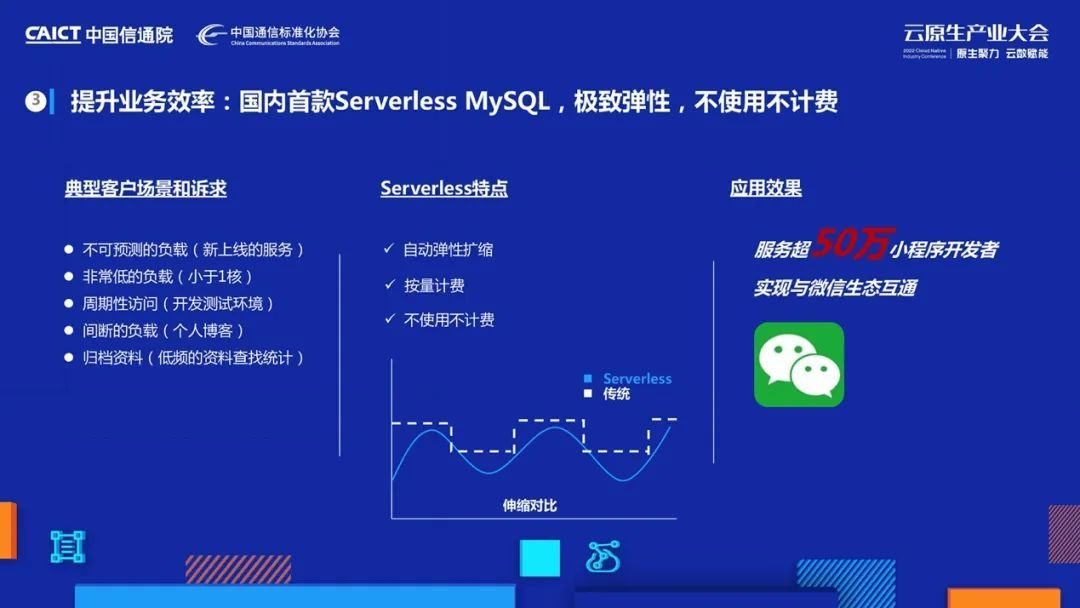
業務效率上,我們首先想到了云原生最初的核心:極致彈性,按需付費,不使用不付費,舉個例子,在公有云的實體中,有相當一部分中小規格的長尾業務,比如周期性開發測驗、個人博客、低頻資料查找等,他們對資料庫的使用負載并不高,對使用成本更敏感,
針對這類用戶,打破傳統固定規格的產品形態,打造根據業務的負載對計算資源進行自動伸縮,按照實際使用計費,不使用不計費的serverless形態,為了實作計算資源的自動伸縮,資料庫在啟停方面做了很多優化,保證系統能在幾秒內完成停機和重啟恢復,提升極致業務體驗,
目前我們資料庫serverless產品僅在微信生態上就為超過50W小程式開發者提供資料庫底座,點擊延伸閱讀《騰訊云資料庫協同微信云托管,助力業務降本增效》,
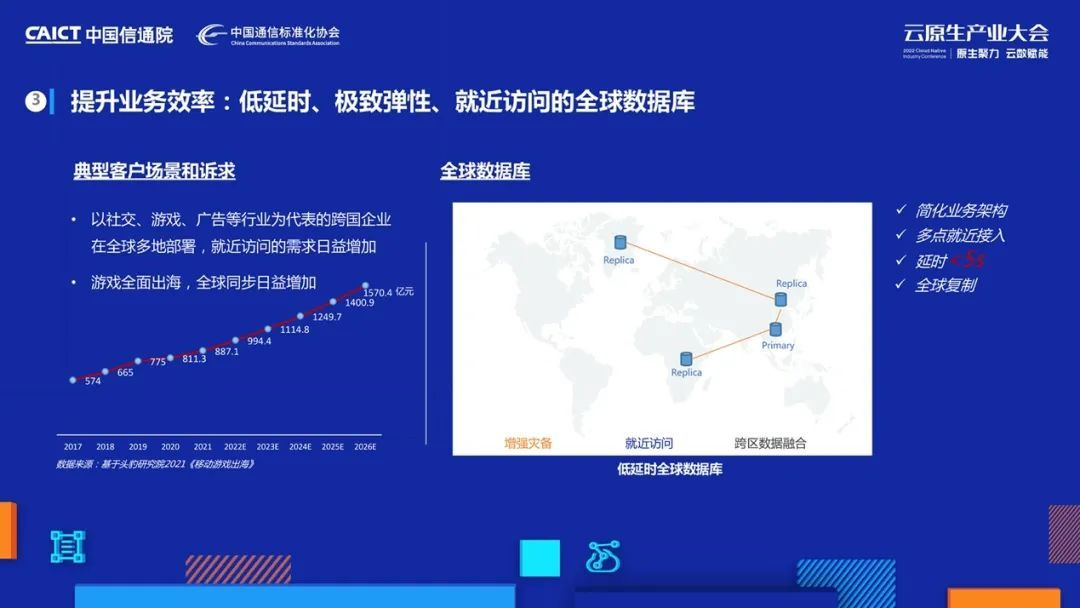
我們發現以社交、游戲、廣告為代表的跨國企業在使用資料庫時存在一大痛點,業務通常會在全球多地部署應用,例如,游戲出海,玩家在世界各地登陸賬號,為了保證登陸體驗,會在世界各地部署多個賬號資料庫,并實作彼此間的資料庫同步,這需要大量人力和精力維護,客戶亟需一個可以實作全球同步和就近訪問的資料庫,以此簡化應用架構,
針對這個問題,我們即將推出全球資料庫功能,提供跨Region部署能力,并在各地提供訪問點,方便客戶就近讀寫,通過物理日志復制技術,解決了跨地域復制的延時問題,
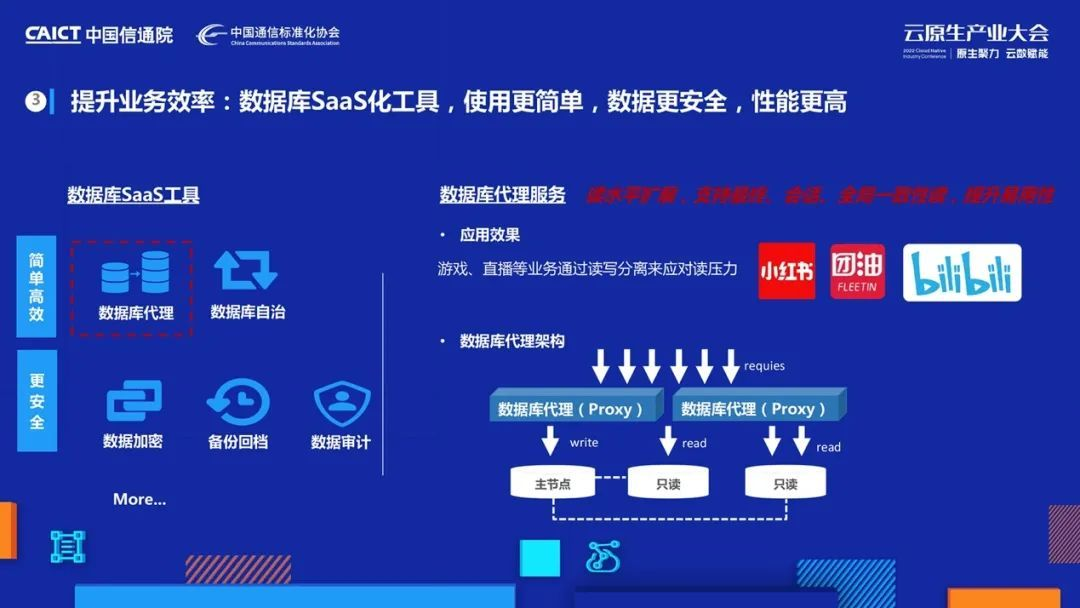
光為用戶提供一個好的資料庫引擎還遠遠不夠,要提升業務效率,還需要為用戶提供方便好用的各類SaaS工具,
騰訊云原生資料庫提供了多種SaaS化工具,例如,資料庫代理幫助業務高性能應對流量洪峰,資料庫自治工具智能調優幫助客戶提高整個系統級的SQL性能,資料庫加密、備份回檔、審計全鏈路幫助企業資料更安全、更合規,
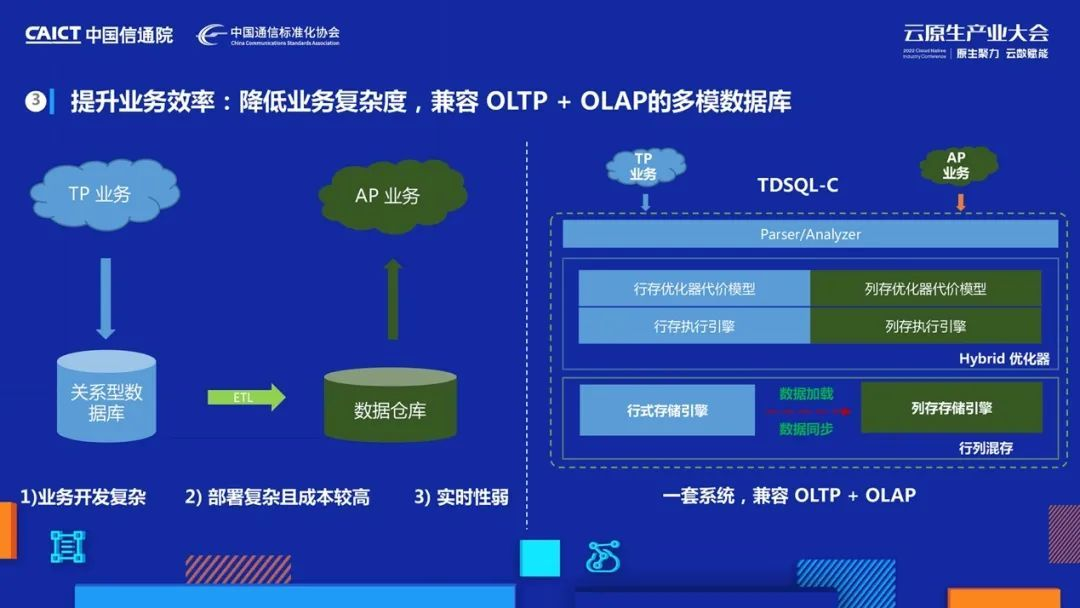
在混合負載處理場景上,我們也進行了一體化的設計,通過一套系統,對業務透明的方式提供OLTP和OLAP兩種資料查詢能力,目前灰度中,很快會上線,
未來展望
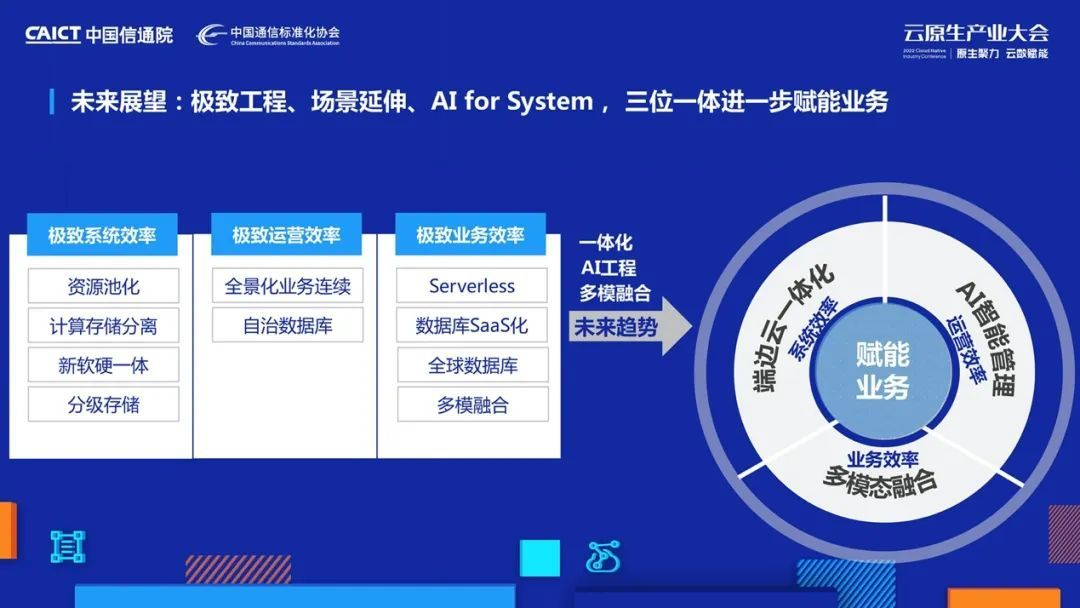
未來我們繼續探索架構的先進性、極致的軟體工程能力,與此同時,我們會深刻理解客戶業務場景,把架構能力、軟體工程能力覆寫到更多的業務場景中,比如,探索資料模型的融合,一庫多用、利用統一框架支撐更多的混合負載處理,來幫助業務降低資料庫架構的復雜度,從而提升應用效率,
同樣,我們繼續踐行AI for system,從外掛智能到內嵌智能,讓資料庫實作最高級別的自治能力,我們繼續在最優效率的資料庫道路上踏步前進,
今天我的分享就到這里了,再次感謝大家和云原生產業大會,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499148.html
標籤:其它