SQL 陳述句決議是一個重要且復雜的技術,資料庫流量相關的 SQL 審計、讀寫分離、分片等功能都依賴于 SQL 決議,而 Pisa-Proxy 作為 Database Mesh 理念的一個實踐,對資料庫流量的治理是其核心,因此實作 SQL 決議是一項很重要的作業,本文將以 Pisa-Proxy 實踐為例,為大家展現 Pisa-Proxy 中的 SQL 決議實作,遇到的問題及優化,
一、背景
關于語法分析
語法分析一般通過詞法分析器,如 Flex,生成相應的 token,語法分析器通過分析 token,來判斷是否滿足定義的語法規則,
語法分析器一般會通過決議生成器生成,
語法分析演算法常用的有以下:
- LL(自上而下)
與背景關系無關文法,從左到右掃描,從最左推導語法樹,相比 LR 更容易理解,錯誤處理更友好,
- LR(自下而上)
與背景關系無關文法,從左到右掃描,從最右節點推導語法樹,相比 LL 速度快,
- LALR
與 LR 類似,在決議時比 LR 生成的狀態更少,從而減少 Shift/Reduce 或者 Reduce/Reduce 沖突,被業界廣泛使用的 bison/yacc 生成的就是基于 LALR 決議器,
關于調研
在開發 SQL 決議之初,我們從性能、維護性、開發效率、完成度四方面分別調研了 antlr_rust,sqlparser-rs,nom-sql 專案,但都存在一些問題,
- antlr_rust
ShardingSphere 實作了基于 Antlr 的不同的 SQL 方言決議,為了使用它的 Grammar,我們調研了 antlr_rust 專案,此專案不夠活躍,成熟度不夠高,
- sqlparser-rs
在 Rust 社區里,sqlparser-rs 專案是一個較為成熟的庫,兼容各種 SQL 方言,Pisa-Proxy 在未來也會支持多種資料源,但是由于其詞法和語法決議都是純手工打造的,對我們來說會不易維護,
- nom-sql
nom-sql 是基于 nom 庫實作的 SQL 決議器,但是未實作完整,性能測驗不如預期,
- grmtools
Grmtools 是在尋找 Rust 相關的 Yacc 實作時發現的庫,該庫實作了兼容絕大部分 Yacc 功能,這樣就可以復用 MySQL 官方的語法檔案,但是需要手寫 Lex 詞法決議,經過對開發效率及完成度權衡后,我們決定做難且正確的事,實作自己的 SQL 決議器,快速實作一個 Demo 進行測驗,
編碼完成后,測驗效果還不錯,
總結如下:
| 工具 | antlr_rust | sqlparser-rs | nom-sql | grmtools |
|---|---|---|---|---|
| 完成度 | ? | ? | ||
| 性能 | ? | ? | ||
| 維護性 | ? | |||
| 開發效率 | ? | ? |
最終我們選擇了 Grmtools 來開發 Pisa-Proxy 中的 SQL 決議,
二、Grmtools 使用
使用 Grmtools 決議庫大致分為兩個步驟,下面以實作計算器為例,
- 撰寫 Lex 和 Yacc 檔案
Lex:創建 calc.l,內容如下:
/%%
[0-9]+ "INT"
\+ "+"
\* "*"
\( "("
\) ")"
[\t ]+ ;
Grammar:創建 calc.y 內容如下:
%start Expr
%avoid_insert "INT"
%%
Expr -> Result<u64, ()>:
Expr '+' Term { Ok($1? + $3?) }
| Term { $1 }
;
Term -> Result<u64, ()>:
Term '*' Factor { Ok($1? * $3?) }
| Factor { $1 }
;
Factor -> Result<u64, ()>:
'(' Expr ')' { $2 }
| 'INT'
{
let v = $1.map_err(|_| ())?;
parse_int($lexer.span_str(v.span()))
}
;
%%
- 構造詞法和語法決議器
Grmtools 需要在編譯時生成詞法和語法決議器,因此需要創建 build.rs,其內容如下:
use cfgrammar::yacc::YaccKind;
use lrlex::CTLexerBuilder;
fn main() -> Result<(), Box<dyn std::error::Error>> {
CTLexerBuilder::new()
.lrpar_config(|ctp| {
ctp.yacckind(YaccKind::Grmtools)
.grammar_in_src_dir("calc.y")
.unwrap()
})
.lexer_in_src_dir("calc.l")?
.build()?;
Ok(())
}
- 在應用中集成決議
use std::env;
use lrlex::lrlex_mod;
use lrpar::lrpar_mod;
// Using `lrlex_mod!` brings the lexer for `calc.l` into scope. By default the
// module name will be `calc_l` (i.e. the file name, minus any extensions,
// with a suffix of `_l`).
lrlex_mod!("calc.l");
// Using `lrpar_mod!` brings the parser for `calc.y` into scope. By default the
// module name will be `calc_y` (i.e. the file name, minus any extensions,
// with a suffix of `_y`).
lrpar_mod!("calc.y");
fn main() {
// Get the `LexerDef` for the `calc` language.
let lexerdef = calc_l::lexerdef();
let args: Vec<String> = env::args().collect();
// Now we create a lexer with the `lexer` method with which we can lex an
// input.
let lexer = lexerdef.lexer(&args[1]);
// Pass the lexer to the parser and lex and parse the input.
let (res, errs) = calc_y::parse(&lexer);
for e in errs {
println!("{}", e.pp(&lexer, &calc_y::token_epp));
}
match res {
Some(r) => println!("Result: {:?}", r),
_ => eprintln!("Unable to evaluate expression.")
}
}
詳見: grmtools - grmtools
上文已經提到,我們需要手寫詞法決議,是因為在原生的 Grmtools 中,詞法決議是用正則匹配的,對于靈活復雜的 SQL 陳述句來說,不足以滿足,因此需要手工打造詞法決議,在 Grmtools 中實作自定義詞法決議需要我們實作以下 Trait:
lrpar::NonStreamingLexer
另外也提供了一個方便的方法去實體化:
lrlex::LRNonStreamingLexer::new()
三、遇到的問題
基于以上,我們開發了 SQL 詞法決議,復用了 MySQL 官方的 sql_yacc 檔案,在開發程序中,也遇到了以下問題,
- Shift/Reduce 錯誤
Shift/Reduce conflicts:
State 619: Shift("TEXT_STRING") / Reduce(literal: "text_literal")
這是使用 LALR 演算法經常出現的錯誤,錯誤成因一般通過分析相關規則解決,例如常見的 If-Else 陳述句,規則如下:
%nonassoc LOWER_THEN_ELSE
%nonassoc ELSE
stmt:
IF expr stmt %prec LOWER_THEN_ELSE
| IF expr stmt ELSE stmt
當 ELSE 被掃描入堆疊時,此時會有兩種情況,
1)按第二條規則繼續 Shift
2)按第一條規則進行 Reduce
這就是經典的 Shift/Reduce 錯誤,
回到我們的問題,有如以下規則:
literal -> String:
text_literal
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
分析:
| stack | Input token | action |
|---|---|---|
| test | Shift test | |
| test | $ | Reduce: text_literal/Shift: TEXT_STRING |
方案:
需要設定優先級解決,給 text_literal 設定更低的優先級,如以下:
%nonassoc 'LOWER_THEN_TEXT_STRING'
%nonassoc 'TEXT_STRING'
literal -> String:
text_literal %prec 'LOWER_THEN_TEXT_STRING'
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
- SQL 包含中文問題
在使用詞法決議時,.chars() 生成字串陣列會出現陣列長度和字符長度不一致的情況,導致決議出錯,要更改為 .as_bytes() 方法,
四、優化
- 在空跑決議(測驗代碼見附錄),不執行 action 的情況下,性能如下:
[mworks@fedora examples]$ time ./parser
real 0m4.788s
user 0m4.781s
sys 0m0.002s
嘗試優化,以下是火焰圖:

通過火焰圖發現,大部分 CPU 耗時在序列化和反序列化,以下是定位到的代碼:
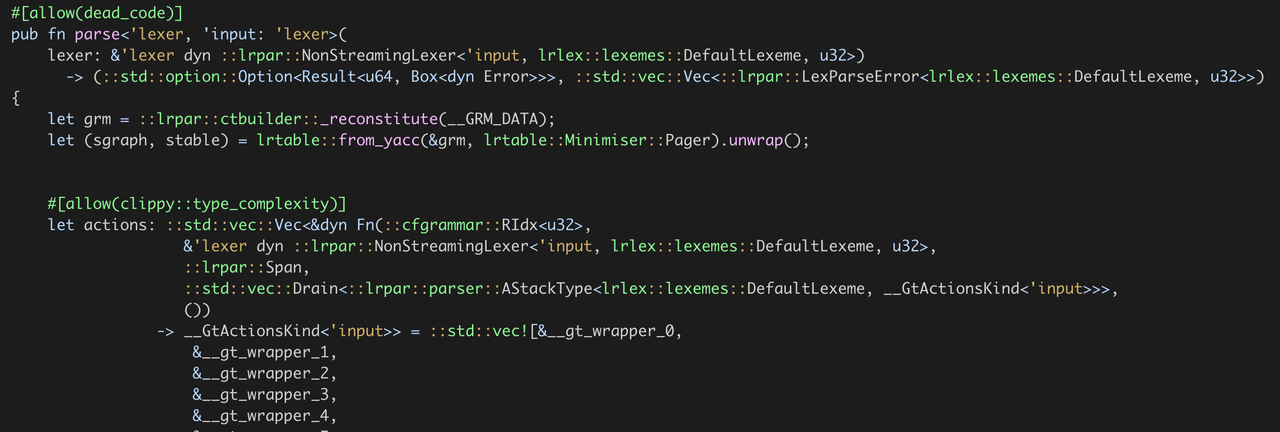
可以看出在每次決議的時候都需要反序列化資料,在編譯完之后,__GRM_DATA 和 __STABLE_DATA 是固定不變的, 因此 grm,stable 這兩個引數可以作為函式引數傳遞,更改為如下:
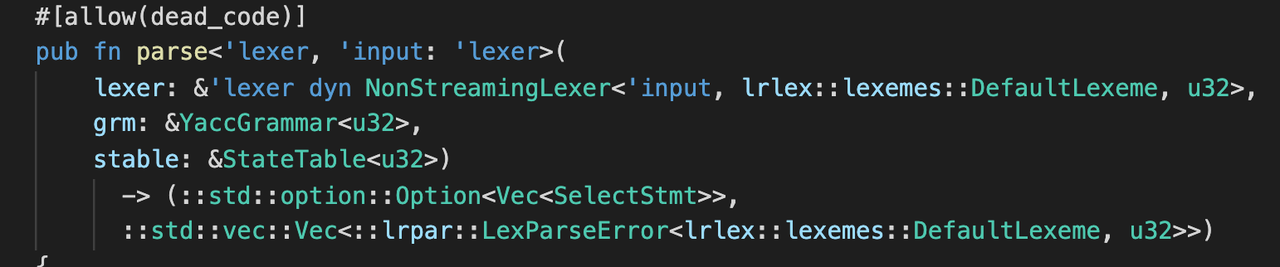
- 再分析,每次決議的時候,都會初始化一個 actions 的陣列,隨著 grammar 中語法規則的增多,actions 的陣列也會隨之增大,且陣列元素型別是 dyn trait 的參考,在運行時是有開銷的,
再看代碼,發現 actions 陣列是有規律的,如以下:
::std::vec![&__gt_wrapper_0,
&__gt_wrapper_1,
&__gt_wrapper_2,
...
]
因此我們可以手動建構式,以下是偽代碼:
match idx {
0 => __gt_wrapper_0(),
1 => __gt_wrapper_1(),
2 => __gt_wrapper_2(),
....
}
通過 gobolt 查看匯編,發現差異還是很大,省去了陣列的相關開銷,也能極大地減少記憶體使用,

詳見:https://rust.godbolt.org/z/zTjW479f6
但是隨著 actions 陣列的不斷增大,會有大量的 je,jmp 指令,不清楚是否會影響 CPU 的分支預測,如影響是否可以通過 likely/unlikely 方式優化,目前還沒有進行測驗,
最侄訓焰圖對比
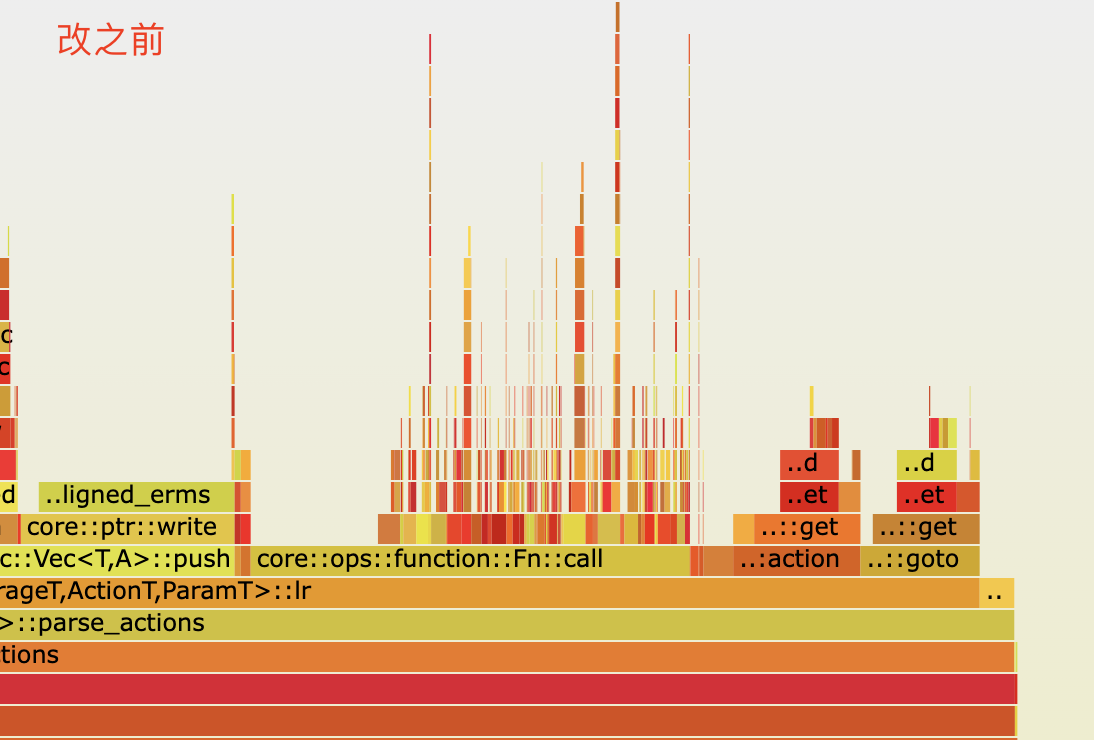
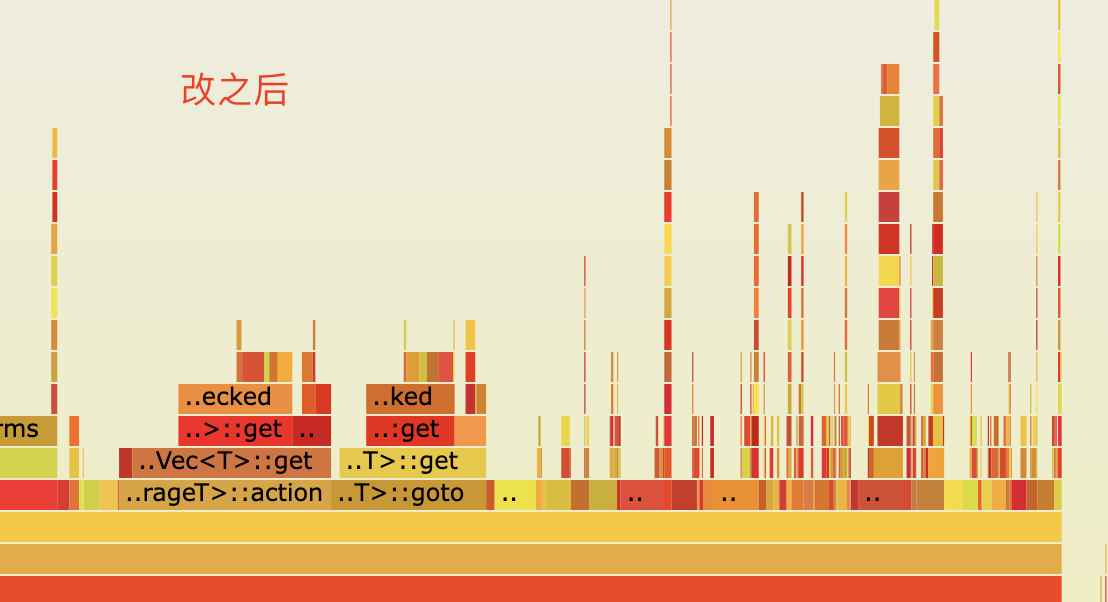
最終測驗結果
[mworks@fedora examples]$ time ./parser
real 0m2.677s
user 0m2.667s
sys 0m0.007s
五、總結
本文為 Pisa-Proxy SQL 決議解讀系列第一篇,介紹了在 Pisa-Proxy 中開發 SQL 決議背后的故事,后續我們會陸續為大家詳細介紹 Yacc 語法規則的撰寫,Grmtools 中組件及實用工具等內容,敬請期待,
附錄
Pisa-Proxy 的 SQL 決議代碼:
pisanix/pisa-proxy/parser/mysql at master · database-mesh/pisan
測驗代碼
let input = "select id, name from t where id = ?;"
let p = parser::Parser::new();
for _ in 0..1_000_000
{
let _ = p.parse(input);
}
Pisanix
專案地址:https://github.com/database-mesh/pisanix
官網地址:https://www.pisanix.io/
Database Mesh:https://www.database-mesh.io/
SphereEx 官網:https://www.sphere-ex.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499150.html
標籤:其它