在如今的業務場景下,高可用性要求越來越高,核心業務跨可用區已然成為標配,騰訊云資料庫高級工程師劉家文結合騰訊云資料庫的內核實戰經驗,給大家分享Redis是如何實作多可用區,內容包含Redis主從版、集群版原生架構,騰訊云Redis集群模式主從版、多AZ架構實作以及多AZ關鍵技術點,具體可分為以下四個部分:
第一部分:介紹Redis的原生架構,包含主從版及集群版;
第二部分:介紹騰訊云Redis架構,為了解決主從架構存在的問題,騰訊云使用了集群模式的主從版,其次為了更好的適應云上的Redis架構,引入了Proxy;
第三部分:分析原生Redis為何不能實作多AZ架構的高可用以及騰訊云是如何實作多可用區;
第四部分:分享實作多可用區的幾個關鍵技術點,包含節點部署、就近接入及節點的選主機制,
點擊觀看視頻
Redis原生架構
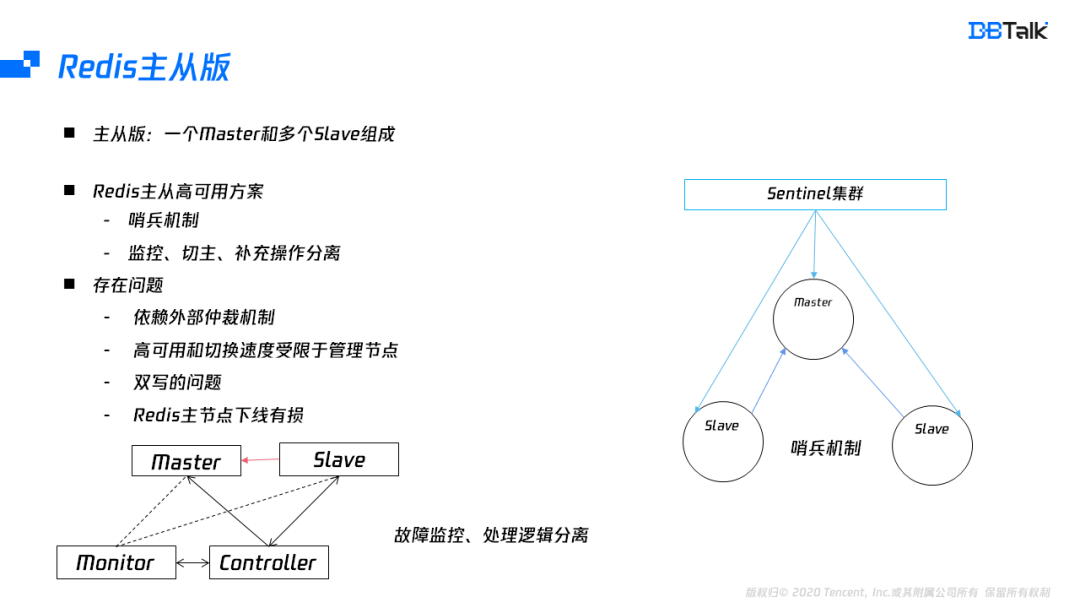
Redis的原生架構包含主從版及集群版,主從版是由一個master,多個slave組成,主從的高可用一般采用哨兵模式,哨兵模式在節點故障后,能自動把相應的節點進行下線處理,但是哨兵模式無法補節點,為了配合補從,需要管控組件進行協助,因此一般會將監控組件和管控組件配合完成主從版的一個高可用,無論是哪種方式,主從版的可用性依賴外部的仲裁組件,存在恢復時間長及組件本身的高可用問題,其次主從版還會導致雙寫的問題及提主有損的功能缺陷,
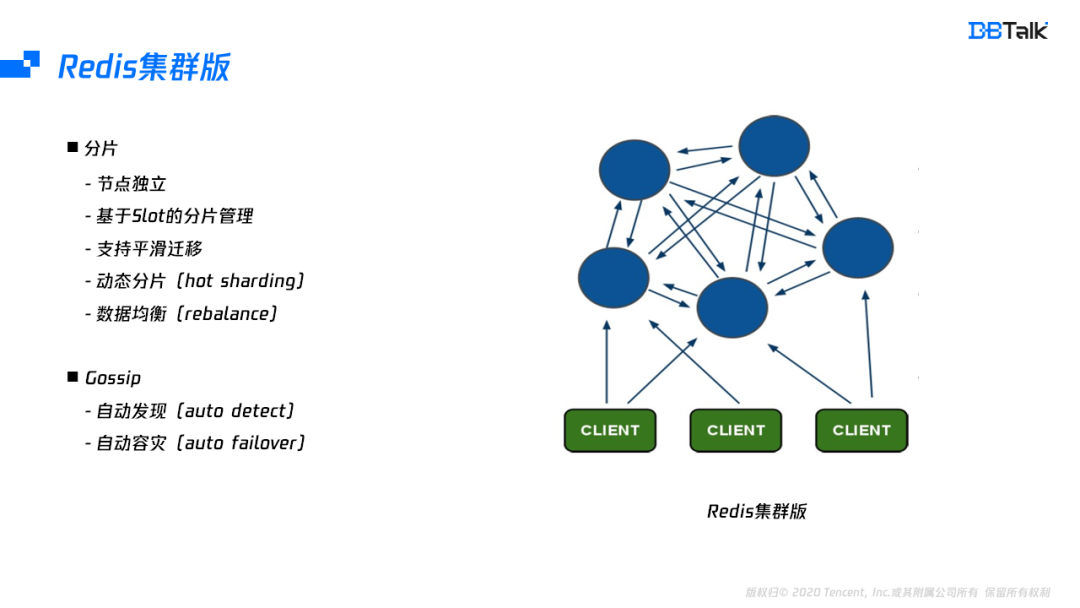
Redis的集群版中的每一個節點相互獨立,節點之間通過Gossip協議來進行通信,每一個節點都保存了集群中所有節點的一個資訊,集群版的資料基于slot進行分片管理,slot總共有16384個,節點的 slot并不是固定的,可以通過搬遷key的方案來完成slot的遷移,有了slot的搬遷功能,集群版可以實作資料均衡及分片的動態調整,
Redis集群版內部集成了Gossip協議,通過Gossip協議能完成節點的自動發現和自動成災的功能,自動發現是指一個節點要加入到集群中,只需要加入集群中的任何一個節點,加入后,新節點的資訊會通過Gossip推廣到集群中的所有的節點,同理,當一個節點故障后,所有節點都會把故障資訊發送給集群其它節點,通過一定的判死邏輯,它會讓這個節點進行自動下線,這個也就是Redis集群版的自動容災功能,
為了說明單可用區是如何部署的,我們需要進一步了解Redis集群版的自動容災,自動容災總共分為兩個步驟,第一個就是我們的判死邏輯,當超過一半的主節點認為該節點故障,集群就會認為這個節點已經故障,此時從節點會發起投票,超過一半的主節點授權該節點為主節點時,它會將角色變為主節點,同時廣播角色資訊,

根據上面這兩點分析,不難發現Redis集群版有兩個部署要求,一個是主從不能同機,當主從同機的機器故障后,整個分片就相當于已經故障了,集群也就變為一個不可用的狀態,其次是我們的節點數不能超過分片數的一半,這里要注意的是節點數,而不是只限制主節點數,
上圖的右邊部分是錯誤部署方式,在集群節點狀態沒有變化的情況下,是能夠滿足高可用的,但集群的主從發生切換后,一個機器上的主節點已經超過大多數,而這個大多數機器故障后,集群無法自動恢復,因此三分三從的集群版,要滿足高可用總共需要六臺機器,
騰訊云Redis架構
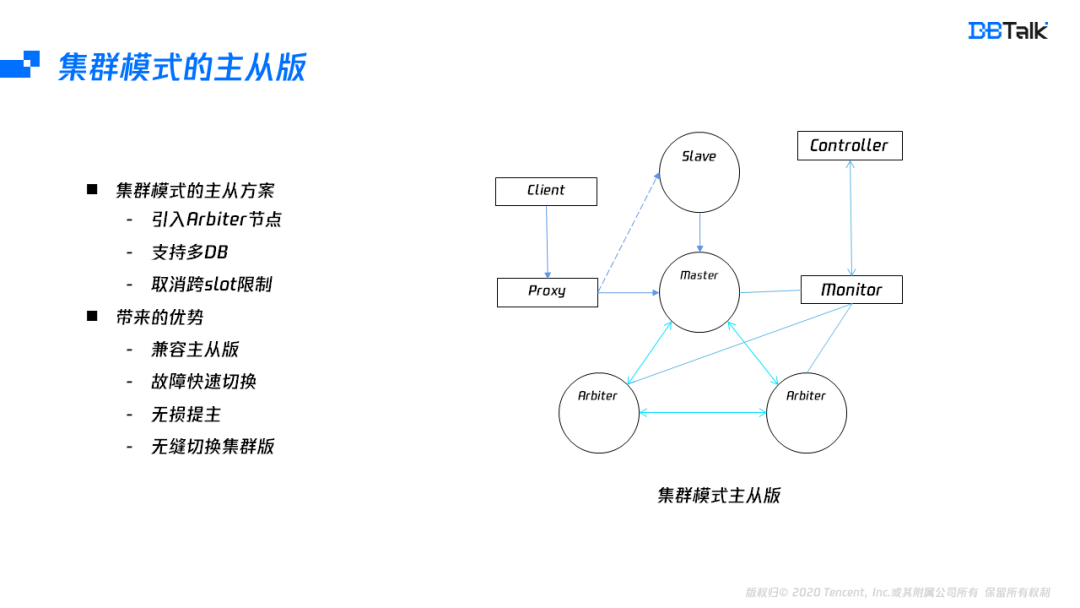
為了解決雙主的問題及支持無損提主的操作,騰訊云上使用了集群模式的主從版,實作集群模式的主從版,先要解決三個問題:
第一個是集群模式需要至少3個投票(仲裁)節點的問題,由于主從版本只有一個Master,為了達到3個仲裁節點,我們引入了兩個Arbiter節點,Arbiter只有投票權,不存盤資料,通過這個改造后,就能夠滿足了集群版的高可用,
第二個是多DB問題,由于騰訊云上引入了Proxy,減少了對多DB管理的復雜,因此可以放開單DB限制,
最后一個是需要啟用跨slot訪問,在主從版中,所有的slot都在一個節點上面,不存在跨節點問題,因此可以取消跨slot限制,
解決完這幾個主要問題后,集群模式可以達到完全兼容主從版,同時擁有集群版的自動容災、無損提主及可以在業務支持的情況下,無縫升級為集群版,
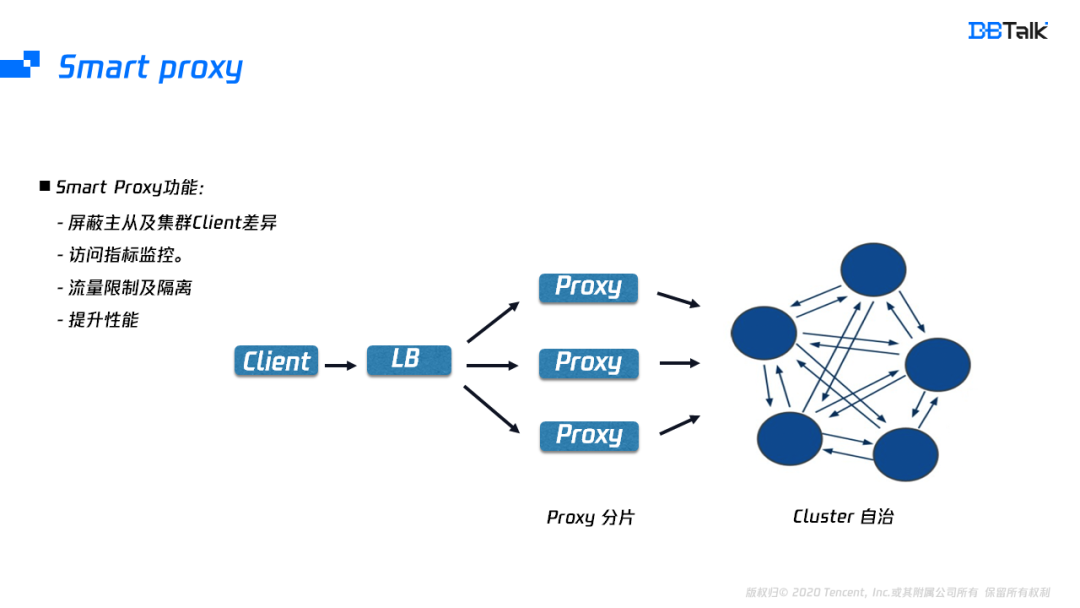
由于Client版本比較多,為了兼容不同的Client,騰訊云引入了Proxy,Proxy除了屏蔽Client的差異外,也屏蔽的后端Redis的版本差異,業務可以使用主從版的Client去使用后端的集群版,Proxy也補齊了Redis缺少的流量隔離及支持更豐富的指標監控,還能將多個連接的請求轉換為pipeline請求轉發到后端,提升Redis的性能,
Redis的多AZ架構
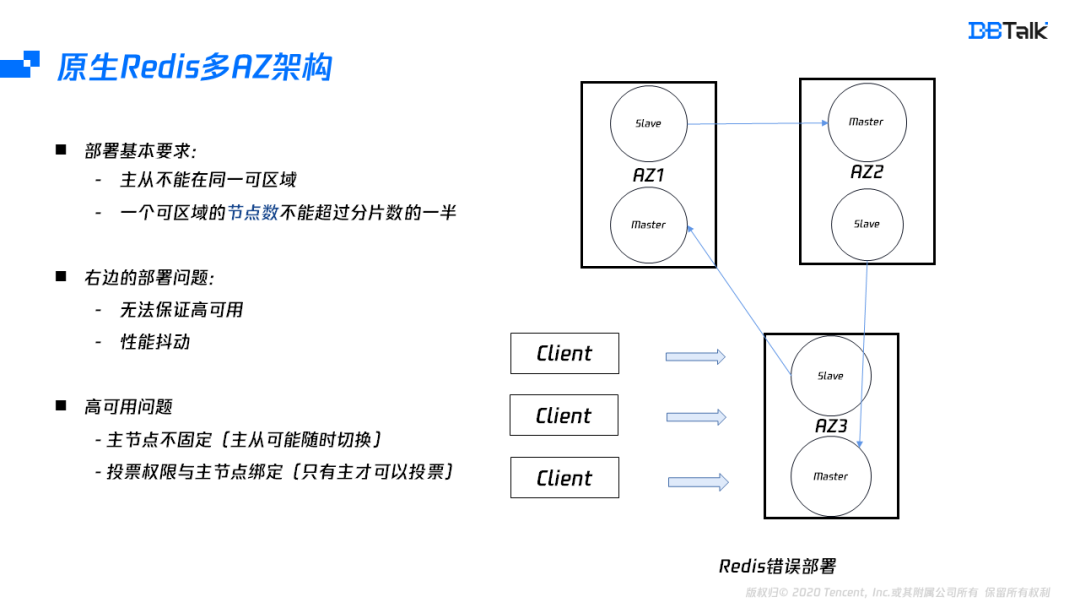
部署高可用的多可用區架構,需要至少滿足兩個條件:
主從不能部署到同一個可用區;
一個可用區的節點數不能超過分片數的一半,
如果我們部署一個三分片的實體,那應該需要個6個可用區才能真正保證它的高可用,即使可用區充足,它也會有性能的抖動,訪問本可用區,性能和單可用區相同,但如果跨可用區訪問,至少出現2ms延遲,因此原生的Redis是不適合多可用區的部署,為了實作高可用的部署,我們需要更深入的分析它的問題所在,這種場景的高可用不滿足主要是由于主節點漂移,而投票權和主節點又是系結關系,當投票權在不同可用區間切換后,導致超過大多數投票節點在該可用區,此時該可用區故障后就會出現集群無法恢復的情況,
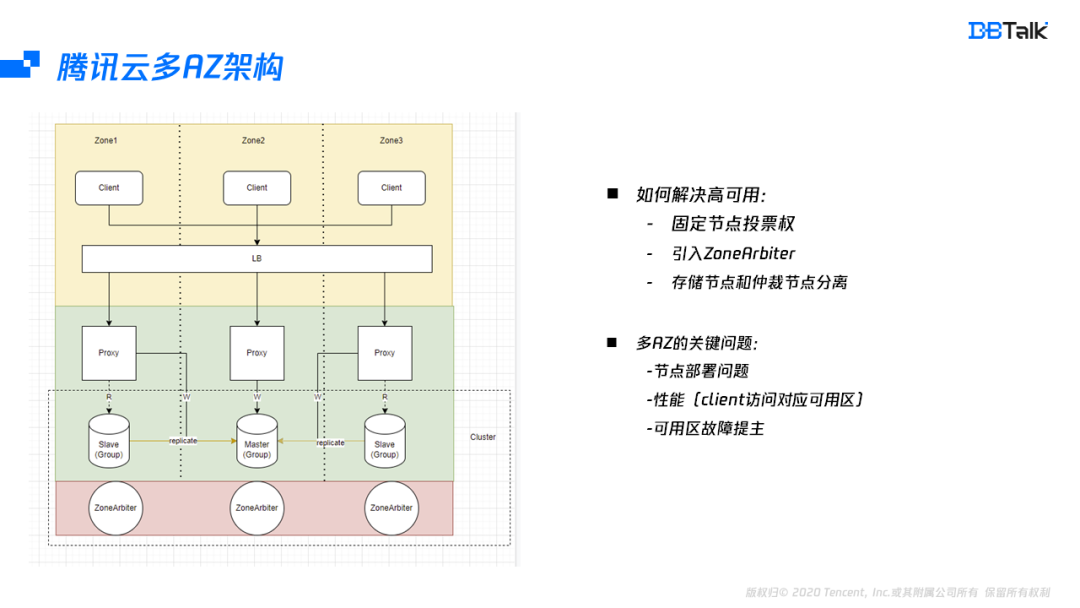
從上面分析可以看出,高可用的問題是由于投票權發生漂移導致的,假如能把投票權固定在某些節點上面,這樣投票權就可以不再漂移,當然這里無法將投票權固定在從或者主節點上,對于多可用區,最好的方式就是引入了一個ZoneArbiter節點,它只位元組點的判死及選主,不存盤任何資料,這樣投票權就從存盤節點中分離出來,在投票權分離后,即使資料節點的Master可以位于一個可用區,從位于不同的可用區也能滿足高可用,業務在主可用區中訪問和單可用區訪問性能是相同的,
多AZ的關鍵技術
保證高可用后,接下來介紹多可用區的三個關鍵的點:高可用如何部署、性能如何達到最優、可用區故障后保證集群自動恢復,
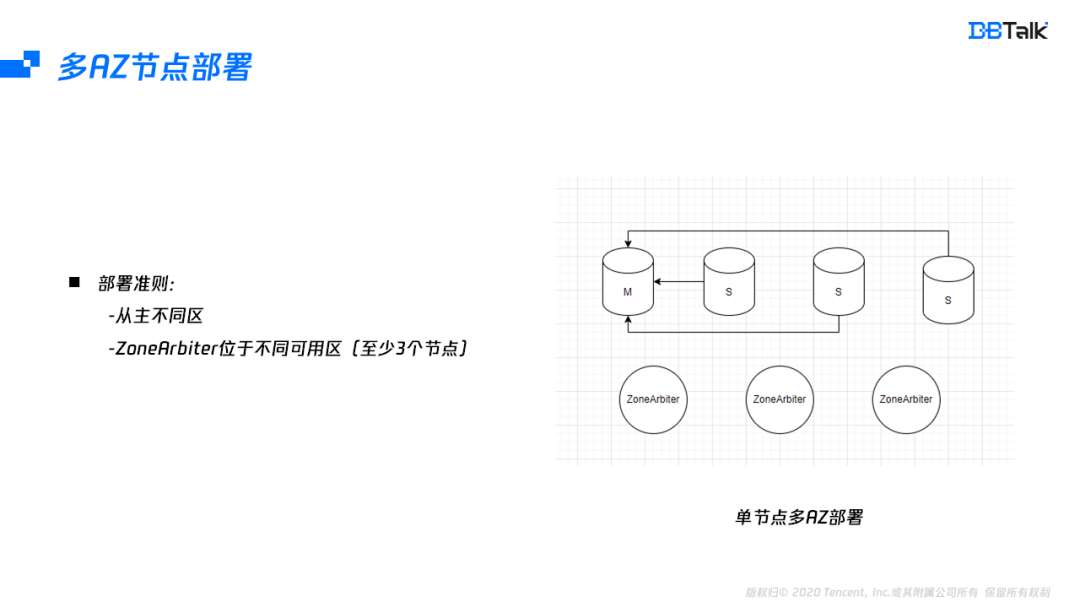
節點部署同樣需要滿足兩個點:第一是主從不能同可用區,這個比較容易滿足,只要有2個可用區即可,第二點是至少三個ZoneArbiter節點位于不同的可用區,第二個條件需要三個可用區,如果沒有三個可用區的地域也可以將ZoneArbiter部署于就近的地域,因為資料節點和仲裁節點是分離的,位于其它可用區的節點只會出現判死及提主有毫秒級延遲,對性能和高可用不會有任何影響,
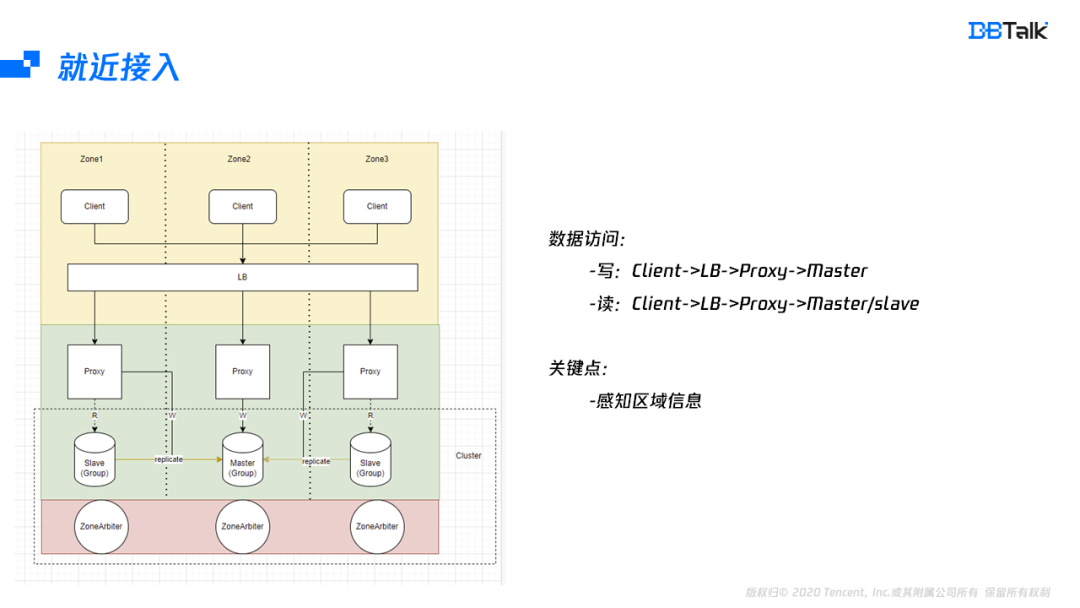
分析完部署后,再來看下資料的存盤鏈路,存盤鏈路分為讀和寫鏈路,寫鏈路是從client到LB,再到Proxy,最后將資料寫入到相應的Master,在讀的時候,開啟就近讀的特性后,鏈路從client到LB,再到Proxy,最后選擇一個就近的節點讀取資料,就近路徑選擇包含LB的就近選擇及Proxy的就近選擇,LB要根據Client的地址選擇相對應的Proxy,如果是讀,Proxy要跟據自身所在可用區資訊選擇同可用區的節點進行讀訪問,如果是寫,Proxy需要訪問主可用區的Master節點,能實作就近訪問,最關鍵的一個點就是要LB及Proxy要存盤相關后端的可用區資訊,有這些資訊后,就能實作就近的路由選擇,
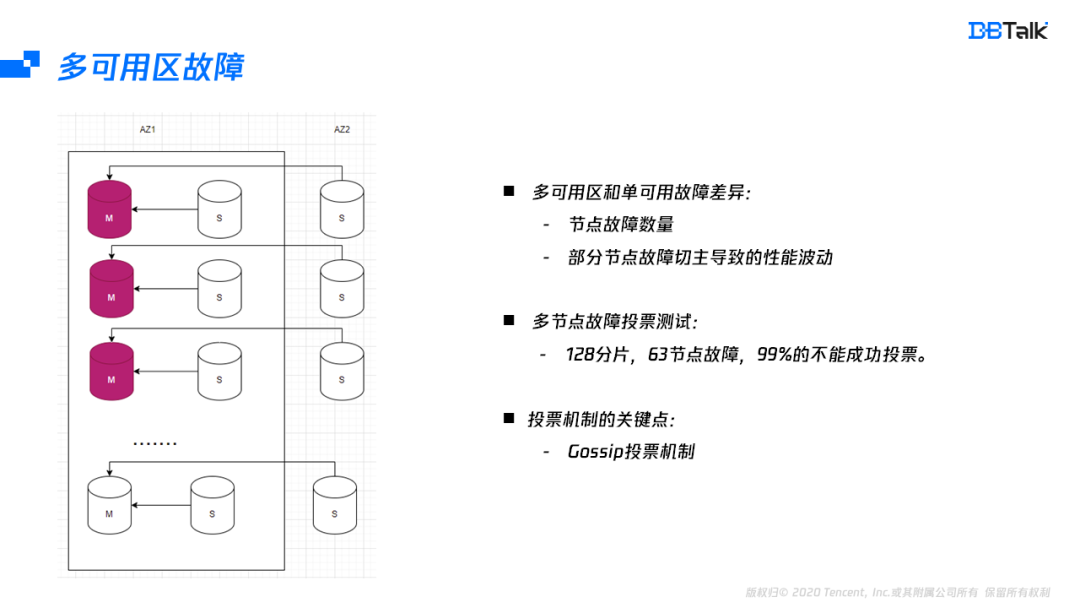
單可用區和多可用區故障的最大區別是:首先多可用區的某一節點故障后,主節點有可能切到其它可用區會導致性能波動,其次對于多可用區的實體,整個可用區故障后,需要投票的節點比單可用區的節點多,在多節點故障的場景測驗中,128分片,63節點同時故障,99%以上都無法正常恢復集群,而無法恢復的關鍵就是Redis的選主機制導致,因此我們需要更深入的理解Redis的選主機制,
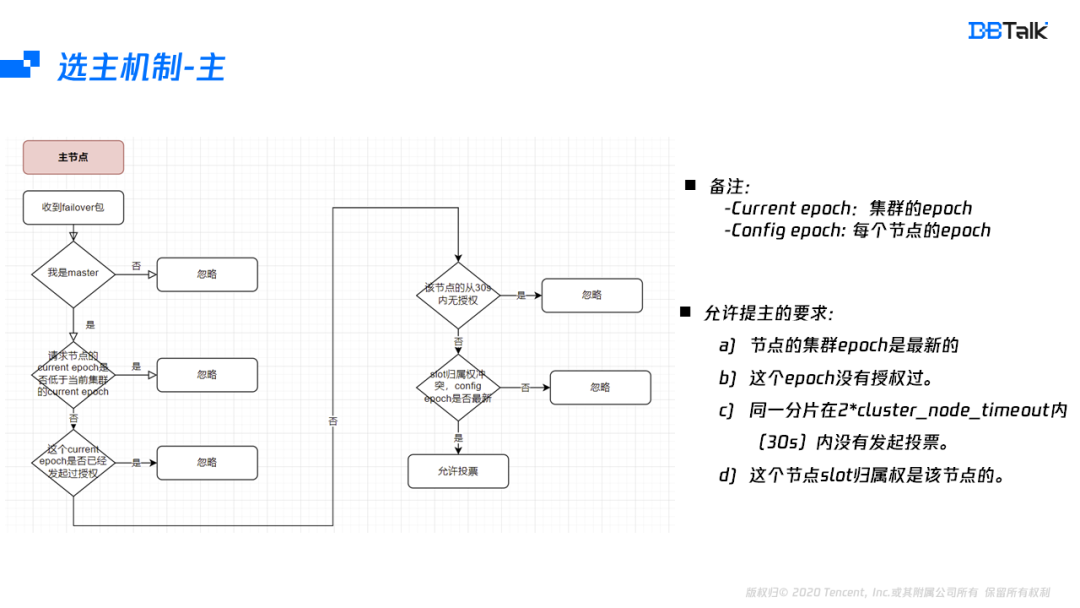
首先看下選主機制的授權機制,當主節點收到一個failover資訊后,核對自身節點為Master,然后檢查投票的這個節點集群的epoch是不是最新的,并且在這個epoch,并沒有投票任何的節點,為了防止一個節點的多個從節點重復發起投票,這里在30s內不允許重復發起,最后再核對這個slot的歸屬權是否屬于發起failover的這個節點,如果都沒有問題,那么就會投票給該節點,
綜上,允許該主節點投票的條件是:
- 發起投票的節點的集群資訊是最新的;
- 一個epoch只能授權一個節點;
- 30s內同一分片只能授權一次;
- slot的歸屬權正確,
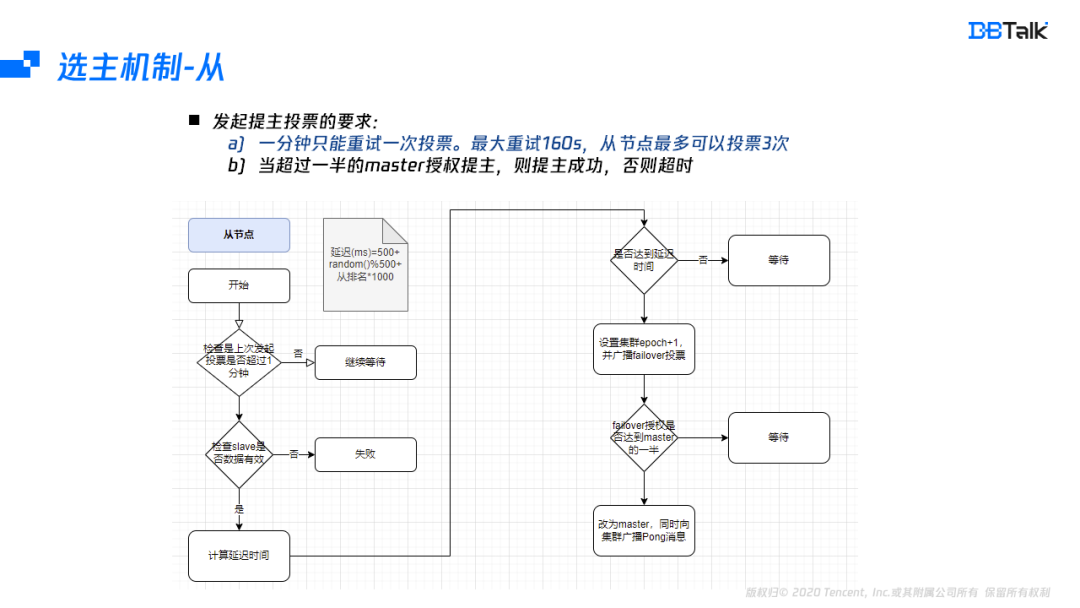
看完主節點的授權機制后,再看下從節點發起投票的機制,發起投票的流程是先核對1分鐘內沒有發起過投票,再核對該節點資料是否有效(不能和主斷開160s),從節點是有效的,就開始計算發起投票的時間,當投票時間到后,將集群的epoch+1,然后再發起failover,如果主節點的授權超過分片數的一半,則自身提為主節點,并廣播節點資訊,這里從節點投票有兩個關鍵的點,一分鐘只能重試一次投票,最大重試160s,從節點最多可以投票3次,當超過一半的master授權提主,提主成功,否則超時,
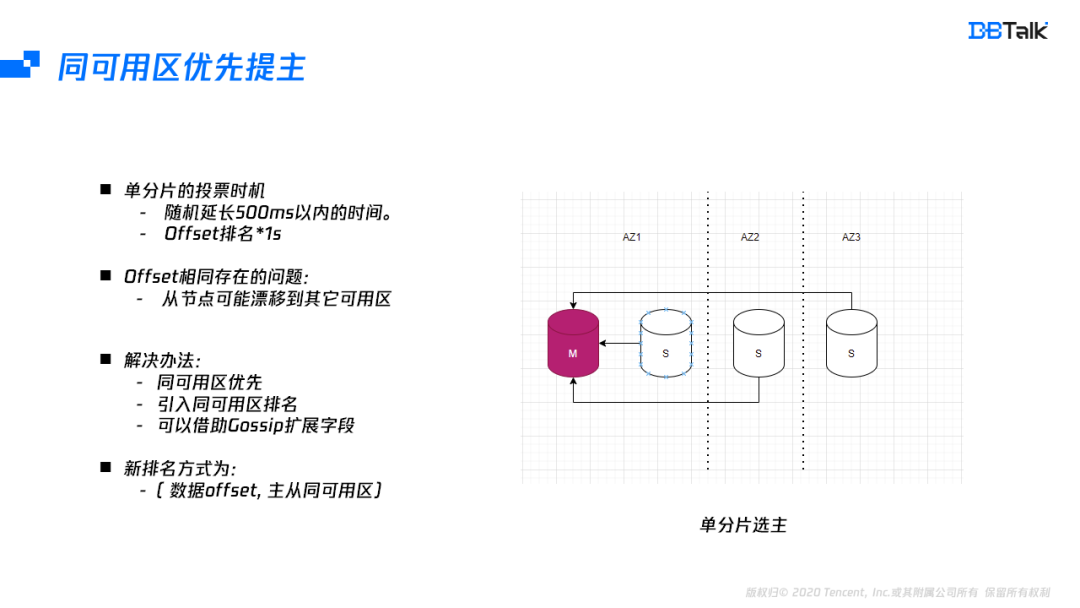
在某一主節點故障后,集群的選主盡量在同可用區中選擇,一個分片不同從節點之間的選主時間由節點的offset排名及的500ms的隨機時間決定,在寫少讀多情況下,offset排名大多時間是相同的,在單可用區場景下,隨機選擇一個節點本身無任何影響,但多可用區就會出現性能的抖動,因此這個就需要在排名中引入同可用區的排名,而同可用區的排名就需要要每個節點都知道所有節點的可用區資訊,在Gossip中剛好有一個預留欄位,我們將可用區資訊存盤在這個預留欄位中,然后將這個節點的可用區資訊會廣播到所有節點中,這樣每個節點都有所有節點的可用區資訊,在投票的時候我們按照offset和可用區資訊排名綜合考慮來保證同可用區優先提主,
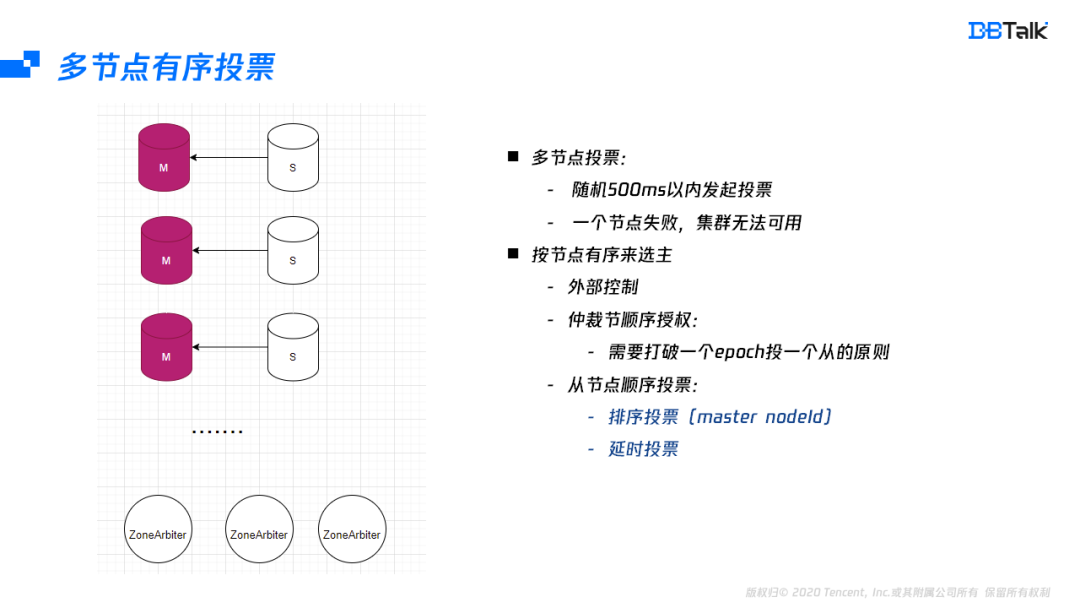
一個節點的選主分析完后,我們來分析下多節點故障的投票時機,多個節點發起投票時,會隨機選擇500毫秒內的一個時間點,然后發起投票,假如集群有100個主節點,500毫秒發起完投票,每個節點投票時間是5毫秒,5毫秒肯定是不夠一個投票周期,在之前的多節點故障投票成功率測驗結果也就證明了這種情況幾乎不能成功,
投票不能成功的關機是集群不同節點投票是隨機發起導致的,既然隨機存在沖突,最直接的解決辦法就是按順序來投票,按順序投票可以簡單分為兩種,一種是依賴外部的控制,引入外部依賴就需要保證它的高可用,一般情況下,存盤鏈路的高可用最好不要依賴外部組件,否則會導致整體的可用性受外部組件加存盤節點的高可用的影響,那再考慮下集群內部實作順序投票,集群內部實作順序投票也有兩種方式,一個是仲裁節點按順序來授權,但是這種方式很容易打破一個epoch投一個從節點的原則,打破后可能會導致投票結果不符合預期,還有一種解決辦法是由從節點來順序發起投票,
從節點要保證順序發起投票,那就需要每個節點的排名是保證相同的,而節點ID在生命周期中是唯一的,且每個節點都有其它節點的ID資訊,因此這里選擇節點ID的排名是比較好的一種方案,每個從節點ID發起投票前,首先核對自己的節點ID是不是第一名,如果是就發起投票,如果不是就等待500ms,這個500ms是為了防止隊頭投票失敗的場景,按這種方式優化后,投票都可以成功,由于本身是分布式的,這里還是存在著小概率失敗,在失敗后就需要外部監控,強行提主,保證集群的盡快恢復,
專家答疑
1.通過sentinel連接redis也會出現雙寫么?
答:雙寫是對存量的連接來說的,如果存量的連接沒有斷開,它會寫入到之前的master節點,而新的連接會寫入到新的master節點,此時就是雙寫,而集群模式出現雙寫最多15s(判死時間),因為15s后發現自身已經脫離大多數,會將節點切換為集群Fail,此時寫入及讀取出錯,而規避了雙寫的問題,
2. 固定節點投票,這幾個節點會不會成為單點
答:單點是不可規避的,比如1主1從,主掛了,那么從提主后,這個節點就是單點,出現單點是需要我們進行補從操作,而這里仲裁節點出現故障,補充一個節點即可,只要保證大多數仲裁節點正常作業即可,由于仲裁和資料訪問是分離的,故障及補節點對資料訪問無任何影響,
3. 整個可用區故障和可用區內節點故障failover的處理策略是什么?
答:不管是整個可用區故障還是單機故障導致的多節點故障,都應該采用順序投票來完成,減少沖突,而如果同可用區有從節點,該節點應該優先提主,
4.想問下寫請求,要同步等從復制完嗎?
答:Redis不是強同步,Redis強同步需要使用wait命令來完成,
5.最大支持多少redis分片呢,節點多了使用gossip有會不會有性能問題?
答:最好不要超過500個,超過500個節點會出現ping導致的性能抖動,此時只能通過調大cluster_node_timeout來降低性能抖動
6.多區主節點,寫同步如何實作?
答:可能想問的是全球多活實體,多活實體一般需要資料先落盤,然后再同步給其它節點,同步的時候要保證從節點先收到資料后,才能發送給多活的其它節點,還需要解決資料同步環路,資料沖突等問題,
7.當前選主邏輯和raft選主有大的區別嗎?
答:相同的點都需要滿足大多數授權,都有一個隨機選擇時間,不同的點Redis是主節點有投票權(針對多分片情況),而raft可認為是所有節點(針對單分片情況),Raft資料寫入要超一半節點成功才回傳成,Redis使用弱同步機制(可以使用wait強勢主從同步完回傳),寫完主節點立即回傳,在主故障后,需要資料越新的節點優先提主(資料偏移值由Gossip通知給其它節點),但不保證它一定成功,
關于作者
劉家文,騰訊云資料庫高級工程師,先后負責Linux內核及redis相關研發作業,目前主要負責騰訊云資料庫Redis的開發和架構設計,對Redis高可用,內核開發有著豐富的經驗,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499156.html
標籤:其它