作為云原生技術先驅,騰訊云資料庫內核團隊致力于不斷提升產品的可用性、可靠性、性能和可擴展性,為用戶提供更加極致的體驗,為幫助用戶了解極致體驗背后的關鍵技術點,本期帶來騰訊云資料庫專家工程師王魯俊給大家分享的騰訊云原生資料庫TDSQL-C的架構探索和實踐,內容主要分為四個部分:
本次分享主要分為四個部分:
第一部分,介紹騰訊云原生資料庫 TDSQL-C 產品架構,包括產品的研發背景和架構主要特性;
第二部分,分享用戶場景實踐,針對線上真實的用戶場景做一些分析和針對性實踐;
第三部分,分享系統關鍵優化;
第四部分,分享產品未來演進,
點擊此處觀看完整視頻
TDSQL-C 產品架構
背景
騰訊云原生資料庫最初采用的是傳統架構,也就是 MySQL 實體,或者說是采用 Binlog 復制的主備方式的架構,但這種架構在現有的一些用戶需求來看是有很多問題的,

比如存盤容量,傳統架構實體的存盤上限受限于本地磁盤上限,一般是幾百 G,或者幾個 T 的量級,做擴展的成本非常高而且麻煩,當用戶資料非常多時,會做分庫分表,使用現有的分庫分表中間件或解決方案會帶來一些分布式事務的問題,
做業務的同學知道,分布式事務處理起來會比較麻煩,涉及如何應對故障,如何應對分布式事務產生的資料不一致等問題,用戶在存盤容量方面的需求是實體容量大于 100T,并且存盤容量能夠快速透明的擴展,
其次是可靠性,傳統架構基于 BinLog 復制,普通的異步或者半同步的復制方式可能會丟資料,同步的復制方式性能損失會比較大,用戶在可靠性方面的需求是第一不能丟資料,即 RPO 等于 0;第二資料是有多副本容災的,也就是要達到一定程度的資料可靠性,
此外還有可用性,可用性對于用戶來講就是服務有多長時間不可用,比如在傳統架構發生一次 HA,或者宕機重啟,這段時間服務都是不可用的,HA、恢復時間慢對用戶來講很難接受,傳統架構 HA 或者副本的恢復速度可能達到了分鐘級,第二個問題是基于 BinLog 復制的時候,主備副本的延遲比較高,有些可能達到分鐘級,甚至達到小時級,用戶希望能夠快速切換 HA,實作秒級恢復,還包括回檔功能,如果有副本,希望副本的延遲能夠比較小,最好是秒級以下,甚至是毫秒級,
最后是可擴展性,傳統架構的擴展性是非常復雜的,基于 Binlog 創建只讀副本也會非常復雜,要先把原始的資料給復制過來,然后搭建主備同步,只讀副本才能開始作業,這個程序至少是分鐘級甚至是小時級別的,對用戶來講,他們希望當讀需求有擴展性需求的時候,可以實作秒級的讀副本擴展,
我們針對這四個方面的用戶需求,采用了存盤計算分離架構,這也是 TDSQL-C 所采納的核心的架構想法,
簡單來說,要解決存盤容量和可靠性方面的問題,第一我們會用云存盤,云存盤之間是可以水平擴展的,理論上它的容量是無限的,而且對于每一份資料都有多副本來保證可靠性,資料分散在云存盤的各個節點上,在這個基礎上可以做持續備份,并行回檔等功能,
在可用性方面,資料放在云存盤上之后,資料的分片是可以做并行恢復的,回檔也可以做并行回檔,物理復制的時延一般會比基于 Binlog 的邏輯復制更低一點,
最后在可擴展性方面,共享存盤的優勢更加明顯,當新建一個只讀副本的時候,資料不需要復制一份出來,因為資料是在云存盤上作為共享資料存在的,只需要把資料共享,另外再構建增量的資料復制就可以了,
架構特性
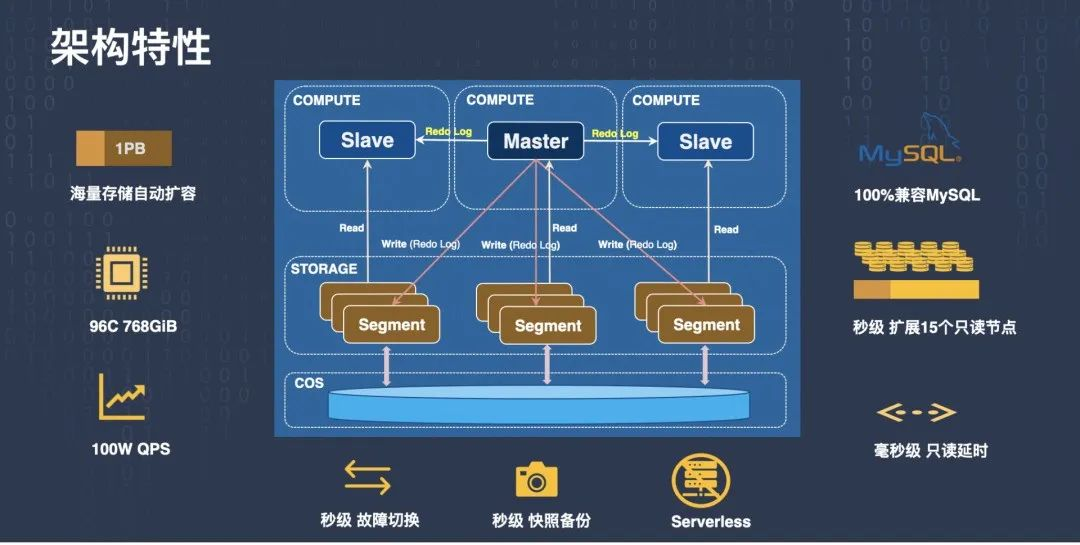
上面這張圖是 TDSQL-C 的整體架構,從這個架構中我們可以看到,它整體上分為上一層的計算層和下一層的存盤層,
計算層有一個讀寫節點,可以提供讀寫請求,還有多個只讀節點,可以提供讀請求,也就是圖里邊的 Master 節點和 Slave 節點,當讀寫請求,尤其是寫請求進來以后,Master 節點也就是讀寫節點產生資料的修改,然后它會把修改產生的 InnoDB 的 Redo Log 下傳到整個存盤層,同時把 Redo Log 分發到自己的 RO 節點,
存盤層負責管理資料,當產生的 Redo 日志發送到存盤層之后,它可以負責 Redo 日志的回放,Segment 把它存盤的頁面對應的 redo 日志 apply 到自己的頁面上來,整個存盤層是架設在 COS 存盤服務上,
TDSQL-C 的存盤可以自動擴容,最大支持超過 1PB 的容量,目前我們的產品最大支持到 96CPU 和 768GiB 的規格,性能方面,只讀大概能跑到一百萬以上 QPS,寫性能也能超過 40 萬 QPS,
基于這種共享存盤的架構,我們可以做到秒級故障切換,包括秒級的快照備份和回檔,并且因為存盤層本身可以做彈性,計算層也可以做彈性,所以可以實作一定程度的 Serverless,
此外,當需要擴展只讀的時候,可以很容易的增加只讀節點,TDSQL-C 現在最多可以掛 15 個只讀節點,并且在讀寫節點和只讀節點之間只有毫秒級的延遲,因為整個工程是基于 MySQL 代碼庫演化過來的,所以是百分之百兼容 MySQL 的,
場景實踐
接下來,我會介紹并分析幾個比較典型的場景實踐,
Serverless
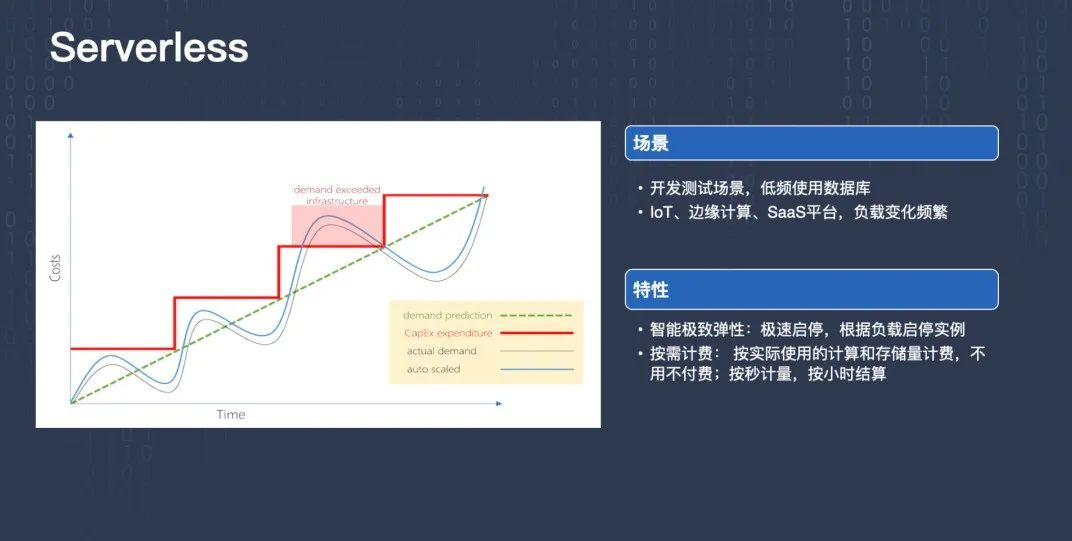
上圖描述的是一些業務預測未來一段時間的資料存盤或者資料計算的需求是持續上漲的,但實際上可能真實的用戶需求是圖中灰色的曲線,為了做好服務,用戶要提前買好服務庫實體,比如圖中紅色的折線,一開始就要準備好這種規格的資料庫實體,
這種情況有一個壞處,實際買的規格都是比真實需求偏大的,這就會造成存盤資源或計算資源的浪費,如果某些時刻有突發的流量進來,突然對存盤或者計算的資源要求非常高,就會出現機器實體資源跟不上、規格太小等情況,這會對業務造成很大的影響,
我們認為理想的情況應該是圖中藍色的曲線,這個曲線的整個資源容量跟真實業務需求的變化規律是一樣的,并且總是比真實的需求稍微多一點,這樣就能真正把資源充分利用起來,而且最大程度上降低成本開銷,
在一些真實的例子里,我們發現有些業務是開發測驗場景,業務真正上線之前,會做一些系統的測驗開發,這個程序對資料庫的需求頻率是非常低的,還有一些像 IoT、邊緣計算、SaaS 平臺,他們的負載變化有非常大的規律性,白天壓力比較大,但是晚上壓力比較小,
TDSQL-C 做到了智能極致的彈性,能夠根據負載來快速啟停實體,第二是按需計費,用了多少花多少,不用不付費,可以做到按秒的計量,按小時的結算,
彈性擴容
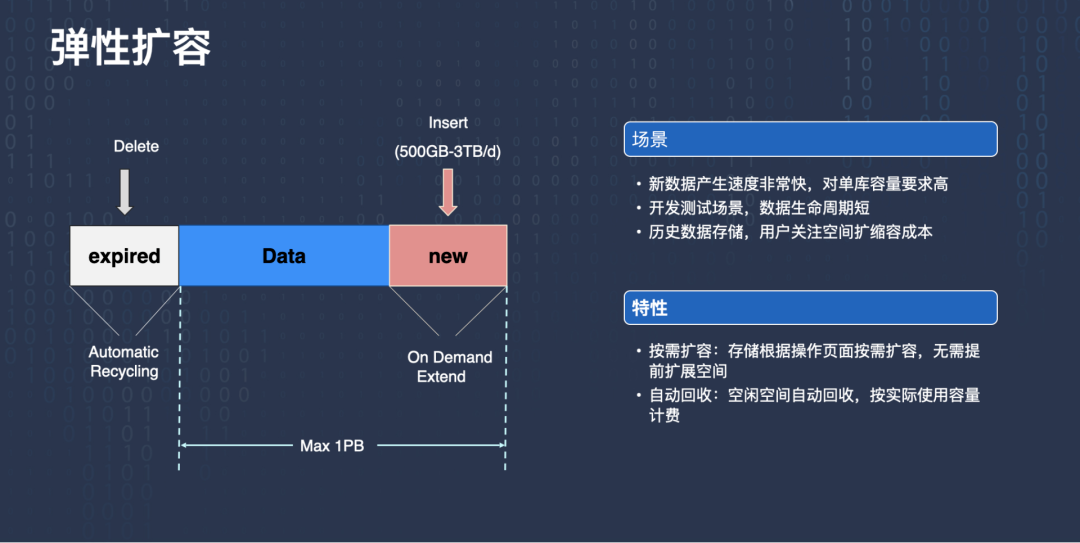
另一個我們在線上業務中發現的實踐需求是彈性擴容,有些業務每天都能產生大量的資料,比如有的業務一天產生幾百 G 的資料,并且這種業務對單庫的容量要求很高,通常都是幾十 T,甚至上百 T 的資料,
有些場景,像開發測驗場景,開發完或者某一次測驗完,資料庫直接就刪掉了,生命周期非常短,另外有些歷史庫場景,歷史資料存盤只是存盤最近一段時間的,特別老的資料直接就洗掉了,洗掉了這些資料希望空間立刻回收,不要再產生存盤成本了,
TDSQL-C 可以做到按需擴容,存盤根據操作頁面按需擴容,如果產生的資料比較多就擴展出來,不需要預先規劃好要做多少存盤,第二點是自動回收,有一些空閑空間,比如資料已經洗掉了,這些資料實際不需要了,但是傳統的 RDS 是邏輯洗掉的,這塊可能還會繼續產生費用,TDSQL-C 可以做到按實際的容量來計費,
備份回檔
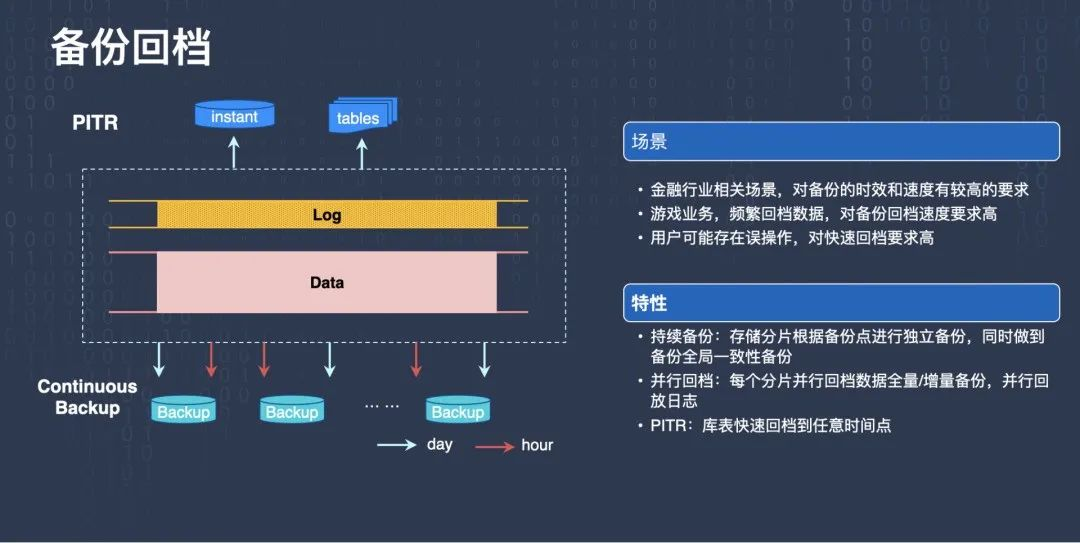
很多場景對備份回檔要求比較高,比如金融行業,因為金融行業對資料安全關注度非常高,他們對備份的速度和備份的時效性都有很高的要求,還有像游戲業務,可能會涉及到頻繁的回檔,所以對備份回檔的速度要求也比較高,
回檔作為“后悔藥”,對很多業務來講都是很重要的一個功能,用戶可能會產生一些誤操作,
TDSQL-C 可以做到持續備份,存盤分片可以根據備份點進行并發的獨立備份,同時可以做到設定全域的一致性備份點來進行備份,此外,TDSQL-C 也可以做到并行回檔,每一個分片并行回檔各自的資料的全量和增量的備份,并行回放自己的日志,還有 PITR,也就是可以快速的恢復到資料庫的任意時間點的資料的狀態,
系統關鍵優化
極速啟停
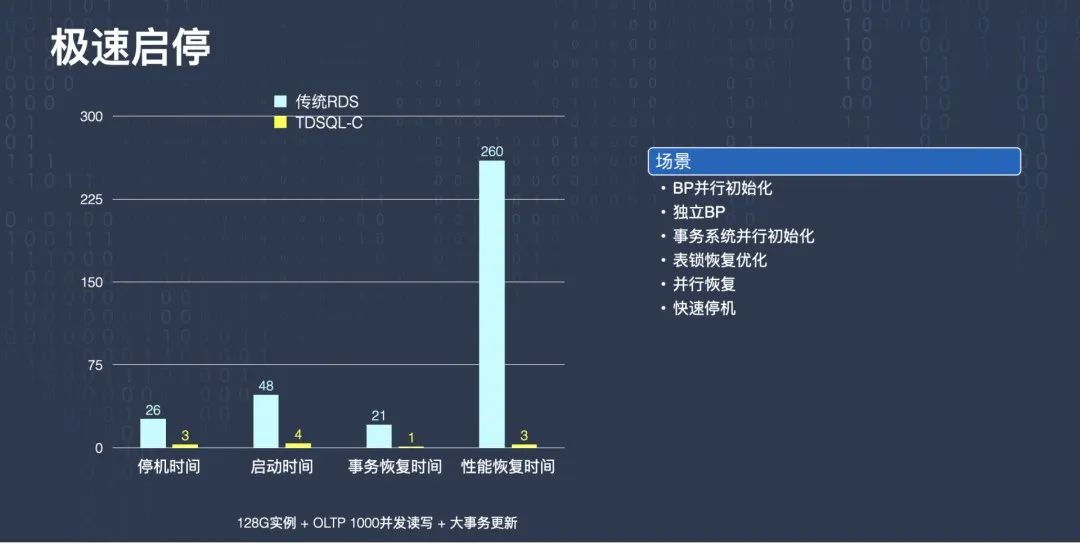
第一個優化就是前面提到的,如何做到極速啟停,也就是支持更好的 Serverless,
這邊有個測驗資料,第一個測驗資料叫停機時間,指的是計劃內的停機時間,即主動停機,TDSQL-C 跟傳統的 RDS 資料庫對比,傳統 RDS 資料庫停機需要 26 秒,TDSQL-C 可以做到 3 秒內停機,
第二個是啟動時間,就是停機之后重新把資料庫實體拉起來,大概需要多少時間能夠恢復起來,RDS 需要 48 秒,TDSQL-C 可以做到 4 秒就啟動起來,
我們分析了一下,這 48 秒有 21 秒是在做事務恢復,也就是第三個柱狀圖,我們對事務系統的并行初始化、表鎖恢復做了一些優化,可以把恢復時間降到一秒,
第四個指標叫性能恢復時間,這個指的是比如重啟之前資料庫的 QPS 大概跑到了 20 萬 QPS,重啟之后大概需要多長時間才能重新恢復到 20 萬 QPS,這對很多業務來說都是很重要的,是恢復質量的問題,傳統 RDS 在有些場景下需要 260 秒才能恢復,但是用 TDSQL-C 3 秒就能恢復了,
這里我們做了一些優化,用的**獨立 BP **的優化方式,Buffer Pool 跟資料庫實體行程是解耦的,由這臺機器上的另外一個行程來負責管理這塊記憶體,當資料庫實體重啟之后,Buffer Pool 是可以繼續用的,這種方式就避免了重啟之后,整個 Buffer Pool 都是冷的,需要很長時間慢慢預熱,省了這個程序,所以恢復時間會非常快,
二級快取
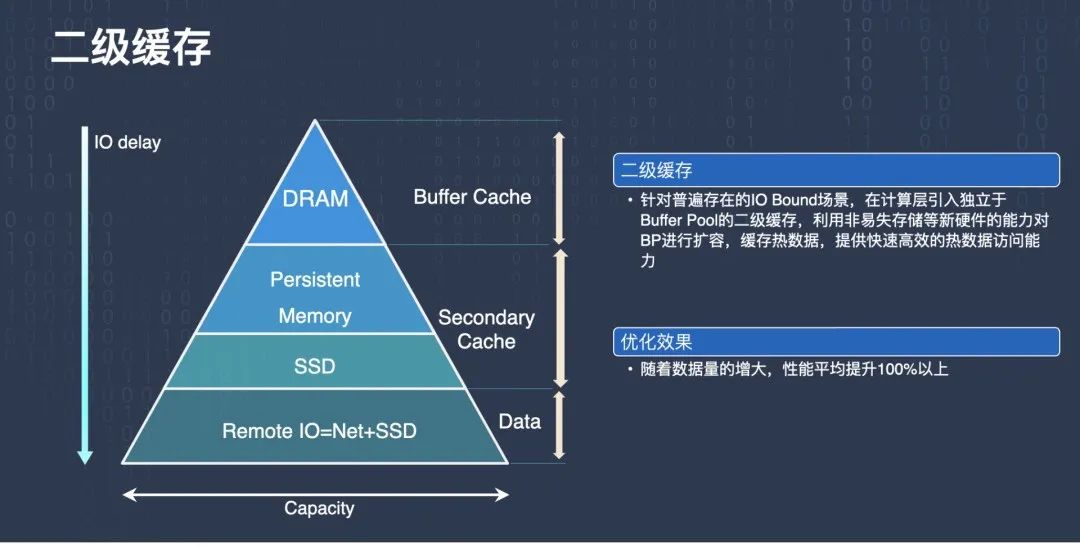
另一個系統關鍵優化是二級快取,二級快取是 TDSQL-C 在存盤計算分離架構下做的比較創新的優化,也是對架構的一個重要補充,
如此前所說,存盤層是可以水平擴展的,這意味著資料量膨脹了很多倍,可能幾十倍、上百倍,資料量多了,但是計算層計算節點的 Buffer cache,也就是 InnoDB 的 Buffer Pool 的容量并沒有太大的變化,這就意味著需要用以前相同大小的 Buffer Pool 來服務更多的資料,
大家知道 InnoDB 的 Buffer Pool 在一定程度上承擔了讀快取的作用,服務更多的資料,意味著讀快取的效率可能會下降,以前一些并不是 IO Bound 的場景,在這種資料量大了的場景下就變成 IO Bound 了,或者以前本來就是 IO Bound 的場景,IO Bound 更嚴重了,這樣對性能影響還是比較大的,
其次,傳統 RDS 的 BufferPool 和本地磁盤空間的存盤中間,是沒有其他硬體存盤設備的,但是在存盤計算分離架構下,Buffer Pool 可能跑得非常快,它的 IO 延遲很低,但資料是存放在遠端的機器上的,我們這邊叫 Remote IO,需要通過網路訪問其他機器的 SSD,在這之間有至少兩個層次的硬體存盤設備,一個是 SSD,就是本機硬碟,另外一塊是 Persistent Memory,就是持久化記憶體,這些是我們可以利用起來的,我們把這一類存盤用作 secondary cache,通過這種方式能夠有效的級訓 IO Bound 場景下 Buffer Pool 命中率低的問題,因為我們可以快取很多的熱資料,能夠加速資料的訪問,
通過測驗可以看到,隨著資料量的增大,整個性能提升還是比較明顯的,在很多場景下性能可以提升到百分之一百以上,達到一倍多,
當然這個問題也有其他的解決方案,有些產品用的是水平擴展 DRAM,類似于我們的 Buffer Pool,就是把 Buffer Pool 放在遠端的機器上,通過更好的 RDMA 來訪問這部分記憶體,而且這個記憶體可能分散在多臺機器上,這種方式也能級訓 IO Bound 場景的一些開銷,
但相對來講,我個人認為使用 Secondary cache 這種方式系統的整體應用成本更低一點,因為畢竟記憶體的成本比 SSD 的成本高的多,尤其是非易失性記憶體,像 3D Xpoint,慢慢流行起來之后,價格是慢慢降低的,用二級快取的方式,整體的實體成本能夠下降非常多,
極致伸縮
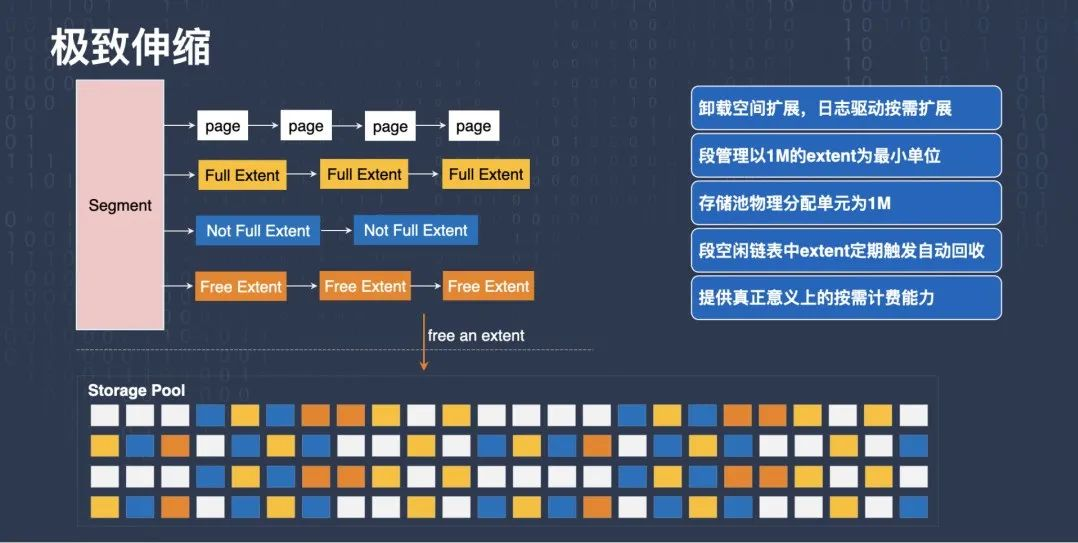
還有一個優化是極致伸縮,我們把存盤功能下放到存盤層之后,存盤層會有存盤池這樣一個概念,
有一些邏輯跟傳統 RDS 方式是類似的,比如段管理還是以 1M 的 extent 為粒度來管理,也有些邏輯有很大的差異,比如我們把存盤空間的擴展,整個 offload 到存盤層,整個空間都池化,當我們發現某個 extent 里面的所有頁面都回收了之后,變成了一個 Free Extent,就可以物理上真正的把它洗掉,而不只是標記為洗掉,通過這種方式真正洗掉之后,客戶的存盤成本就降低下來了,也就是能夠實作按需計費的能力,
極速備份回檔
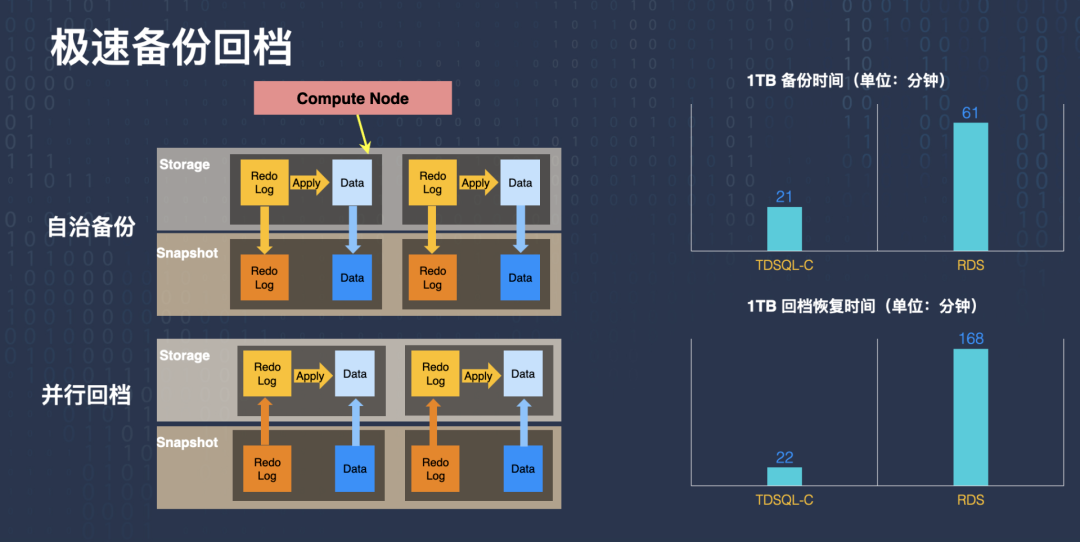
極速備份回檔的實作包含兩部分:備份、回檔,
此前提到,我們的資料是分散到分布式存盤組件上的,分布式存盤包含很多的存盤節點,而且它本身還有一定的計算能力,當實體需要做備份的時候,每個存盤節點都可以獨自的去做備份,我們叫自治備份,它可以持續的做備份,當我們需要全域一致的備份位點時,可以由計算節點來負責協調,通過一些特殊的命令,或者日志來通知所有存盤層的節點基于快照做一個統一的備份,
跟備份相反的一個操作是回檔,基于備份再把實體的資料恢復到某個時間點,回檔也是并行回檔的,每個計算節點都可以獨立的做自己的回放,
針對極速備份回檔的測驗資料看,1TB 的備份時間,RDS 實體需要 61 分鐘,TDSQL-C 只需要 21 分鐘就夠了,1TB 的回檔恢復時間,RDS 需要 168 分鐘之多,但 TDSQL-C 22 分鐘就可以恢復出來,
Instant DDL
還有一些優化是功能性優化,包含 Instant DDL 和并行構建索引,
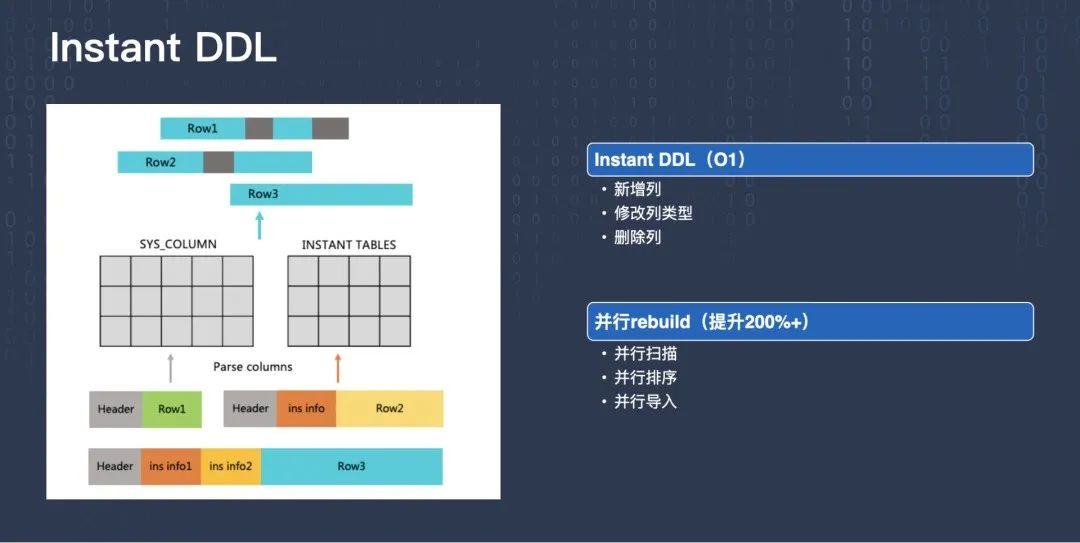
Instant DDL 是 MySQL 8.0 新增的一個功能,它指的是在處理新增列,或修改列型別,或洗掉列 DDL 的時候,可以僅僅修改原資料就直接回傳,
大概的原理是,比如這張表原來有三列,現在需要新增一列,變成四列,只需要在系統表里面標記一下,這張表就從原來的三列變成了四列,之后再新寫入的資料都是按四列寫入的,原來的資料在磁盤上存的是三列的,新插入的資料會打上新格式資料的標記,原來的資料是沒有標記的,當用戶讀取的時候,回傳客戶之前根據標記來決定,如果是舊資料,我們就給它補一個新的列,一般補默認值 default value;如果是新列就直接回傳,通過這種方式就做到了 O(1) 的 DDL,時間非常短,
并行構建索引
接下來介紹下并行構建索引,比如 create index,或者 optimize table 的時候,都會涉及到一些表的重建,
RDS 構建索引的時候,尤其是 8.0 的相對早一點的版本,都是單執行緒構建的,構建程序是先掃描所有的主表資料,掃描之后,根據掃描到的每一行主表資料,再根據索引資訊,生成對應的索引行,這些索引行生成后存盤到臨時檔案里面,
第二步是對這個臨時檔案按照索引行的索引鍵進行排序,一般是 mergesort,完成之后把它匯入到一個空的 Btree 里,這樣就完成了整個索引的構建,我們針對這塊做了并行化優化,掃描主表、外排,還有把資料匯入到 Btree,這三個程序都是可以并行化的,
在第一個階段,我們基于 InnoDB 8.0 的 parallel DDL 做了并行掃描,第二步的 mergesort 我們也做了基于采樣的并行化,通過這種方式來提升并行度,第三步構建 Btree 的時候,也是可以并行化的,比如產生了八萬行的索引行,如果八并發,每一個并發執行緒負責一萬行資料的構建,最后再把形成的八個子 Btree 合并成一個大的 Btree,再去壓縮層高等等,我們測下來很多場景下能提升到兩倍以上,還有很多場景可以提高的更多,
未來演進
第一個我們在探索的演進叫 Global Database,
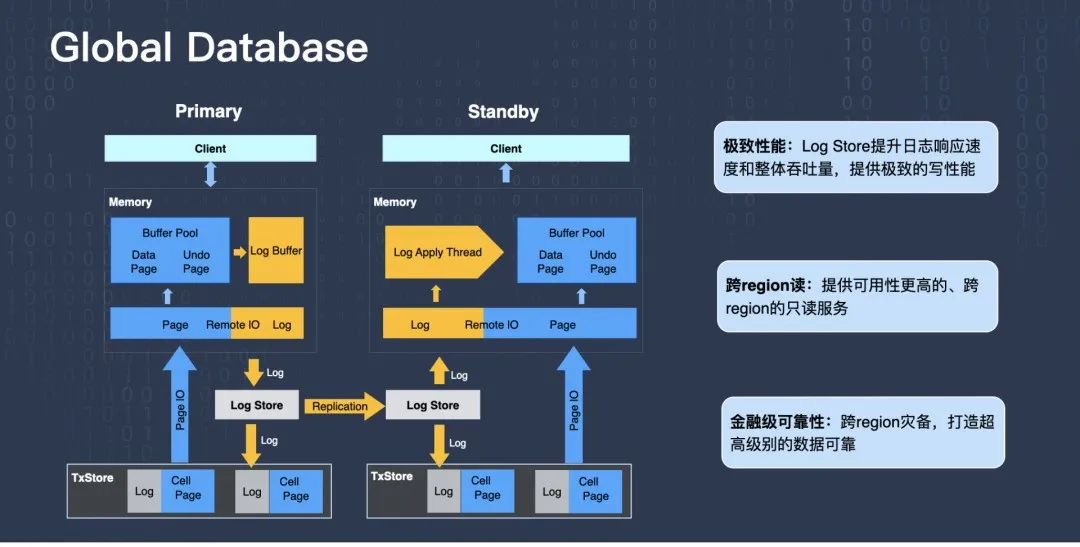
如上圖所示,左邊有一個 Primary 實體,這個實體讀寫節點產生了 Redo log,Redo log 需要分發到存盤層,我們現在新增了 Log Store 模塊,它負責接收和分發日志,通過這種方式,Log Store 一定程度上可以提升日志的回應速度和整體 Redo log 的 IO 吞吐,進一步提升寫性能,
另外一個很重要的點是 Primary 實體跟右側 Standby 實體可以通過各自的 Log Store 來建立資料復制的鏈路,通過這種方式,相當于擴展出了一個只讀節點,實作讀擴展,而且是跨 Region 的讀,因為 Standby 可以部署在另外一個 Region 上,另外我們通過這種方式實作了跨 Region 容災,這對于很多金融業務來講都是剛需,
另一個我們在探索的演進是計算下推,
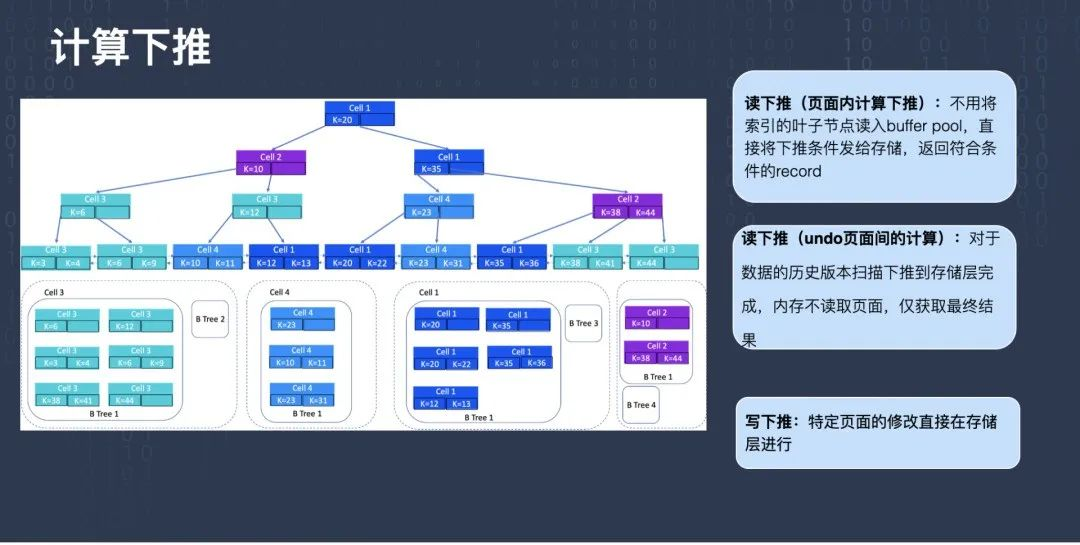
根據我們的架構,存盤和計算是分開的,計算在上面,存盤在下面,存盤不只有存盤能力,還擁有一定的計算能力,像剛才提到的備份恢復,每個節點可以獨立持續的做備份,就是利用存盤層計算能力的一個例子,
除此之外還有很多業務邏輯也可以通過這種方式把存盤層的計算資源利用起來,第一個是頁面內計算下推,比如現在要做一個有條件的掃描,掃描到了某個頁面,這個頁面可能有一百行資料,滿足條件的有五條,可以把條件下推到存盤層,直接放在存盤層做過濾,只把這五條資料回傳給計算層就可以了,這就避免了把這一百行全部讀到計算層,在計算層再做計算,減少了中間網路帶寬的消耗,
第二個是 Undo 頁面間的計算下推,我們 InnoDB 是支持 MVCC 即多版本的,舉個例子,我們現在啟動一個只讀,這個讀事務快照相對比較老,比如讀一小時之前的,當我現在去讀的時候,發現某一行資料太新了,不是我想要的那個資料,需要找到以前的版本,
這個程序在 InnoDB 里面,需要找到這一行對應的 Undo 頁面,把它的前鏡像找出來,要讀的是 Undo 頁面記錄的前鏡像,這個程序如果放在計算節點做,需要把原始的頁面資料加載到計算節點,然后根據讀快照把 Undo 頁面找出來,再把 Undo 頁面應用到資料頁面上,產生一個舊版本的資料,這整個程序都可以在存盤層來做,我們現在也是把這個下沉下來的,
還有一個下推叫寫下推,比如我就改某個頁面 Header 部分的前幾個位元組,或者 Page Header 的某個欄位,這種情況很多是盲寫的,不需要讀出來,直接可以更新,這種情況也是可以下推的,
計算下推在存盤計算分離的架構下是很自然的一個事情,剛才講到了存盤計算分離,它的存盤層帶有一定的計算能力,大量的計算實際上都是可以下沉到存盤層的,哪些計算可以下推并沒有很明顯的邊界,我個人覺得除了事務之外,大部分計算型的都可以下推到存盤層,甚至可以把存盤層的一些計算資源當成純粹的計算資源,不關心它是不是存資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499160.html
標籤:其它
上一篇:反詐困境,國有大行如何破局?