目錄
- 一、對表進行聚合查詢
- 1.1 聚合函式
- 1.2. 計算表中資料的行數
- 1.3 計算 NULL 之外的資料的行數
- 1.4 計算合計值
- 1.5 計算平均值
- 1.6 計算最大值和最小值
- 1.7 使用聚合函式洗掉重復值(關鍵字 DISTINCT)
- 二、對表進行分組
- 2.1 GROUP BY 子句
- 2.2 聚合鍵中包含 NULL 的情況
- 2.3 使用 WHERE 子句時 GROUP BY 的執行結果
- 2.4 與聚合函式和 GROUP BY 子句有關的常見錯誤
- 三、為聚合結果指定條件
- 3.1 HAVING 子句
- 3.2 HAVING 子句的構成要素
- 3.3 相對于 HAVING 子句,更適合寫在 WHERE 子句中的條件
- 四、對查詢結果進行排序
- 4.1 ORDER BY 子句
- 4.2 指定升序或降序
- 4.3 指定多個排序鍵
- 4.4 NULL 的順序
- 4.5 在排序鍵中使用顯示用的別名
- 4.6 ORDER BY 子句中可以使用的列
- 4.7 不要使用列編號
隨著表中記錄(資料行)的不斷積累,存盤資料逐漸增加,有時我們可能希望計算出這些資料的合計值或者平均值等,
本文介紹如何使用 SQL 陳述句對表進行聚合和分組的方法,此外,還介紹在匯總操作時指定條件,以及對匯總結果進行升序、降序的排序方法,
一、對表進行聚合查詢
本節重點
使用聚合函式對表中的列進行計算合計值或者平均值等的匯總操作,
通常,聚合函式會對
NULL以外的物件進行匯總,但是只有COUNT函式例外,使用COUNT(*)可以查出包含NULL在內的全部資料的行數,使用
DISTINCT關鍵字洗掉重復值,
1.1 聚合函式
通過 SQL 對資料進行某種操作或計算時需要使用函式,例如,計算表中全部資料的行數時,可以使用 COUNT 函式,該函式就是使用 COUNT(計數)來命名的,
除此之外,SQL 中還有很多其他用于匯總的函式,請大家先記住以下 5 個常用的函式,
-
COUNT:計算表中的記錄數(行數) -
SUM:計算表中數值列中資料的合計值 -
AVG:計算表中數值列中資料的平均值 -
MAX:求出表中任意列中資料的最大值 -
MIN:求出表中任意列中資料的最小值
如上所示,用于匯總的函式稱為聚合函式或者聚集函式,本文中統稱為聚合函式,所謂聚合,就是將多行匯總為一行,實際上,所有的聚合函式都是這樣,輸入多行輸出一行,
接下來,本文將繼續使用在 SQL 如何對表進行創建、更新和洗掉操作 中創建的 Product 表(圖 1)來學習聚合函式的使用方法,
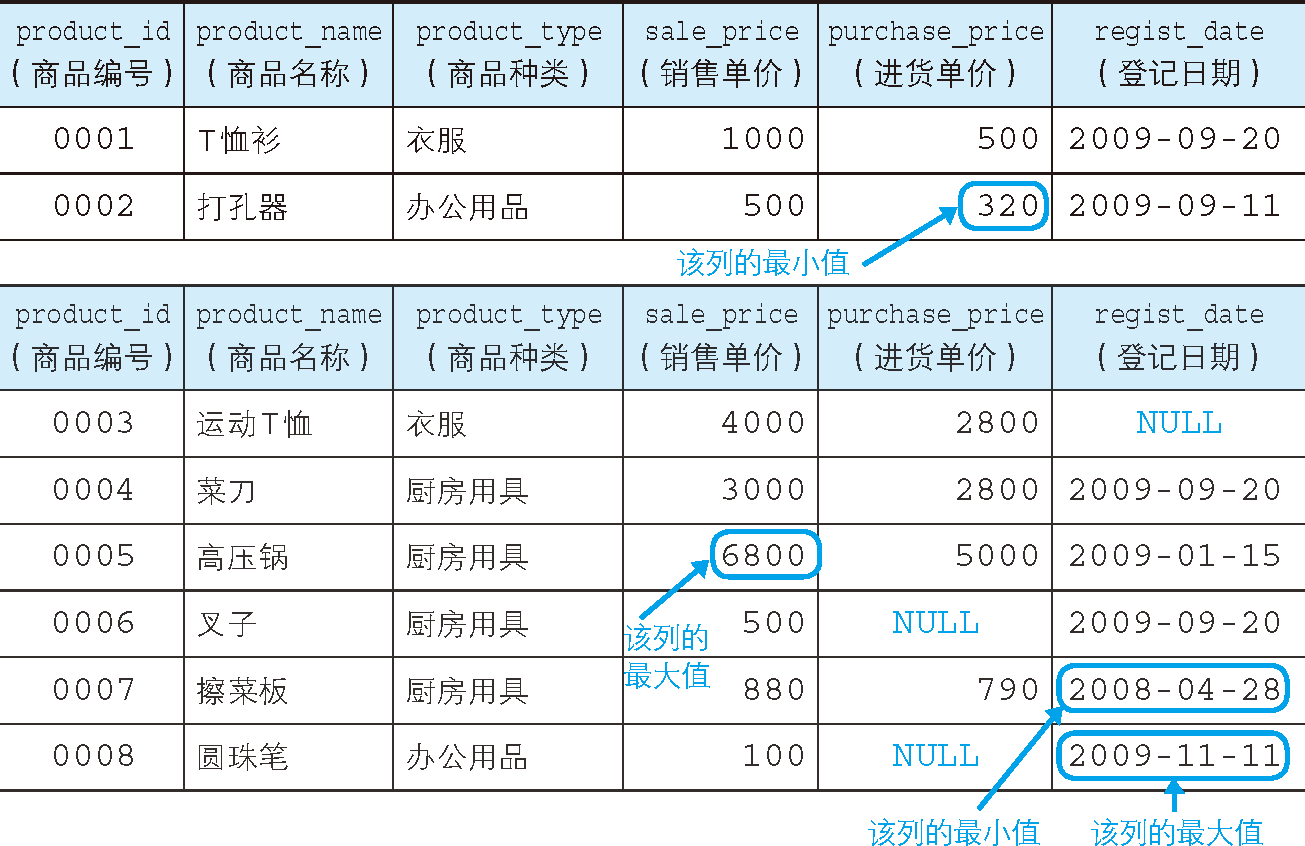
圖 1 Product 表的內容
1.2. 計算表中資料的行數
首先,我們以 COUNT 函式為例讓大家對函式形成一個初步印象,函式這個詞,與我們在學校數學課上學到的意思是一樣的,就像是輸入某個值就能輸出相應結果的盒子一樣 [1],
使用 COUNT 函式時,輸入表的列,就能夠輸出資料行數,如圖 2 所示,將表中的列放入名稱為 COUNT 的盒子中,咔嗒咔嗒地進行計算,咕咚一下行數就出來了……就像自動售歡訓那樣,很容易理解吧,
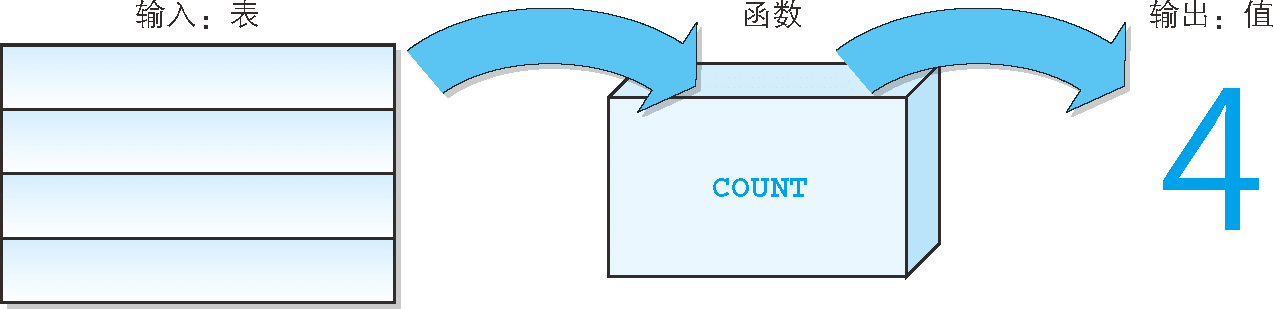
圖 2 COUNT 函式的操作演示圖
接下來讓我們看一下 SQL 中的具體書寫方法,COUNT 函式的語法本身非常簡單,像代碼清單 1 那樣寫在 SELECT 子句中就可以得到表中全部資料的行數了,
代碼清單 1 計算全部資料的行數

執行結果:

COUNT() 中的星號,我們在 SQL SELECT WHERE 陳述句如何指定一個或多個查詢條件 中已經介紹過,代表全部列的意思,COUNT 函式的輸入值就記述在其后的括號中,
此處的輸入值稱為引數或者 parameter,輸出值稱為回傳值,這些稱謂不僅本文中會使用,在多數編程語言中使用函式時都會頻繁出現,請大家牢記,
1.3 計算 NULL 之外的資料的行數
想要計算表中全部資料的行數時,可以像 SELECT COUNT(*) 這樣使用星號,
如果想得到 purchase_price 列(進貨單價)中非空行數的話,可以像代碼清單 2 那樣,通過將物件列設定為引數來實作,
代碼清單 2 計算 NULL 之外的資料行數
SELECT COUNT(purchase_price)
FROM Product;
執行結果:
count
-------
6
此時,如圖 1 所示,purchase_price 列中有兩行資料是 NULL,因此并不應該計算這兩行,對于 COUNT 函式來說,引數列不同計算的結果也會發生變化,這一點請大家特別注意,
為了有助于大家理解,請看如下這個只包含 NULL 的表的極端例子,

圖 3 只包含 NULL 的表
我們來看一下針對上述表,將星號(*)和列名作為引數傳遞給 COUNT 函式時所得到的結果(代碼清單 3),
代碼清單 3 將包含 NULL 的列作為引數時,COUNT(*) 和 COUNT(<列名>) 的結果并不相同
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
執行結果:

如上所示,即使對同一個表使用 COUNT 函式,輸入的引數不同得到的結果也會不同,由于將列名作為引數時會得到 NULL 之外的資料行數,所以得到的結果是 0 行,
該特性是 COUNT 函式所特有的,其他函式并不能將星號作為引數(如果使用星號會出錯),
法則 1
COUNT函式的結果根據引數的不同而不同,COUNT(*)會得到包含NULL的資料行數,而COUNT(<列名>)會得到NULL之外的資料行數,
1.4 計算合計值
接下來我們學習其他 4 個聚合函式的使用方法,這些函式的語法基本上與 COUNT 函式相同,但就像我們此前所說的那樣,在這些函式中不能使用星號作為引數,
首先,我們使用計算合計值的 SUM 函式,求出銷售單價的合計值(代碼清單 4),
代碼清單 4 計算銷售單價的合計值
SELECT SUM(sale_price)
FROM Product;
執行結果:
sum
------
16780
得到的結果 16780 元,是所有銷售單價(sale_price 列)的合計,與下述計算式的結果相同,

接下來,我們將銷售單價和進貨單價(purchase_price 列)的合計值一起計算出來(代碼清單 5),
代碼清單 5 計算銷售單價和進貨單價的合計值
SELECT SUM(sale_price), SUM(purchase_price)
FROM Product;
執行結果:

這次我們通過 SUM(purchase_price) 將進貨單價的合計值也一起計算出來了,但有一點需要大家注意,具體的計算程序如下所示,

大家都已經注意到了吧,與銷售單價不同,進貨單價中有兩條不明資料 NULL,對于 SUM 函式來說,即使包含 NULL,也可以計算出合計值,
還記得 SQL SELECT WHERE 陳述句如何指定一個或多個查詢條件 內容的讀者可能會產生如下疑問,
“四則運算中如果存在 NULL,結果一定是 NULL,那此時進貨單價的合計值會不會也是 NULL 呢?”
有這樣疑問的讀者思維很敏銳,但實際上這兩者并不矛盾,從結果上說,所有的聚合函式,如果以列名為引數,那么在計算之前就已經把 NULL 排除在外了,
因此,無論有多少個 NULL 都會被無視,這與“等價為 0”并不相同 [2],
因此,上述進貨單價的計算運算式,實際上應該如下所示,

法則 2
聚合函式會將
NULL排除在外,但COUNT(*)例外,并不會排除NULL,
1.5 計算平均值
接下來,我們練習一下計算多行資料的平均值,為此,我們需要使用 AVG 函式,其語法和 SUM 函式完全相同(代碼清單 6),
代碼清單 6 計算銷售單價的平均值
SELECT AVG(sale_price)
FROM Product;
執行結果:
avg
----------------------
2097.5000000000000000
平均值的計算式如下所示,
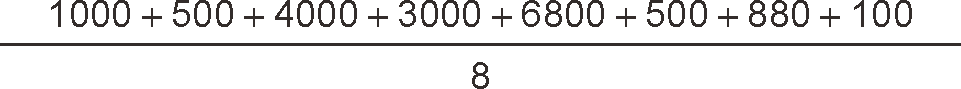
(值的合計)/(值的個數) 就是平均值的計算公式了,下面我們也像使用 SUM 函式那樣,計算一下包含 NULL 的進貨單價的平均值(代碼清單 7),
代碼清單 7 計算銷售單價和進貨單價的平均值
SELECT AVG(sale_price), AVG(purchase_price)
FROM Product;
執行結果:

計算進貨單價平均值的情況與 SUM 函式相同,會事先洗掉 NULL 再進行計算,因此計算式如下所示,
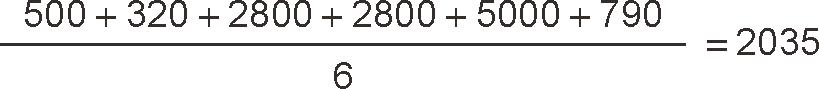
需要注意的是分母是 6 而不是 8,減少的兩個也就是那兩條 NULL 的資料,
但是有時也想將 NULL 作為 0 進行計算,具體的實作方式請參考 SQL 常用的函式,
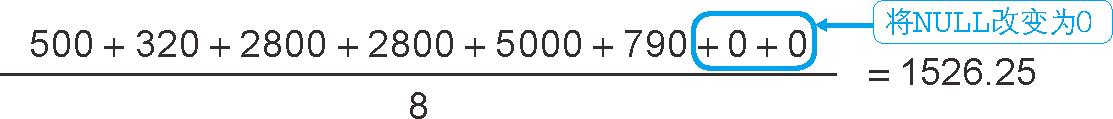
1.6 計算最大值和最小值
想要計算出多條記錄中的最大值或最小值,可以分別使用 MAX 和 MIN 函式,它們是英語 maximam(最大值)和 minimum(最小值)的縮寫,很容易記住,
這兩個函式的語法與 SUM 的語法相同,使用時需要將列作為引數(代碼清單 8),
代碼清單 8 計算銷售單價的最大值和進貨單價的最小值
SELECT MAX(sale_price), MIN(purchase_price)
FROM Product;
執行結果:

如圖 1 所示,我們取得了相應的最大值和最小值,
但是,MAX/MIN 函式和 SUM/AVG 函式有一點不同,那就是 SUM/AVG 函式只能對數值型別的列使用,而 MAX/MIN 函式原則上可以適用于任何資料型別的列,
例如,對圖 1 中日期型別的列 regist_date 使用 MAX/MIN 函式進行計算的結果如下所示(代碼清單 9),
代碼清單 9 計算登記日期的最大值和最小值
SELECT MAX(regist_date), MIN(regist_date)
FROM Product;
執行結果:

剛剛我們說過 MAX/MIN 函式適用于任何資料型別的列,也就是說,只要是能夠排序的資料,就肯定有最大值和最小值,也就能夠使用這兩個函式,
對日期來說,平均值和合計值并沒有什么實際意義,因此不能使用 SUM/AVG 函式,
這點對于字串型別的資料也適用,字串型別的資料能夠使用 MAX/MIN 函式,但不能使用 SUM/AVG 函式,
法則 3
MAX/MIN函式幾乎適用于所有資料型別的列,SUM/AVG函式只適用于數值型別的列,
1.7 使用聚合函式洗掉重復值(關鍵字 DISTINCT)
接下來我們考慮一下下面這種情況,
在圖 1 中我們可以看到,商品種類(product_type 列)和銷售單價(sale_price 列)的資料中,存在多行資料相同的情況,
例如,拿商品種類來說,表中總共有 3 種商品共 8 行資料,其中衣服 2 行,辦公用品 2 行,廚房用具 4 行,
如果想要計算出商品種類的個數,怎么做比較好呢?洗掉重復資料然后再計算資料行數似乎是個不錯的辦法,
實際上,在使用 COUNT 函式時,將 SQL 如何對表進行創建、更新和洗掉操作 中介紹過的 DISTINCT 關鍵字作為引數,就能得到我們想要的結果了(代碼清單 10),
代碼清單 10 計算去除重復資料后的資料行數
SELECT COUNT(DISTINCT product_type)
FROM Product;
執行結果:
count
-------
3
請注意,這時 DISTINCT 必須寫在括號中,這是因為必須要在計算行數之前洗掉 product_type 列中的重復資料,
如果像代碼清單 11 那樣寫在括號外的話,就會先計算出資料行數,然后再洗掉重復資料,結果就得到了 product_type 列的所有行數(也就是 8),
代碼清單 11 先計算資料行數再洗掉重復資料的結果
SELECT DISTINCT COUNT(product_type)
FROM Product;
執行結果:
count
-------
8
法則 4
想要計算值的種類時,可以在
COUNT函式的引數中使用DISTINCT,
不僅限于 COUNT 函式,所有的聚合函式都可以使用 DISTINCT,
下面我們來看一下使用 DISTINCT 和不使用 DISTINCT 時 SUM 函式的執行結果(代碼清單 12),
代碼清單 12 使不使用 DISTINCT 時的動作差異(SUM 函式)
SELECT SUM(sale_price), SUM(DISTINCT sale_price)
FROM Product;
執行結果:

左側是未使用 DISTINCT 時的合計值,和我們之前計算的結果相同,都是 16780 元,
右側是使用 DISTINCT 后的合計值,比之前的結果少了 500 元,
這是因為表中銷售單價為 500 元的商品有兩種——“打孔器”和“叉子”,在洗掉重復資料之后,計算物件就只剩下一條記錄了,
法則 5
在聚合函式的引數中使用
DISTINCT,可以洗掉重復資料,
二、對表進行分組
本節重點
使用
GROUP BY子句可以像切蛋糕那樣將表分割,通過使用聚合函式和GROUP BY子句,可以根據“商品種類”或者“登記日期”等將表分割后再進行匯總,聚合鍵中包含
NULL時,在結果中會以“不確定”行(空行)的形式表現出來,使用聚合函式和
GROUP BY子句時需要注意以下 4 點,
只能寫在
SELECT子句之中
GROUP BY子句中不能使用SELECT子句中列的別名
GROUP BY子句的聚合結果是無序的
WHERE子句中不能使用聚合函式
2.1 GROUP BY 子句
目前為止,我們看到的聚合函式的使用方法,無論是否包含 NULL,無論是否洗掉重復資料,都是針對表中的所有資料進行的匯總處理,
下面,我們先把表分成幾組,然后再進行匯總處理,也就是按照“商品種類”“登記日期”等進行匯總,
這里我們將要第一次接觸到 GROUP BY 子句,其語法結構如下所示,
語法 1 使用 GROUP BY 子句進行匯總
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……;
下面我們就按照商品種類來統計一下資料行數(= 商品數量)(代碼清單 13),
代碼清單 13 按照商品種類統計資料行數
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
執行結果:
product_type | count
--------------+------
衣服 | 2
辦公用品 | 2
廚房用具 | 4
如上所示,未使用 GROUP BY 子句時,結果只有 1 行,而這次的結果卻是多行,這是因為不使用 GROUP BY 子句時,是將表中的所有資料作為一組來對待的,
而使用 GROUP BY 子句時,會將表中的資料分為多個組進行處理,如圖 4 所示,GROUP BY 子句對表進行了切分,
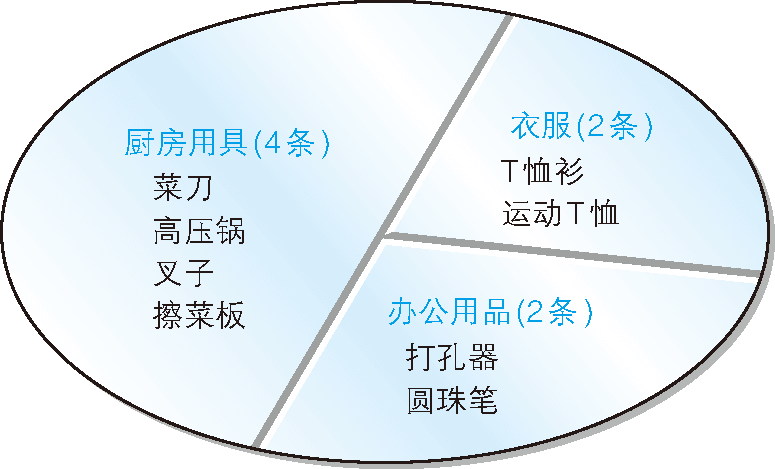
圖 4 按照商品種類對表進行切分
這樣,GROUP BY 子句就像切蛋糕那樣將表進行了分組,在 GROUP BY 子句中指定的列稱為聚合鍵或者分組列,由于能夠決定表的切分方式,所以是非常重要的列,
當然,GROUP BY 子句也和 SELECT 子句一樣,可以通過逗號分隔指定多列,
如果用畫線的方式來切分表中資料的話,就會得到圖 5 那樣以商品種類為界線的三組資料,然后再計算每種商品的資料行數,就能得到相應的結果了,
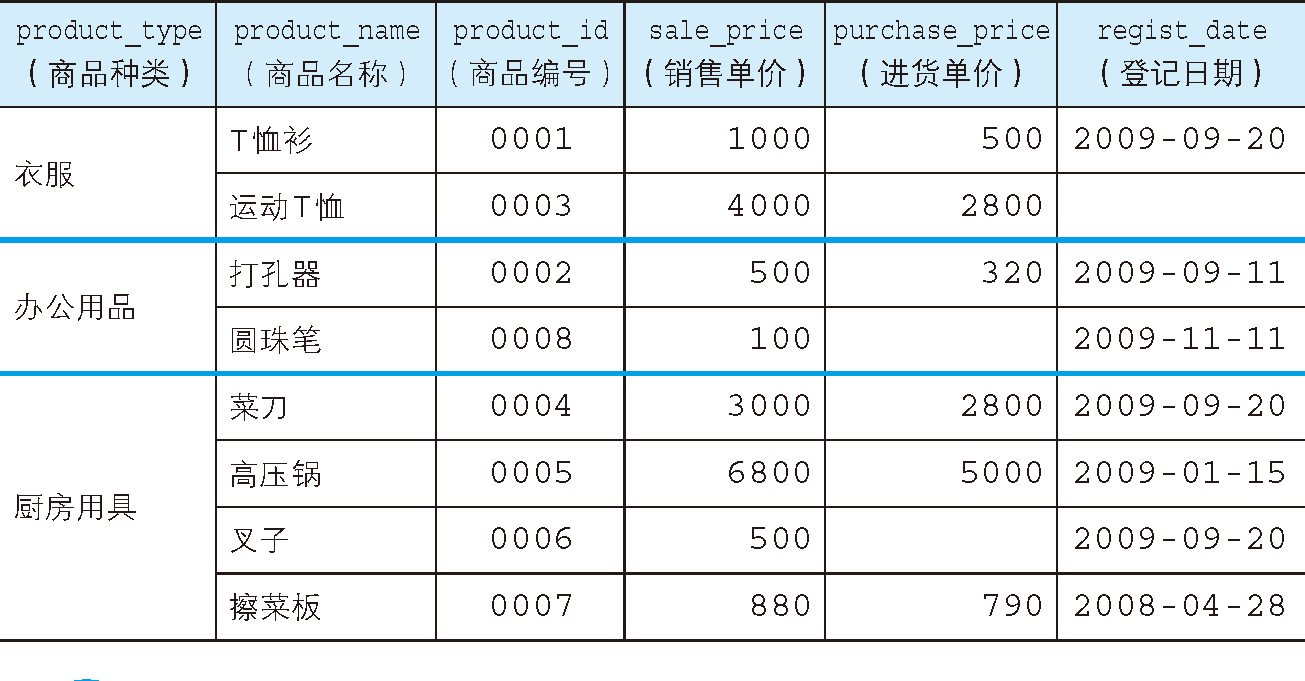
圖 5 按照商品種類對表進行切分
法則 6
GROUP BY就像是切分表的一把刀,
此外,GROUP BY 子句的書寫位置也有嚴格要求,一定要寫在 FROM 陳述句之后(如果有 WHERE 子句的話需要寫在 WHERE 子句之后),
如果無視子句的書寫順序,SQL 就一定會無法正常執行而出錯,目前 SQL 的子句還沒有全部登場,已經出現的各子句的暫定順序如下所示,
子句的書寫順序(暫定)
1. SELECT → 2. FROM → 3. WHERE → 4. GROUP BY
法則 7
SQL 子句的順序不能改變,也不能互相替換,
2.2 聚合鍵中包含 NULL 的情況
接下來我們將進貨單價(purchase_price)作為聚合鍵對表進行切分,在 GROUP BY 子句中指定進貨單價的結果請參見代碼清單 14,
代碼清單 14 按照進貨單價統計資料行數
SELECT purchase_price, COUNT(*)
FROM Product
GROUP BY purchase_price;
上述 SELECT 陳述句的結果如下所示:

像 790 元或者 500 元這樣進貨單價很清楚的資料行不會有什么問題,結果與之前的情況相同,
問題是結果中的第一行,也就是進貨單價為 NULL 的組,
從結果我們可以看出,當聚合鍵中包含 NULL 時,也會將 NULL 作為一組特定的資料,如圖 6 所示,
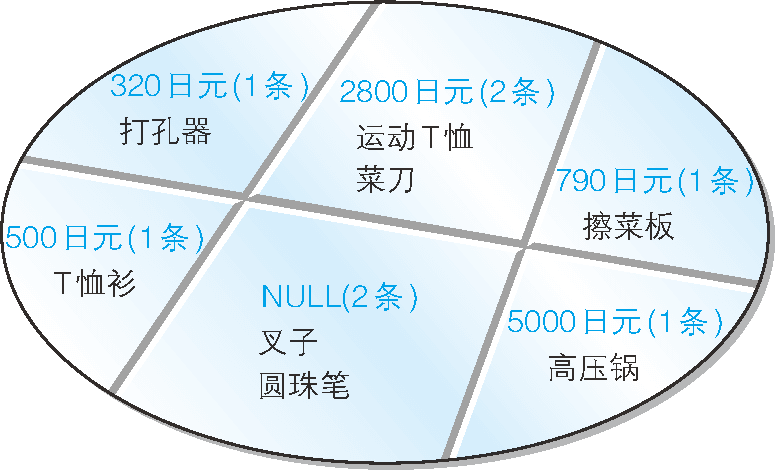
圖 6 按照進貨單價對表進行切分
這里的 NULL,大家可以理解為“不確定”,
法則 8
聚合鍵中包含
NULL時,在結果中會以“不確定”行(空行)的形式表現出來,
2.3 使用 WHERE 子句時 GROUP BY 的執行結果
在使用了 GROUP BY 子句的 SELECT 陳述句中,也可以正常使用 WHERE 子句,子句的排列順序如前所述,語法結果如下所示,
語法 2 使用 WHERE 子句和 GROUP BY 子句進行匯總處理
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
WHERE
GROUP BY <列名1>, <列名2>, <列名3>, ……;
像這樣使用 WHERE 子句進行匯總處理時,會先根據 WHERE 子句指定的條件進行過濾,然后再進行匯總處理,請看代碼清單 15,
代碼清單 15 同時使用 WHERE 子句和 GROUP BY 子句
SELECT purchase_price, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY purchase_price;
因為上述 SELECT 陳述句首先使用了 WHERE 子句對記錄進行過濾,所以實際上作為聚合物件的記錄只有 2 行,如表 1 所示,
表 1 WHERE 子句過濾的結果
| product_type(商品種類) | product_name(商品名稱) | product_id(商品編號) | sale_price(銷售單價) | purchase_price(進貨單價) | regist_date(登記日期) |
|---|---|---|---|---|---|
| 衣服 | T 恤衫 | 0001 | 1000 | 500 | 2009-09-20 |
| 衣服 | 運動 T 恤 | 0003 | 4000 | 2800 |
使用進貨單價對這 2 條記錄進行分組,就得到了如下的執行結果:
purchase_price | count
----------------+------
500 | 1
2800 | 1
GROUP BY 和 WHERE 并用時,SELECT 陳述句的執行順序如下所示,
GROUP BY 和 WHERE 并用時 SELECT 陳述句的執行順序
FROM → WHERE → GROUP BY → SELECT
這與之前語法 2 中的說明順序有些不同,這是由于在 SQL 陳述句中,書寫順序和 DBMS 內部的執行順序并不相同,這也是 SQL 難以理解的原因之一,
2.4 與聚合函式和 GROUP BY 子句有關的常見錯誤
截至目前,我們已經介紹了聚合函式和 GROUP BY 子句的基本使用方法,雖然由于使用方便而經常被使用,但是書寫 SQL 時卻很容易出錯,希望大家特別小心,
-
常見錯誤 ① ——在 SELECT 子句中書寫了多余的列
在使用
COUNT這樣的聚合函式時,SELECT子句中的元素有嚴格的限制,實際上,使用聚合函式時,SELECT子句中只能存在以下三種元素,-
常數
-
聚合函式
-
GROUP BY子句中指定的列名(也就是聚合鍵)
在 資料庫和 SQL 是什么關系 中我們介紹過,常數就是像數字
123,或者字串'測驗'這樣寫在 SQL 陳述句中的固定值,將常數直接寫在SELECT子句中沒有任何問題,此外還可以書寫聚合函式或者聚合鍵,這些在之前的示例代碼中都已經出現過了,
這里經常會出現的錯誤就是把聚合鍵之外的列名書寫在
SELECT子句之中,例如代碼清單 16 中的SELECT陳述句就會發生錯誤,無法正常執行,代碼清單 16 在 SELECT 子句中書寫聚合鍵之外的列名會發生錯誤
SELECT product_name, purchase_price, COUNT(*) FROM Product GROUP BY purchase_price;執行結果(使用 PostgreSQL 的情況):
ERROR:列"product,product_name"必須包含在GROUP BY子句之中,或者必須在聚合函式內使用 行 1: SELECT product_name, purchase_price, COUNT(*)列名
product_name并沒有包含在GROUP BY子句當中,因此,該列名也不能書寫在SELECT子句之中 [3],不支持這種語法的原因,大家仔細想一想應該就明白了,通過某個聚合鍵將表分組之后,結果中的一行資料就代表一組,
例如,使用進貨單價將表進行分組之后,一行就代表了一個進貨單價,問題就出在這里,聚合鍵和商品名并不一定是一對一的,
例如,進貨單價是
2800元的商品有“運動 T 恤”和“菜刀”兩種,但是2800元這一行應該對應哪個商品名呢(圖 7)?如果規定了哪種商品優先表示的話則另當別論,但其實并沒有這樣的規則,
-
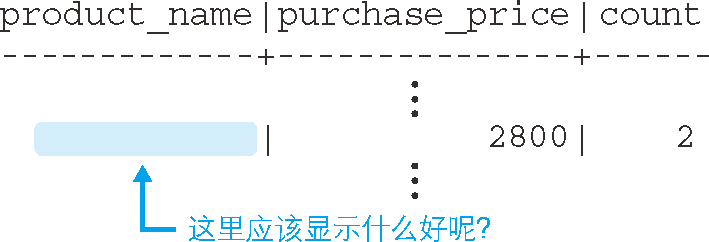
圖 7 聚合鍵和商品名不是一對一的情況
像這樣與聚合鍵相對應的、同時存在多個值的列出現在 SELECT 子句中的情況,理論上是不可能的,
法則 9
使用
GROUP BY子句時,SELECT子句中不能出現聚合鍵之外的列名,
-
常見錯誤 ② ——在 GROUP BY 子句中寫了列的別名
這也是一個非常常見的錯誤,在 為列設定別名 中我們學過,
SELECT子句中的專案可以通過AS關鍵字來指定別名,但是,在
GROUP BY子句中是不能使用別名的,代碼清單 17 中的SELECT陳述句會發生錯誤 [4],代碼清單 17 GROUP BY 子句中使用列的別名會引發錯誤

上述陳述句發生錯誤的原因之前已經介紹過了,是 SQL 陳述句在 DBMS 內部的執行順序造成的——
SELECT子句在GROUP BY子句之后執行,在執行
GROUP BY子句時,SELECT子句中定義的別名,DBMS 還并不知道,使用 PostgreSQL 執行上述 SQL 陳述句并不會發生錯誤,而會得到如下結果,但是這樣的寫法在其他 DBMS 中并不是通用的,因此請大家不要使用,
執行結果(使用 PostgreSQL 的情況):
pt | count -------------+------ 衣服 | 2 辦公用品 | 2 廚房用具 | 4法則 10
在
GROUP BY子句中不能使用SELECT子句中定義的別名, -
常見錯誤 ③ —— GROUP BY 子句的結果能排序嗎
GROUP BY子句的結果通常都包含多行,有時可能還會是成百上千行,那么,這些結果究竟是按照什么順序排列的呢?答案是:“隨機的,”
我們完全不知道結果記錄是按照什么規則進行排序的,可能乍一看是按照行數的降序或者聚合鍵的升序進行排列的,但其實這些全都是偶然的,
當你再次執行同樣的
SELECT陳述句時,得到的結果可能會按照完全不同的順序進行排列,通常
SELECT陳述句的執行結果的顯示順序都是隨機的,因此想要按照某種特定順序進行排序的話,需要在SELECT陳述句中進行指定,具體的方法將在本文第 4 節中學習,法則 11
GROUP BY子句結果的顯示是無序的, -
常見錯誤 ④ ——在 WHERE 子句中使用聚合函式
最后要介紹的是初學者非常容易犯的一個錯誤,
我們還是先來看一下之前提到的按照商品種類(
product_type列)對表進行分組,計算每種商品資料行數的例子吧,SELECT陳述句如代碼清單 18 所示,代碼清單 18 按照商品種類統計資料行數
SELECT product_type, COUNT(*) FROM Product GROUP BY product_type;執行結果:
product_type | count --------------+------- 衣服 | 2 辦公用品 | 2 廚房用具 | 4如果我們想要取出恰好包含 2 行資料的組該怎么辦呢?滿足要求的是“辦公用品”和“衣服”,
想要指定選擇條件時就要用到
WHERE子句,初學者通常會想到使用代碼清單 19 中的SELECT陳述句吧,代碼清單 19 在 WHERE 子句中使用聚合函式會引發錯誤
SELECT product_type, COUNT(*) FROM Product WHERE COUNT(*) = 2 GROUP BY product_type;遺憾的是,這樣的
SELECT陳述句在執行時會發生錯誤,執行結果(使用 PostgreSQL 的情況):
ERROR: 不能在WHERE子句中使用聚合 行 3: WHERE COUNT(*) = 2 ^實際上,只有
SELECT子句和HAVING子句(以及之后將要學到的ORDER BY子句)中能夠使用COUNT等聚合函式,并且,
HAVING子句可以非常方便地實作上述要求,下一節我們將會學習HAVING子句,法則 12
只有
SELECT子句和HAVING子句(以及ORDER BY子句)中能夠使用聚合函式,
專欄
DISTINCT 和 GROUP BY
細心的讀者可能會發現,第 1 節中介紹的
DISTINCT和第 2 節介紹的GROUP BY子句,都能夠洗掉后續列中的重復資料,例如,代碼清單 A 中的 2 條
SELECT陳述句會回傳相同的結果,代碼清單 A DISTINCT 和 GROUP BY 能夠實作相同的功能
SELECT DISTINCT product_type FROM Product; SELECT product_type FROM Product GROUP BY product_type;執行結果:
product_type -------------- 衣服 辦公用品 廚房用具除此之外,它們還都會把
NULL作為一個獨立的結果回傳,對多列使用時也會得到完全相同的結果,其實不僅處理結果相同,執行速度也基本上差不多,那么到底應該使用哪一個呢?但其實這個問題本身就是本末倒置的,我們應該考慮的是該
SELECT陳述句是否滿足需求,選擇的標準其實非常簡單,在“想要洗掉選擇結果中的重復記錄”時使用
DISTINCT,在“想要計算匯總結果”時使用GROUP BY,不使用
COUNT等聚合函式,而只使用GROUP BY子句的SELECT陳述句,會讓人覺得非常奇怪,使人產生“到底為什么要對表進行分組呢?這樣做有必要嗎?”等疑問,SQL 陳述句的語法與英語十分相似,理解起來非常容易,如果大家浪費了這一優勢,撰寫出一些難以理解的 SQL 陳述句,那就太可惜了,
三、為聚合結果指定條件
本節重點
使用
COUNT函式等對表中資料進行匯總操作時,為其指定條件的不是WHERE子句,而是HAVING子句,聚合函式可以在
SELECT子句、HAVING子句和ORDER BY子句中使用,
HAVING子句要寫在GROUP BY子句之后,
WHERE子句用來指定資料行的條件,HAVING子句用來指定分組的條件,
3.1 HAVING 子句
使用前一節學過的 GROUP BY 子句,可以得到將表分組后的結果,在此,我們來思考一下通過指定條件來選取特定組的方法,
例如,如何才能取出“聚合結果正好為 2 行的組”呢(圖 8)?
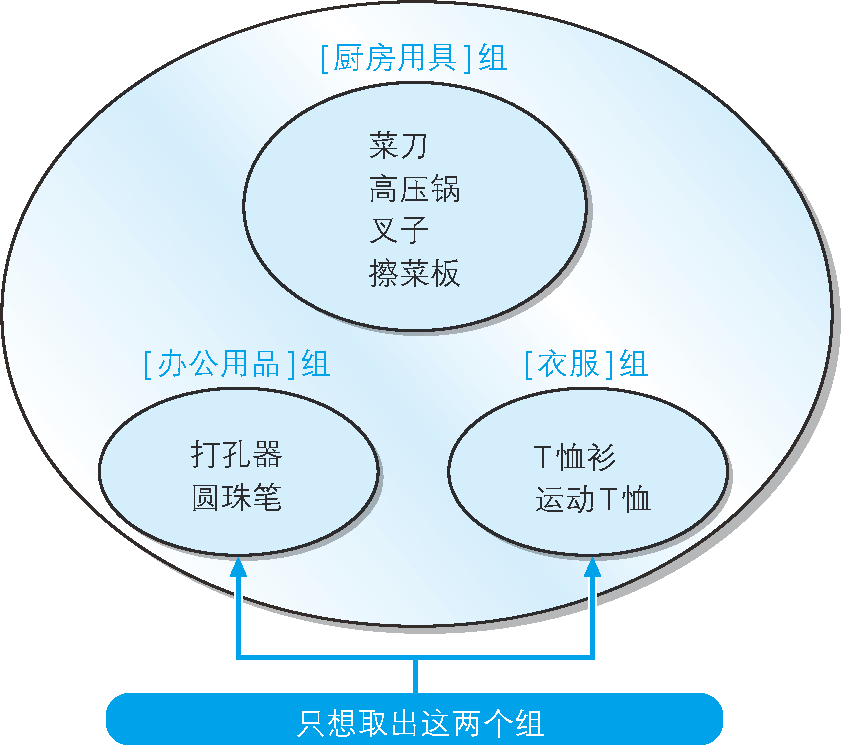
圖 8 取出符合指定條件的組
說到指定條件,估計大家都會首先想到 WHERE 子句,但是,WHERE 子句只能指定記錄(行)的條件,而不能用來指定組的條件(例如,“資料行數為 2 行”或者“平均值為 500”等),
因此,對集合指定條件就需要使用其他的子句了,此時便可以用 HAVING 子句 [5],
HAVING 子句的語法如下所示,
語法 3 HAVING 子句
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……
HAVING <分組結果對應的條件>
HAVING 子句必須寫在 GROUP BY 子句之后,其在 DBMS 內部的執行順序也排在 GROUP BY 子句之后,
使用 HAVING 子句時 SELECT 陳述句的順序
SELECT → FROM → WHERE → GROUP BY → HAVING
法則 13
HAVING子句要寫在GROUP BY子句之后,
接下來就讓我們練習一下 HAVING 子句吧,例如,針對按照商品種類進行分組后的結果,指定“包含的資料行數為 2 行”這一條件的 SELECT 陳述句,請參見代碼清單 20,
代碼清單 20 從按照商品種類進行分組后的結果中,取出“包含的資料行數為 2 行”的組
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING COUNT(*) = 2;
執行結果:
product_type | count
--------------+------
衣服 | 2
辦公用品 | 2
我們可以看到執行結果中并沒有包含資料行數為 4 行的“廚房用具”,
未使用 HAVING 子句時的執行結果中包含“廚房用具”,但是通過設定 HAVING 子句的條件,就可以選取出只包含 2 行資料的組了(代碼清單 21),
代碼清單 21 不使用 HAVING 子句的情況
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
執行結果:

下面我們再來看一個使用 HAVING 子句的例子,這次我們還是按照商品種類對表進行分組,但是條件變成了“銷售單價的平均值大于等于 2500 元”,
首先來看一下不使用 HAVING 子句的情況,請參見代碼清單 22,
代碼清單 22 不使用 HAVING 子句的情況
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type;
執行結果:
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
辦公用品 | 300.0000000000000000
廚房用具 | 2795.0000000000000000
按照商品種類進行切分的 3 組資料都顯示出來了,下面我們使用 HAVING 子句來設定條件,請參見代碼清單 23,
代碼清單 23 使用 HAVING 子句設定條件的情況
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;
執行結果:
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
廚房用具 | 2795.0000000000000000
銷售單價的平均值為 300 元的“辦公用品”在結果中消失了,
3.2 HAVING 子句的構成要素
HAVING 子句和包含 GROUP BY 子句時的 SELECT 子句一樣,能夠使用的要素有一定的限制,限制內容也是完全相同的,HAVING 子句中能夠使用的 3 種要素如下所示,
-
常數
-
聚合函式
-
GROUP BY子句中指定的列名(即聚合鍵)
代碼清單 20 中的例文指定了 HAVING COUNT(*)= 2 這樣的條件,其中 COUNT(*) 是聚合函式,2 是常數,全都滿足上述要求,
反之,如果寫成了下面這個樣子就會發生錯誤(代碼清單 24),
代碼清單 24 HAVING 子句的不正確使用方法
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_name = '圓珠筆';
執行結果:
ERROR: 列"product,product_name"必須包含在GROUP BY子句當中,或者必須在聚合函式中使用
行 4: HAVING product_name = '圓珠筆';
product_name 列并不包含在 GROUP BY 子句之中,因此不允許寫在 HAVING 子句里,
在思考 HAVING 子句的使用方法時,把一次匯總后的結果(類似表 2 的表)作為 HAVING 子句起始點的話更容易理解,
表 2 按照商品種類分組后的結果
product_type |
COUNT(*) |
|---|---|
| 廚房用具 | 4 |
| 衣服 | 2 |
| 辦公用品 | 2 |
可以把這種情況想象為使用 GROUP BY 子句時的 SELECT 子句,匯總之后得到的表中并不存在 product_name 這個列,SQL 當然無法為表中不存在的列設定條件了,
3.3 相對于 HAVING 子句,更適合寫在 WHERE 子句中的條件
也許有的讀者已經發現了,有些條件既可以寫在 HAVING 子句當中,又可以寫在 WHERE 子句當中,這些條件就是聚合鍵所對應的條件,
原表中作為聚合鍵的列也可以在 HAVING 子句中使用,因此,代碼清單 25 中的 SELECT 陳述句也是正確的,
代碼清單 25 將條件書寫在 HAVING 子句中的情況
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_type = '衣服';
執行結果:
product_type | count
--------------+------
衣服 | 2
上述 SELECT 陳述句的回傳結果與代碼清單 26 中 SELECT 陳述句的回傳結果是相同的,
代碼清單 26 將條件書寫在 WHERE 子句中的情況
SELECT product_type, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY product_type;
執行結果:
product_type | count
--------------+------
衣服 | 2
雖然條件分別寫在 WHERE 子句和 HAVING 子句當中,但是條件的內容以及回傳的結果都完全相同,因此,大家可能會覺得兩種書寫方式都沒問題,
如果僅從結果來看的話,確實如此,但筆者卻認為,聚合鍵所對應的條件還是應該書寫在 WHERE 子句之中,
理由有兩個,
首先,根本原因是 WHERE 子句和 HAVING 子句的作用不同,如前所述,HAVING 子句是用來指定“組”的條件的,
因此,“行”所對應的條件還是應該寫在 WHERE 子句當中,這樣一來,書寫出的 SELECT 陳述句不但可以分清兩者各自的功能,理解起來也更加容易,
WHERE 子句 = 指定行所對應的條件
HAVING 子句 = 指定組所對應的條件
其次,對初學者來說,研究 DBMS 的內部實作這一話題有些深奧,這里就不做介紹了,感興趣的讀者可以參考隨后的專欄——WHERE 子句和 HAVING 子句的執行速度,
法則 14
聚合鍵所對應的條件不應該書寫在
HAVING子句當中,而應該書寫在WHERE子句當中,
專欄
WHERE 子句和 HAVING 子句的執行速度
在
WHERE子句和HAVING子句中都可以使用的條件,最好寫在WHERE子句中的另一個理由與性能即執行速度有關系,由于性能不在本文介紹的范圍之內,因此暫不進行說明,通常情況下,為了得到相同的結果,將條件寫在
WHERE子句中要比寫在HAVING子句中的處理速度更快,回傳結果所需的時間更短,為了理解其中原因,就要從 DBMS 的內部運行機制來考慮,使用
COUNT函式等對表中的資料進行聚合操作時,DBMS 內部就會進行排序處理,排序處理是會大大增加機器負擔的高負荷的處理,因此,只有盡可能減少排序的行數,才能提高處理速度,
通過
WHERE子句指定條件時,由于排序之前就對資料進行了過濾,因此能夠減少排序的資料量,但
HAVING子句是在排序之后才對資料進行分組的,因此與在WHERE子句中指定條件比起來,需要排序的資料量就會多得多,雖然 DBMS 的內部處理不盡相同,但是對于排序處理來說,基本上都是一樣的,
此外,
WHERE子句更具速度優勢的另一個理由是,可以對WHERE子句指定條件所對應的列創建索引,這樣也可以大幅提高處理速度,創建索引是一種非常普遍的提高 DBMS 性能的方法,效果也十分明顯,這對
WHERE子句來說也十分有利,
四、對查詢結果進行排序
學習重點
使用
ORDER BY子句對查詢結果進行排序,在
ORDER BY子句中列名的后面使用關鍵字ASC可以進行升序排序,使用DESC關鍵字可以進行降序排序,
ORDER BY子句中可以指定多個排序鍵,排序健中包含
NULL時,會在開頭或末尾進行匯總,
ORDER BY子句中可以使用SELECT子句中定義的列的別名,
ORDER BY子句中可以使用SELECT子句中未出現的列或者聚合函式,
ORDER BY子句中不能使用列的編號,
4.1 ORDER BY 子句
截至目前,我們使用了各種各樣的條件對表中的資料進行查詢,本節讓我們再來回顧一下簡單的 SELECT 陳述句(代碼清單 27),
代碼清單 27 顯示商品編號、商品名稱、銷售單價和進貨單價的 SELECT 陳述句
SELECT product_id, product_name, sale_price, purchase_price
FROM Product;
執行結果:
product_id | product_name | sale_price | purchase_price
------------+---------------+--------------+----------------
0001 | T恤衫 | 1000 | 500
0002 | 打孔器 | 500 | 320
0003 | 運動T恤 | 4000 | 2800
0004 | 菜刀 | 3000 | 2800
0005 | 高壓鍋 | 6800 | 5000
0006 | 叉子 | 500 |
0007 | 擦菜板 | 880 | 790
0008 | 圓珠筆 | 100 |
對于上述結果,在此無需特別說明,本節要為大家介紹的不是查詢結果,而是查詢結果的排列順序,
那么,結果中的 8 行記錄到底是按照什么順序排列的呢?乍一看,貌似是按照商品編號從小到大的順序(升序)排列的,
其實,排列順序是隨機的,這只是個偶然,因此,再次執行同一條 SELECT 陳述句時,順序可能大為不同,
通常,從表中抽取資料時,如果沒有特別指定順序,最終排列順序便無從得知,即使是同一條 SELECT 陳述句,每次執行時排列順序很可能發生改變,
但是不進行排序,很可能出現結果混亂的情況,這時,便需要通過在 SELECT 陳述句末尾添加 ORDER BY 子句來明確指定排列順序,
ORDER BY 子句的語法如下所示,
語法 4 ORDER BY 子句
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
ORDER BY <排序基準列1>, <排序基準列2>, ……
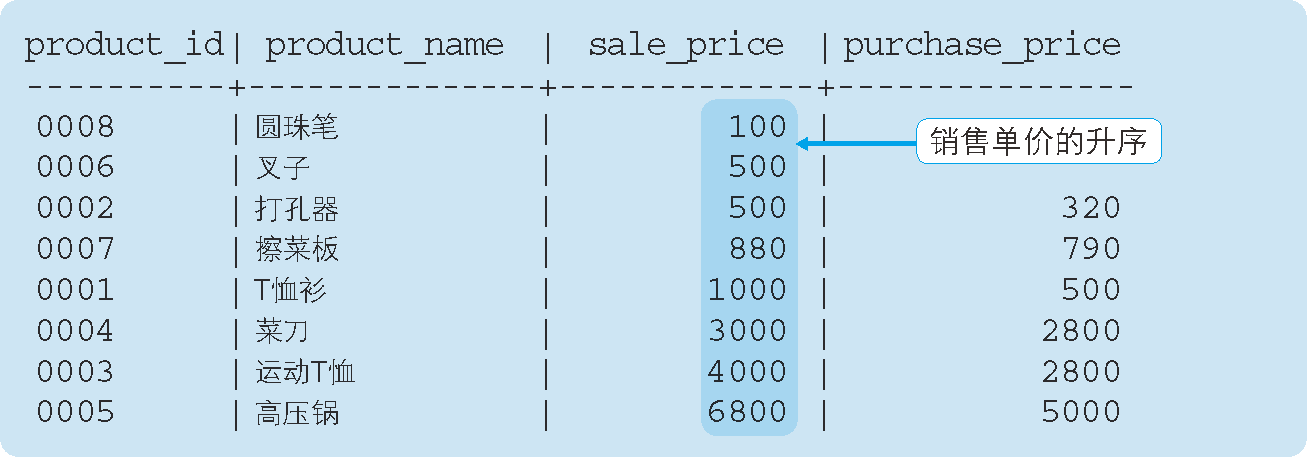
例如,按照銷售單價由低到高,也就是升序排列時,請參見代碼清單 28,
代碼清單 28 按照銷售單價由低到高(升序)進行排列
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price;
執行結果:
不論何種情況,ORDER BY 子句都需要寫在 SELECT 陳述句的末尾,
這是因為對資料行進行排序的操作必須在結果即將回傳時執行,ORDER BY 子句中書寫的列名稱為排序鍵,該子句與其他子句的順序關系如下所示,
子句的書寫順序
1. SELECT 子句 → 2. FROM 子句 → 3. WHERE 子句 → 4. GROUP BY 子句 → 5. HAVING 子句 → 6. ORDER BY 子句
法則 15
ORDER BY子句通常寫在SELECT陳述句的末尾,
不想指定資料行的排列順序時,SELECT 陳述句中不寫 ORDER BY 子句也沒關系,
4.2 指定升序或降序
與上述示例相反,想要按照銷售單價由高到低,也就是降序排列時,可以參見代碼清單 29,在列名后面使用 DESC 關鍵字,
代碼清單 29 按照銷售單價由高到低(降序)進行排列
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price DESC;
執行結果:
product_id | product_name | sale_ price | purchase_ price
------------+--------------+-------------+----------------
0005 | 高壓鍋 | 6800 | 5000
0003 | 運動T恤 | 4000 | 2800
0004 | 菜刀 | 3000 | 2800
0001 | T恤衫 | 1000 | 500
0007 | 擦菜板 | 880 | 790
0002 | 打孔器 | 500 | 320
0006 | 叉子 | 500 |
0008 | 圓珠筆 | 100 |
如上所示,這次銷售單價最高(6800 元)的高壓鍋排在了第一位,
其實,使用升序進行排列時,正式的書寫方式應該是使用關鍵字 ASC,但是省略該關鍵字時會默認使用升序進行排序,
這可能是因為實際應用中按照升序排序的情況更多吧,ASC 和 DESC 是 ascendent(上升的)和 descendent(下降的)這兩個單詞的縮寫,
法則 16
未指定
ORDER BY子句中排列順序時會默認使用升序進行排列,
由于 ASC 和 DESC 這兩個關鍵字是以列為單位指定的,因此可以同時指定一個列為升序,指定其他列為降序,
4.3 指定多個排序鍵
本節開頭曾提到過對銷售單價進行升序排列的 SELECT 陳述句(代碼清單 28)的執行結果,我們再來回顧一下,
可以發現銷售單價為 500 元的商品有 2 件,相同價格的商品的順序并沒有特別指定,或者可以說是隨機排列的,
如果想要對該順序的商品進行更細致的排序的話,就需要再添加一個排序鍵,在此,我們以添加商品編號的升序為例,請參見代碼清單 30,
代碼清單 30 按照銷售單價和商品編號的升序進行排序
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price, product_id;
執行結果:
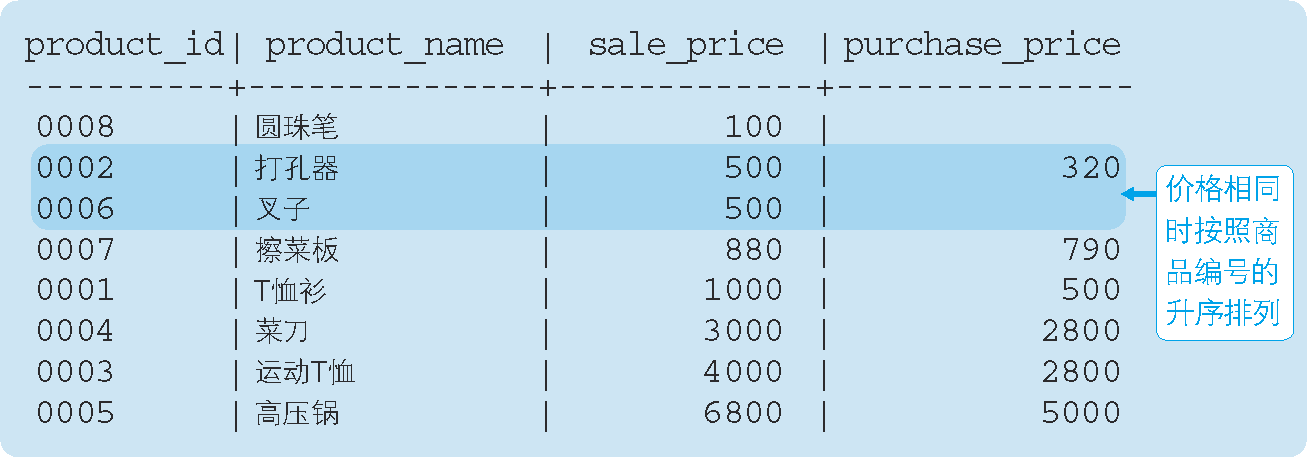
這樣一來,就可以在 ORDER BY 子句中同時指定多個排序鍵了,規則是優先使用左側的鍵,如果該列存在相同值的話,再接著參考右側的鍵,當然,也可以同時使用 3 個以上的排序鍵,
4.4 NULL 的順序
在此前的示例中,我們已經使用過銷售單價(sale_price 列)作為排序鍵了,這次讓我們嘗試使用進貨單價(purchase_price 列)作為排序鍵吧,
此時,問題來了,圓珠筆和叉子對應的值是 NULL,究竟 NULL 會按照什么順序進行排列呢? NULL 是大于 100 還是小于 100 呢?或者說 5000 和 NULL 哪個更大呢?
請大家回憶一下我們在 不能對 NULL 使用比較運算子 中學過的內容,沒錯,不能對 NULL 使用比較運算子,也就是說,不能對 NULL 和數字進行排序,也不能與字串和日期比較大小,
因此,使用含有 NULL 的列作為排序鍵時, NULL 會在結果的開頭或末尾匯總顯示(代碼清單 31),
代碼清單 31 按照進貨單價的升序進行排列
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY purchase_price;
執行結果:
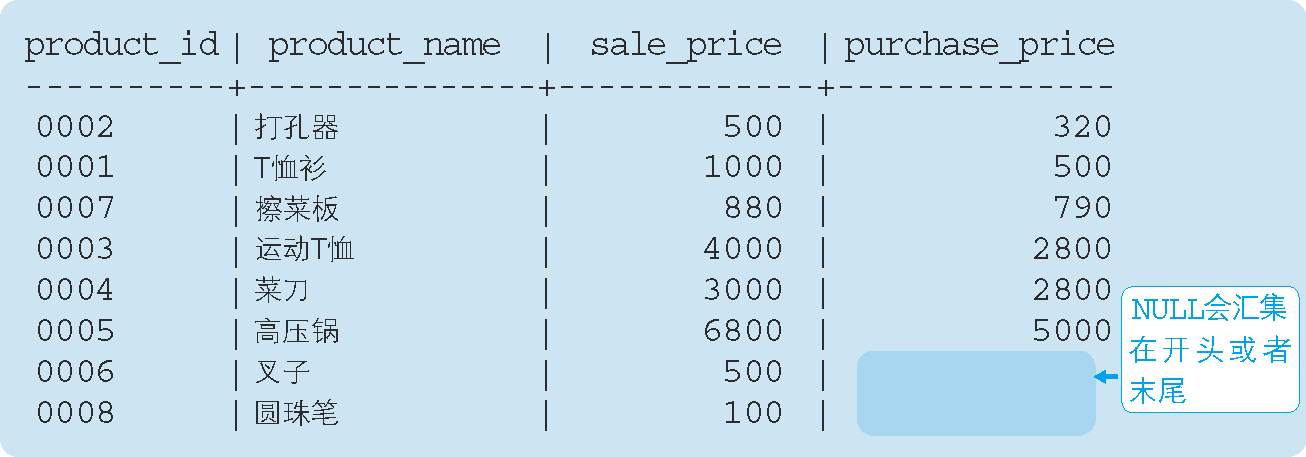
究竟是在開頭顯示還是在末尾顯示,并沒有特殊規定,某些 DBMS 中可以指定 NULL 在開頭或末尾顯示,希望大家對自己使用的 DBMS 的功能研究一下,
法則 17
排序鍵中包含
NULL時,會在開頭或末尾進行匯總,
4.5 在排序鍵中使用顯示用的別名
在第 2 節“常見錯誤 ②”中曾介紹過,在 GROUP BY 子句中不能使用 SELECT 子句中定義的別名,但是在 ORDER BY 子句中卻是允許使用別名的,
因此,代碼清單 32 中的 SELECT 陳述句并不會出錯,可正確執行,
代碼清單 32 ORDER BY 子句中可以使用列的別名
SELECT product_id AS id, product_name, sale_price AS sp, purchase_price
FROM Product
ORDER BY sp, id;
上述 SELECT 陳述句與之前按照“銷售單價和商品編號的升序進行排列”的 SELECT 陳述句(代碼清單 31)意思完全相同:
id | product_name | sp | purchase_price
------+---------------+-------+---------------
0008 | 圓珠筆 | 100 |
0002 | 打孔器 | 500 | 320
0006 | 叉子 | 500 |
0007 | 擦菜板 | 880 | 790
0001 | T恤衫 | 1000 | 500
0004 | 菜刀 | 3000 | 2800
0003 | 運動T恤 | 4000 | 2800
0005 | 高壓鍋 | 6800 | 5000
不能在 GROUP BY 子句中使用的別名,為什么可以在 ORDER BY 子句中使用呢?這是因為 SQL 陳述句在 DBMS 內部的執行順序被掩蓋起來了,
SELECT 陳述句按照子句為單位的執行順序如下所示,
使用 HAVING 子句時 SELECT 陳述句的順序
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
這只是一個粗略的總結,雖然具體的執行順序根據 DBMS 的不同而不同,但是大家有這樣一個大致的印象就可以了,
一定要記住 SELECT 子句的執行順序在 GROUP BY 子句之后,ORDER BY 子句之前,
因此,在執行 GROUP BY 子句時,SELECT 陳述句中定義的別名無法被識別 [^8],對于在 SELECT 子句之后執行的 ORDER BY 子句來說,就沒有這樣的問題了,
[^8] 也是因為這一原因,HAVING 子句也不能使用別名,
法則 18
在
ORDER BY子句中可以使用SELECT子句中定義的別名,
4.6 ORDER BY 子句中可以使用的列
ORDER BY 子句中也可以使用存在于表中、但并不包含在 SELECT 子句之中的列(代碼清單 33),
代碼清單 33 SELECT 子句中未包含的列也可以在 ORDER BY 子句中使用
SELECT product_name, sale_price, purchase_price
FROM Product
ORDER BY product_id;
執行結果:
product_name | sale_price | purchase_price
---------------+-------------+----------------
T恤衫 | 1000 | 500
打孔器 | 500 | 320
運動T恤 | 4000 | 2800
菜刀 | 3000 | 2800
高壓鍋 | 6800 | 5000
叉子 | 500 |
擦菜板 | 880 | 790
圓珠筆 | 100 |
除此之外,還可以使用聚合函式(代碼清單 34),
代碼清單 34 ORDER BY 子句中也可以使用聚合函式

執行結果:
product_type | count
---------------+------
衣服 | 2
辦公用品 | 2
廚房用具 | 4
法則 19
在
ORDER BY子句中可以使用SELECT子句中未使用的列和聚合函式,
4.7 不要使用列編號
在 ORDER BY 子句中,還可以使用在 SELECT 子句中出現的列所對應的編號,是不是沒想到?
列編號是指 SELECT 子句中的列按照從左到右的順序進行排列時所對應的編號(1, 2, 3,…),因此,代碼清單 35 中的兩條 SELECT 陳述句的含義是相同的,
代碼清單 35 ORDER BY 子句中可以使用列的編號
-- 通過列名指定
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price DESC, product_id;
-- 通過列編號指定
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY 3 DESC, 1;
上述第 2 條 SELECT 陳述句中的 ORDER BY 子句所代表的含義,就是“按照 SELECT 子句中第 3 列的降序和第 1 列的升序進行排列”,這和第 1 條 SELECT 陳述句的含義完全相同,
執行結果:
product_id | product_name | sale_price | purchase_price
-----------+---------------+-------------+----------------
0005 | 高壓鍋 | 6800 | 5000
0003 | 運動T恤 | 4000 | 2800
0004 | 菜刀 | 3000 | 2800
0001 | T恤衫 | 1000 | 500
0007 | 擦菜板 | 880 | 790
0002 | 打孔器 | 500 | 320
0006 | 叉子 | 500 |
0008 | 圓珠筆 | 100 |
雖然列編號使用起來非常方便,但我們并不推薦使用,原因有以下兩點,
第一,代碼閱讀起來比較難,使用列編號時,如果只看 ORDER BY 子句是無法知道當前是按照哪一列進行排序的,只能去 SELECT 子句的串列中按照列編號進行確認,
上述示例中 SELECT 子句的列數比較少,因此可能并沒有什么明顯的感覺,
但是在實際應用中往往會出現列數很多的情況,而且 SELECT 子句和 ORDER BY 子句之間,還可能包含很復雜的 WHERE 子句和 HAVING 子句,直接人工確認實在太麻煩了,
第二,這也是最根本的問題,實際上,在 SQL-92 [6] 中已經明確指出該排序功能將來會被洗掉,
因此,雖然現在使用起來沒有問題,但是將來隨著 DBMS 的版本升級,可能原本能夠正常執行的 SQL 突然就會出錯,
不光是這種單獨使用的 SQL 陳述句,對于那些在系統中混合使用的 SQL 來說,更要極力避免,
法則 20
在
ORDER BY子句中不要使用列編號,
原文鏈接:https://www.developerastrid.com/sql/sql-aggregate-group-by-having-order-by/
(完)
函式中的函就是盒子的意思, ??
雖然使用
SUM函式時,“將NULL除外”和“等同于 0”的結果相同,但使用AVG函式時,這兩種情況的結果就完全不同了,接下來我們會詳細介紹在AVG函式中使用包含NULL的列作為引數的例子, ??不過,只有 MySQL 認同這種語法,所以能夠執行,不會發生錯誤(在多列候補中只要有一列滿足要求就可以了),但是 MySQL 以外 的 DBMS 都不支持這樣的語法,因此請不要使用這樣的寫法, ??
需要注意的是,雖然這樣的寫法在 PostgreSQL 和 MySQL 都不會發生執行錯誤,但是這并不是通常的使用方法 ??
HAVING是 HAVE( 擁有 )的現在分詞,并不是通常使用的英語單詞, ??1992 年制定的 SQL 標準, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499166.html
標籤:SQL Server
上一篇:DBeaverEE for Mac(資料庫管理工具)
下一篇:SQL 如何插入、洗掉和更新資料