一、資料庫的操作
1.創建資料庫
若在可視化軟體上創建資料庫,參考如下圖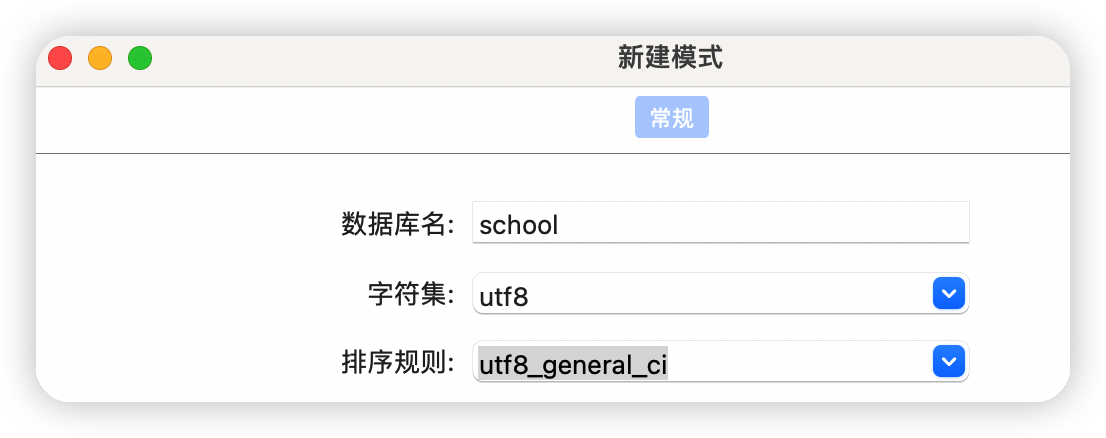
如果要創建的資料庫不存在,則創建成功
create database if not exists westos;

2.洗掉資料庫
drop database if exists westos;

3.使用資料庫
use tmalldemodb;
//tab鍵的上面,如果你的表名或者欄位名是一個特殊字符,就需要帶``

4.查看資料庫
show databases;

5.清空當前命令列界面命令
clear;
6.創建表
-
auto_increment:自增
-
字串使用單引號括起來
-
所有陳述句后面加逗號,英文的,最后一個不用加
-
primary key主鍵,一般一個表只有一個唯一的主鍵,且必須要有
-
engine=innodb:資料庫表的引擎
mysql> create table if not exists student(
-> id int(4) not null auto_increment comment '學號',
-> name varchar(30) not null default '匿名' comment '姓名',
-> pwd varchar(20) not null default '123456' comment '密碼',
-> sex varchar(2) not null default '女' comment '性別',
-> birthday datetime default null comment '出生日期',
-> address varchar(100) default null comment '家庭地址',
-> email varchar(50) default null comment '郵箱',
-> primary key(id)
-> )engine=innodb default charset=utf8;
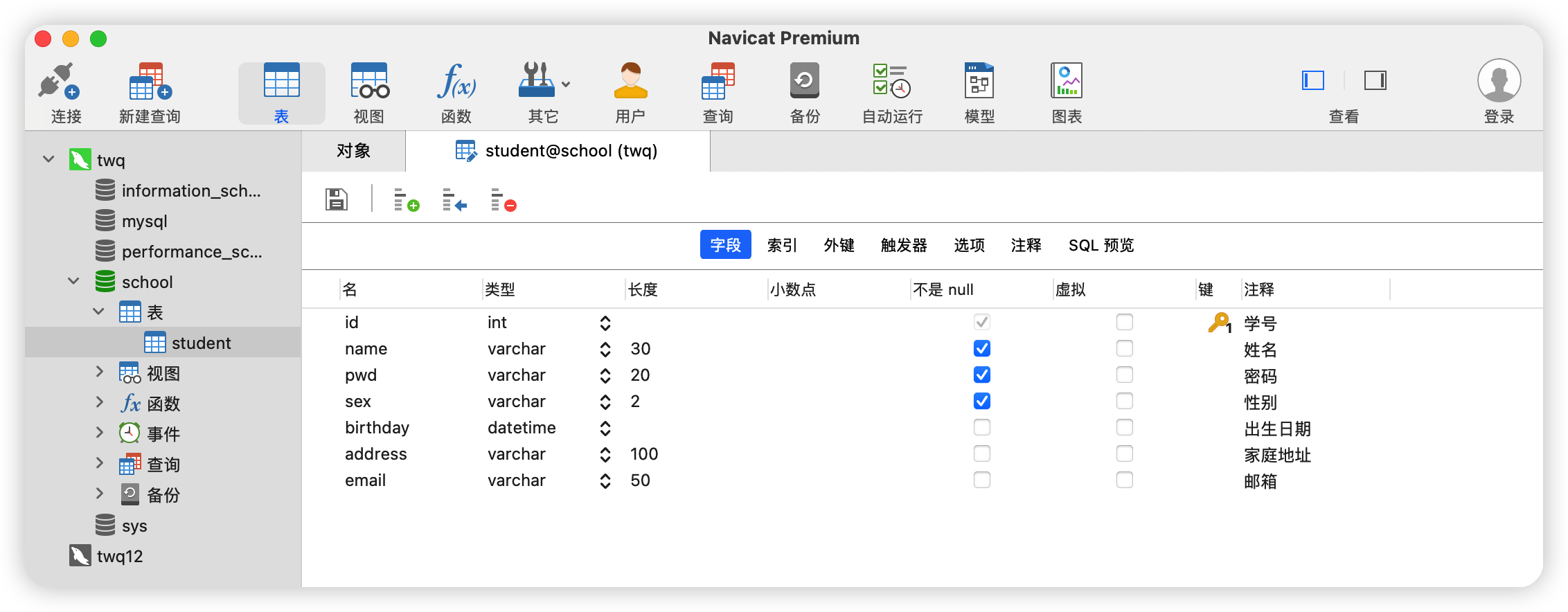
創鍵成功之后的圖
7.常用命令
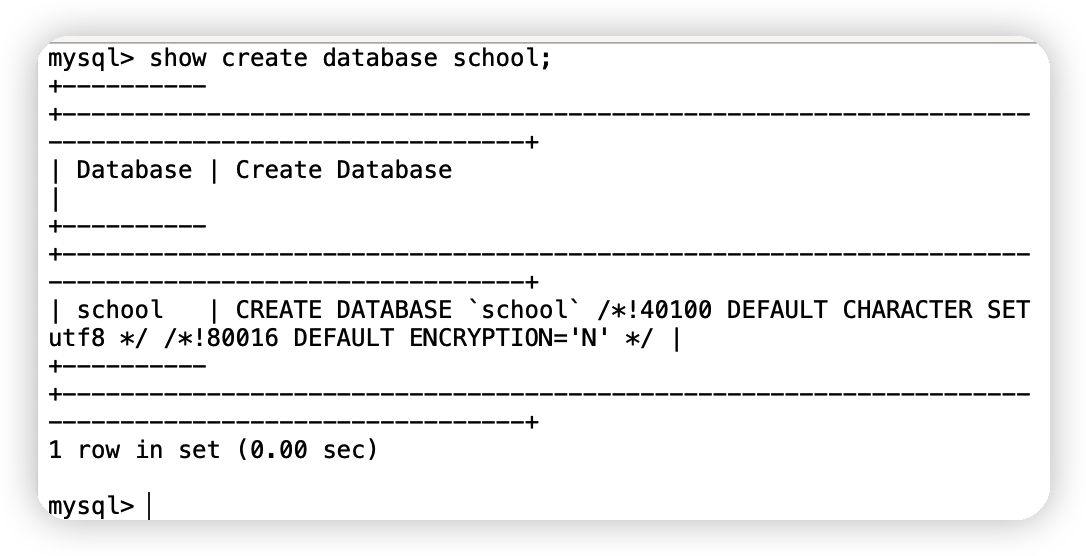
(1)查看創建資料庫的陳述句
show create database 資料庫名;
運行結果圖
(2)查看表的創建陳述句
show create table 表名;

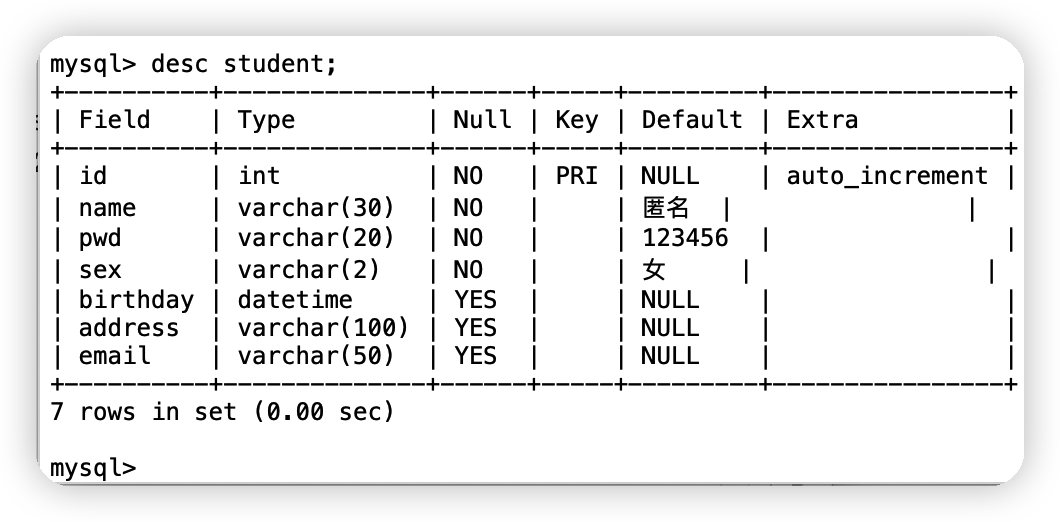
(3)顯示表的結構
desc 表名;
8.資料表的型別
(1)資料庫的引擎
innodb //默認使用
myisam//早些年使用的
-
事務:假設有兩個SQL都執行,要么都成功,要么都失敗,如果有一個成功一個失敗,它就提交不上去
-
資料行鎖定:假設有兩條SQL去查同一個表,他會把這個表先鎖住,剩下的資料再查的時候就要排隊等待
-
外鍵約束:一張表連接到另一張表
-
全文索引:比如在百度上根據你輸入的關鍵詞(在資料庫叫欄位)區搜索你想要的結果
| myisam | innodb | |
|---|---|---|
| 事務支持 | 不支持 | 支持 |
| 資料行鎖定 | 不支持 (支持表鎖) | 支持 |
| 外鍵約束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空間的大小 | 較小 | 較大,約為myisam的2倍 |
常規使用操作:
-
myisam 節約空間,速度較快
-
innodb安全性高,事務的處理,多表多用戶操作
(2)在物理空間存在的位置
所有的資料庫檔案都存在data目錄下 本質還是檔案的存盤!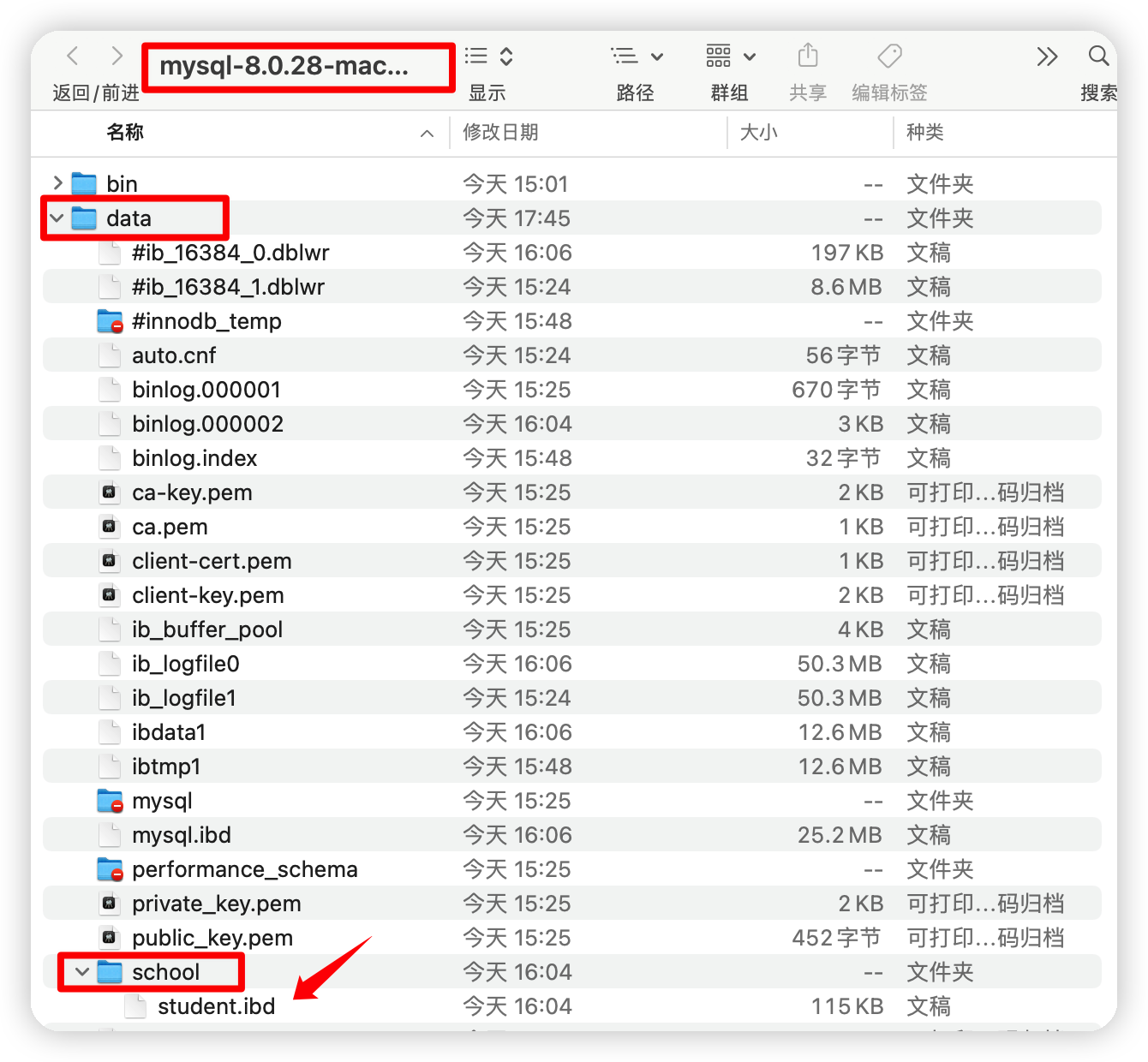
9.修改和洗掉表的欄位
(1)修改表名
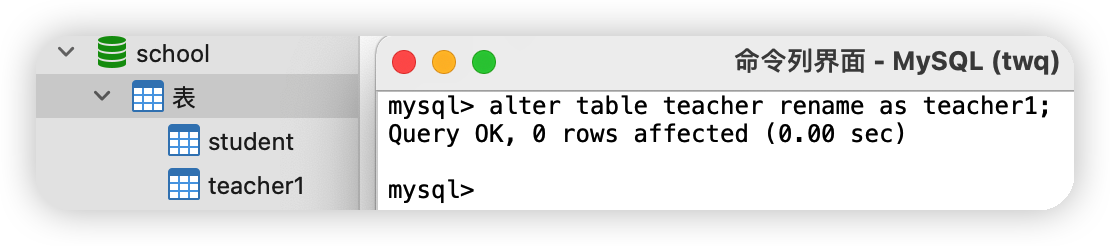
alter table 舊表名 rename as 新表名;alter table teacher rename as teacher1;
(2)增加表的欄位
alter table 表名 add 欄位名 列屬性;alter table teacher1 add age int(11);

(3)修改表的欄位(重命名,修改約束)
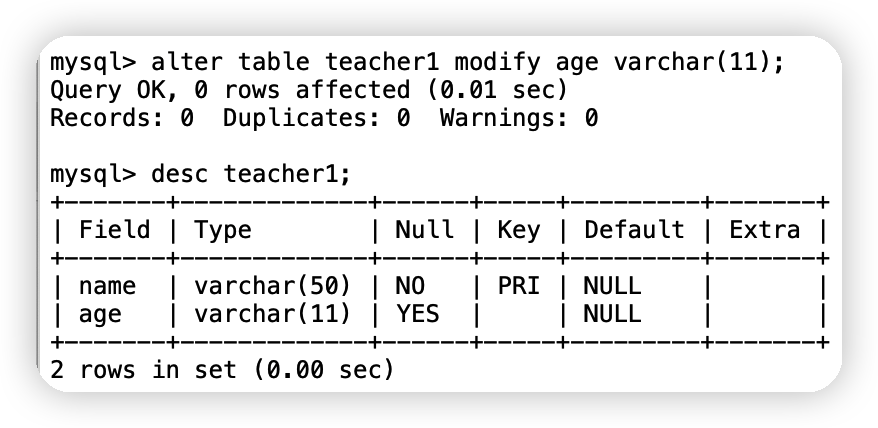
①修改約束modify(不能重命名): alter table 表名 modify 欄位名 新的列屬性;alter table teacher1 modify age varchar(11);
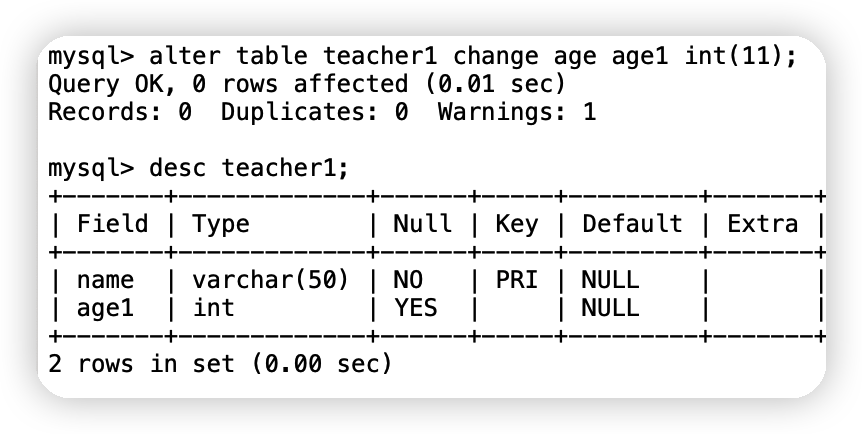
②欄位重命名(既可以給欄位重命名,又可以修改約束)
alter table 表名 change 舊欄位名 新欄位名 列屬性;
alter table teacher1 change age age1 int(11);
(4)洗掉表的欄位
alter table 表名 drop 欄位名;alter table teacher1 drop age1;
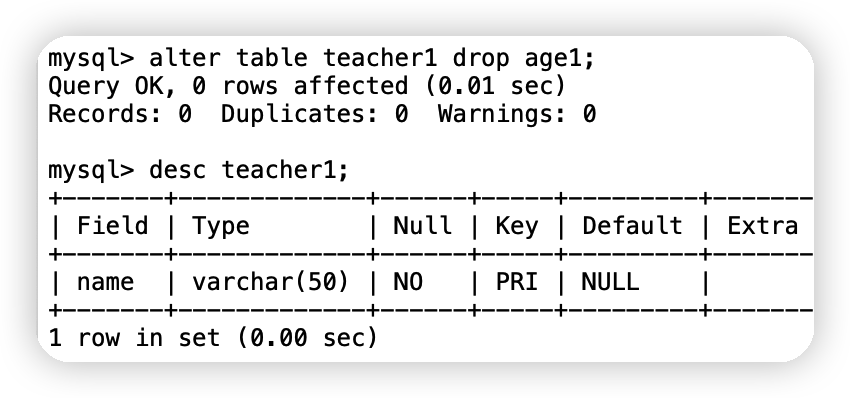
(5)洗掉表
如果要洗掉的表存在,則洗掉 drop table if exists 表名;drop table if exists teacher1;
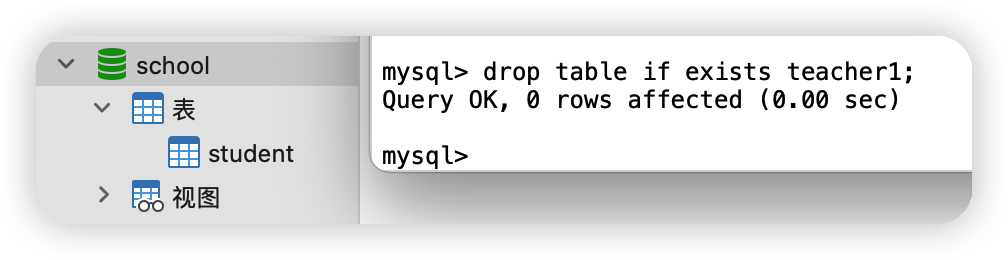
所有的創建和洗掉操作都盡量加上判斷,以免報錯
二、列的資料型別詳解
1.數值
-
tinyint 十分小的資料 1個位元組
-
smallint 較小的資料 2個位元組
-
int 標準的整數 4個位元組 常用
-
bigint 較大的資料 8個位元組
-
float 浮點數 4個位元組
-
double 浮點數 8個位元組
-
decimal 字串形式的浮點數
2.字串
-
char 字串固定的大小 0-255
-
varchar 可變字串 0-65535 常用
-
tinytext 微型文本 2^8-1
-
text 保存大文本 2^16-1
3.時間和日期
-
date 日期格式:YYYY-MM-DD
-
time 時間格式:HH:mm:ss
-
datetime 日期格式:YYYY-MM-DD HH:mm:ss 常用
-
timestamp 時間戳,從1970.1.1至現在的毫秒數 常用
-
year 年份表示
4.null
-
沒有值,未知
-
注意,不要使用NULL進行運算,結果為NULL
三、資料庫的欄位屬性(重點)
1.unsigned
-
無符號的整數
-
不能宣告為負數
2.zerofill
-
0填充的
-
假設你現在要寫一個長度為10的int型別,但是你只寫了個1,則他會用自動給你在1前面填充9個零
3.自增
-
通常理解為自增,自動在上一條記錄的基礎上+1(默認)
-
通常用來設計唯一的主鍵~index,必須是整數型別
-
可以自定義設定主鍵自增的起始值和步長
4.非空
-
假設設定為not null ,如果不給它賦值,就會報錯!
-
Null,如果不填寫值,默認就是null!
5.默認
-
設定默認的值
-
sex,默認值為男,如果不指定該列的值,則會有默認的值!
-
設定默認的值
四、MySQL資料管理
1.外鍵(了解即可)
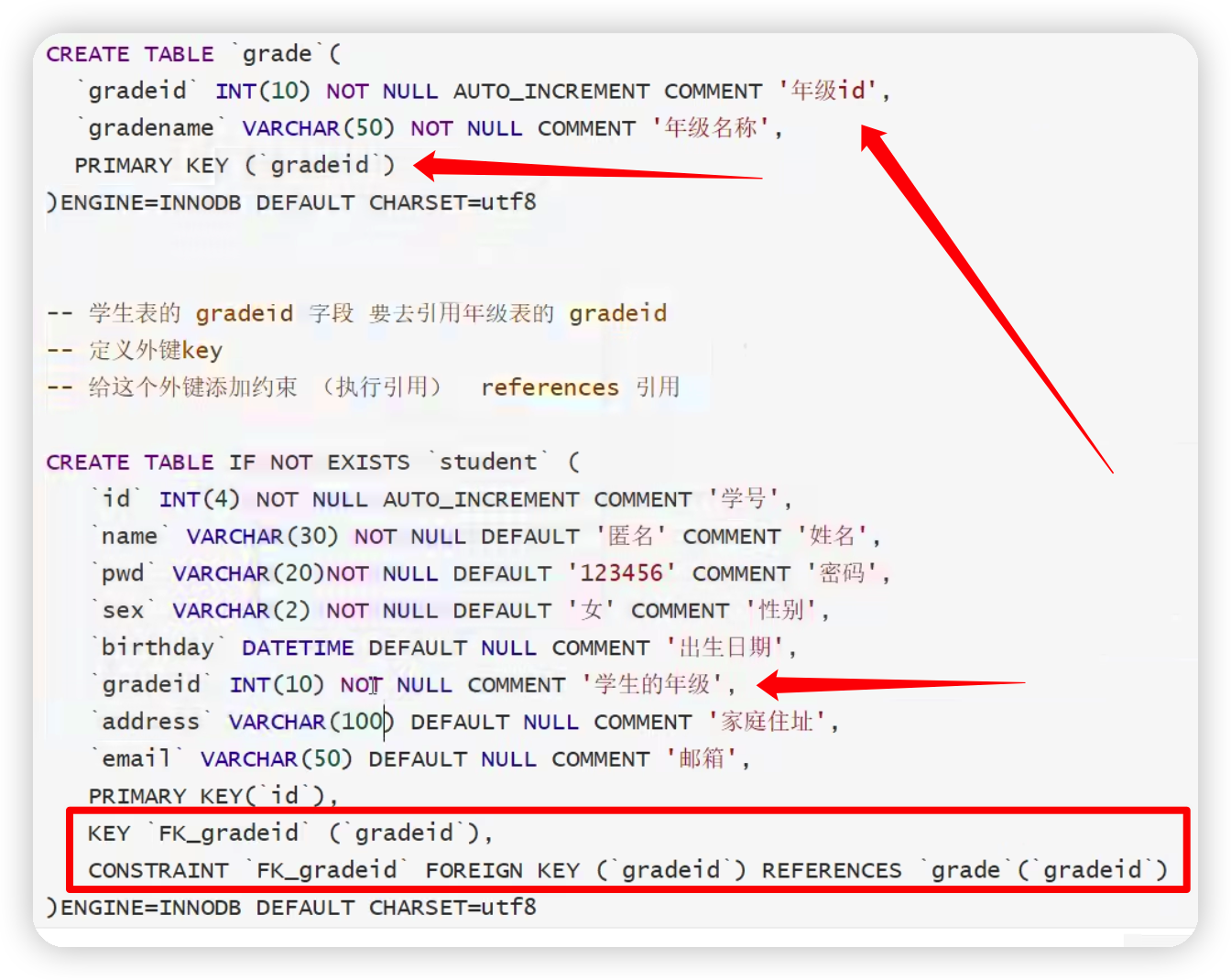
洗掉有外鍵關系的表的時候,必須要先洗掉字表,才能洗掉父表
2.DML語言(全部背住)
-
insert
-
update
-
delete
3.添加
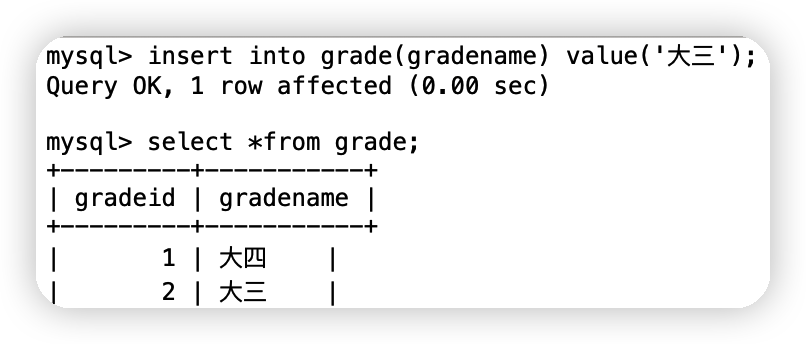
insert into 表名(欄位名1,欄位名2,欄位名3,....) value(值1,值2,值3,....) ==注意:一般寫插入陳述句,我們一定要資料和欄位一一對應!==(1)插入一行資料
insert into grade(gradename) value('大三');
(2)插入多行資料
==注意:給一個欄位添加多行值時,每個值都用括號括起來,且中間用逗號隔開,==insert grade(gradename) value('大二'),('大一');

insert into student(name,pwd,sex) values('張三','aaaa','男'),('李四','vvvv','女');
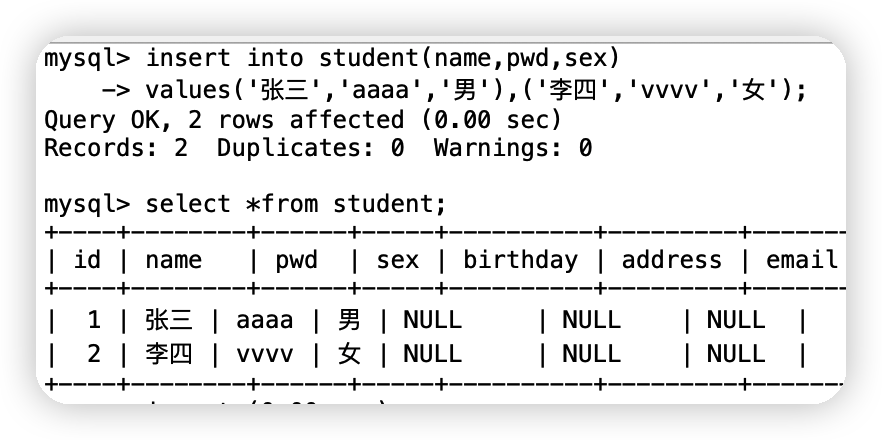
4.修改
(1)修改一條資料
格式:update 表名 set colnum_name = value where 條件 下面這行代碼的意思是將student表中id=2的name值設定為TWQupdate student set name='TWQ' where id =2;
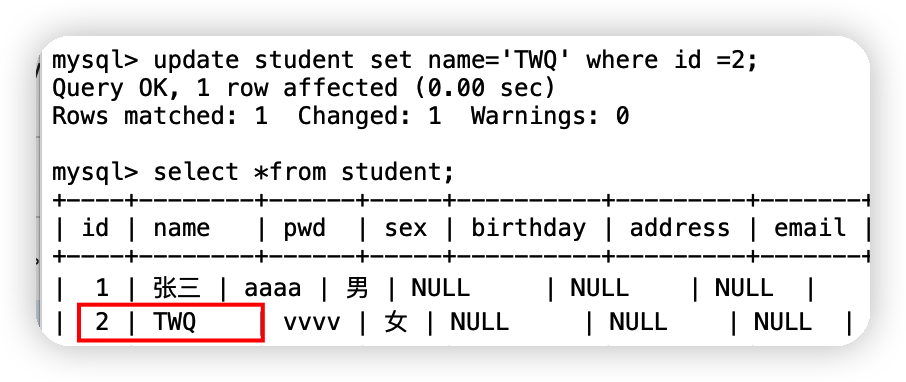
(2)修改多條資料
條件:where子句,運算子id等于某個值,大于某個值,或在某個區間內修改| 運算子 | 含義 | 范圍 | 結果 |
|---|---|---|---|
| = | 等于 | 5=6 | false |
| <>或!= | 不等于 | 5<>6 | true |
| < | 小于 | 5<6 | true |
| > | 大于 | 5>6 | false |
| <= | 小于等于 | 5<=6 | true |
| >= | 大于等于 | 5>=6 | false |
| between a and b | 在a到b這個閉包區間內 | [a,b] | true |
| and | 我和你 && | 5>1 and 1>2 | false |
| or | 我或你 | 5>1 or 1>2 | true |
5.洗掉
(1)delete命令
語法:delete from 表名 where 條件;delete from student where id =1;
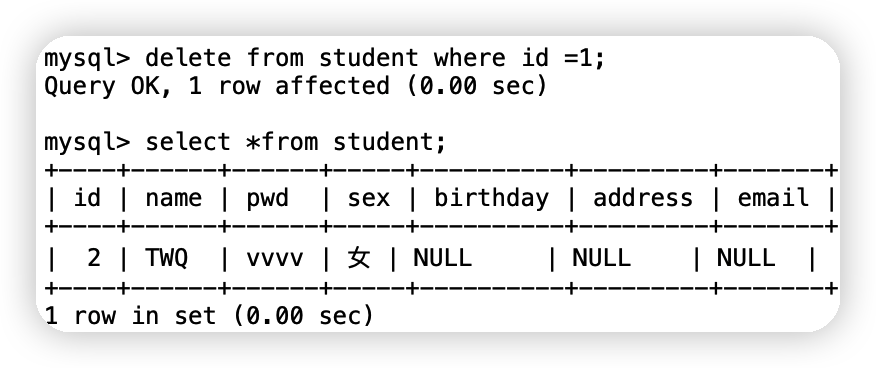
(2)truncate命令
作用:完全清空一個資料庫表,表的結構和索引不會變truncate table student;

(3)truncate和delete命令區別
-
相同點:都能洗掉資料,都不會洗掉表結構
-
不同:①truncate重新設定自增列,計數器會歸零,②truncate不會影響事務
使用delete洗掉表中所有資料,不會影響自增的值
拓展(了解即可)關于delete洗掉的問題:洗掉后重啟資料庫 -
若該表使用的引擎為innodb,重啟資料庫后,自增列會從1開始(存在記憶體當中斷電即失)
-
若采用的引擎是myisam 重啟資料庫后,會繼續從上一個自增變數開始(存盤在檔案中,不會丟失)
delete from grade;
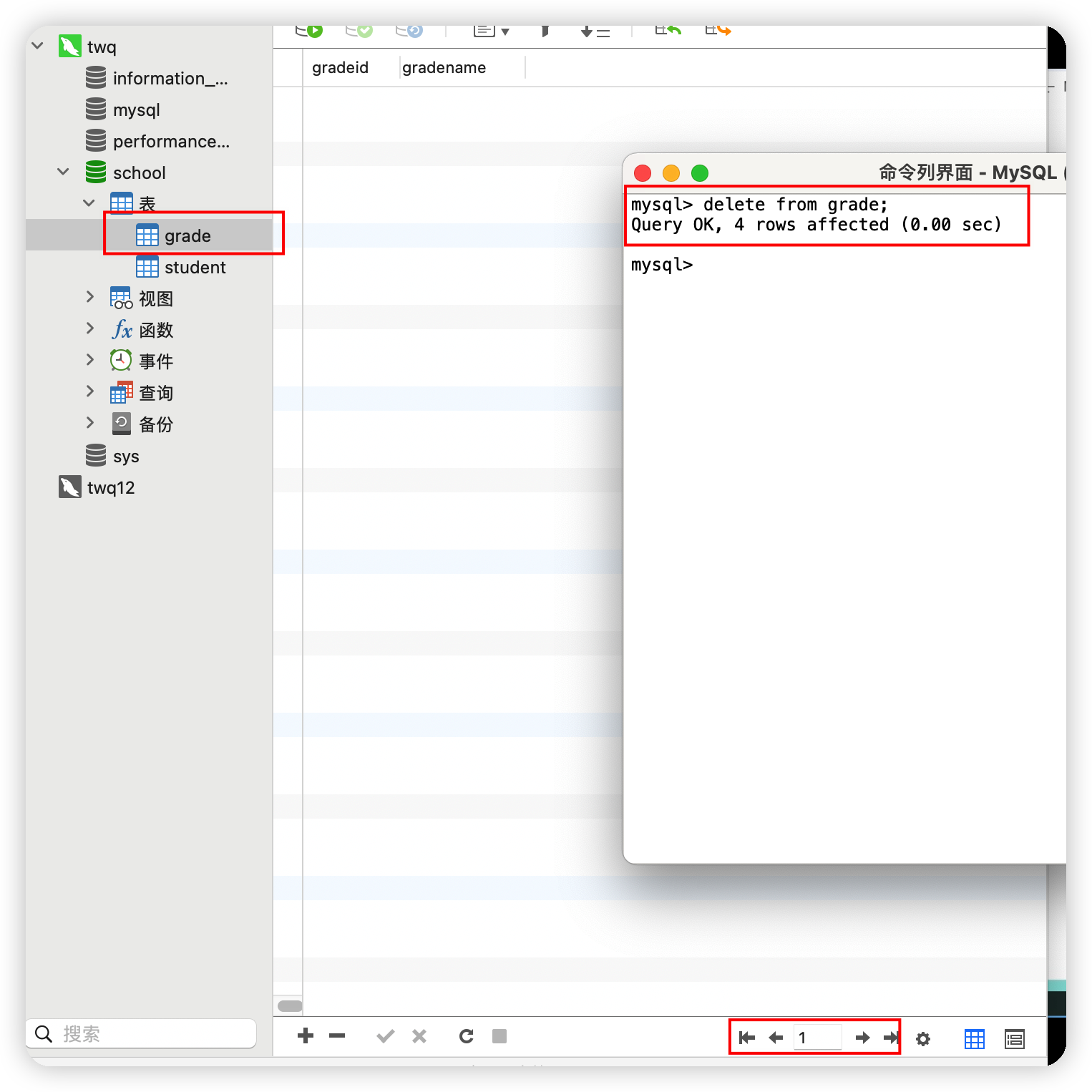
使用truncate洗掉表中所有資料,自增變數會歸零
truncate table grade;
五、DQL查詢資料(重點中的重點)
select語法
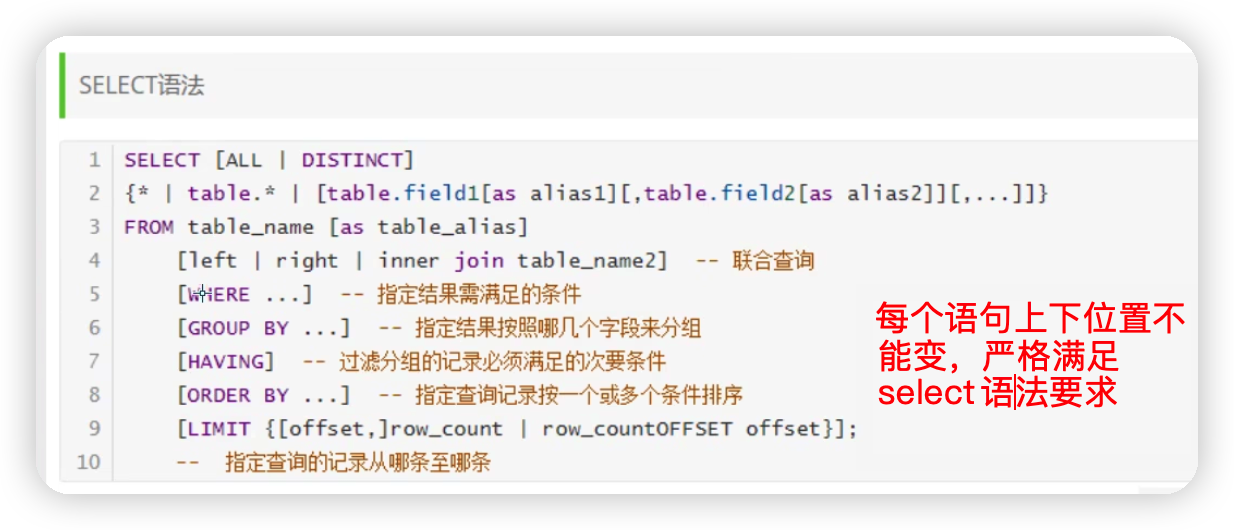
5.1指定查詢欄位
(1)查詢某個表中全部的資料
如查詢student表中所有的資料select * from student;
(2)查詢某個表中指定欄位
①查詢student表中name和pwd欄位的值select name,pwd from student;
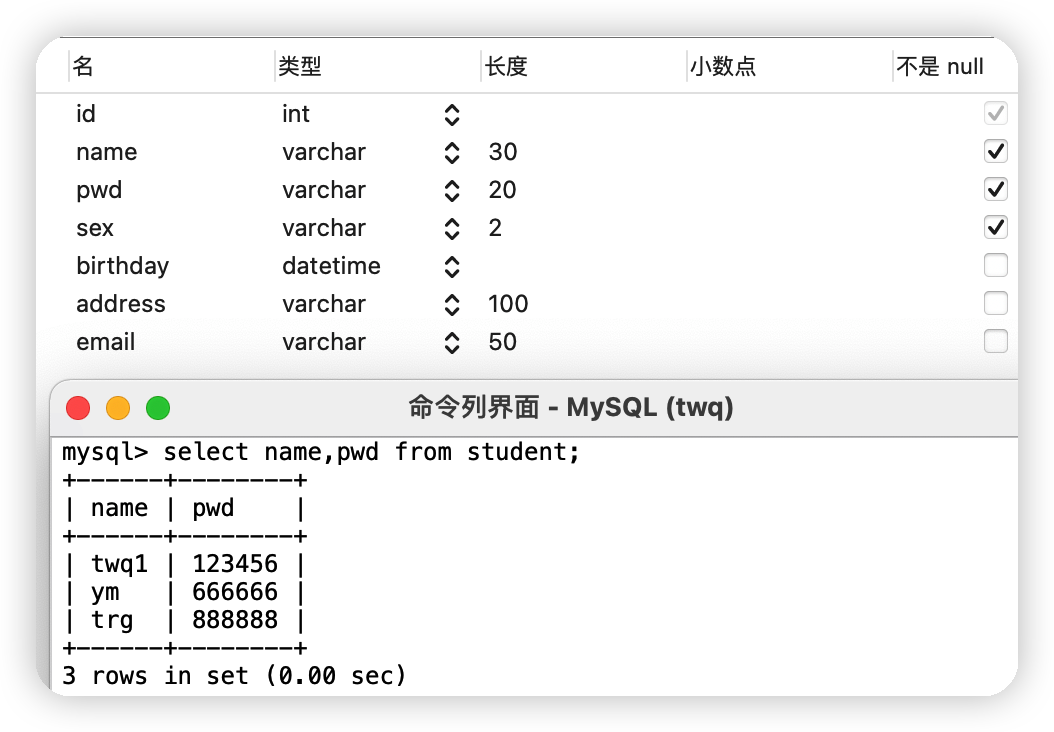
②給欄位或表名起別名(as)
select name as 姓名,pwd as 密碼 from student;

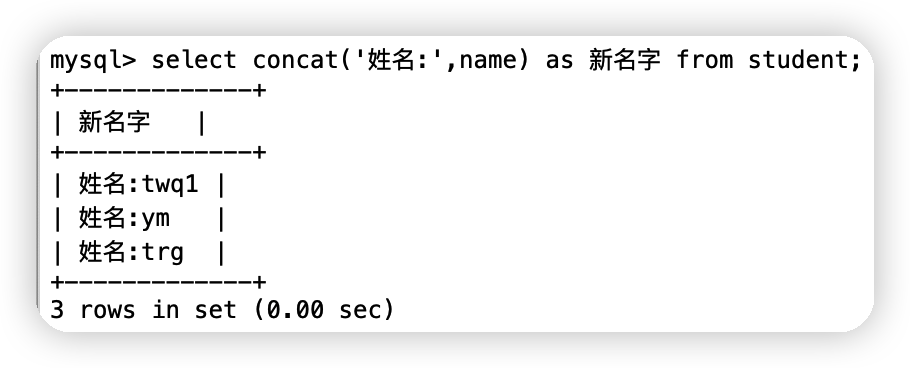
(3)函式concat(a,b)
select concat('姓名:',name) as 新名字 from student;
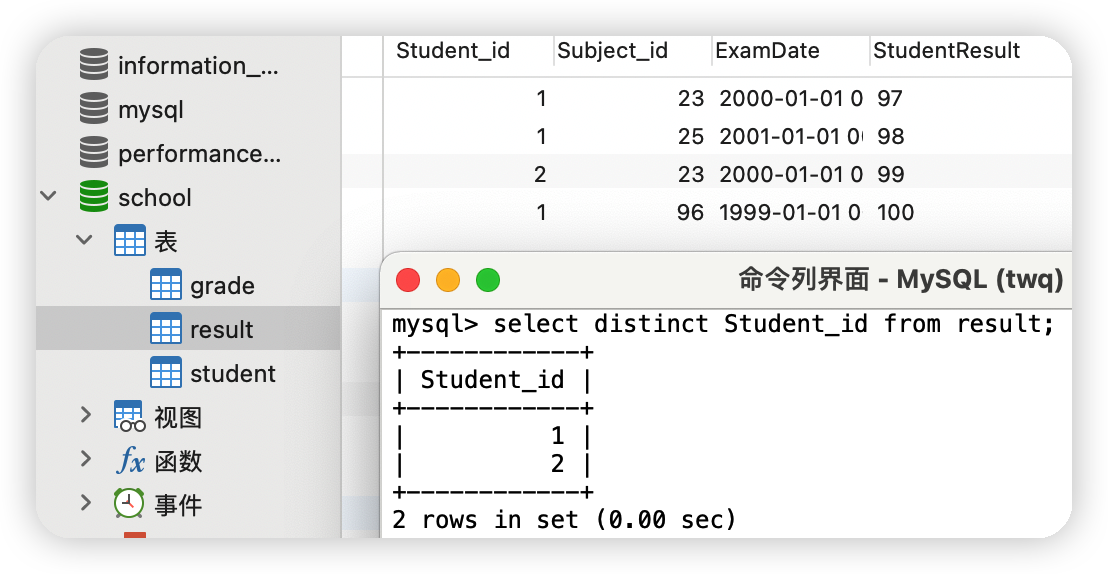
(4)去重distinct
①查詢有哪些同學參加了考試(可能有一個同學考了多個學科,造成的資料重復,需要去重)select distinct Student_id from result;
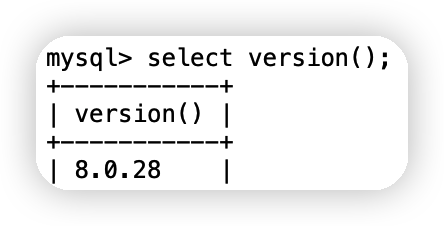
(5)查詢系統版本
select version();
(6)用來計算
select 100*3-1 as 計算結果;

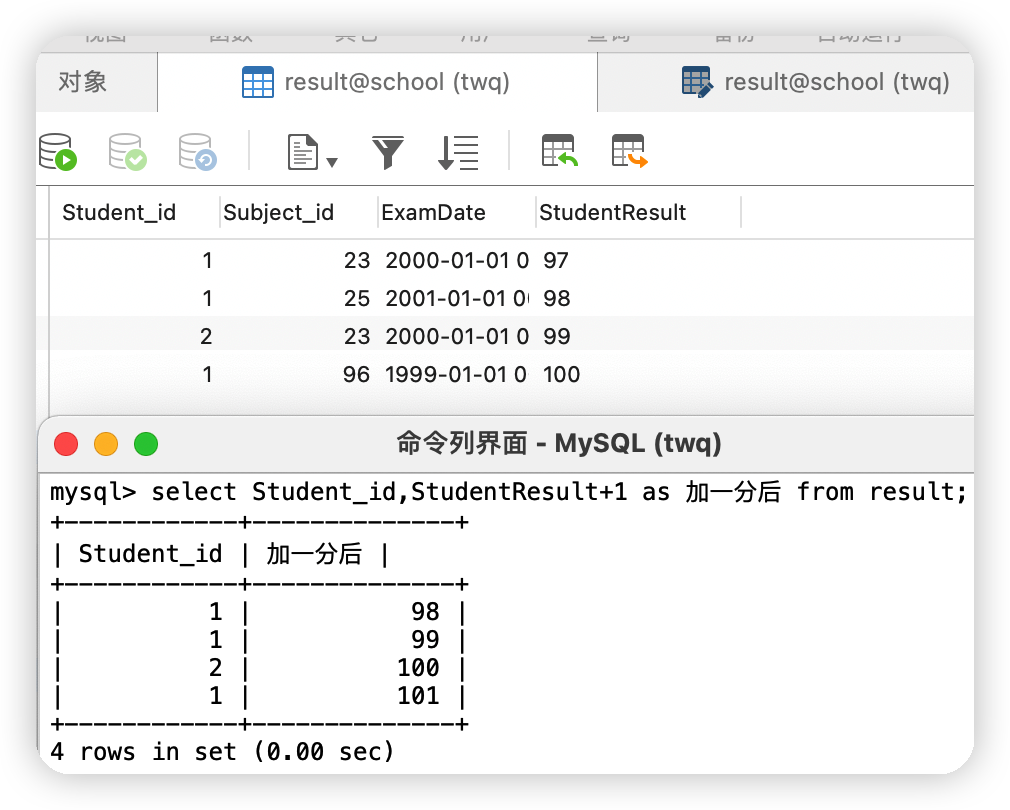
(7)查看學生成績+1分之后的結果
select Student_id,StudentResult+1 as 加一分后 from result;
5.2 where條件子句
作用:檢索資料中符合條件的值 搜索的條件由一個或者多個運算式組成!結果為布林值(1)邏輯運算子
| 運算子 | 語法 | 描述 |
|---|---|---|
| and | a and b | 邏輯與 |
| or | a or b | 邏輯或 |
| Not | not a | 邏輯非 |
(2)where的運用
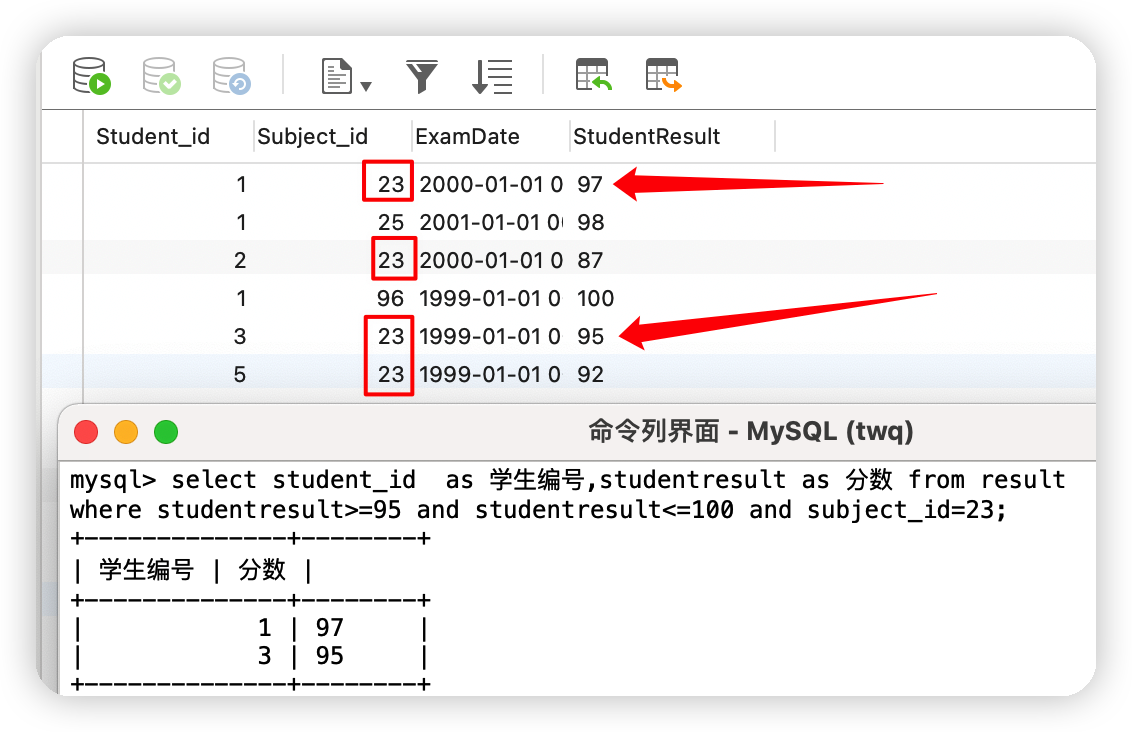
①查詢23(學科編號)這個學科成績在95到100之間的學生//方式一:
select student_id as 學生編號,studentresult as 分數 from result
where studentresult>=95 and studentresult<=100 and subject_id=23;
//方式二:
select student_id as 學生編號,studentresult as 分數 from result
where studentresult between 95 and 100 and subject_id=23;
(3)模糊查詢:比較運算子
| 運算子 | 語法 | 描述 |
|---|---|---|
| is null | a is null | 如果運算子為null,結果為真 |
| is not null | a is not nul | 如果運算子為不為null,結果為真 |
| between | a between b and c | 若a在b和c之間,則結果為真 |
| like | a like b | sql匹配,如果匹配b,則結果為真 |
| in | a in(a1,a2,a3,.....) | 假設a在a1,或者a2....其中的一個值中,結果為真 |
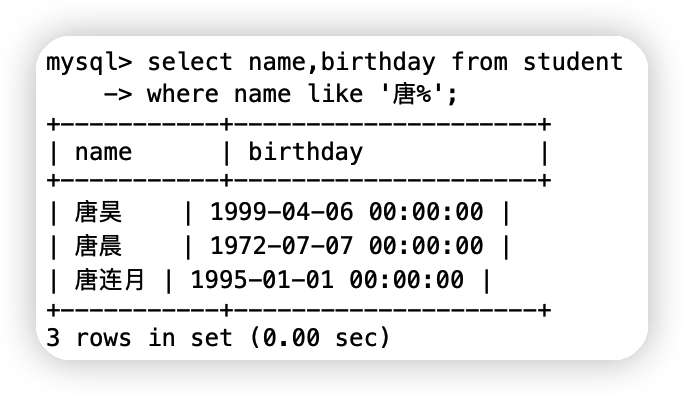
①查詢姓唐的同學
like 結合 %(代表0到任意個字符) _(一個字符)
select name,birthday from student
where name like '唐%';
②查詢姓唐的同學,并且名字后面僅有一個字的
select name,birthday from student
where name like '唐_';
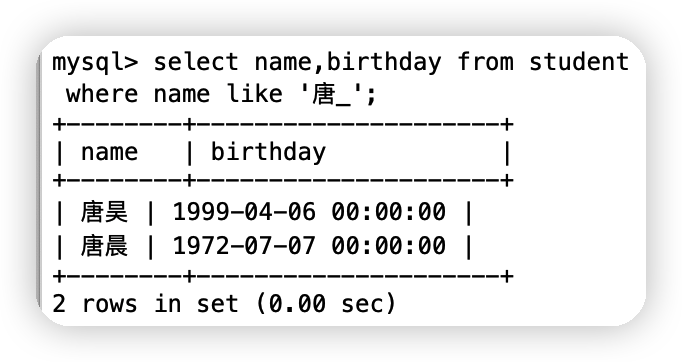
③查詢姓唐的同學,并且名字后面僅有個字的
select name,birthday from student
where name like '唐__';
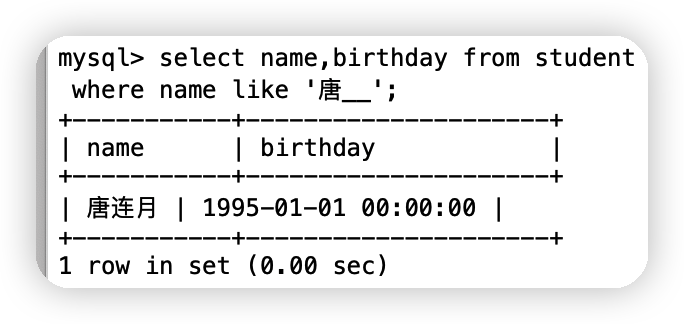
④查詢名字中含有嘉字的同學 %嘉%
select name,birthday from student
where name like '%嘉%';
⑤查詢id為3,4,5號的學生
select name,birthday from student
where id in (3,4,5);
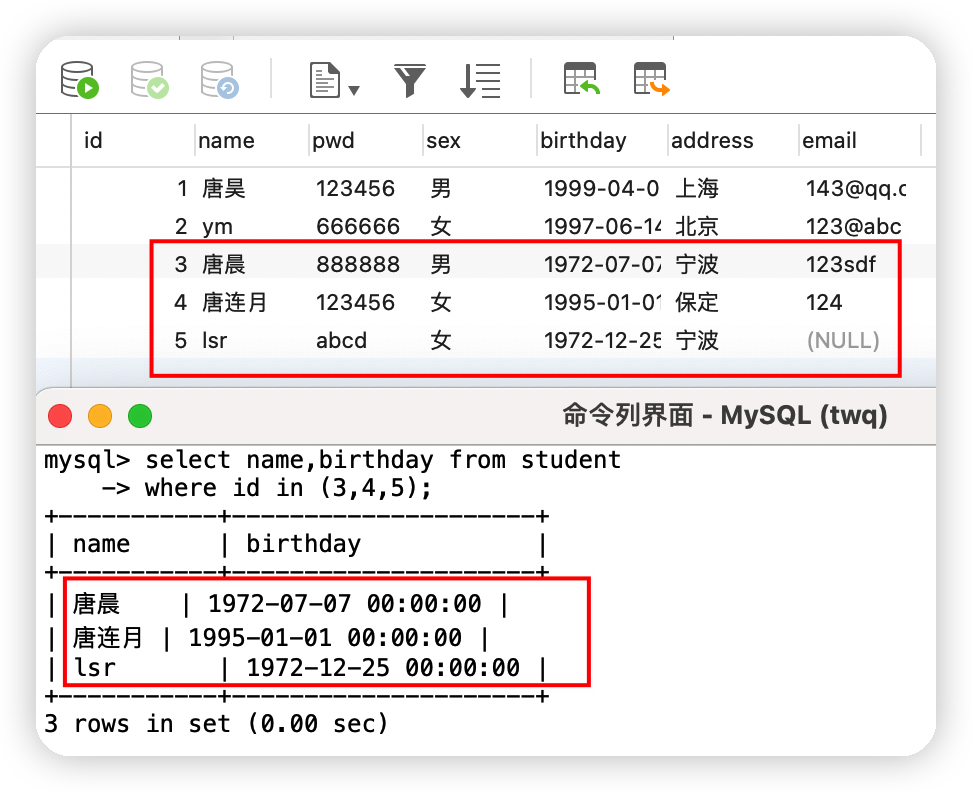
⑥查詢家住在寧波和上海的學生
select name,address from student
where address in ('寧波','上海');

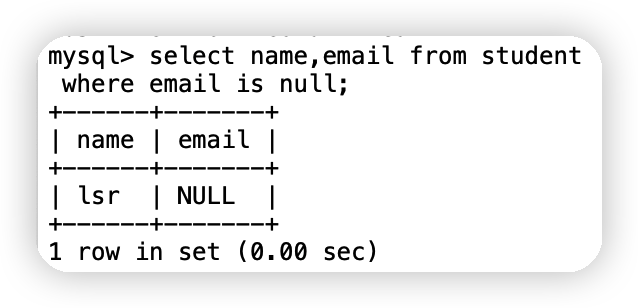
⑦查詢郵箱為空的學生
select name,email from student
where email is null;
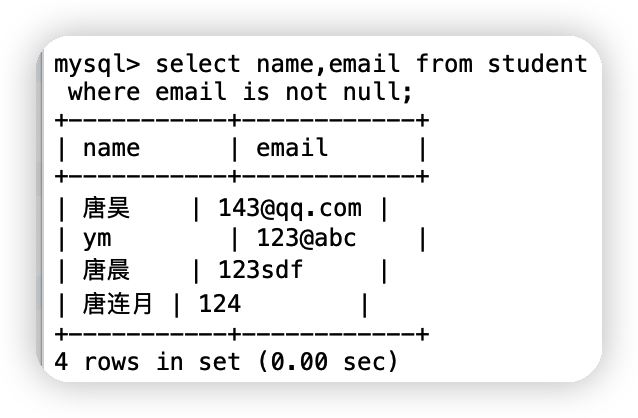
⑧查詢郵箱不為空的同學
select name,email from student
where email is not null;
5.3聯表查詢
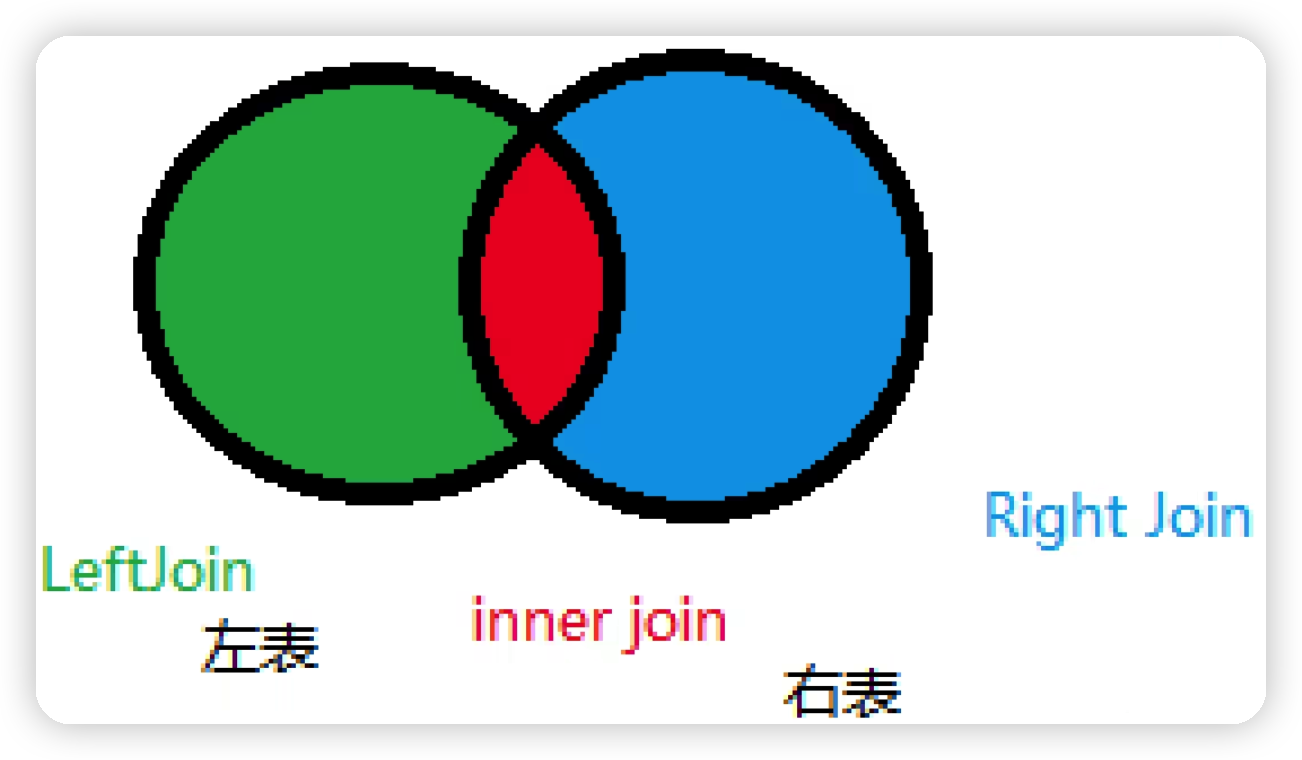
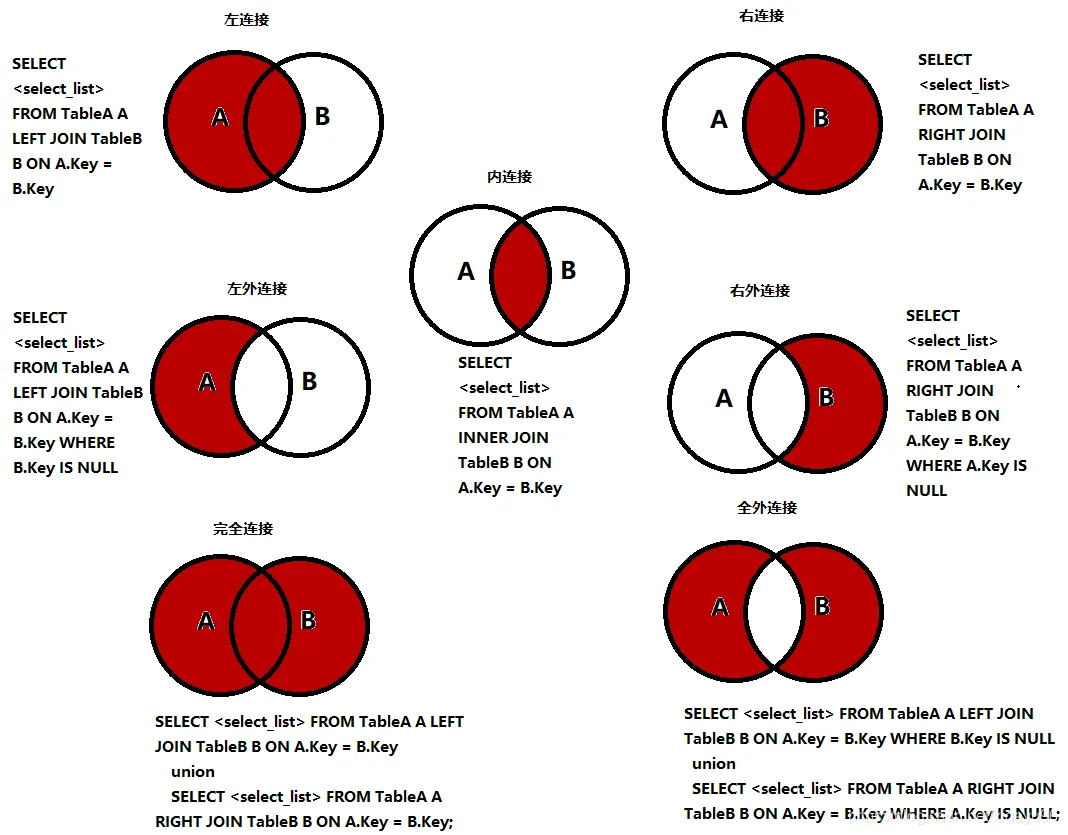
(1)join對比
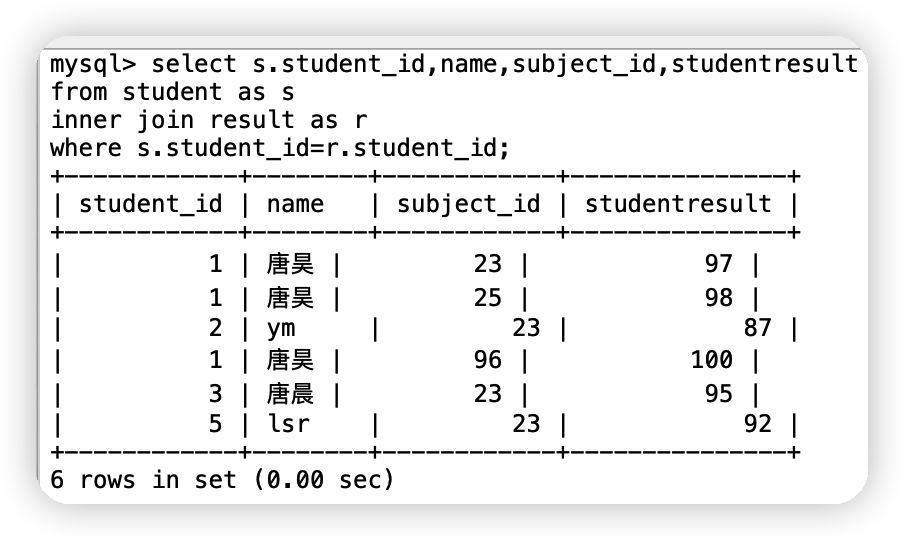
①查詢參加了考試的同學(學號,姓名,科目編號,分數)使用inner join來查詢
思路:
-
分析需求,分析查詢的欄位來自哪些表,(連接查詢)
-
確定使用哪種連接查詢? 7種
-
確定交叉點(這兩個表中那個資料是相同的)判斷條件:學生表中的student_id = 成績表的student_id
-- 這里給student表和result表起別名,就是因為這兩張表中都有student_id這個屬性,為了不扯皮,所以起別名并寫明用哪個表的id
select s.student_id,name,subject_id,studentresult
from student as s
inner join result as r
where s.student_id=r.student_id;
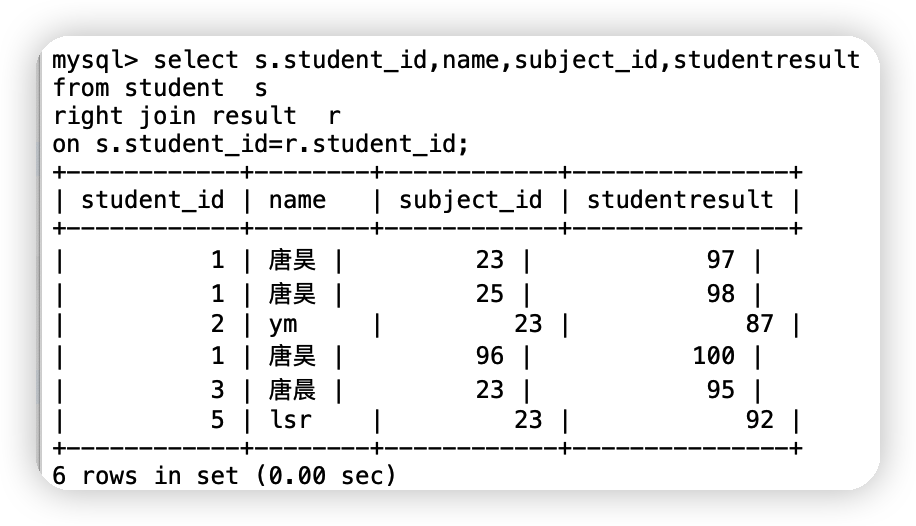
②使用right join來實作上述操作
join(連接的表) on(判斷的條件) 連接查詢
where 等值查詢
select s.student_id,name,subject_id,studentresult
from student s
right join result r
on s.student_id=r.student_id;
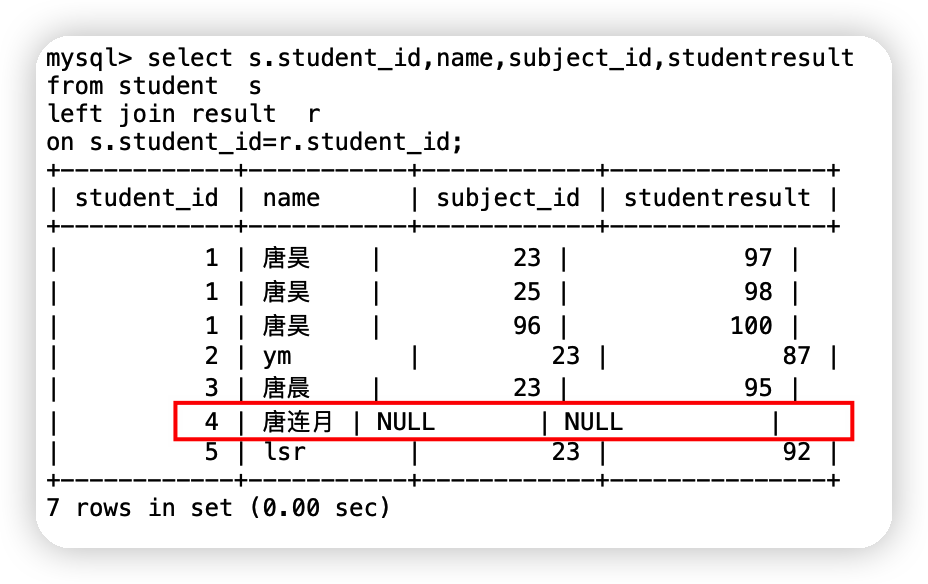
③使用left join操作上述問題
select s.student_id,name,subject_id,studentresult
from student s
left join result r
on s.student_id=r.student_id;
由結果可知left join會將沒有參與考試的學生也查了出來
| 操作 | 描述 |
|---|---|
| inner join | 如果表中至少有一個匹配,就回傳行(hang) |
| left join | 會從左表中回傳所有的值 ,即使右表中沒有匹配 |
| right join | 會從右表中回傳所有的值 ,即使左表中沒有匹配 |
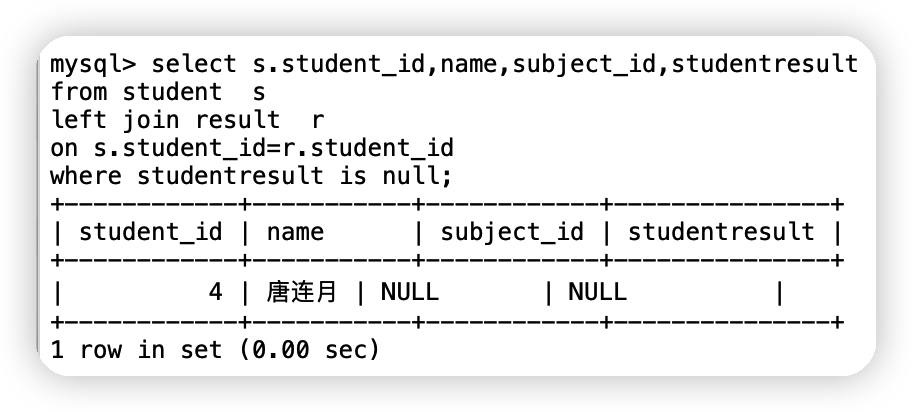
| ④查詢缺考的同學 |
select s.student_id,name,subject_id,studentresult
-- 起別名的時候as也可以省略
from student s
left join result r
on s.student_id=r.student_id
where studentresult is null;
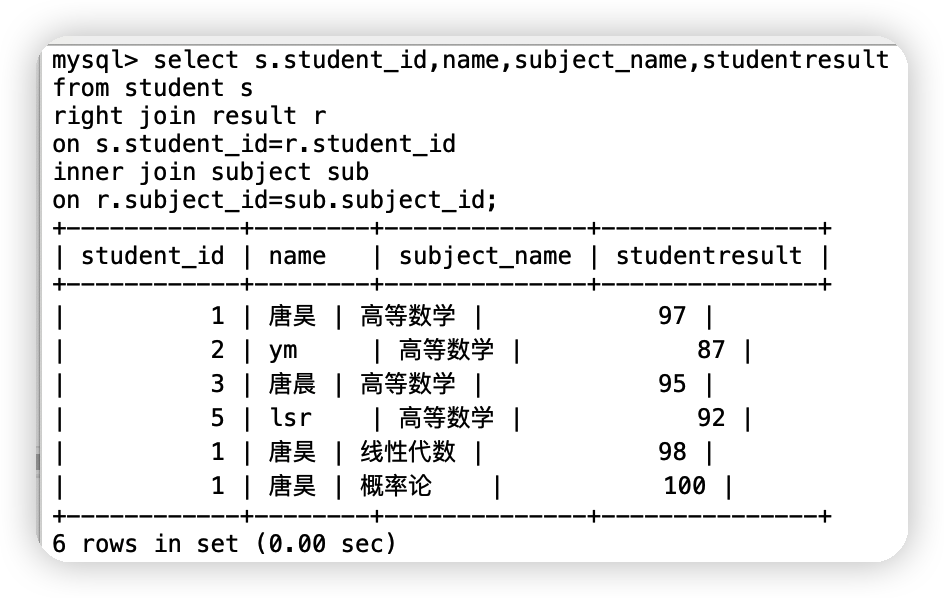
⑤查詢參加了考試的同學的資訊:學號,姓名,科目名,分數
思路:
-
分析需求,分析查詢的欄位來自哪些表,student,result,subject(連接查詢)
-
確定使用哪種連接查詢? 7種
-
確定交叉點(這兩個表中那個資料是相同的)判斷條件:學生表中的student_id = 成績表的student_id ,成績表中的subject_id =科目表中的subject_id;
select s.student_id,name,subject_name,studetresult
from student s
right join result r
on s.student_id=r.student_id
inner join subject sub
on r.subject_id=sub.subject_id;
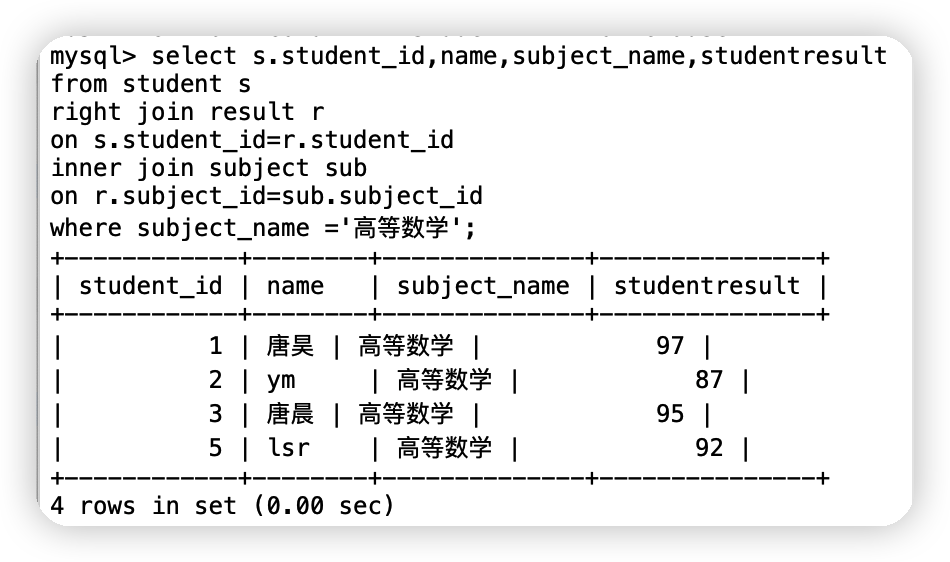
⑥查詢參加了高等數學考試的同學的資訊:學號,姓名,科目名,分數
select s.student_id,name,subject_name,studentresult
from student s
right join result r
on s.student_id=r.student_id
inner join subject sub
on r.subject_id=sub.subject_id
where subject_name ='高等數學';
總結:
-
我要查詢哪些資料 select.....
-
從哪幾個表中查 from 表 xxx join 連接的表 on 交叉條件
-
假設存在一種多張表查詢,慢慢來,先查詢兩張表然后再慢慢增加
(2)自連接
自己的表和自己的表連接,核心:一張表拆為兩張一樣的表即可 對于下面這張表進行拆分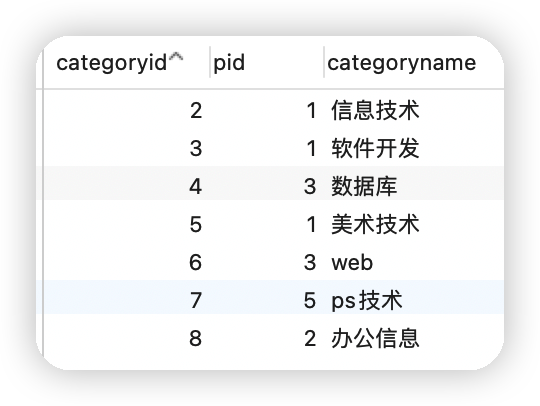
父類(找pid等于1的為一棵樹的最頂端)
| categoryid | categoryname |
|---|---|
| 2 | 資訊技術 |
| 3 | 軟體開發 |
| 5 | 美術技術 |
子類
| pid | categoryid | categoryname |
|---|---|---|
| 3 | 4 | 資料庫 |
| 3 | 6 | web |
| 5 | 7 | ps技術 |
| 2 | 8 | 辦公資訊 |
①操作:查詢父類對應的子類關系
| 父欄目 | 子欄目 |
|---|---|
| 資訊技術 | 辦公資訊 |
| 軟體開發 | 資料庫 |
| 軟體開發 | web |
| 美術技術 | ps技術 |
采用聯表查詢得到上表只需要讓父類的categoryid等于子類的pid即可
//將一張表看成一模一樣的表
select a.categoryname as 父欄目,b.categoryname as 子欄目
from category as a,category as b
where a.categoryid = b.pid;

5.4分頁(limit)和排序(order by)
(1)排序
①升序asc
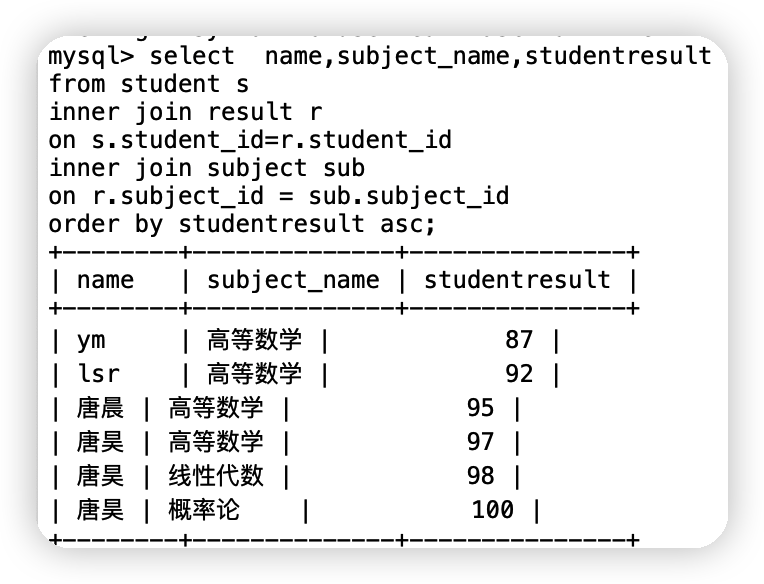
查詢參加了考試同學的資訊(姓名,考試科目,成績)并將成績按從小到大排序select name,subject_name,studentresult
from student s
inner join result r
on s.student_id=r.student_id
inner join subject sub
on r.subject_id = sub.subject_id
order by studentresult asc;
②降序desc
只需在上述例子中將asc改為desc即可(2)分頁
語法:==limit(查詢起始下標,pagesize)==第一頁: limit 0,5 起始查詢下標:(1-1)5
第二頁: limit 5,5 起始查詢下標:(2-1)5
第三頁: limit 10,5 起始查詢下標:(3-1)5
第N頁: limit (n-1)5,5 起始查詢下標:(n-1)*pagesize
pagesize:頁面大小
(n-1)*pagesize:起始查詢下標
n:當前頁
資料總數/頁面大小 = 總頁數
5.5子查詢
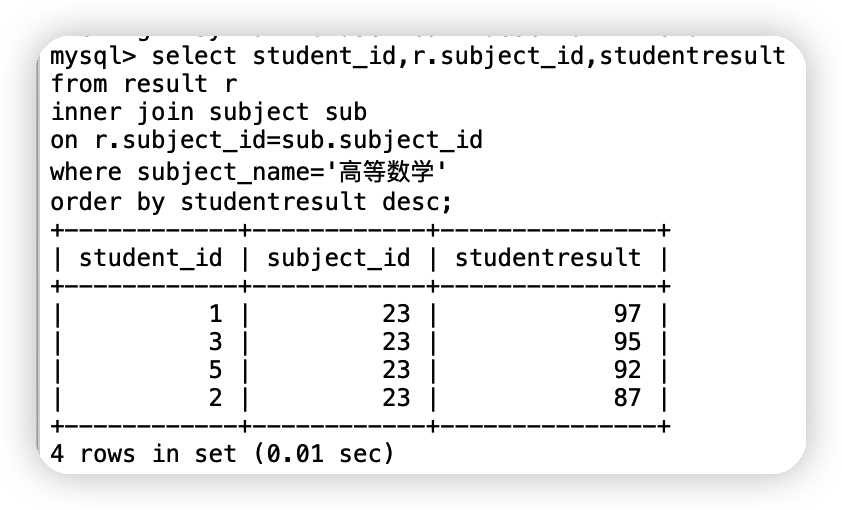
①查詢高等數學 的所有考試結果(學生id,科目編號,成績)降序排列 方式一:使用連接查詢select student_id,r.subject_id,studentresult
from result r
inner join subject sub
on r.subject_id=sub.subject_id
where subject_name='高等數學'
order by studentresult desc;
方式二:使用子查詢
select student_id,subject_id,studentresult
from result
where subject_id =(
select subject_id
from subject
where subject_name='高等數學'
);

六、MySQL函式
1.常用函式
①數學運算
-- 絕對值
select abs(-8)
-- 向上取整
select ceiling(9.4)
-- 向下取整
select floor(9.4)
-- 回傳一個0-1之間的亂數
select rand()
-- 判斷一個數的符號 0-0 回傳-1,正數回傳1
select sign(10)
②字串函式
-- 字串長度
select char length('發來的法計算')
-- 拼接字串
select concat('我','adf','asd')
-- 查詢,從某個位置開始替換某個長度
select insert('我愛變成helloworld',1,2,'超級熱愛')
-- 小寫字母
select lower('KjfdsSJK')
-- 大寫字母
select upper('KjfdsSJK')
-- 回傳第一次出現的子串的索引
select instr('twq123','3')
-- 替換出現的指定字串
select replace('堅持就是勝利','堅持','努力')
-- 回傳指定的字串(源字串,截取的位置,截取的長度)
select substr('堅持就是勝利',3,2)
-- 反轉
select reverse('清晨我上馬')
運用
將姓唐的同學姓式改為姓湯
select replace(name,'唐','湯') from student
where name like '唐%';

③時間和日期函式
-- 獲取當前的日期
select current date()
-- 獲取當前日期
select curdate()
-- 獲取當前的時間
select now()
-- 獲取本地時間
select localtime()
-- 獲取系統時間
select system()
select year(now())
select month(now())
select day(now())
select hour(now())
select minute(now())
select second(now())
--系統
select system_usr()
select user()
select version()
2.聚合函式(常用)
| 函式名稱 | 描述 |
|---|---|
| count() | 計數 |
| sum() | 求和 |
| avg() | 平均值 |
| max() | 最大值 |
| min() | 最小值 |
| .... |
查詢student表中一共有多少人
-- 都能夠統計,表中的資料(想查詢一個表中有多少個記錄,就是用這個count())
select count(name) from student -- count(欄位),會忽略所有的null值
select count(*) from student; -- count(*) 不會忽略null值 ,本質在計算行數
select count(1) from result; -- count(1) 不會忽略null值 ,本質在計算行數
select sum(studentresult) as 總和 from result
select avg(studentresult) as 平均分 from result
select max(studentresult) as 最高分 from result
select min(studentresult) as 最低分 from result
-- 查詢不同課程的平均分,最高分,最低分
-- 核心:(根據不同的課程分組)
select subject_name, avg(studentresult),max(studentresult),min(studentresult)
from result r
inner join subject sub
on r.subject_id =sub.subject_id
group by r.subject_id -- 通過什么欄位來分組
having 平均分>80; -- 分組之后再添加條件必須使用having,詳見select語法的圖

注意:執行以上命令可能會如果沒有修改MySQL的mode將會報以下錯誤
1055 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'school.sub.subject_name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
解決方式:
在Navicat或者sqlyog的命令中執行以下命令即可
SET sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
5.3資料庫級別的MD5加密(擴展)
-- 明文密碼
insert into testmd5 values(1,'zhanshan','123456'),(2,'lisi','abcdefg'),(3,'wangwu','asdfgh');

-- 加密
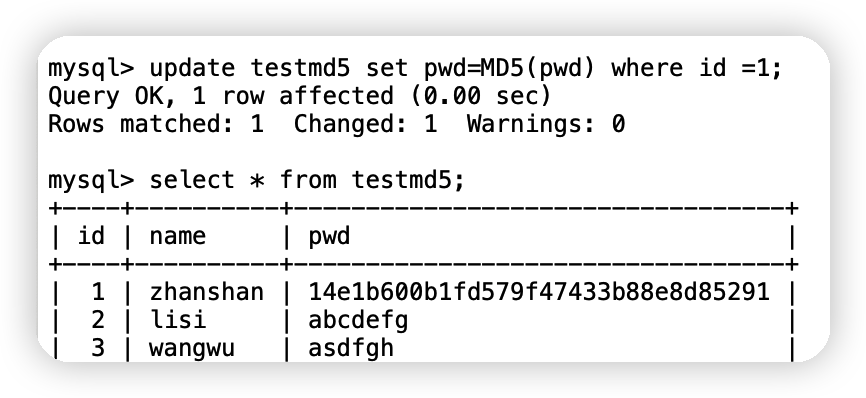
update testmd5 set pwd=MD5(pwd) where id =1; -- 對單個資料進行加密
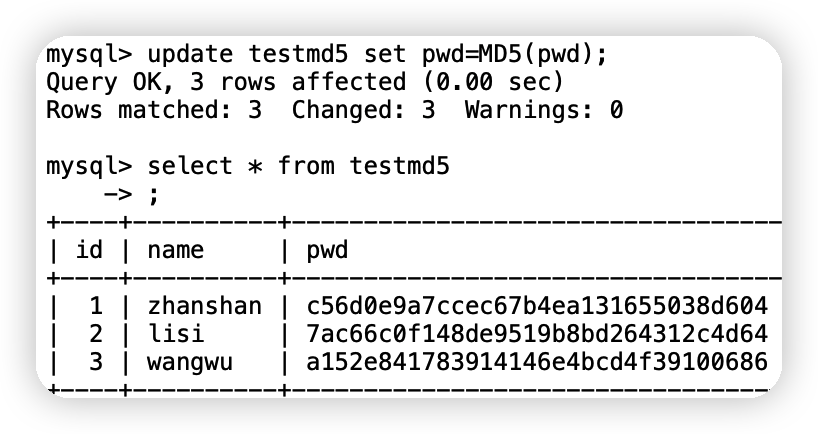
update testmd5 set pwd=MD5(pwd); -- 加密全部資料
-- 插入的資料的時候加密
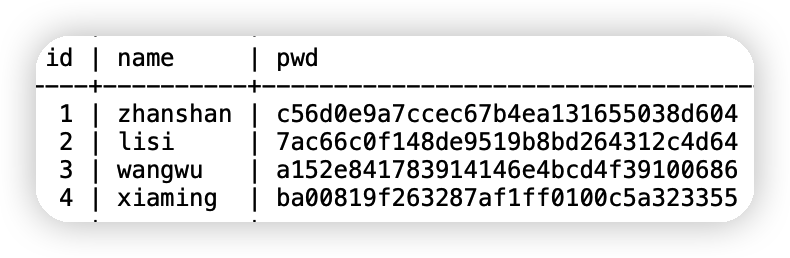
insert into testmd5 values(4,'xiaming',MD5('567890'));
七、事務
7.1什么是事務
要么都成功,要么都失敗就是下面這個轉賬的事務,必須要子啊兩條SQL執行完成之后該事務才算結束,體現事物的原子性
①、SQL執行 A給B轉賬 A最開始有1000 B最開始有200 A給B轉200
②、SQL執行 B收到A的錢 此時A有800 B有400
7.2事務原則
ACID 原則:原子性,一致性,隔離性,持久性(1)一致性
還是A給B轉賬這個事,事務完成后,符合邏輯運算也就是總錢數始終是1200(2)隔離性
所謂的獨立性是指并發(多個用戶同時操作)的事務之間不會互相影響,如果一個事務要訪問的資料正在被另外一個事務修改,只要另外一個事務未提交,它所訪問的資料就不受未提交事務的影響 隔離所導致的一些問題:①臟讀:
指一個事務讀取另外一個事務未提交的資料.
②不可重復讀:
在一個事務內讀取表中的某一行資料,多次讀取結果不同.(這個不一定是錯誤,只是某些場合不對).
③虛讀(幻讀):
是指在一個事務內讀取到了別的事務插入的資料,導致前后讀取不一致.
(3)持久性
事務因提交不可逆轉,被持久化到資料庫中
(4)事務的實際操作
-- MySQL是默認開啟事務自動提交的
set autocommit =0 -- 關閉
set autocommit =1; --開啟(默認的)
-- 手動處理事務
set autocommit =0 -- 關閉自動提交
-- 事務開啟
start transaction -- 標記一個事務的開始,從這個之后的sql都在同一個事務內
-- 提交:持久化(成功)
commit
-- 回滾:回到原來的樣子(失敗)
rollback
-- 事務結束
set autocommit=1 -- 開啟自動提交
(5)模擬事務場景
-- 創建一個轉賬的資料庫
create database shop character set utf8 collate utf8_general_ci;
-- 在此資料庫中創建表
create table account(
id int(3) not null auto_increment,
name varchar(20) not null,
money decimal(9,2) not null,
primary key(id)
)engine=innodb default charset=utf8;
--往表里添加資料
insert into account(name,money)
values('A',2000.00),('B',10000);
--模擬轉賬,事務
set autocommit =0; -- 關閉自動提交
start transaction; --開啟一個事務
update account set money=money-500 where name='A'; -- A減500
update account set money=money+500 where name='B'; -- B加500
commit; -- 提交事務
rollback; -- 回滾
set autocommit =1; -- 開啟自動提交
八、索引
索引的定義:索引是幫助MySQL高效獲取資料的資料結構,
提取句子主干,就可以得到索引的本質:索引就是資料結構
8.1索引的分類
在一個表中,主鍵索引只能有一個,唯一索引可以有多個- 主鍵索引(primary key)
- 唯一的標識,主鍵不可重復,只能有一個列作為主鍵
*唯一索引 (unique key)
-
避免重復列出現,唯一索引可以重復,多個列都可以標識唯一索引
-
常規索引(key / index)
- 默認的,index,key關鍵字來設定
-
全文索引(fulltext)
- 快速定位資料
(1)索引的使用
-- 索引的使用
-- 1.在創建表的時候給欄位增加索引
-- 2.創建完畢后,增加索引
show index from student; -- 顯示所有的索引資訊
-- 增加一個全文索引(索引名) 列名
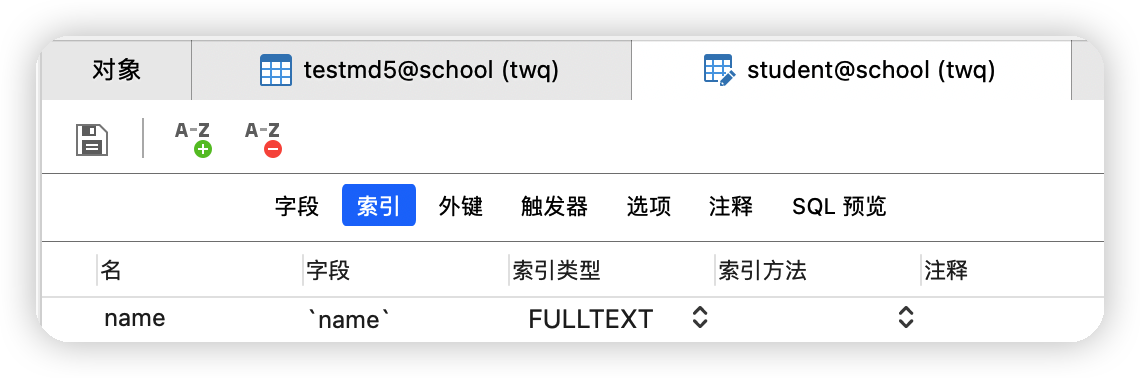
alter table school.student add fulltext index name (name);
-- explain 分析sql執行的狀況
explain select * from student;-- 非全文索引
explain select * from student where match(name) against('唐');
給student表中的name添加欄位之后結果圖
8.2測驗索引
~~~sql -- 插入100萬條資料 -- 寫函式之前必須要寫,標志 delimiter $$ create function mock_data() returns int begin declare num int default 1000000; declare i int default 0;while i <num do
insert into app_user(name,email,phone,gender,password,age)
values(concat('用戶',i),'[email protected]',concat('18',floor(rand()((999999999-100000000)+100000000))),floor(rand()2),uuid(),floor(rand()*100));
set i =i+1;
end while;
return i;
end;
執行上述函式可能會報以下錯誤
1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
解決方式:
臨時解決方法(重啟MySQL后失效):
在命令列界面執行以下命令
~~~sql
set global log_bin_trust_function_creators=TRUE;
永久解決方法:
在組態檔/etc/my.cnf的[mysqld]配置log_bin_trust_function_creators=1
8.3索引的原則
-
索引不是越多越好
-
不要對行程變動資料加索引
-
小資料量的表不需要加索引
-
索引一般加在常用來查詢的欄位上
(1)索引的資料結構
Hash型別的索引 Btree:innodb的默認資料結構九、資料庫備份
十、權限管理
1.用戶管理
十一、資料庫的規約,三大范式
十二、JDBC
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499804.html
標籤:其他
上一篇:資料庫持久化+JDBC資料庫連接
下一篇:MySQL實戰45講 1,2