04 | 深入淺出索引(上)
索引的出現其實就是為了提高資料查詢的效率,就像書的目錄一樣
索引的常見模型
哈希表、有序陣列和搜索樹
哈希表
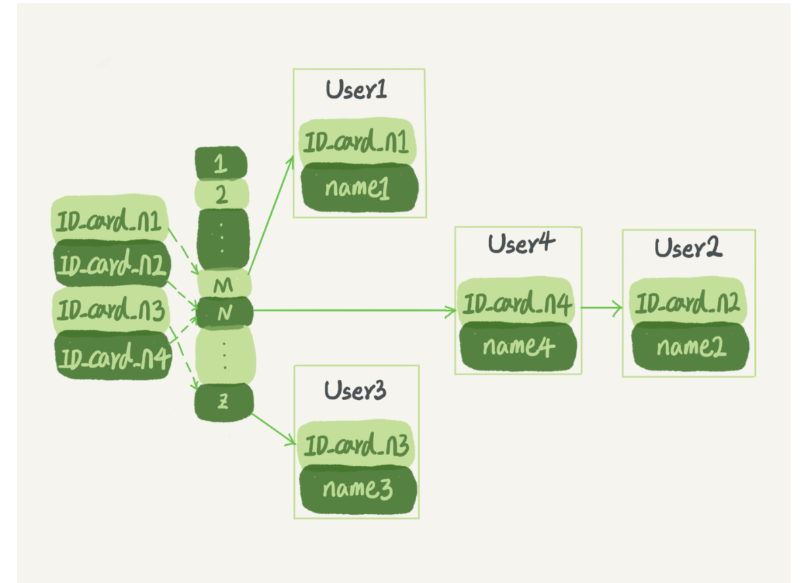
User2 和 User4 根據身份證號算出來的值都是 N,但沒關系,后面還跟了一個鏈表,
需要注意的是,圖中四個 ID_card_n hash 出來的值并不是遞增的,這樣做的好處是增加新的 User 時速度會很快,只需要往后追加,但缺點是,因為不是有序的,所以哈希索引做區間查詢的速度是很慢的,需要全部掃描一遍,
所以,哈希表這種結構適用于只有等值查詢的場景,比如 Memcached 及其他一些 NoSQL 引擎,
有序陣列
有序陣列在等值查詢和范圍查詢場景中的性能就都非常優秀
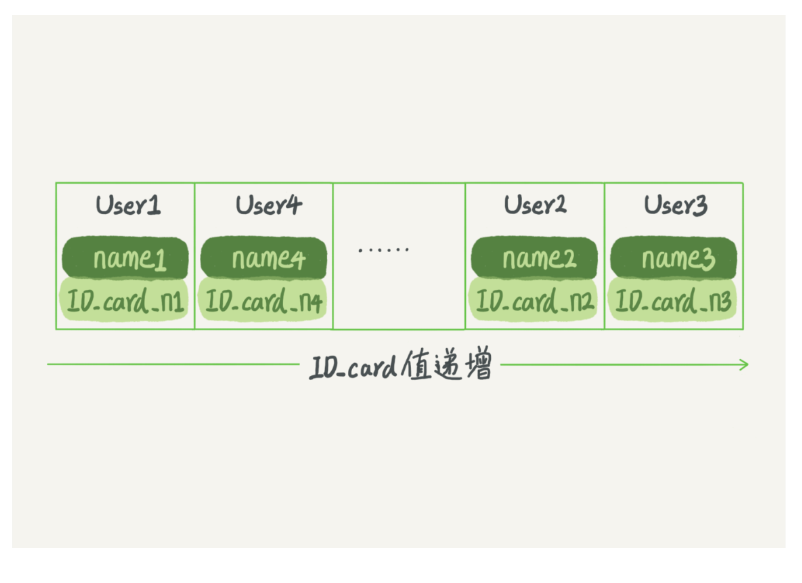
陣列就是按照身份證號遞增的順序保存的,這時候如果你要查 ID_card_n2 對應的名字,用二分法就可以快速得到,這個時間復雜度是 O(log(N))
同樣可以通過二分找到大于范圍和小于范圍的兩個值
更新資料的時候必須得挪動后面所有的記錄,成本太高
有序陣列索引只適用于靜態存盤引擎
二叉樹
二叉搜索樹:一棵空樹,或者是具有下列性質的二叉樹:若它的左子樹不空,則左子樹上所有結點的值均小于它的根結點的值;若它的右子樹不空,則右子樹上所有結點的值均大于它的根結點的值;二叉搜索樹的左、右子樹也分別為二叉搜索樹,
平衡二叉樹:平衡二叉樹是在二叉搜索樹的基礎上引入的,指的是結點的左子樹和右子樹的深度差不超過 1.
多叉樹:每個結點可以有多個子結點,子節點的大小從左到右依次遞增,
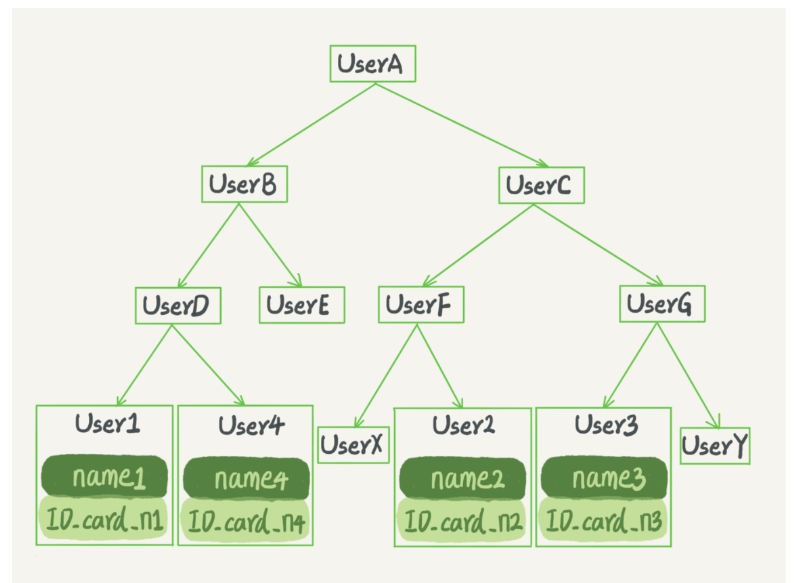
二叉搜索樹的特點是:每個節點的左兒子小于父節點,父節點又小于右兒子,這樣如果你要查 ID_card_n2 的話,按照圖中的搜索順序就是按照 UserA -> UserC -> UserF -> User2 這個路徑得到,這個時間復雜度是 O(log(N))
當然為了維持 O(log(N)) 的查詢復雜度,你就需要保持這棵樹是平衡二叉樹,為了做這個保證,更新的時間復雜度也是 O(log(N))
一棵 100 萬節點的平衡二叉樹,樹高 20,一次查詢可能需要訪問 20 個資料塊
Q:為什么樹高20就是20個資料塊?
A:每個葉子結點就是一個塊,每個塊包含兩個資料(?),塊之間通過鏈式方式鏈接,樹高20的話,就要遍歷20個塊,因為是二叉樹結構,每次指標查找很大概率是觸發隨機磁盤讀(比如很難剛好碰上一個節點和他的左右兒子剛好相鄰)
資料庫中的所有資料都存盤于資料塊中,而葉子節點塊只是資料塊的一種,因為它位于索引b*tree結構中的最末端(root(根)-->branch(分枝)-->leaf(葉子)),所以,就稱為葉子節點塊(leaf node block)
《個人理解》參照下面的B+樹,一個葉子塊中可以存放多條索引和資料
為了讓一個查詢盡量少地讀磁盤,就必須讓查詢程序訪問盡量少的資料塊,那么,我們就不應該使用二叉樹,而是要使用“N 叉”樹,這里,“N 叉”樹中的“N”取決于資料塊的大小,
Q:B+樹是一顆N叉樹,N是由什么決定的?能否調整?
A:
-
通過修改page的大小來間接調整N的大小,一個節點上的所有資料都在一個page中,頁越大,每頁存放的索引就越多,N就越大,資料頁調整后,如果資料頁太小層數會太深,資料頁太大,加載到記憶體的時間和單個資料頁查詢時間會提高,需要達到平衡才行,
-
修改索引的大小,每個索引包括固定位元組數的Point指標和索引欄位內容,索引欄位越小,每頁能存的索引就越多,N就越大,
以 InnoDB 的一個整數欄位索引為例,這個 N 差不多是 1200,這棵樹高是 4 的時候,就可以存 1200 的 3 次方個值,這已經 17 億了,考慮到樹根的資料塊總是在記憶體中的,一個 10 億行的表上一個整數欄位的索引,查找一個值最多只需要訪問 3 次磁盤,其實,樹的第二層也有很大概率在記憶體中,那么訪問磁盤的平均次數就更少了,
InnoDB 的索引模型
在 InnoDB 中,表都是根據主鍵順序以索引的形式存放的,這種存盤方式的表稱為索引組織表,
InnoDB 使用了 B+ 樹索引模型,所以資料都是存盤在 B+ 樹中的,
假設,我們有一個主鍵列為 ID 的表,表中有欄位 k,并且在 k 上有索引,
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分別為 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),兩棵樹的示例示意圖如下,
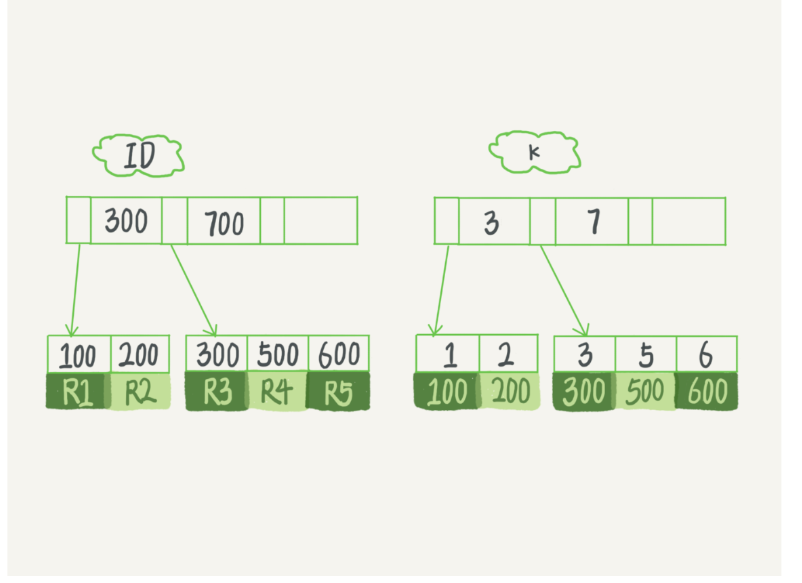
索引型別分為主鍵索引和非主鍵索引
主鍵索引的葉子節點存的是整行資料,在 InnoDB 里,主鍵索引也被稱為聚簇索引(clustered index),
非主鍵索引的葉子節點內容是主鍵的值,在 InnoDB 里,非主鍵索引也被稱為二級索引(secondary index),
Q:基于主鍵索引和普通索引的查詢有什么區別?
A:
- 如果陳述句是 select * from T where ID=500,即主鍵查詢方式,則只需要搜索 ID 這棵 B+ 樹;
- 如果陳述句是 select * from T where k=5,即普通索引查詢方式,則需要先搜索 k 索引樹,得到 ID 的值為 500,再到 ID 索引樹搜索一次,這個程序稱為回表,
索引維護
B+ 樹為了維護索引有序性,在插入新值的時候需要做必要的維護,
以上面這個圖為例,
如果插入新的行 ID 值為 700,則只需要在 R5 的記錄后面插入一個新記錄,
如果新插入的 ID 值為 400,就相對麻煩了,需要邏輯上挪動后面的資料,空出位置,
而更糟的情況是,如果 R5 所在的資料頁已經滿了,根據 B+ 樹的演算法,這時候需要申請一個新的資料頁,然后挪動部分資料過去,這個程序稱為頁分裂,
當相鄰兩個頁由于洗掉了資料,利用率很低之后,會將資料頁做合并,
Q:如果插入的資料是在主鍵樹葉子結點的中間,后面的所有頁如果都是滿的狀態,是不是會造成后面的每一頁都會去進行頁分裂操作,直到最后一個頁申請新頁移過去最后一個值?
A: 不會不會,只會分裂它要寫入的那個頁面,每個頁面之間是用指標串的,改指標就好了,不需要“后面的全部挪動
ps:資料塊和資料頁的含義應該是一致的
自增主鍵
自增主鍵是指自增列上定義的主鍵,在建表陳述句中一般是這么定義的: NOT NULL PRIMARY KEY AUTO_INCREMENT,
好處:(存,查,插)
- 插入新記錄的時候可以不指定 ID 的值,系統會獲取當前 ID 最大值加 1 作為下一條記錄的 ID 值,每次插入一條新記錄,都是追加操作,都不涉及到挪動其他記錄,也不會觸發葉子節點的分裂,
- 自增欄位為整形或長整型,每個非主鍵索引的葉子節點上都是主鍵的值,主鍵長度越小,普通索引的葉子節點就越小,普通索引占用的空間也就越小,
- 業務邏輯欄位不容易保證索引樹結點有序插入,這樣寫入成本較高,
Q:有沒有什么場景適合用業務欄位直接做主鍵的呢?
A:典型的 KV 場景
-
只有一個索引;
-
該索引必須是唯一索引
這時候我們就要優先考慮上一段提到的“盡量使用主鍵查詢”原則,直接將這個索引設定為主鍵,可以避免每次查詢需要搜索兩棵樹,
自增ID用完了怎么辦?
https://www.modb.pro/db/131380
表的自增 id 達到上限后,再申請時它的值就不會改變,進而導致繼續插入資料時報主鍵沖突的錯誤
索引重建
重建普通索引時,直接先洗掉索引,再重新創建即可,
alter table T drop index k;
alter table T add index(k);
主鍵索引不能通過上面的陳述句去重建,因為洗掉主鍵索引后,innodb會如下處理:
- 如果存在非空且欄位型別為數值的唯一索引(INT and NOT NULL and UNIQUE INDEX), 會將第一個滿足條件的索引作為主鍵索引, _rowid為對應主鍵,值與唯一索引相同,(可通過
select _rowid from table查詢), - 如果找不到合適的索引,那么 InnoDB 會自動生成一個不可見的名為 ROW_ID 的列名為 GEN_CLUST_INDEX 的主鍵索引,該列是一個 6 位元組的自增數值,隨著插入而自增,
所以洗掉主鍵索引的結果其實是修改了主鍵欄位,而普通索引的葉子節點存的是主鍵的值,所以,一旦修改了主鍵欄位,普通索引也會有影響,葉子節點的值將被修改成新的主鍵欄位,
當主鍵索引需要重建時,更好的做法是直接使用alter table t engine=innodb重建表,
05 | 深入淺出索引(下)
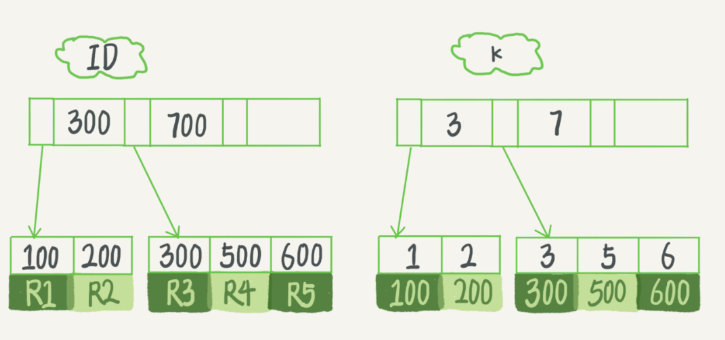
Q :執行 select * from T where k between 3 and 5,需要執行幾次樹的搜索操作,會掃描多少行?
A:
- 在 k 索引樹上找到 k=3 的記錄,取得 ID = 300;
- 再到 ID 索引樹查到 ID=300 對應的 R3;
- 在 k 索引樹取下一個值 k=5,取得 ID=500;
- 再回到 ID 索引樹查到 ID=500 對應的 R4;
- 在 k 索引樹取下一個值 k=6,不滿足條件,回圈結束,
由于查詢結果所需要的資料只在主鍵索引上有,所以不得不回表,那么,有沒有可能經過索引優化,避免回表程序呢?
覆寫索引
如果執行的陳述句是 select ID from T where k between 3 and 5,這時只需要查 ID 的值,而 ID 的值已經在 k 索引樹上了,因此可以直接提供查詢結果,不需要回表,也就是說,在這個查詢里面,索引 k 已經“覆寫了”我們的查詢需求,我們稱為覆寫索引,
由于覆寫索引可以減少樹的搜索次數,顯著提升查詢性能,所以使用覆寫索引是一個常用的性能優化手段,
在高頻請求考慮建立聯合索引(例如:(身份證號、姓名)),就是用到了覆寫索引,不再需要回表查整行記錄,減少陳述句的執行時間,
最左前綴原則
「聯合索引的多個欄位中,只有當查詢條件為聯合索引的第一個欄位時,查詢才能使用該索引,」
這個最左前綴可以是聯合索引的最左 N 個欄位
「索引可以根據欄位值最左若干個字符進行模糊查詢,」
分析(name,age)這個聯合索引,可以看到,索引項是按照索引定義里面出現的欄位順序排序的,當你的邏輯需求是查到所有名字是“張三”的人時,可以快速定位到 ID4,然后向后遍歷得到所有需要的結果,如果你要查的是所有名字第一個字是“張”的人,你的 SQL 陳述句的條件是"where name like ‘張 %’",這時,你也能夠用上這個索引,查找到第一個符合條件的記錄是 ID3,然后向后遍歷,直到不滿足條件為止,
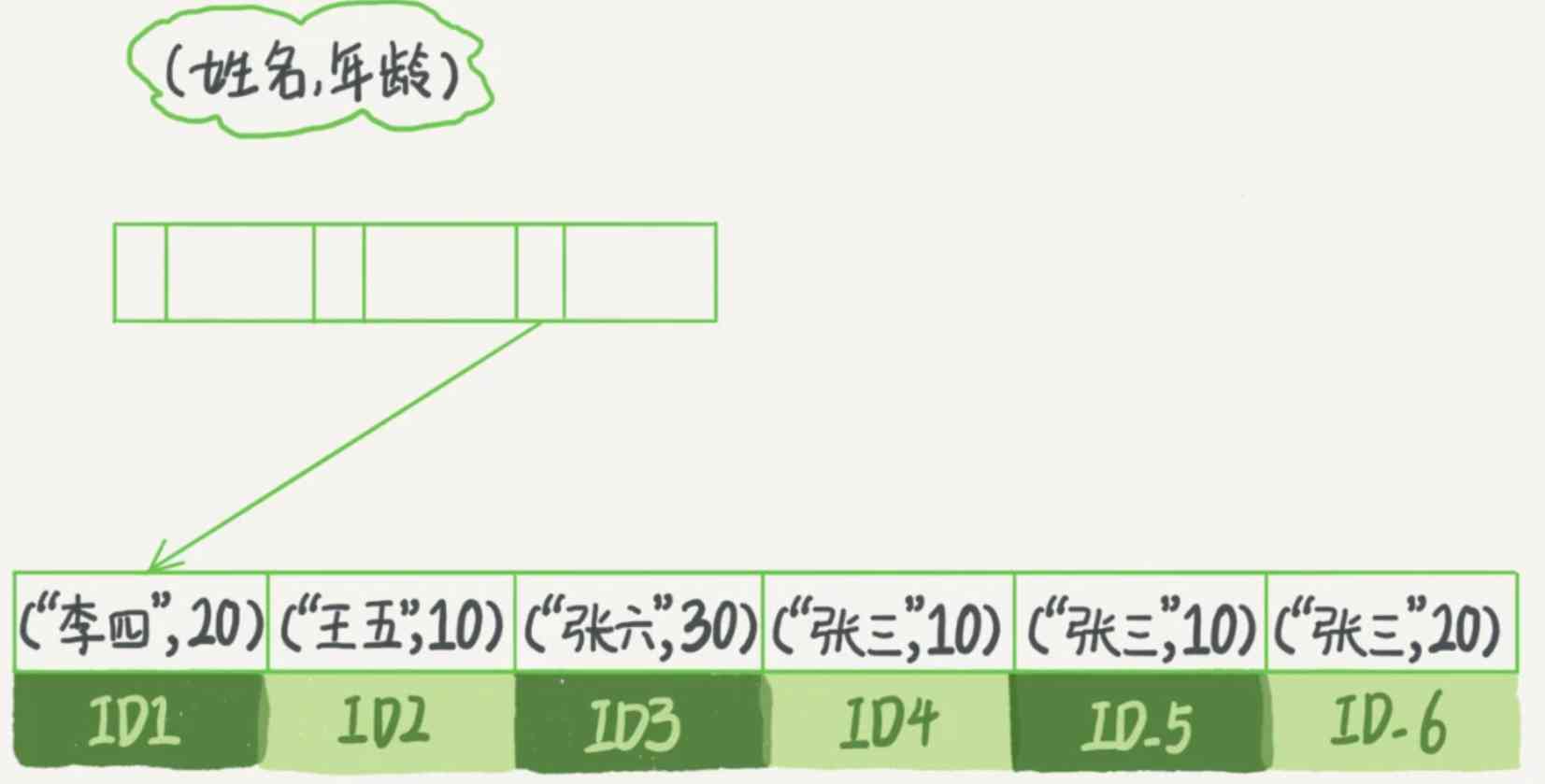
現在,假設我們有一下三種查詢情景:
- 查出用戶名的第一個字是 “張” 開頭的人的密碼,即查詢條件子句為 "where username like ' 張 %'"
- 查處用戶名中含有 “張” 字的人的密碼,即查詢條件子句為 "where username like '% 張 %'"
- 查出用戶名以 “張” 字結尾的人的密碼,即查詢條件子句為 "where username like '% 張 '"
以上三種情況下,只有第 1 種能夠使用(username,password)聯合索引來加快查詢速度,
Q:表id為主鍵,username為普通索引,問select id, username from user_table where username like '%張%' 能否使用到 (username) 索引?
A:答案是可以的,因為查詢的所有欄位 (id, username) 在二級索引(username)中都存在,二級索引樹比主鍵索引樹小很多,所以會直接遍歷二級索引,值得注意的是,這里是遍歷整個索引樹,而不是在索引樹中快速定位資料,
前綴索引
Q:需要根據 email 欄位查找用戶資訊的需求,當然我們可以直接給 email 欄位創建一個索引,但我們仔細想想,有必要為整個 email 欄位創建索引嗎?
A:其實沒必要的,因為郵箱地址是有一個格式的,都是 "[email protected]", 所以其實 email 欄位的后面幾位區分度不高,這時為整個 email 欄位創建索引很浪費空間,我們可以創建前綴索引,將欄位的前幾個字符作為索引即可,
mysql 中使用 ADD KEY (column_name (prefix_length)) 為欄位創建前綴索引,
前綴索引設計的好壞在于選擇合適的前綴索引長度,如果選擇太長,會造成索引空間的浪費;如果選擇太短,會導致索引樹大量重復的 key,索引效果不理想
問題:
- 使用前綴索引可能會增加記錄掃描次數與回表次數,影響性能
- 使用前綴索引就用不上覆寫索引對查詢性能的優化了
前綴索引的區分度不夠高怎么辦
一個很常見的解決手段就是 Hash,
對這個超長欄位 a 進行 hash(假設命名為 a_hash) 存入資料庫,然后對這個 hash 值建立索引,由于 hash 值同樣可能存在沖突,也就是說兩個不同的 a 通過 Hash 函式得到的結果可能是相同的,所以我們在查詢陳述句的 where 部分還需要進行一次精確判斷
索引下推
對于 user_table 表,我們現在有(username,age)聯合索引 如果現在有一個需求,查出名稱中以 “張” 開頭且年齡小于等于 10 的用戶資訊,陳述句 C 如下:
"select * from user_table where username like ' 張 %' and age > 10".
陳述句 C 會根據(username,age)聯合索引查詢所有滿足名稱以 “張” 開頭的索引,然后直接再篩選出年齡小于等于 10 的索引,之后再回表查詢全行資料
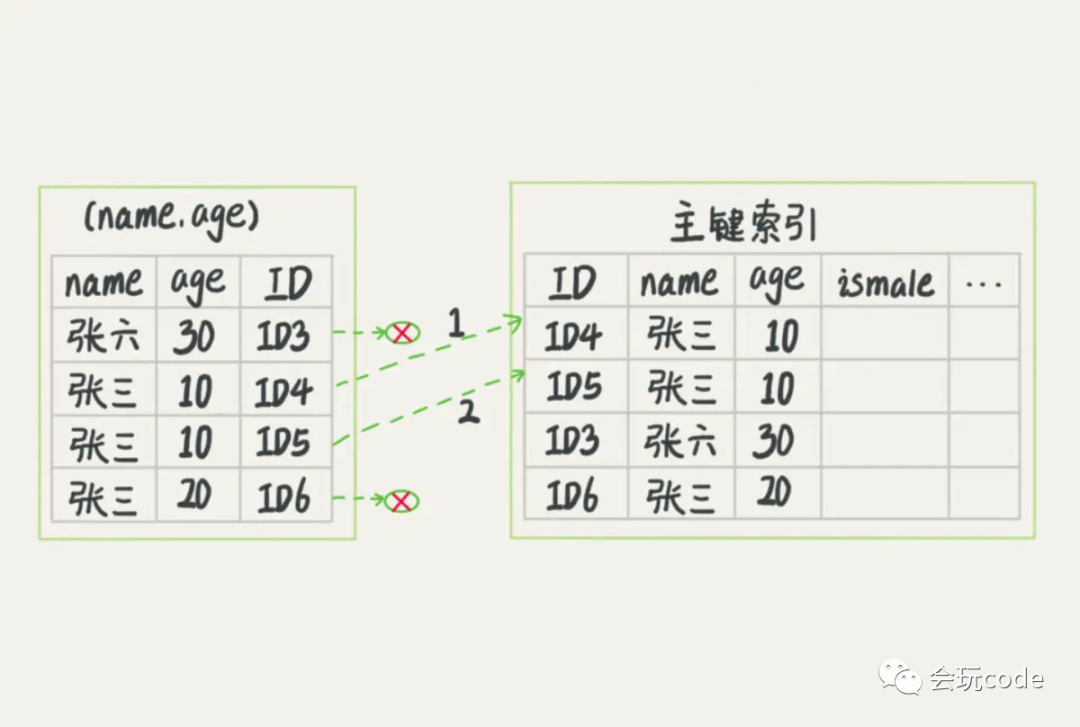
第二種方式需要回表查詢的全行資料比較少,這就是 mysql 的索引下推,在索引遍歷程序中,對索引中包含的欄位先做判斷,直接過濾掉不滿足條件的記錄,減少回表次數,
https://copyfuture.com/blogs-details/20211116185246587T#_157
https://mp.weixin.qq.com/s?__biz=MzI4MTc0NDg2OQ==&mid=2247483854&idx=1&sn=13a28d8754b2718d8e6a044492897b99
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499920.html
標籤:MySQL
上一篇:事務
下一篇:MySQL高可用安裝