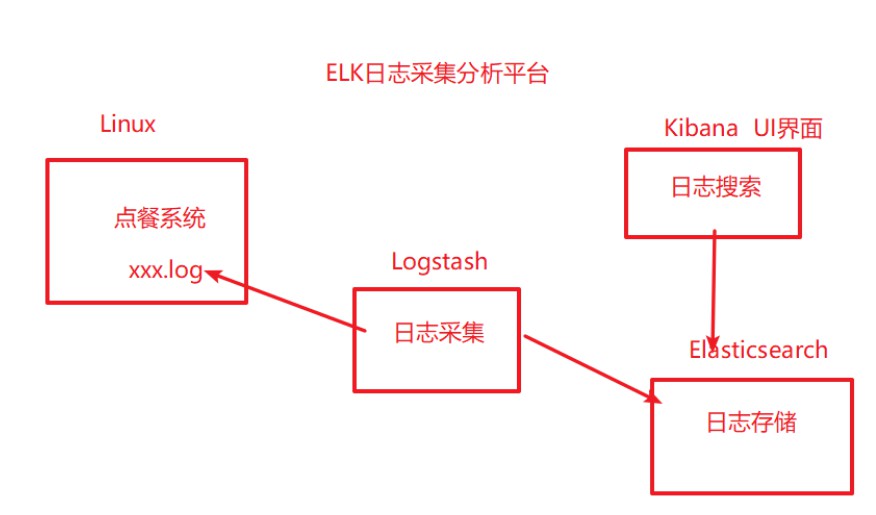
一、ElasticSearch的倒排索引
1.1、資料庫存在的問題
-
-
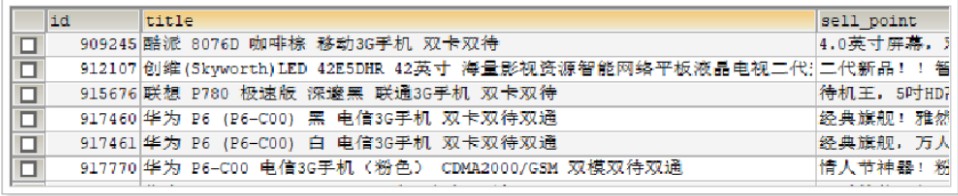
問題1: 查詢title中包含"手機"的資訊
-
SELECT * FROM goods WHERE title LIKE '%手機%' -
使用模糊搜索,左邊有通配符,不會走索引,會全表掃描,性能低
-
-
問題2:查詢title中包含"我要買一部華為手機"的資訊
-
SELECT * FROM goods WHERE title LIKE '%我要買一部華為手機%' -
關系型資料庫提供的查詢,功能太弱
-
1.2、倒排索引
了解倒排索引的存盤原理
-
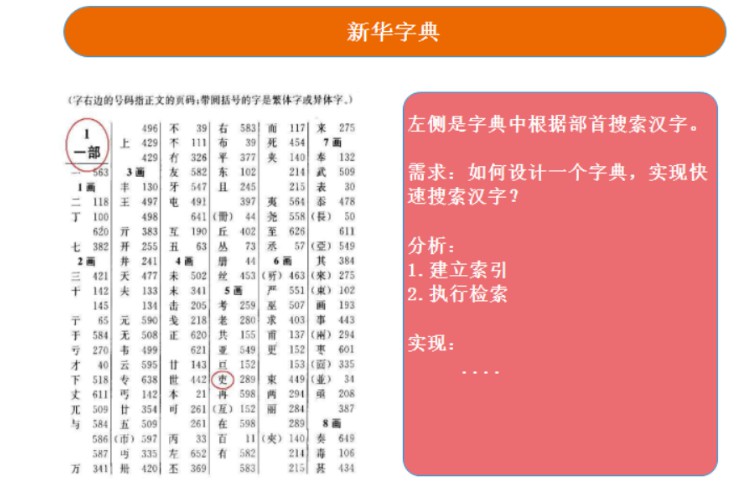
使用新華字典查找漢字,先找到漢字的偏旁部首,再根據偏旁部首對應的目錄(索引)找到目標漢字
-
ES樣例
- 檔案0(編號0):we like java java java
- 檔案1(編號1):we like lucene lucene lucene
-
建立倒排索引的流程
-
首先對所有資料的內容進行拆分(分詞),拆分成唯一的一個詞語(詞條Term)
-
然后建立詞條和每條資料的對應關系(詞條在檔案出現的位置下標,出現頻率),如下所示
-
(Term 詞條) (Doc ID,Freq 頻率) (Pos 位置) we (0,1) (1,1) (0,0)(1,0) like (0,1) (1,1) (0,1)(1,1) java (0,3) (2,3,4) lucene (1,3) (2,3,4)
-
-
小結
- 倒排索引:將每條資料中的內容進行分詞,形成詞條,然后記錄詞條和資料的唯一標識(id)的對應關系,形成的產物
二、ElasticSearch存盤和搜索原理
理解ElasticSearch存盤和搜索原理
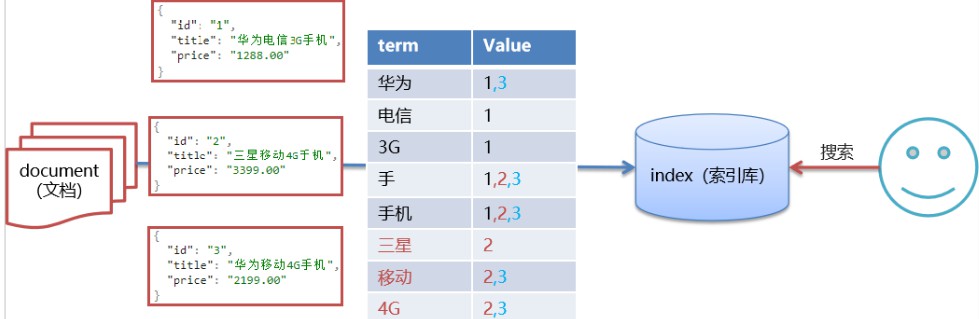
- 假設資料存在以下幾條資料
- ES中存盤以及搜索原理圖如下所示
- 說明
- ES的資料庫我們稱其為 index (索引庫),每條資料我們稱之為 document (檔案),ES在存盤檔案的時候,會對它需要分詞的欄位內容進行切分,切分成一個個詞條,再建立每個詞條與檔案唯一標識(id)的對應關系,即倒排索引
- 我們再回過頭看之間資料庫存在的兩個問題,通過ES是否能夠解決
- 問題1
- 性能低:使用模糊查詢,左邊有通配符,不會走索引,會全表掃描,性能低
- ES解決方案:如果使用"手機"作為關鍵字查詢,ES生成的倒排索引中,詞潭訓排序,形成一顆樹形結構,提升詞條的查詢速度
- 問題2
- 功能弱:如果以"華為手機" 作為條件,查詢不出來資料
- ES解決方案:如果使用"華為手機"作為關鍵字查詢,ES也可以對搜索的關鍵字進行分詞,比如將華為手機拆分成"華為"、"手機",然后根據兩個詞分詞去倒排索引中進行查詢,然后取結果的并集
- 問題1
三、ElasticSearch相關概念
理解ElasticSearch和關系型資料庫的區別以及分工
3.1、介紹
- ElasticSearch是Java語言開發的,并作為Apache許可條款下的開放原始碼發布,基于Lucene實作,是一款分布式、高擴展、近實時的搜索服務,可以基于RESTful web介面進行操作
- 官網:https://www.elastic.co/
- 基于Lucene的產品
- Slor:實時性偏弱,在高并發地寫入資料時,Slor需要頻繁地構建索引庫,而索引庫構建影響到查詢性能
- Elasticsearch:實時性非常強(近實時),ES在頻繁地構建索引庫的同時,不太影響查詢的性能
3.2、應用場景
- 海量資料的查詢(京東,淘寶商品搜素)
- 日志資料分析(ELK ElasticSearch + Logstach + Kibana 搭建日志監控平臺)
- 實時資料分析
3.3、ElasticSearch和MySQL的區別
-
我們可以把傳統關系型資料庫MySQL和ElasticSearch進行一下對比
-
MySQL Elasticsearch 說明 Database Index 索引(index),就是檔案的集合,類似資料庫(Database) Table Type 型別(Type),就是檔案的型別,相當于資料庫中的表(Table) Row Document 檔案(Document),就是一條條的資料,類似資料庫中的行(Row),檔案都是JSON格式 Column Field 欄位(Field),就是JSON檔案中的欄位,類似資料庫中的列(Column) Schema Mapping Mapping(映射)是索引中檔案的約束,例如欄位型別約束,類似資料庫的表結構(Schema) index Everything is indexed es對存盤的所有資料都進行分詞建立索引 SQL DSL(Domain Specification Lanuage)
-
-
不難發現,兩者均有其優勢
- MySQL:擅長事務型別操作,可以確保資料的安全和一致性,進行復雜的多表查詢
- ElasticSearch:擅長海量資料的搜索、分析、計算
-
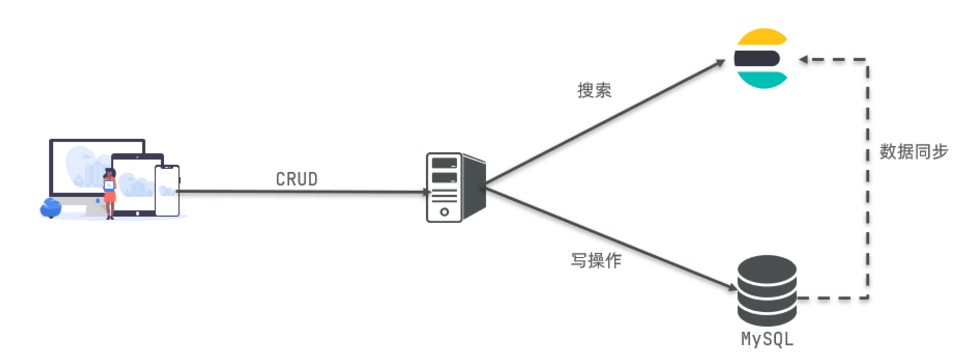
因此在企業中,往往是兩者結合使用
- 對安全性要求較高的寫操作,關系復雜的表需求,使用MySQL實作
- 對查詢性能要求較高的搜索需求,使用Elasticsearch實作
- 兩者再基于某種方式,實作資料的同步,保證資料一致性
3.4、小結
- 資料庫查詢存在的問題
- 性能低
- 功能較弱
- 倒排索引
- 將檔案中欄位的內容進行分詞,形成詞條和每條資料id的對應關系
- Elasticsearch概念以及作用
- 搜索服務器
- 高性能、功能強大
- 不是替換MySQL,es做搜索,MySQL做資料存盤
- 索引庫(index)= 資料庫
- 型別(type)= 表
- 映射(mapping)= 表結構
- 檔案(document)= 一行資料
- 映射引數(field)= 表欄位
四、ElasticSearch的安裝
4.1、下載鏡像
- 命令
docker pull elasticsearch:7.4.1
- 如下所示
- Windows下載很簡單,去官網下載,解壓后啟動即可使用
4.2、啟動容器
-
命令
-
docker run -di --name=elasticsearch -p 9200:9200 -v /root/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.type=single-node" elasticsearch:7.4.1 -
埠映射:9200
-
檔案夾映射:
/usr/share/elasticsearch/plugins -
添加環境變數,名為
discovery.type=single-node -
PS:可以暫時不用理解為什么映射這個檔案夾,以及后面的
"discovery.type=single-node"
-
-
如下所示

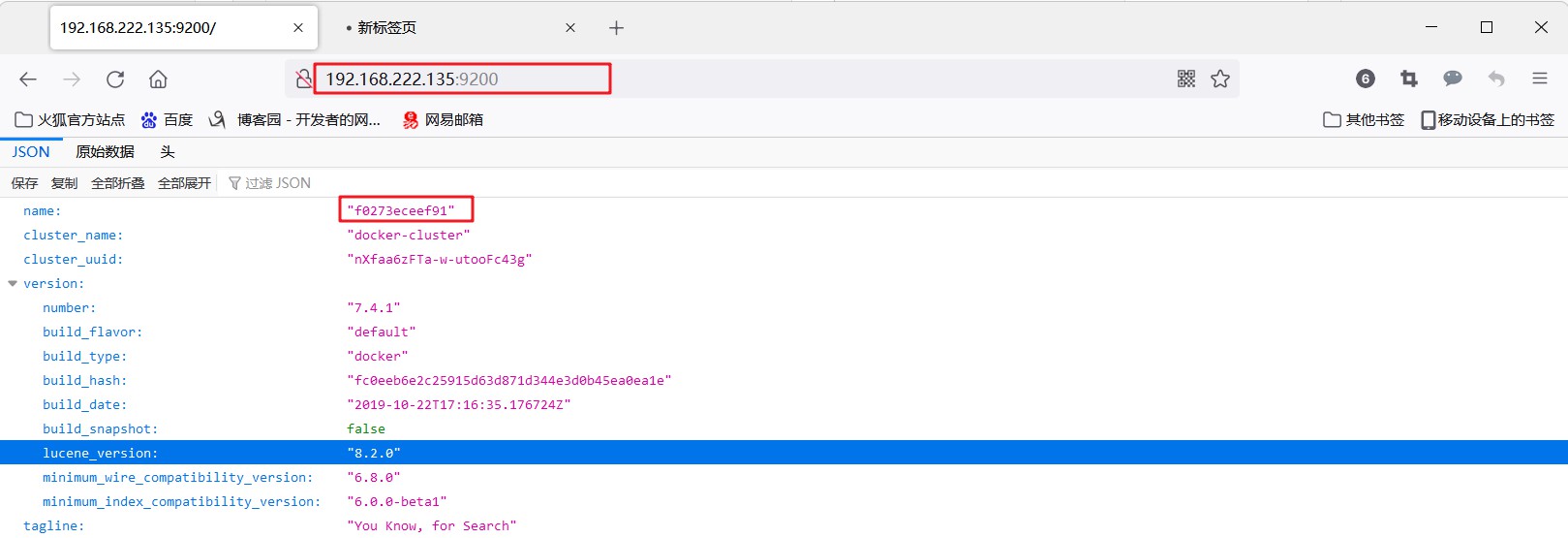
4.3、瀏覽器訪問
-
瀏覽器輸入:http:宿主機IP:9200
-
如果發現啟動失敗問題(記憶體分配原因),可以參考下面這個鏈接
-
日常踩坑之elasticsearch docker 無法啟動問題_不懂1417的博客-CSDN博客_docker無法啟動elasticsearch]
-
也可以參考這個命令
-
sysctl -w vm.max_map_count=262144 docker run -di --name=elasticsearch -p 9200:9200 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -v /root/elasticsearch/plugins:/usr/share/elasticsearch/plugins -v /root/elasticsearch/data:/usr/share/elasticsearch/data elasticsearch:7.4.1 -
主要看
ES_JAVA_OPTS=-Xms512m -Xmx512m
-
-
如果報錯資訊為:
java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes,可以參考以下的博客- java.nio.file.AccessDeniedException: /usr/share/elasticsearch/data/nodes......_楊林偉的博客-CSDN博客_java.nio.file.accessdenied
-
-
如何查看報錯資訊
docker logs 容器id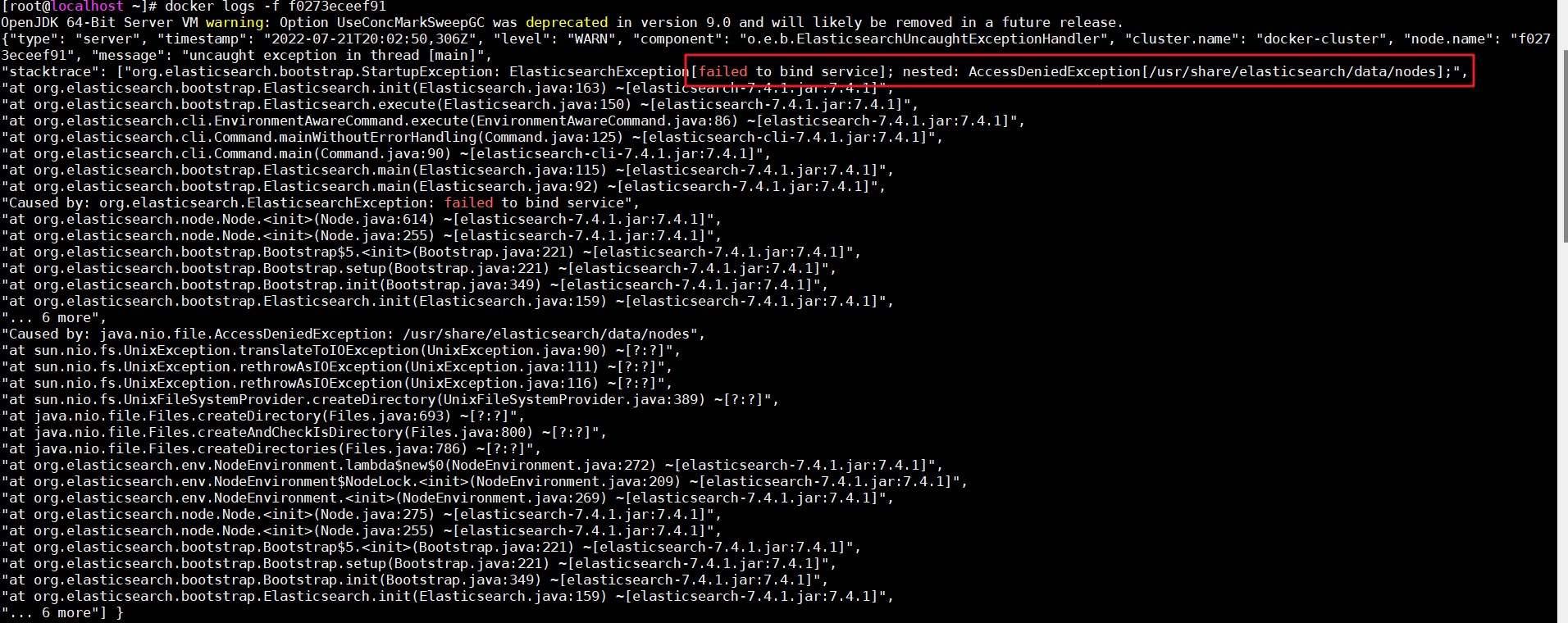
- 可以根據報錯資訊自行百度查看,一般都會有解決辦法
-
-
PS:如果訪問不了,記得開放埠或者關閉防火墻
- 開放埠如下所示

-
五、Kibana的安裝
kibana是elasticsearch的頁面可視化工具,類似MySQL的SQLyog等可視化工具
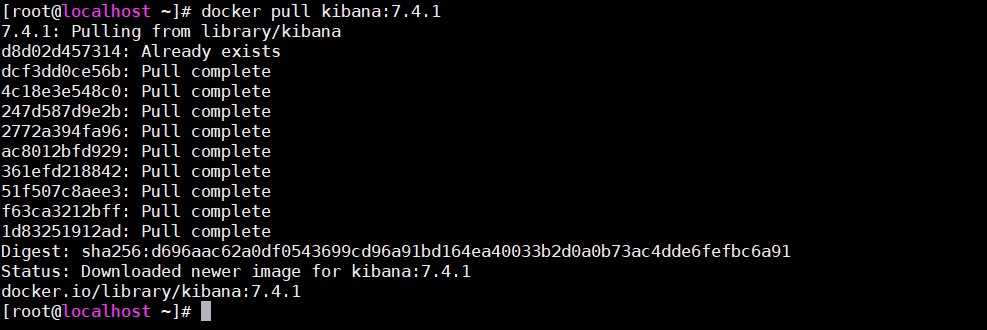
5.1、拉取鏡像
- 命令
docker pull kibana:7.4.1
- 如下所示
5.2、創建容器
-
命令
-
docker run -id -p 5601:5601 --link elasticsearch --name=kibana -e "ELASTICSEARCH_URL=http://你的自己的ip地址:9200" kibana:7.4.0
-
-
如下所示

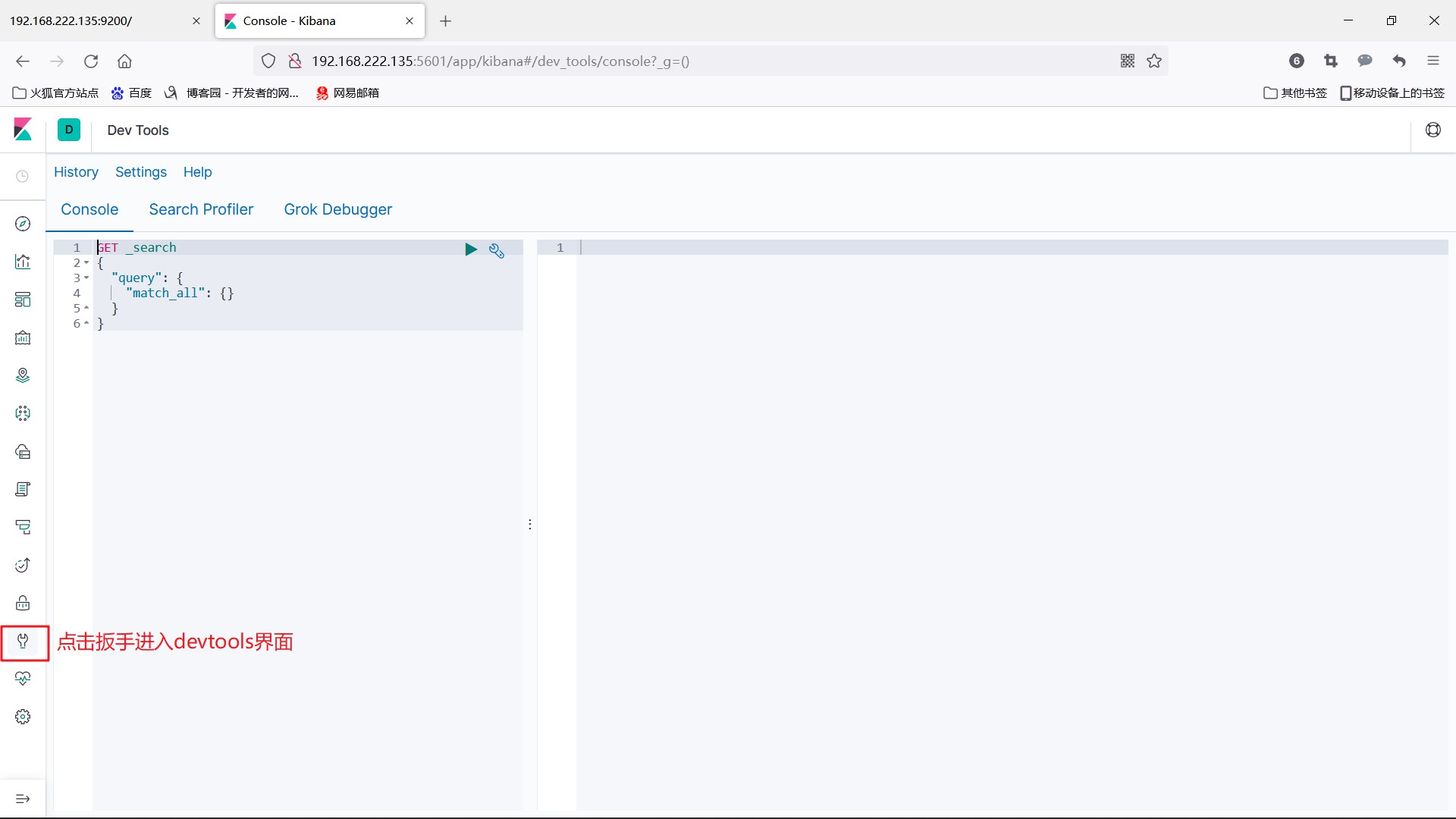
5.3、瀏覽器訪問
- 瀏覽器訪問:http://宿主機IP地址/5601
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500032.html
標籤:其他
上一篇:資料庫_多表查詢_內連接&外連接