06 | 全域鎖和表鎖 :給表加個欄位怎么有這么多阻礙?
Connection連接與Session會話
通俗來講,會話(Session)是通信雙?從開始通信到通信結束期間的?個背景關系(Context),這個背景關系是?段位于服務器端的記憶體:記錄了本次連接的客戶端機器、通過哪個應用程式、哪個用戶登錄等資訊,
連接是物理上的客戶端同服務器的通信鏈路

根據加鎖的范圍,MySQL 里面的鎖大致可以分成全域鎖、表級鎖和行鎖三類,
全域鎖
全域鎖就是對整個資料庫實體加鎖
Flush tables with read lock (FTWRL)
當你需要讓整個庫處于只讀狀態的時候,可以使用這個命令,之后其他執行緒的以下陳述句會被阻塞:資料更新陳述句(資料的增刪改)(DML) 、資料定義陳述句(包括建表、修改表結構等)(DDL)和更新類事務的提交陳述句,
全域鎖的典型使用場景是,做全庫邏輯備份,也就是把整庫每個表都 select 出來存成文本,
Q:在可重復讀隔離級別下開啟一個事務是一致性視圖,這時由于MVCC資料是可以正常更新的,所以為什么不用這種方式?
A:官方自帶的邏輯備份工具是 mysqldump,當 mysqldump 使用引數–single-transaction 的時候,導資料之前就會啟動一個事務,來確保拿到一致性視圖,但存在一個問題:single-transaction 方法只適用于所有的表使用事務引擎的庫,而MyISAM不支持事務
Q:既然要全庫只讀,為什么不使用 set global readonly=true 的方式呢?
A:
- 一是,在有些系統中,readonly 的值會被用來做其他邏輯,比如用來判斷一個庫是主庫還是備庫,因此,修改 global 變數的方式影響面更大,我不建議你使用,
- 二是,在例外處理機制上有差異,如果執行 FTWRL 命令之后由于客戶端發生例外斷開,那么 MySQL 會自動釋放這個全域鎖,整個庫回到可以正常更新的狀態,而將整個庫設定為 readonly 之后,如果客戶端發生例外,則資料庫就會一直保持 readonly 狀態,這樣會導致整個庫長時間處于不可寫狀態,風險較高,
表級鎖
表級別的鎖有兩種:一種是表鎖,一種是元資料鎖(meta data lock,MDL),
lock tables … read/write,與 FTWRL 類似,可以用 unlock tables 主動釋放鎖,也可以在客戶端斷開的時候自動釋放,需要注意,lock tables 語法除了會限制別的執行緒的讀寫外,也限定了本執行緒接下來的操作物件,
另一類表級的鎖是 MDL(metadata lock),
MDL作用是防止DDL和DML并發的沖突,
MDL 不需要顯式使用,在訪問一個表的時候會被自動加上,事務中的 MDL 鎖,在陳述句執行開始時申請,但是陳述句結束后并不會馬上釋放,而會等到整個事務提交后再釋放,

我們可以看到 session A 先啟動,這時候會對表 t 加一個 MDL 讀鎖,由于 session B 需要的也是 MDL 讀鎖,因此可以正常執行,之后 session C 會被 blocked,是因為 session A 的 MDL 讀鎖還沒有釋放,而 session C 需要 MDL 寫鎖,因此只能被阻塞,并且之后所有要在表 t 上新申請 MDL 讀鎖的請求也會被 session C 阻塞
MDL 會直到事務提交才釋放,在做表結構變更的時候,一定要小心不要導致鎖住線上查詢和更新,
Q:如何安全地給小表加欄位?
A:首先我們要解決長事務,事務不提交,就會一直占著 MDL 鎖,如果你要做 DDL 變更的表剛好有長事務在執行,要考慮先暫停 DDL,或者 kill 掉這個長事務,
Q:如果你要變更的表是一個熱點表,雖然資料量不大,但是上面的請求很頻繁,而你不得不加個欄位,你該怎么做呢?
A:這時候 kill 可能未必管用,因為新的請求馬上就來了,比較理想的機制是,在 alter table 陳述句里面設定等待時間,如果在這個指定的等待時間里面能夠拿到 MDL 寫鎖最好,拿不到也不要阻塞后面的業務陳述句,先放棄,之后開發人員或者 DBA 再通過重試命令重復這個程序,
Q:備份一般都會在備庫上執行,你在用–single-transaction 方法做邏輯備份的程序中,如果主庫上的一個小表做了一個 DDL,比如給一個表上加了一列,這時候,從備庫上會看到什么現象呢?
A:假設這個 DDL 是針對表 t1 的, 備份程序中幾個關鍵的陳述句:
/* 在備份開始的時候,為了確保 RR(可重復讀)隔離級別,再設定一次 RR 隔離級別 (Q1)*/
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
/* 啟動事務,這里用 WITH CONSISTENT SNAPSHOT 確保這個陳述句執行完就可以得到一個一致性視圖(Q2) */
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* 設定一個保存點,這個很重要(Q3); */
Q3:SAVEPOINT sp;
/* show create 是為了拿到表結構 (Q4) 時刻 1 */
Q4:show create table `t1`;
/* 正式導資料 (Q5) 時刻 2 */
Q5:SELECT * FROM `t1`;
/* 回滾到 SAVEPOINT sp,在這里的作用是釋放 t1 的 MDL 鎖 時刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 時刻 4 */
/* other tables */
DDL 從主庫傳過來的時間按照效果不同,分為四個時刻,
題目設定為小表,我們假定到達后,如果開始執行,則很快能夠執行完成,
- 如果在 Q4 陳述句執行之前到達,現象:沒有影響,備份拿到的是 DDL 后的表結構,
- 如果在“時刻 2”到達,則表結構被改過,Q5 執行的時候,報 Table definition has changed, please retry transaction,現象:mysqldump 終止;
- 如果在“時刻 2”和“時刻 3”之間到達,mysqldump 占著 t1 的 MDL 讀鎖,binlog 被阻塞,現象:主從延遲,直到 Q6 執行完成,
- 從“時刻 4”開始,mysqldump 釋放了 MDL 讀鎖,現象:沒有影響,備份拿到的是 DDL 前的表結構,
07 | 行鎖功過:怎么減少行鎖對性能的影響?
MySQL 的行鎖
MySQL 的行鎖是在引擎層由各個引擎自己實作的,但并不是所有的引擎都支持行鎖,比如 MyISAM 引擎就不支持行鎖,
行鎖就是針對資料表中行記錄的鎖,這很好理解,比如事務 A 更新了一行,而這時候事務 B 也要更新同一行,則必須等事務 A 的操作完成后才能進行更新,
兩階段鎖

事務 A 持有的兩個記錄的行鎖,都是在 commit 的時候才釋放的,事務 B 的 update 陳述句會被阻塞,直到事務 A 執行 commit 之后,事務 B 才能繼續執行,
在 InnoDB 事務中,行鎖是在需要的時候才加上的,但并不是不需要了就立刻釋放,而是要等到事務結束時才釋放,這個就是兩階段鎖協議,
如果你的事務中需要鎖多個行,要把最可能造成鎖沖突、最可能影響并發度的鎖盡量往后放,
死鎖和死鎖檢測
當并發系統中不同執行緒出現回圈資源依賴,涉及的執行緒都在等待別的執行緒釋放資源時,就會導致這幾個執行緒都進入無限等待的狀態,稱為死鎖,
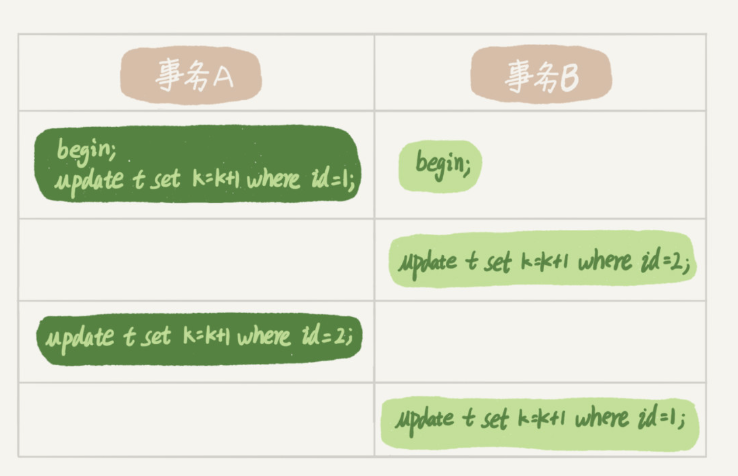
這時候,事務 A 在等待事務 B 釋放 id=2 的行鎖,而事務 B 在等待事務 A 釋放 id=1 的行鎖, 事務 A 和事務 B 在互相等待對方的資源釋放,就是進入了死鎖狀態,
當出現死鎖以后,有兩種策略:
- 一種策略是,直接進入等待,直到超時,這個超時時間可以通過引數 innodb_lock_wait_timeout 來設定,
- 另一種策略是,發起死鎖檢測,發現死鎖后,主動回滾死鎖鏈條中的某一個事務,讓其他事務得以繼續執行,將引數 innodb_deadlock_detect 設定為 on,表示開啟這個邏輯,每當一個事務被鎖的時候,就要看看它所依賴的執行緒有沒有被別人鎖住 n2復雜度),如此回圈,最后判斷是否出現了回圈等待,也就是死鎖,(死鎖的四個必要條件 互斥,請求與保持,不可剝奪,回圈等待)
死鎖檢測要耗費大量的 CPU 資源
Q:怎么解決由這種熱點行更新導致的性能問題呢?
A:
- 臨時把死鎖檢測關掉,可能會出現大量的超時,這是業務有損的,
- 控制并發度,在中間件實作,對于相同行的更新,在進入引擎之前排隊,這樣在 InnoDB 內部就不會有大量的死鎖檢測作業了,
- 從設計上優化,拆分一行改為邏輯上的多行,隨機選一個加上,再求和
Q:如果你要洗掉一個表里面的前 10000 行資料,有以下三種方法可以做到:
- 第一種,直接執行 delete from T limit 10000;
- 第二種,在一個連接中回圈執行 20 次 delete from T limit 500;
- 第三種,在 20 個連接中同時執行 delete from T limit 500,
選擇哪一種方法呢?為什么呢?
A:
第二種方式是相對較好的,
第一種方式(即:直接執行 delete from T limit 10000)里面,單個陳述句占用時間長,鎖的時間也比較長;而且大事務還會導致主從延遲,
第三種方式(即:在 20 個連接中同時執行 delete from T limit 500),會人為造成鎖沖突,
08 | 事務到底是隔離的還是不隔離的?
如果是可重復讀隔離級別,事務 T 啟動的時候會創建一個視圖 read-view,之后事務 T 執行期間,即使有其他事務修改了資料,事務 T 看到的仍然跟在啟動時看到的一樣,也就是說,一個在可重復讀隔離級別下執行的事務,好像與世無爭,不受外界影響,
一個事務要更新一行,如果剛好有另外一個事務擁有這一行的行鎖,它又不能這么超然了,會被鎖住,進入等待狀態,
Q:既然進入了等待狀態,那么等到這個事務自己獲取到行鎖要更新資料的時候,它讀到的值是什么呢?
舉一個例子,下面是一個只有兩行的表的初始化陳述句,
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);
事務開始時間點,分為兩種情況:
1)start transaction 時,是第一條陳述句的執行時間點,就是事務開始的時間點,第一條select陳述句建立一致性讀的snapshot;
2)start transaction with consistent snapshot 時,則是立即建立本事務的一致性讀snapshot,當然也開始事務了;

在這個例子中,事務 C 沒有顯式地使用 begin/commit,表示這個 update 陳述句本身就是一個事務,陳述句完成的時候會自動提交,
事務 B 在更新了行之后查詢 ;
事務 A 在一個只讀事務中查詢,并且時間順序上是在事務 B 的查詢之后,
結果:事務 B 查到的 k 的值是 3,而事務 A 查到的 k 的值是 1
A:
不妨做如下假設:
- 事務 A 開始前,系統里面只有一個活躍事務 ID 是 99;
- 事務 A、B、C 的版本號分別是 100、101、102,且當前系統里只有這四個事務;
- 三個事務開始前,(1,1)這一行資料的 row trx_id 是 90,
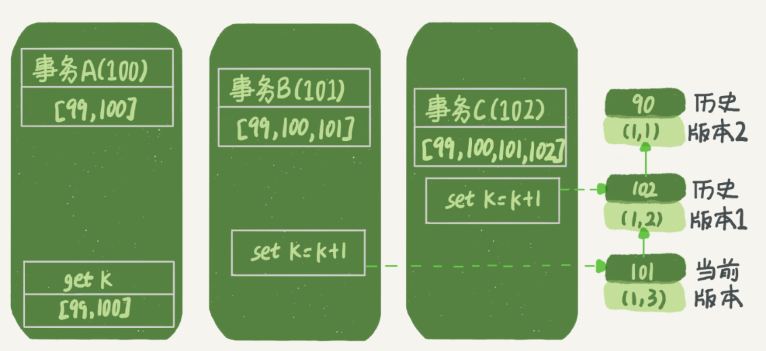
從圖中可以看到,第一個有效更新是事務 C,把資料從 (1,1) 改成了 (1,2),這時候,這個資料的最新版本的 row trx_id 是 102,而 90 這個版本已經成為了歷史版本,
第二個有效更新是事務 B,把資料從 (1,2) 改成了 (1,3),這時候,這個資料的最新版本(即 row trx_id)是 101,而 102 又成為了歷史版本,
在事務 A 查詢的時候,其實事務 B 還沒有提交,但是它生成的 (1,3) 這個版本已經變成當前版本了,但這個版本對事務 A 必須是不可見的,否則就變成臟讀了,
事務 A 要來讀資料了,它的視圖陣列是 [99,100],當然了,讀資料都是從當前版本讀起的,所以,事務 A 查詢陳述句的讀資料流程是這樣的:
- 找到 (1,3) 的時候,判斷出 row trx_id=101,比高水位大,處于紅色區域,不可見;
- 接著,找到上一個歷史版本,一看 row trx_id=102,比高水位大,處于紅色區域,不可見;
- 再往前找,終于找到了(1,1),它的 row trx_id=90,比低水位小,處于綠色區域,可見,
總結:
一個資料版本,對于一個事務視圖來說,除了自己的更新總是可見以外,有三種情況:
- 版本未提交,不可見;
- 版本已提交,但是是在視圖創建后提交的,不可見;
- 版本已提交,而且是在視圖創建前提交的,可見,
兩個“視圖”的概念
在 MySQL 里,有兩個“視圖”的概念:
- 一個是 view,它是一個用查詢陳述句定義的虛擬表,在呼叫的時候執行查詢陳述句并生成結果,創建視圖的語法是 create view … ,而它的查詢方法與表一樣,
- 另一個是 InnoDB 在實作 MVCC 時用到的一致性讀視圖,即 consistent read view,用于支持 RC(Read Committed,讀提交)和 RR(Repeatable Read,可重復讀)隔離級別的實作,
它沒有物理結構,作用是事務執行期間用來定義“我能看到什么資料”,
“快照”在 MVCC 里是怎么作業的?
在可重復讀隔離級別下,事務在啟動的時候就“拍了個快照”,注意,這個快照是基于整庫的,
InnoDB 里面每個事務有一個唯一的事務 ID,叫作 transaction id,它是在事務開始的時候向 InnoDB 的事務系統申請的,是按申請順序嚴格遞增的,
而每行資料也都是有多個版本的,每次事務更新資料的時候,都會生成一個新的資料版本,并且把 transaction id 賦值給這個資料版本的事務 ID,記為 row trx_id,同時,舊的資料版本要保留,并且在新的資料版本中,能夠有資訊可以直接拿到它,
也就是說,資料表中的一行記錄,其實可能有多個版本 (row),每個版本有自己的 row trx_id,
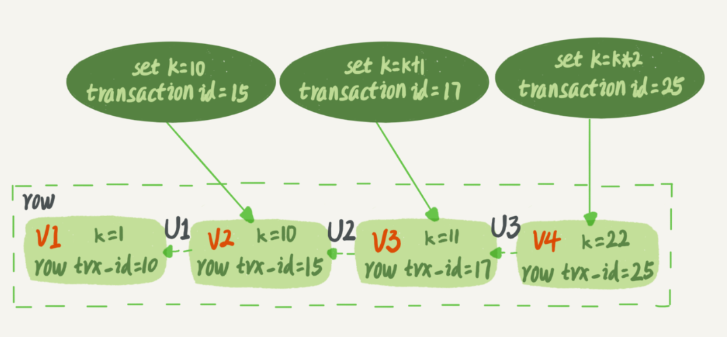
圖中虛線框里是同一行資料的 4 個版本,當前最新版本是 V4,k 的值是 22,它是被 transaction id 為 25 的事務更新的,因此它的 row trx_id 也是 25,
實際上,圖 2 中的三個虛線箭頭,就是 undo log;而 V1、V2、V3 并不是物理上真實存在的,而是每次需要的時候根據當前版本和 undo log 計算出來的,比如,需要 V2 的時候,就是通過 V4 依次執行 U3、U2 算出來,
按照可重復讀的定義,一個事務啟動的時候,能夠看到所有已經提交的事務結果,但是之后,這個事務執行期間,其他事務的更新對它不可見,因此,一個事務只需要在啟動的時候宣告說,“以我啟動的時刻為準,如果一個資料版本是在我啟動之前生成的,就認;如果是我啟動以后才生成的,我就不認,我必須要找到它的上一個版本”,當然,如果“上一個版本”也不可見,那就得繼續往前找,還有,如果是這個事務自己更新的資料,它自己還是要認的,
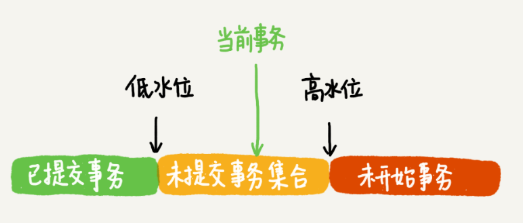
在實作上, InnoDB 為每個事務構造了一個陣列,用來保存這個事務啟動瞬間,當前正在“活躍”的所有事務 ID,“活躍”指的就是,啟動了但還沒提交,
陣列里面事務 ID 的最小值記為低水位,當前系統里面已經創建過的事務 ID 的最大值加 1 記為高水位,
這個視圖陣列和高水位,就組成了當前事務的一致性視圖(read-view)
資料版本的可見性規則,就是基于資料的 row trx_id 和這個一致性視圖的對比結果得到的,
這個視圖陣列把所有的 row trx_id 分成了幾種不同的情況,
- 如果落在綠色部分,表示這個版本是已提交的事務或者是當前事務自己生成的,這個資料是可見的;
- 如果落在紅色部分,表示這個版本是由將來啟動的事務生成的,是肯定不可見的;
- 如果落在黃色部分,那就包括兩種情況
a. 若 row trx_id 在陣列中,表示這個版本是由還沒提交的事務生成的,不可見;
b. 若 row trx_id 不在陣列中,表示這個版本是已經提交了的事務生成的,可見,
有了這個宣告后,系統里面隨后發生的更新,就跟這個事務看到的內容無關了,因為之后的更新,生成的版本一定屬于上面的 2 或者 3(a) 的情況,而對它來說,這些新的資料版本是不存在的,所以這個事務的快照,就是“靜態”的了,
如果有一個事務,它的低水位是 18,那么當它訪問這一行資料時,就會從 V4 通過 U3 計算出 V3,所以在它看來,這一行的值是 11,
InnoDB 利用了“所有資料都有多個版本”的這個特性,實作了“秒級創建快照”的能力,
更新邏輯
Q:事務 B 的 update 陳述句,如果按照一致性讀,好像結果不對哦?
事務 B 的視圖陣列是先生成的,之后事務 C 才提交,不是應該看不見 (1,2) 嗎,怎么能算出 (1,3) 來?
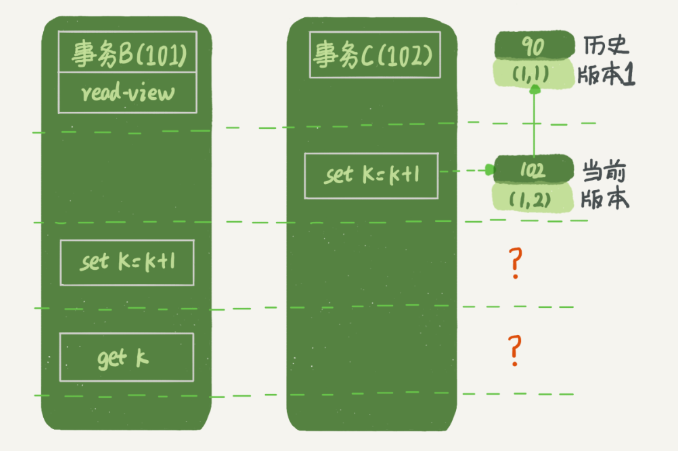
A:如果事務 B 在更新之前查詢一次資料,這個查詢回傳的 k 的值確實是 1,
但是,當它要去更新資料的時候,就不能再在歷史版本上更新了,否則事務 C 的更新就丟失了,因此,事務 B 此時的 set k=k+1 是在(1,2)的基礎上進行的操作,
更新資料都是先讀后寫的,而這個讀,只能讀當前的值,稱為“當前讀”(current read),
因此,在更新的時候,當前讀拿到的資料是 (1,2),更新后生成了新版本的資料 (1,3),這個新版本的 row trx_id 是 101,所以,在執行事務 B 查詢陳述句的時候,一看自己的版本號是 101,最新資料的版本號也是 101,是自己的更新,可以直接使用,所以查詢得到的 k 的值是 3,
除了 update 陳述句外,select 陳述句如果加鎖,也是當前讀,
所以,如果把事務 A 的查詢陳述句 select * from t where id=1 修改一下,加上 lock in share mode 或 for update,也都可以讀到版本號是 101 的資料,回傳的 k 的值是 3,
下面這兩個 select 陳述句,就是分別加了讀鎖(S 鎖,共享鎖)和寫鎖(X 鎖,排他鎖),
select k from t where id=1 lock in share mode;
select k from t where id=1 for update;
Q:假設事務 C 不是馬上提交的,而是變成了下面的事務 C’,會怎么樣呢?
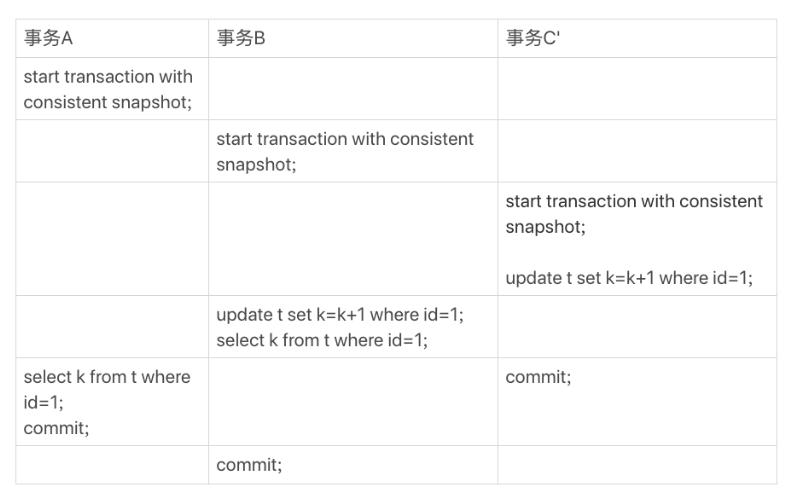
事務 C’的不同是,更新后并沒有馬上提交,在它提交前,事務 B 的更新陳述句先發起了,前面說過了,雖然事務 C’還沒提交,但是 (1,2) 這個版本也已經生成了,并且是當前的最新版本,那么,事務 B 的更新陳述句會怎么處理呢?
A:考慮兩階段鎖協議,事務 C’沒提交,也就是說 (1,2) 這個版本上的寫鎖還沒釋放,而事務 B 是當前讀,必須要讀最新版本,而且必須加鎖,因此就被鎖住了,必須等到事務 C’釋放這個鎖,才能繼續它的當前讀,
事務的可重復讀的能力是怎么實作的?
可重復讀的核心就是一致性讀(consistent read);而事務更新資料的時候,只能用當前讀,如果當前的記錄的行鎖被其他事務占用的話,就需要進入鎖等待,
讀提交的邏輯和可重復讀
而讀提交的邏輯和可重復讀的邏輯類似,它們最主要的區別是:
- 在可重復讀隔離級別下,只需要在事務開始的時候創建一致性視圖,之后事務里的其他查詢都共用這個一致性視圖;
- 在讀提交隔離級別下,每一個陳述句執行前都會重新算出一個新的視圖,“start transaction with consistent snapshot; ”的意思是從這個陳述句開始,創建一個持續整個事務的一致性快照,所以,在讀提交隔離級別下,這個用法就沒意義了,等效于普通的 start transaction,
導致:
- 對于可重復讀,查詢只承認在事務啟動前就已經提交完成的資料;
- 對于讀提交,查詢只承認在陳述句啟動前就已經提交完成的資料;
Q:在讀提交隔離級別下,事務 A 和事務 B 的查詢陳述句查到的 k,分別應該是多少呢?
A:
下面是讀提交時的狀態圖,可以看到這兩個查詢陳述句的創建視圖陣列的時機發生了變化,就是圖中的 read view 框,(注意:這里,我們用的還是事務 C 的邏輯直接提交,而不是事務 C’)
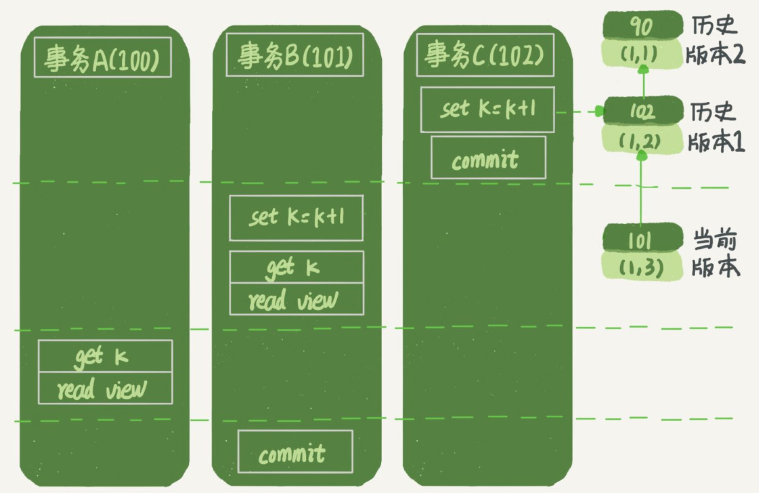
這時,事務 A 的查詢陳述句的視圖陣列是在執行這個陳述句的時候創建的,時序上 (1,2)、(1,3) 的生成時間都在創建這個視圖陣列的時刻之前,但是,在這個時刻:
- (1,3) 還沒提交,屬于情況 1,不可見;
- (1,2) 提交了,屬于情況 3,可見,
所以,這時候事務 A 查詢陳述句回傳的是 k=2,事務 B 查詢結果 k=3,能看到已提交的,,
Q:用下面的表結構和初始化陳述句作為試驗環境,事務隔離級別是可重復讀,現在,我要把所有“欄位 c 和 id 值相等的行”的 c 值清零,但是卻發現了一個“詭異”的、改不掉的情況,請你構造出這種情況,并說明其原理,
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);
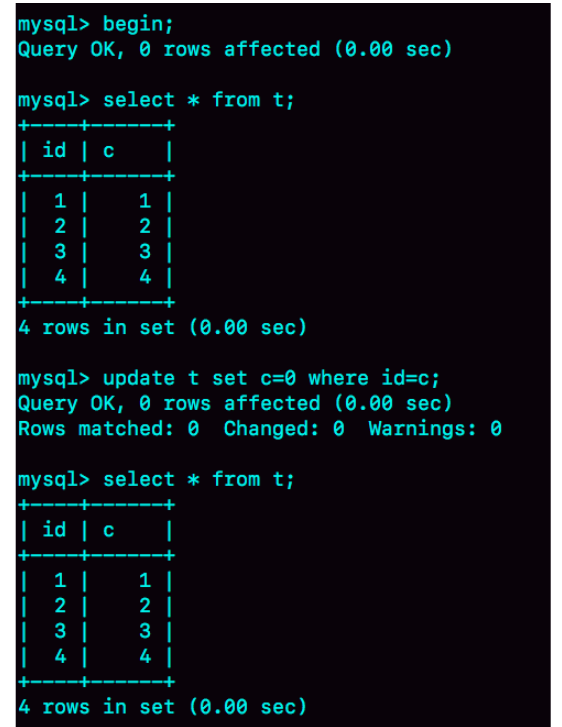
A:如何構造一個“資料無法修改”的場景,


轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500142.html
標籤:MySQL
上一篇:MySQL實戰45講 9
下一篇:MySQL實戰45講 10