1.初識資料庫
-
資料庫(DB,database)
-
概念:資料倉庫,安裝在作業系統上的一款軟體
-
作用:存盤管理資料
-
分類:
- 關系型資料庫(SQL):
- MySQL,Oracle,Sql Server,DB2,SQLlite
- 通過表和表之間,行和列之間的關系進行資料的存盤
- 非關系型資料庫(NoSQL not only) :
- Redis,MongDB
- 非關系資料庫,物件存盤,通過物件自身的屬性決定
- 關系型資料庫(SQL):
-
DBMS(資料庫管理系統):
- 資料庫的管理軟體,科學有效的管理資料,維護和獲取資料
- MySQL,資料庫管理系統
-
下載安裝MySQL資料庫
-
下載安裝資料庫可視化工具Navicat
-
連接資料庫(命令列):
- 打開cmd
- 跳轉到mysql的bin目錄
- 輸入mysql -uroot -p
- 輸入密碼
- exit退出
-
資料庫一些命令:
--注:每個sql陳述句結束都要用分號結尾 flush privilege; --重繪權限 show databases; --查看所有資料庫 use 資料庫名; --使用資料庫 Database changed show tables; --查看資料庫中所有的表 describe student; --查看表的資訊 create database test_db; --創建資料庫
2. 操作資料庫
操作資料庫》操作資料庫中的表》操作表中的資訊
-
操作資料庫:
-
操作資料庫:
CREATE DATABASE [if not exists] shcool; -
洗掉資料庫:
drop database [if exists] lpjsql; -
使用資料庫:
use db_yq; -
查看資料庫:
show DATABASES;
-
-
操作資料庫表:
-
資料庫列的型別:
-
數值:
tinyint --十分小的整數|1個位元組 smallint --較小的整數|2個位元組 mediumint --中等大小的整數|3個位元組 int --標準的整數|4個位元組|常用 bigint --較大的整數|8個位元組 float --單精度浮點數|4個位元組 double --多精度浮點數|8個位元組 decimal --字串形式的浮點數|用于金融計算 -
字串:
char --固定大小的字串|0~255 varchar --可變長字串|0~65535|常用 tinytext --微型文本|0~2^8-1 text --文本串|0~2^16-1|保存大文本 -
時間和日期:
date --YYYY-MM-DD|日期 time --HH:mm:ss|時間 datetime --YYYY-MM-DD HH:mm:ss|最常用的時間格式 timestamp --時間戳|1970.1.1到現在的毫秒數|較為常用 year --年份 -
null:
--沒有值,未知,注意不要使用null進行運算,因為結果一定為null
-
-
-
資料庫的欄位屬性(重點):
- unsigned (無符號的整數 聲名該列不能為負數)
- zerofill(0填充 不足的位數用0填充 1 001)
- auto_increment( 自增,自動在上一條記錄的基礎上+1(默認) 通常用來設計唯一的主鍵 必須是整數 可自定義設計主鍵的自增起始值和步長)
- NULL NOT NULL(非空 ,假設不賦值就會報錯)
- default '默認值'(默認 ,設定默認值)(navicat設定字符默認值時需要加引號)
-
拓展:做專案時,每個表設計時都應該具有的五個欄位:
- id 主鍵
- ‘version’ 樂觀鎖 版本號
- is_delete 偽洗掉
- gmt_create 創建時間
- gmt_update 修改時間
-
注:在資料庫中int的長度并不影響資料的存盤精度,長度只是和顯示有關
-
創建資料庫表:
create table if not exists ‘studnet’ ( `id` int(4) not null auto_increment COMMENT '學號', `name` VARCHAR(20) not NULL DEFAULT '匿名' COMMENT '姓名', `psd` VARCHAR(20) not NULL DEFAULT '123456' COMMENT '密碼', `sex` VARCHAR(2) not NULL DEFAULT '男' COMMENT '性別', `birthda` datetime DEFAULT null COMMENT '出生日期', `address` VARCHAR(100) DEFAULT null COMMENT '家庭住址', `email` VARCHAR(18) DEFAULT null COMMENT '郵箱', PRIMARY key(`id`) ); show create table studnet; --查看表的創建陳述句 desc studnet;--查看表的結構 --注:use 資料庫之后,相關操作比如創建表是在該資料庫下創建 -
資料表的型別:
-
資料引擎:
MyISAM InnoDB 事務支持 不支持 支持 資料行鎖定 不支持 支持 外鍵約束 不支持 支持 全文索引 支持 不支持 表空間大小 較小 較大,約為倍 常規使用操作:
- MyISAM:節約空間,速度較快
- InnoDB:安全性高,支持事務,多表多用戶操作
物理存盤位置:所有資料庫檔案都存在data目錄下,本質上還是檔案存盤
-
MySQL引擎在物理上檔案的區別而:
-
.MySQL(server)創建并管理的資料庫檔案:
-
.frm檔案:存盤資料表的框架結構,檔案名與表名相同,每個表對應一個同名frm檔案,與作業系統和存盤引擎無關,即不管MySQL運行在何種作業系統上,使用何種存盤引擎,都有這個檔案,
-
除了必有的.frm檔案,根據MySQL所使用的存盤引擎的不同(MySQL常用的兩個存盤引擎是MyISAM和InnoDB),存盤引擎會創建各自不同的資料庫檔案,
-
MyISAM資料庫表檔案:
- .MYD檔案:即MY Data,表資料檔案
- .MYI檔案:即MY Index,索引檔案
-
InnoDB資料庫檔案(即InnoDB檔案集,ib-file set):
- ibdata1等:系統表空間檔案,存盤InnoDB系統資訊和用戶資料庫表資料和索引,所有表共用
- .ibd檔案:單表表空間檔案,每個表使用一個表空間檔案(file per table),存放用戶資料庫表資料和索引
- 日志檔案: ib_logfile0、ib_logfile1
-
-
-
-
-
資料庫表的字符集編碼:不設定的話會使用默認的編碼
-
修改洗掉表:
-
修改表:
ALTER table studnet RENAME as student --修改表名 --增加表的欄位 ALTER TABLE test1 add age int(10) not null COMMENT '年齡' --修改約束和欄位型別,不能重命名 ALTER TABLE test1 MODIFY age VARCHAR(11); --不能單獨修改欄位型別和約束,但是可以在重命名時設定欄位型別約束 ALTER TABLE test1 CHANGE age age1 int(2); --洗掉表的欄位 ALTER TABLE test1 drop age; -
洗掉表:
drop table if exists test1;注:所有的洗掉或者創建操作盡量加上判斷條件
-
3.MySQL資料管理
-
外鍵(了解):資料庫中直接設立外鍵都是資料庫級別的外鍵,不建議使用(避免資料庫過多造成困擾),
- 最佳實作:資料庫就是單純的表,只用來存盤資料,當有多張表進行操作時或者想使用外鍵建議使用程式實作,
-
DML語言(掌握):
-
insert:
--方法一:直接插入一整條記錄 insert into 表名 values(全部列值,且一一對應); --方法二:對應列插入值 insert into 表名(欄位1,欄位2...) values(欄位值1,欄位值2,...); --一次性插入多個記錄 INSERT into 表名(欄位1,欄位2...) VALUES (欄位值1,欄位值2,...),(欄位值1,欄位值2,...),...; -
update:
update 表名 set 欄位名=欄位值[,欄位名=欄位值,...] [where ...] --注1:如果沒有條件限定,會直接修改全部記錄的對應欄位值 --注2:欄位值不僅可以是常量,也可以是變數,比如常用的時間函式 -
delete:
delete from 表名;--洗掉整個表所有資料 delete from 表名 where ...;--洗掉指定資料 --補充 --完全清空一個資料庫表,表的結構和索引約束不會變 truncate table 表名; --兩種方式的區別 --相同點:都能洗掉資料且不會洗掉表 --不同點: --truncate:自增會歸零 --delete:不影響自增 --拓展:delete 洗掉資料時,如果重啟資料庫,那么 --InnoDB:自增列會從1開始(存在記憶體中的,斷電即失) --MySAM:繼續從上一個自增量開始(存在檔案中的,不會丟失)
-
-
DQL語言(查詢資料):
-
別名:欄位名 as 新名字;表名 as 新名字;或者直接:欄位名 新名字;表名 新名字;
-
拼接字串:Concat(a,b,c,...)
SELECT CONCAT('名字:',number,'寢室') as '寢室號' , CONCAT('樓:',building_name) as '所屬樓層' from room; -
去重:distinct(將查詢中的重復結果只顯示一條)
SELECT DISTINCT room_id FROM student; -
特殊作用:
SELECT VERSION();--查詢版本號 SELECT 123*223;--查詢計算結果
注:資料庫中的運算式:文本值,列,null,函式,計算運算式,系統變數,而
select 運算式 from 表
-
where條件陳述句:
-
常用運算子:
-
邏輯運算子:
運算子 含義 AND 或者 && 邏輯與,含義為“并且”,當所有運算元均為非零值且不為 null 時,回傳值為 1;當一個或多個運算元為 0 時,回傳值為 0;其余情況回傳值為 null OR 或者 || 邏輯或,含義為“或者”,當所有運算元均不為 null 且任意一個運算元為非零時,回傳值為 1,否則為 0;當有運算元為 null,且存在另一個運算元為非零時,回傳值為 1,否則為 null;當所有運算元均為 null 時,回傳值為 null NOT 或者 ! 邏輯非,含義為“取反”,當運算元為 0 時,回傳值為 1;當運算元為非零時,回傳值為 0;當運算元為 null 時,回傳值為 null -
比較運算子:
運 算 符 含 義 = 等于 <=> 安全等于,可以比較 null <> 或 != 不等于 >= 大于等于 <= 小于等于 > 大于 < 小于 -
算術運算子:
運 算 符 含 義 + 加法運算 - 減法運算 * 乘法運算 / 除法運算,回傳商 % 求余運算,回傳余數 -
模糊查詢:
運算子 含義 IS NULL 判斷一個值是否為 null IS NOT NULL 判斷一個值是否不為 null BETWEEN AND 在什么和什么之間 LIKE 匹配 in a in (a1,a2,a3,...),如果a在a1,a2,a3之間存在,那么為真 注1:like與%(0~任意個字符)和_(一個字符)結合使用,且不一定要是字符型別才可以使用,數字型別也可以加上引號使用
select id from student where id like '%2%';注2:in()必須指定的是確定的值,使用%或者_不行,確定值的運算式也可以
select id from student where id in (7,8,9,10,1+11);
-
-
-
聯表查詢:
-
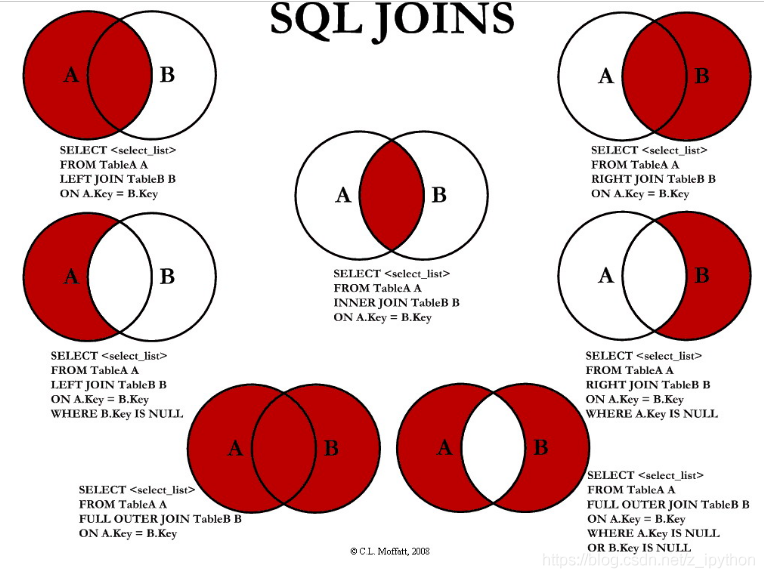
-
兩種連接表的查詢:
- 等值查詢:where
- 聯表查詢:join...on
-
聯表查詢:
-
inner join:內連接,特點是查詢出來的結果是兩個表都有的部分
--如a表有1,2,3,4,b表有2,3,4,5,那么查詢的結果包含2,3,4 SELECT s.room_id,r.id,s.name,r.building_name from student s INNER JOIN room r on s.room_id=r.id; -
left join:
-
左連接:
--如a表有1,2,3,4,b表有2,3,4,5,那么查詢的結果包含1,2,3,4 SELECT s.room_id,r.id,s.name,r.building_name from student s LEFT JOIN room r on s.room_id=r.id; -
左外連接:
--如a表有1,2,3,4,b表有2,3,4,5,那么查詢的結果包含1 SELECT s.room_id,r.id,s.name,r.building_name from student s LEFT JOIN room r on s.room_id=r.id where r.building_name is null;
-
-
right join:
-
右連接:
--如a表有1,2,3,4,b表有2,3,4,5,那么查詢的結果包含2,3,4,5 SELECT s.room_id,r.id,s.name,r.building_name from student s RIGHT JOIN room r on s.room_id=r.id -
右外連接:
--如a表有1,2,3,4,b表有2,3,4,5,那么查詢的結果包含5 SELECT s.room_id,r.id,s.name,r.building_name from student s RIGHT JOIN room r on s.room_id=r.id where s.room_id is null;
-
-
全連接(mysql不支持全連接)
-
三個及以上的多表查詢:
select r.*,s.`寢室人數`,e.* from room r left join (SELECT count(*) as '寢室人數',room_id as id from student GROUP BY room_id) as s on r.id=s.id RIGHT JOIN `repair` e on r.id=e.room_id --注:直接先兩表查詢,然后接著兩表查詢的結果后面再連接表 -
聯表查詢+子查詢;
select r.*,s.`寢室人數` from room r left join (SELECT count(*) as '寢室人數',room_id as id from student GROUP BY room_id) as s on r.id=s.id --注:在s.`寢室人數`處使用字符時應該使用`而不是引號 -
自連接(了解):將一張表看成兩張表進行連接查詢
-
-
-
分頁和排序:
-
order by(排序):
-
desc(降序):
order by 欄位 DESC -
asc(升序):
order by 欄位 ASC
-
-
limit(分頁):
LIMIT 資料起始位置,頁面數量
-
-
子查詢:
select room.id,`repair`.`describe`,student.`name` from student,room,`repair` WHERE student.room_id=(SELECT id FROM room WHERE number=2624) and `repair`.room_id=(SELECT id FROM room WHERE number=2624) and room.number=2624 -
分組和過濾(當分組后還有條件時,可以使用having):
select room_id FROM student GROUP BY room_id having COUNT(*) = 2注:(select ...)可以當做一個表,可以跟在from后面,也可以跟在連接查詢后面,同時在查詢的時候新生成的表都要設定別名,
-
4.mysql函式:
參考網站:https://www.jb51.net/article/226393.htm
-
常用函式:
-
length(str):獲取引數值的位元組個數;對于
utf8字符集來說,一個英文占1個位元組;一個中文占3個位元組;對于
gbk字符集來說,一個英文占1個位元組;一個中文占2個位元組; -
concat(str1,str2,…):拼接字串; -
upper(str):將字符中的所有字母變為大寫; -
lower(str):將字符中所有字母變為小寫; -
instr(str,要查找的子串):回傳子串第一次出現的索引,如果找不到,回傳0; 當查找的子串存在于字串中:回傳該子串在字串中【第一次】出現的索引,當查找的子串不在字串中:回傳0, -
trim(str):去掉字串前后的空格; 該函式只能去掉字串前后的空格,不能去掉字串中間的空格, -
lpad(str,len,填充字符):用指定的字符,實作對字串左填充至指定長度; -
rpad(str,len,填充字符):用指定的字符,實作對字串右填充至指定長度 -
replace(str,子串,另一個字串):將字串str中的字串,替換為另一個字串; -
round(x,[保留的位數]):四舍五入 -
ceil(x):向上取整 -
floor(x):向下取整 -
mod(被除數,除數):取余 -
now():回傳系統當前的日期和時間; -
curdate():只回傳系統當前的日期,不包含時間; -
curtime():只回傳系統當前的時間,不包含日期; -
獲取日期和時間中年、月、日、時、分、秒;
獲取年份:year();
獲取月份:month();
獲取日:day();
獲取小時:hour();
獲取分鐘:minute();
獲取秒數:second();
-
weekofyear():獲取當前時刻所屬的周數; -
quarter():獲取當前時刻所屬的季度;
-
-
聚合函式:
- count():計數
- sum():求和
- avg():平均值
- max():最大值
- min():最小值
注:
-
sum()函式和avg()函式對于字串型別、日期/時間型別的計算都沒有太大意義,因此,sum()函式和avg()函式,我們只用來對小數型別和整型進行求和
-
max()和min()中傳入的是"整型/小數型別",計算的是數值的
最大值和最小值,max()和min()中傳入的是"日期型別",max()計算的最大值是離我們最近的那個日期,min()計算的最小值是離我們最遠的那個日期,這個可以記一下,max()和min()中傳入的是字串型別,max()計算的最大值是按照英文字母順序顯示的,min()計算的最小值也是按照英文字母順序顯示的,意義不太大, -
當某個欄位列中沒有null值,則"count(列欄位)=count(),"
當某個欄位列中有null值,則"count(列欄位)<count(),"
因此,假如你想統計的是整張表的行數,請用count(*),另可參考:https://blog.csdn.net/qq_41711758/article/details/116258290
-
拓展(MD5加密):
--資料庫中使用MD5函式加密 INSERT into `repair` (id,`describe`,room_id) VALUES (15,md5('2624'),2)
5.事務
-
什么是事務;
經典例子:
轉賬:
操作: 張三和李四各自的賬號都是1000元;張三向李四轉賬100元
組成單元: 張三錢-100, 李四錢+100
操作成功: 張三錢900,李四錢1100
操作失敗: 張三錢1000,李四錢1000
不可能發生: 張三錢900,李四錢1000;或者 戰三錢1000,李四錢1100
-
事務特性:
- 原子性:要么都成功,要么都失敗,即不會出現錢轉出去了但是沒有收到的情況,即轉錢和收錢兩個操組合作為一個不可拆分的操作
- 一致性:事務前后資料完整性一致,比如轉錢轉錢一共2000,那么轉錢之后一共也是2000
- 持久性-----事務提交:事務提交后不可逆,被持久化保存到資料庫中
- 隔離性:多個事務之前是相互隔離的,互不影響,資料庫允許多個并發同時對其資料進行讀寫和修改,隔離性可以防止多個事務并發執行時由于交叉執行而導致的資料不一致,
比如操作同一張表時,資料庫為每一個用戶開啟的事務,不能被其他事務的操作所干擾,多個并發事務之間要相互隔離, - 隔離造成的一些問題:
- 臟讀:一個事務讀取了另外一個事務未提交的資料
- 不可重復讀:在一個事務內讀取表中某一行資料多次讀取結果不一致(不一定是錯誤,可能是場合不對)
- 虛讀(幻讀):在一個事務內讀取到了別的事務插入的資料,導致前后讀取不一致
-
資料庫實作事務:
-
mysql是默認開啟事務自動提交的
set autocommit =0; --關閉事務 set autocommit =1; --開啟事務,默認 -
手動實作事務步驟:
--第一步:關閉事務 set autocommit =0; --第二步:開始一個事務 START TRANSACTION; --標記一個事務的開始,這個之后的sql陳述句都算一個事務 --第三步:sql陳述句執行 --第四步:提交或者回滾 commit --提交:持久化,事務成功 ROLLBACK --回滾:回到之前的狀態,一旦被提交就持久化了無法回滾 --第五步:事務結束 set autocommit =1; --開啟事務提交 --了解: SAVEPOINT 保存點名 --設定一個事務保存點 ROLLBACK to SAVEPOINT 保存點名 --回滾到保存點名 RELEASE SAVEPOINT 保存點名 --撤銷保存點,一個事務可以有多個保存點
-
6.索引
-
定義:索引是幫助mysql高效獲取資料的一種資料結構
-
分類:
- 主鍵索引(primary):
- 唯一標識,不可重復,只能存在一個主鍵
- 唯一索引(unique):
- 避免重復的列出現,唯一索引可以重復,多個列都可以標識為唯一索引
- 常規索引(key/index):
- 默認的,使用index或者key設定
- 全文索引(FullText):
- 快速定位資料
- 主鍵索引(primary):
-
使用:
-
在創建表的時候增加索引
-
創建完畢后,增加索引:
-
ALTER TABLE 表名 add 索引型別 索引名 (列名1,列名2,列名3,...)
--查看對應表的索引 show index from student --增加一個全文索引 ALTER TABLE student add FULLTEXT index `student_name` (`name`) --EXPLAIN:分析sql執行的狀況 EXPLAIN SELECT * FROM student --非全文索引 -
create 索引型別 索引名 on 表 (列名)
CREATE UNIQUE INDEX `student_name` on student (name)
-
-
洗掉索引:DROP INDEX index_name ON table_name
drop index `student_name` on student
-
-
索引原則:
- 索引不是越多越好
- 不要對經常變動的資料加索引
- 小資料量的表不需要加索引
- 索引一般加在常用來查詢的欄位
-
索引的資料結構和原理:
參考鏈接:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
-
mysql優化:參考鏈接:參考鏈接;https://blog.csdn.net/jiadajing267/article/details/81269067
7.資料庫的備份和用戶管理
-
備份:
-
方式:
-
直接拷貝物理檔案(data)
-
直接在可視化工具里面匯出匯入
-
使用命令列匯出:在Bin目錄下
--匯出 --mysqldump -h主機 -u用戶名 -p密碼 資料庫 [表1 表2 表3] >位置 mysqldump -hlocalhost -uroot -p18227022334a mysql user >D:/mysql_user.sql --匯入 --登錄的情況下,切換到對應資料庫 --source 檔案 source D:/mysql_user.sql --未登錄的情況下 --mysql -u用戶名 -p密碼 庫名 [表名]< 檔案 mysql -uroot -p18227022334a mysql user< D:/mysql_user.sql
-
-
-
用戶管理:
-
navicat操作:
-
sql命令操作:
用戶表:mysql資料庫下的user表
--創建用戶: CREATE user 用戶名 IDENTIFIED by 密碼 --修改密碼 ALTER USER 用戶名@Host IDENTIFIED WITH mysql_native_password BY 密碼 --用戶重命名 RENAME user 用戶名@Host to 新用戶名@新Host --用戶授權 grant all privileges on *.* to 用戶名@Host with grant option; --查詢權限 --撤銷權限 --洗掉用戶 DROP user 用戶名@Host
-
8.規范資料庫設計
-
三大范式:
- 第一范式(1NF):原子性:保證每一列不可再分
- 第二范式(2NF):滿足第一范式前提下,每張表只集中于一件事(比如姓名,性別,年齡,課程名稱,課程成績這張表就不滿足第二范式,應該拆分為姓名,性別,年齡和姓名,課程名稱,課程成績兩張表)
- 第三范式(3NF):滿足第二范式的前提下,確保資料表中每一列資料都跟主鍵直接相關,不能間接相關
-
規范性和性能問題:
阿里內部規定關聯查詢的表表的超過三張
- 從成本和用戶體驗方面來說,性能更加重要
- 在考慮性能問題的同時應該適當考慮下規范性
- 可以故意增加一些冗余欄位(從多表查詢變成單表查詢)
- 故意增加一些計算列(從大資料量變為小資料量的查詢:索引)
9.JDBC
-
匯入資料庫驅動
-
jdbc:Java資料庫連接,(Java Database Connectivity,簡稱JDBC)是Java語言中用來規范客戶端程式如何來訪問資料庫的應用程式介面應用程式介面,提供了諸如查詢和更新資料庫中資料的方法,我們通常說的JDBC是面向關系型資料庫的,
-
操作資料庫步驟:
-
加載驅動:
Class.forName("com.mysql.jdbc.cj.Driver"); -
用戶資訊和密碼:
String url="jdbc.url=jdbc:mysql://localhost:3306/dormitory_db?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai"; String username="root"; String password="18227022334a"; -
連接資料庫:
Connection conn= DriverManager.getConnection(url,username,password); -
創建執行sql陳述句的Statement物件:
Statement statement=conn.createStatement(); -
執行sql陳述句:
String sql="SELECT * from room;"; ResultSet resultSet = statement.executeQuery(sql); //遍歷結果集獲得資料 while (resultSet.next()){ System.out.println(resultSet.getObject("id")); System.out.println(resultSet.getObject("number")); System.out.println(resultSet.getObject("building_name")); System.out.println(resultSet.getObject("max_capacity")); } -
釋放連接:
resultSet.close(); statement.close(); conn.close();
-
-
連接資料庫各物件:
-
DriverManager:
Class.forName("com.mysql.jdbc.cj.Driver"); //加載資料庫驅動 DriverManager.getConnection(url,username,password);//獲得一個資料庫的連接物件 //url成分分析 // jdbc:mysql://主機名:埠號/資料庫名?引數 -
connection:
//相當于資料庫 connection.commit();//事務提交 connection.rollback();//事務回滾 connection.setAutoCommit();//設定自事務動提交 connection.createStatement();//創建一個執行sql陳述句的 -
Statement:
statement.executeQuery(sql);//執行查詢陳述句,回傳結果集 statement.execute(sql);//執行任何陳述句 statement.executeUpdate(sql);//執行更新,插入,洗掉陳述句,回傳受影響的行數 -
resulSet:
//遍歷結果集 resultSet.next();//游標移動到下一行,注:游標一開始是在第一行前面 //獲得資料 resultSet.getObject();//不知道型別情況下使用 resultSet.getXXX();//XXX為基本資料型別,根據指定的資料型別獲得資料
注:在最后都應該釋放資源,釋放的原則遵循:假如創建時順序為abc,那么釋放是cba
-
-
Statement物件存在的問題:sql注入問題且效率低
//比如:模擬一個用戶登錄的場景 //假設存在一個login(username,password) //由于使用statement執行sql陳述句時,傳入了引數,則需要使用字串的拼接 String sql="select * from student where name ='"+name+"' and password = '"+"';"; //當用戶非法傳入進行字串的拼接時,就會導致資料庫的泄露,比如 login("' or '1=1'","' or '1=1'"); /*此時會查詢出資料庫student表所有資訊,因為引數傳進來進行拼接后成為 select * from student where name ="" or '1=1' and password="" or '1=1'; */ -
使用PreStatement物件:
public int execUpdate(String sql, Object[] parms) { int count = 0; try { this.getConn(); ps = conn.prepareStatement(sql); if (parms != null) { for (int i = 0; i < parms.length; i++) { ps.setObject(i + 1, parms[i]); } } count = ps.executeUpdate(); return count; } catch (SQLException e) { e.printStackTrace(); } finally { //關閉資料庫連接 this.closeConn(conn, resultSet, ps); } return count; }注:PreparedStatement 防止 SQL 注入的原理就是把用戶非法輸入的單引號進行轉義,最終傳入引數作為一個整體執行,從而防止 SQL 注入,而 Statement 物件不會進行此操作,
-
idea操作資料庫
-
jdbc操作事務:
1、獲得connection物件
2、設定conn.setAutoCommit(false);
3、只有執行conn.commit();才會一起提交,否則不會一起提交 conn.rollback(); 回滾方法
public void test(){ try { this.getConn(); String sql1="update user set money=money-500 where user_name='張三'"; String sql2="update user set money=money+500 where user_name='李四'"; conn.setAutoCommit(false);//關閉自動提交,開啟事務 conn.prepareStatement(sql1).executeUpdate(); int x=1/0;//模擬中途出錯 conn.prepareStatement(sql2).executeUpdate(); conn.commit();//事務提交 } catch (SQLException e) { try { conn.rollback();//執行失敗,事務回滾 } catch (SQLException ex) { ex.printStackTrace(); } e.printStackTrace(); }finally { closeConn(conn,null,null); } } -
資料庫連接池:
-
資料庫連接--執行完畢--釋放
由于連接--釋放十分浪費系統資源,故而開發出池化技術
池化技術:準備一些預先的資源,連接時連接預先準備好的
比如:
資料庫最大資源數:20
假設常用連接數:10
那么最大連接數:20
小于10的連接數直接使用,超過10小于20則需要使用備用的資源
超過20那么進行一個等待
如果等待時間過長,那么等待超時
-
撰寫連接池:實作一個介面DataSource
-
開源資料源:DBCP,C3P0,Druid:阿里巴巴,當使用了資料庫連接池之后就不用我們自己去實作資料庫的連接的代碼的撰寫了
- DBCP:dataSource= BasicDataSourceFactory.createDataSource(),該資料源的相關資訊是通過一個propertiee檔案保存的,在配置資料源時直接讀取該屬性檔案資訊,
- C3P0:ComboPooledDataSource dataSource = new ComboPooledDataSource();該資料源資訊是通過一個xml檔案進行配置的,并且它可以配備多個資料源,在使用的時候可以指定使用哪個資料源,
注:使用資料庫連接池都是需要去實作一個dataSource介面,
-
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500213.html
標籤:其他
上一篇:SQL陳述句實戰學習
下一篇:未來資料庫需要關心的硬核創新