14 | count(*)這么慢,我該怎么辦?
在開發系統的時候,你可能經常需要計算一個表的行數,比如一個交易系統的所有變更記錄總數,
隨著系統中記錄數越來越多,select count(*) from t 陳述句執行得也會越來越慢
count(*) 的實作方式
在不同的 MySQL 引擎中,count(*) 有不同的實作方式,
- MyISAM 引擎把一個表的總行數存在了磁盤上,因此執行 count(*) 的時候會直接回傳這個數,效率很高;
- 而 InnoDB 引擎執行 count(*) 的時候,需要把資料一行一行地從引擎里面讀出來,然后累積計數,
這里討論的是沒有過濾條件的 count(*),如果加了 where 條件的話,MyISAM 表也是不能回傳得這么快的,
Q:為什么 InnoDB 不跟 MyISAM 一樣,也把數字存起來呢?
A:因為即使是在同一個時刻的多個查詢,由于多版本并發控制(MVCC)的原因,InnoDB 表“應該回傳多少行”也是不確定的,
舉個例子:
假設表 t 中現在有 10000 條記錄,我們設計了三個用戶并行的會話,
- 會話 A 先啟動事務并查詢一次表的總行數;
- 會話 B 啟動事務,插入一行后記錄后,查詢表的總行數;
- 會話 C 先啟動一個單獨的陳述句,插入一行記錄后,查詢表的總行數,

在最后一個時刻,三個會話 A、B、C 會同時查詢表 t 的總行數,但拿到的結果卻不同,
這和 InnoDB 的事務設計有關系,可重復讀是它默認的隔離級別,在代碼上就是通過多版本并發控制,也就是 MVCC 來實作的,每一行記錄都要判斷自己是否對這個會話可見,因此對于 count(*) 請求來說,InnoDB 只好把資料一行一行地讀出依次判斷,可見的行才能夠用于計算“基于這個查詢”的表的總行數,
在執行 count(*) 操作時的優化
InnoDB 是索引組織表,主鍵索引樹的葉子節點是資料,而普通索引樹的葉子節點是主鍵值,所以,普通索引樹比主鍵索引樹小很多,對于 count(*) 這樣的操作,遍歷哪個索引樹得到的結果邏輯上都是一樣的,因此,MySQL 優化器會找到最小的那棵樹來遍歷,
在保證邏輯正確的前提下,盡量減少掃描的資料量,是資料庫系統設計的通用法則之一,
Q:TABLE_ROWS 能代替 count(*) 嗎?
A:show table status 命令輸出結果是 TABLE_ROWS ,但是實際上,TABLE_ROWS 是從采樣估算得來的,因此它很不準,所以,show table status 命令顯示的行數也不能直接使用,
小結
- MyISAM 表雖然 count(*) 很快,但是不支持事務;
- show table status 命令雖然回傳很快,但是不準確;
- InnoDB 表直接 count(*) 會遍歷全表,雖然結果準確,但會導致性能問題,
如果你現在有一個頁面經常要顯示交易系統的操作記錄總數,只能自己計數
自己計數的方法以及優缺點
用快取系統保存計數
可以用一個 Redis 服務來保存這個表的總行數,這個表每被插入一行 Redis 計數就加 1,每被洗掉一行 Redis 計數就減 1,
這種方式下,讀和更新操作都很快
存在問題:Redis 的資料不能永久地留在記憶體里,快取系統可能會丟失更新
解決方法:找一個地方把這個值定期地持久化存盤起來,
存在問題:即使持久話存盤,仍然可能丟失更新,試想如果剛剛在資料表中插入了一行,Redis 中保存的值也加了 1,然后 Redis 例外重啟了,重啟后你要從存盤 redis 資料的地方把這個值讀回來,而剛剛加 1 的這個計數操作卻丟失了,
解決方法:Redis 例外重啟以后,到資料庫里面單獨執行一次 count(*) 獲取真實的行數,再把這個值寫回到 Redis 里就可以了,例外重啟畢竟不是經常出現的情況,這一次全表掃描的成本,可以接受,
存在問題:即使 Redis 正常作業,這個值還是邏輯上不精確的,
假設存在一個頁面,要顯示操作記錄的總數,同時還要顯示最近操作的 100 條記錄,那么,這個頁面的邏輯就需要先到 Redis 里面取出計數,再到資料表里面取資料記錄,
可能存在兩種情況:
- 一種是,查到的 100 行結果里面有最新插入記錄,而 Redis 的計數里還沒加 1;
- 另一種是,查到的 100 行結果里沒有最新插入的記錄,而 Redis 的計數里已經加了 1,
情況1:
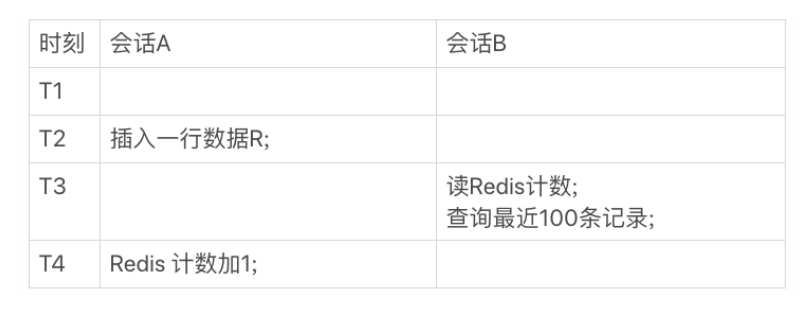
會話 A 是一個插入交易記錄的邏輯,往資料表里插入一行 R,然后 Redis 計數加 1;會話 B 就是查詢頁面顯示時需要的資料,
在 T3 時刻會話 B 來查詢的時候,會顯示出新插入的 R 這個記錄,但是 Redis 的計數還沒加 1,這時候,就會出現資料不一致,
情況2:
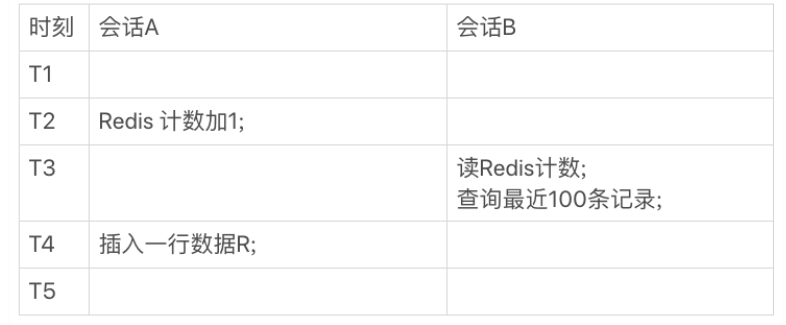
會話 B 在 T3 時刻查詢的時候,Redis 計數加了 1 了,但還查不到新插入的 R 這一行,也是資料不一致的情況,
在并發系統里面,我們是無法精確控制不同執行緒的執行時刻的,因為存在圖中的這種操作序列,所以,我們說即使 Redis 正常作業,這個計數值還是邏輯上不精確的,
兩個不同的存盤構成的系統,不支持分布式事務,無法拿到精確一致的視圖,
在資料庫保存計數(優)
這個計數直接放到資料庫里單獨的一張計數表 C 中
解決了崩潰丟失的問題,InnoDB 是支持崩潰恢復不丟資料的,
解決計數不精確的問題,由于事務,存在不可見,邏輯上就是一致的,

雖然會話 B 的讀操作仍然是在 T3 執行的,但是因為這時候更新事務還沒有提交,所以計數值加 1 這個操作對會話 B 還不可見,因此,會話 B 看到的結果里, 查計數值和“最近 100 條記錄”看到的結果,邏輯上就是一致的,
不同的 count 用法
Q:在 select count(?) from t 這樣的查詢陳述句里面,count(*)、count(主鍵 id)、count(欄位) 和 count(1) 等不同用法的性能,有哪些差別?
A:
count() 的語意
count() 是一個聚合函式,對于回傳的結果集,一行行地判斷,如果 count 函式的引數不是 NULL,累計值就加 1,否則不加,最后回傳累計值,
所以,count(*)、count(主鍵 id) 和 count(1) 都表示回傳滿足條件的結果集的總行數;而 count(欄位),則表示回傳滿足條件的資料行里面,引數“欄位”不為 NULL 的總個數,
分析性能差別的原則
- server 層要什么就給什么;
- InnoDB 只給必要的值;
- 現在的優化器只優化了 count(*) 的語意為“取行數”,其他“顯而易見”的優化并沒有做,
對于 count(主鍵 id) 來說,InnoDB 引擎會遍歷整張表,把每一行的 id 值都取出來,回傳給 server 層,server 層拿到 id 后,判斷是不可能為空的,就按行累加,
對于 count(1) 來說,InnoDB 引擎遍歷整張表,但不取值,server 層對于回傳的每一行,放一個數字“1”進去,判斷是不可能為空的,按行累加,
單看這兩個用法的差別的話,count(1) 執行得要比 count(主鍵 id) 快,因為從引擎回傳 id 會涉及到決議資料行,以及拷貝欄位值的操作,
對于 count(欄位) 來說:
- 如果這個“欄位”是定義為 not null 的話,一行行地從記錄里面讀出這個欄位,判斷不能為 null,按行累加;
- 如果這個“欄位”定義允許為 null,那么執行的時候,判斷到有可能是 null,還要把值取出來再判斷一下,不是 null 才累加,
也就是前面的第一條原則,server 層要什么欄位,InnoDB 就回傳什么欄位,
但是 count(*) 是例外,并不會把全部欄位取出來,而是專門做了優化,不取值,count(*) 肯定不是 null,按行累加,
Q:優化器就不能自己判斷一下嗎,主鍵 id 肯定非空啊,為什么不能按照 count(*) 來處理
A:MySQL 專門針對這個陳述句進行優化,也不是不可以,但是這種需要專門優化的情況太多了,而且 MySQL 已經優化過 count(*) 了,直接使用這種用法就可以了,
結論:
按照效率排序的話,count(欄位)<count(主鍵 id)<count(1)≈count(*),所以我建議你,盡量使用 count(*),
Q:先前用事務來確保計數準確,由于事務可以保證中間結果不被別的事務讀到,因此修改計數值和插入新記錄的順序是不影響邏輯結果的,但是,從并發系統性能的角度考慮,你覺得在這個事務序列里,應該先插入操作記錄(insert into t),還是應該先更新計數表(update cnt_t)呢?
A:
并發系統性能的角度考慮,應該先插入操作記錄,再更新計數表,
- 更新計數表涉及到行鎖的競爭,先插入再更新能最大程度地減少事務之間的鎖等待,提升并發度,
PS:計數表保存了多個業務表的計數值不會導致行鎖等待,
用一個計數表記錄多個業務表的行數,也肯定會給表名欄位加唯一索引,類似于下面這樣的表結構:
CREATE TABLE `rows_stat` (
`table_name` varchar(64) NOT NULL,
`row_count` int(10) unsigned NOT NULL,
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB;
在更新計數表的時候,一定會傳入where table_name=$table_name,使用主鍵索引,更新加行鎖只會鎖在一行上,而在不同業務表插入資料,是更新不同的行,不會有行鎖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500323.html
標籤:MySQL
下一篇:MySQL實戰45講 15