1、行轉列
源資料:
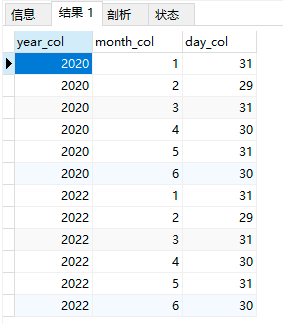
目標資料:
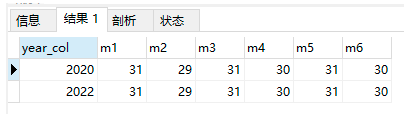
資料準備
-- 建表插入資料
drop table if exists time_temp;
create table if not exists time_temp(
`year_col` int not null comment '年份',
`month_col` int not null comment '月份',
`day_col` int not null comment '天數'
)engine = innodb default charset = utf8;
insert into time_temp values
(2020,1,31),
(2020,2,29),
(2020,3,31),
(2020,4,30),
(2020,5,31),
(2020,6,30);
insert into time_temp values
(2022,1,31),
(2022,2,29),
(2022,3,31),
(2022,4,30),
(2022,5,31),
(2022,6,30);
1.1 方式1 分組+子查詢
-- 將資料根據年份分組,然后在進行子查詢通過月份查出對應的天數;
select t.year_col,
(select t1.day_col from time_temp t1 where t1.month_col = 1 and t1.year_col = t.year_col) 'm1',
(select t1.day_col from time_temp t1 where t1.month_col = 2 and t1.year_col = t.year_col) 'm2',
(select t1.day_col from time_temp t1 where t1.month_col = 3 and t1.year_col = t.year_col) 'm3',
(select t1.day_col from time_temp t1 where t1.month_col = 4 and t1.year_col = t.year_col) 'm4',
(select t1.day_col from time_temp t1 where t1.month_col = 5 and t1.year_col = t.year_col) 'm5',
(select t1.day_col from time_temp t1 where t1.month_col = 6 and t1.year_col = t.year_col) 'm6'
from time_temp t
group by t.year_col;
1.2 方式2:分組+case when
-- 先根據年份分組,在根據case when .. then ... 條件判斷 輸入出指定列的資訊
select t.year_col,
min(case when t.month_col = 1 then t.day_col end) 'm1',
min(case when t.month_col = 2 then t.day_col end) 'm2',
min(case when t.month_col = 3 then t.day_col end) 'm3',
min(case when t.month_col = 4 then t.day_col end) 'm4',
min(case when t.month_col = 5 then t.day_col end) 'm5',
min(case when t.month_col = 6 then t.day_col end) 'm6'
from time_temp t
group by t.year_col;
2、洗掉重復資料
思路:先查詢出需要保留的資料,然后洗掉其他的資料;
-- ====================洗掉重復資料=========================
DROP TABLE IF EXISTS `results_temp`;
CREATE TABLE `results_temp`(
`id` int primary key auto_increment comment '主鍵',
`stu_no` int NOT NULL COMMENT '學號',
`subj_no` int NOT NULL COMMENT '課程編號',
`exam_date` datetime NOT NULL COMMENT '考試時間',
`stu_result` int NOT NULL COMMENT '考試成績'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '成績表臨時' ROW_FORMAT = Dynamic;
-- 將另外一張表的資料插入到此表中(也可以用其他方式插資料,這里時為了方便) 插入兩次,讓資料重復
insert into results_temp (stu_no,subj_no,exam_date,stu_result)
select stu_no,subj_no,exam_date,stu_result
from results
where subj_no = 1;
-- 查詢資料,每個學生的同一門課程的成績有兩個,或者多個
select * from results_temp
order by stu_no desc;
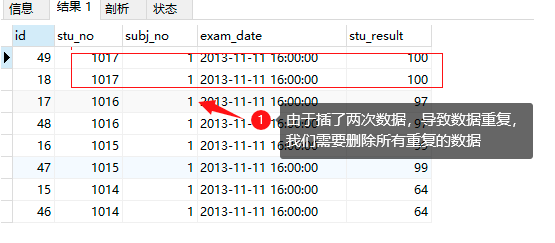
解決方法:篩選出我們需要的資料,其他資料洗掉;
-- 剔除重復的學生成績,只保留一份
-- 我們要保留的資料
select min(id) from results_temp
group by stu_no;
delete from results_temp
where id not in( -- 除了我們要保留的資料其他資料都洗掉
select * from(
select min(id) from results_temp -- 我們要保留的資料
group by stu_no
) rt
);
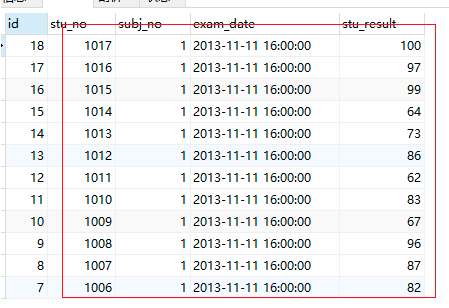
再次執行SQL重復資料洗掉成功
select * from results_temp
order by stu_no desc;
3、如果一張表,沒有id自增主鍵,實作自定義一個序號
實作思路:通過定義一個變數,查詢到一行資料就對變數 +1;
使用@關鍵字創建“用戶變數”;
mysql中變數不用事前申明,在用的時候直接用“@變數名”,
第一種用法:set @num=1; 或set @num:=1;
第二種用法:select @num:=1; 也可以把欄位的值賦值給變數 select @num:=欄位名 from 表名 where ……
注意上面兩種賦值符號,使用set時可以用 = 或 := ,但是使用select時必須用 :=
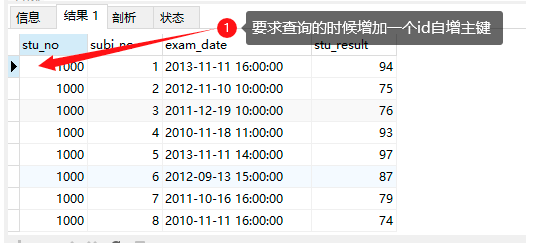
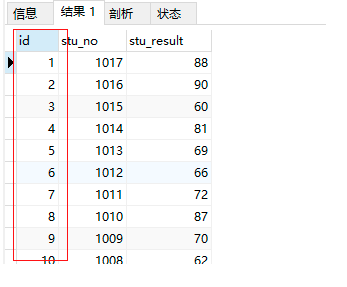
SQL實作
select @rownum:=@rownum + 1 'id',stu_no,stu_result -- @rownum:=@rownum + 1 每查詢出一條資料就對變數 @rownum 加一
from results,
(select @rownum:= 0) rowss -- 宣告:前面要使用 @rownum 要在這里(form后面)先宣告并賦值為0 @rownum:= 0 ,前面才可以使用
where subj_no = 2
order by stu_no desc;
4、約束
4.1 主鍵約束 primary key
4.1.1 創建表和約束
-- 主鍵約束
create table employees_temp1(
emp_id int primary key,
emp_name varchar(50)
)engine = innodb charset = utf8;
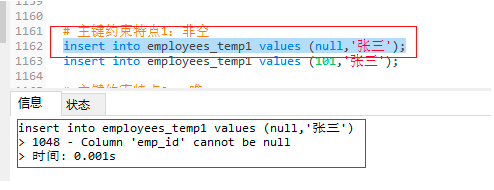
4.1.2 主鍵約束特點1:非空
insert into employees_temp1 values (null,'張三'); -- 添加一條資料,主鍵為空
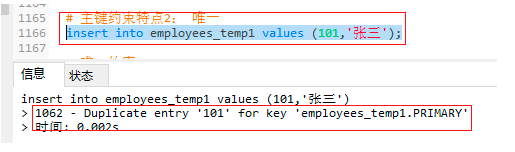
4.1.3 主鍵約束特點2: 唯一
insert into employees_temp1 values (101,'張三');
insert into employees_temp1 values (101,'張三'); -- 插入兩個相同的資料
4.2 唯一約束 unique
4.2.1 創建表和唯一約束
-- 唯一約束,
create table employees_temp2(
emp_id int primary key,
emp_name varchar(50),
emp_tel char(11) unique -- 使用列級別宣告
)engine = innodb charset = utf8;
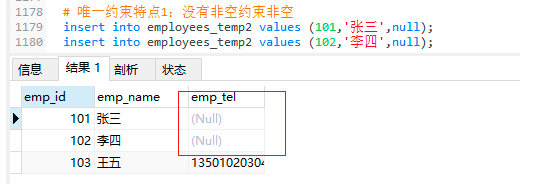
4.2.2 唯一約束特點1:沒有非空約束非空
-- 唯一約束特點1:沒有非空約束非空
insert into employees_temp2 values (101,'張三',null); -- 可以插入null值
insert into employees_temp2 values (102,'李四',null);
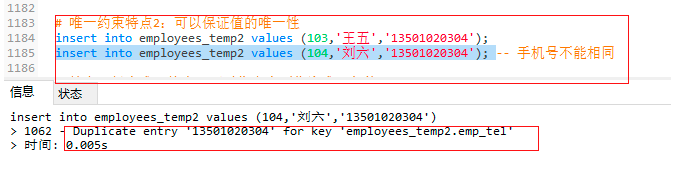
4.2.3 唯一約束特點2:可以保證值的唯一性
-- 唯一約束特點2:可以保證值的唯一性
insert into employees_temp2 values (103,'王五','13501020304');
insert into employees_temp2 values (104,'劉六','13501020304'); -- 手機號不能相同
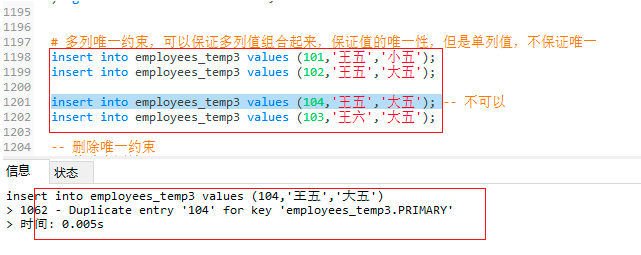
4.2.4 組合唯一約束
-- 補充:組合唯一約束,可以指定多列作為唯一條件
create table employees_temp3(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
-- 使用表級別宣告,真實姓名和昵稱的組合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick)
)engine = innodb charset = utf8;
-- 多列唯一約束,可以保證多列值組合起來,保證值的唯一性,但是單列值,不保證唯一
insert into employees_temp3 values (101,'王五','小五');
insert into employees_temp3 values (102,'王五','大五');
insert into employees_temp3 values (104,'王五','大五'); -- 不可以
insert into employees_temp3 values (103,'王六','大五');
4.2.5 洗掉唯一約束
-- 修改表語法
-- alter table 表名 drop 約束名
alter table employees_temp3 drop index uk_emp_name_nick;
-- drop 語法
-- drop index 約束名 on 表名
drop index uk_emp_name_nick on employees_tem
4.3 外鍵約束 delete時的級聯洗掉和級聯置空
4.3.1 級聯洗掉 on delete cascade
-- 級聯洗掉
-- 創建部門表
drop table if exists departments_temp1;
create table departments_temp1(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
-- 插入部門資料
insert into departments_temp1 values(100,'研發部'),(200,'市場部')
-- 創建員工表 和外鍵約束
drop table if exists employees_temp4;
create table employees_temp4(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表級宣告,增加部門編號的外鍵約束,并指定級聯洗掉
constraint fk_emp_dept_id foreign key (dept_id)
references departments_temp1(dept_id)
on delete cascade
)engine = innodb charset = utf8;
-- 插入員工資料
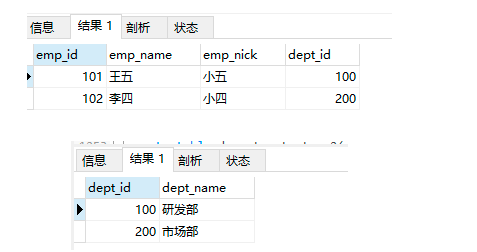
insert into employees_temp4 values (101,'王五','小五',100);
insert into employees_temp4 values (102,'李四','小四',200);
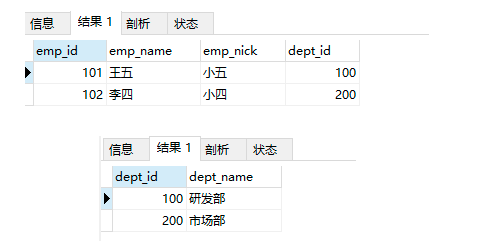
查詢資料:
select * from employees_temp4;
select * from departments_temp1;
-- 當設定外鍵屬性為級聯洗掉時,洗掉部門表中的資料,自動將所有關聯表中的外鍵資料,一并洗掉
delete from departments_temp1 where dept_id = 100;
-- 再次查詢資料:
select * from employees_temp4;
select * from departments_temp1;
-- 部門洗掉后,該部門的資料也被洗掉了
4.3.2 級聯洗掉置空 on delete set null
-- 級聯置空
-- 創建部門表
drop table if exists departments_temp2;
create table departments_temp2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
-- 插入部門資料
insert into departments_temp2 values(100,'研發部'),(200,'市場部')
-- 創建員工表和外鍵約束
drop table if exists employees_temp5;
create table employees_temp5(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表級宣告,增加部門編號的外鍵約束,并指定級聯洗掉
constraint fk_null_emp_dept_id foreign key (dept_id)
references departments_temp2(dept_id)
on delete set null
)engine = innodb charset = utf8;
-- 插入員工資料
insert into employees_temp5 values (101,'王五','小五',100);
insert into employees_temp5 values (102,'李四','小四',200)
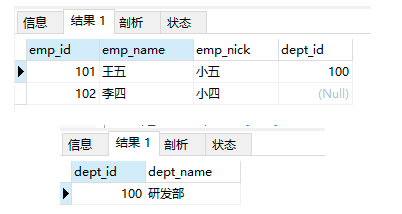
查詢資料:
select * from employees_temp5;
select * from departments_temp2;
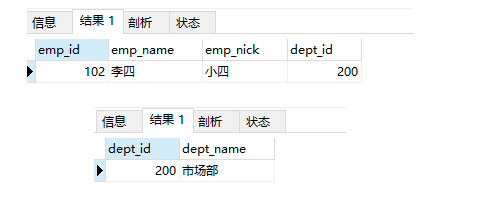
-- 當設定外鍵屬性為級聯置空時,洗掉部門表中的資料,自動將所有關聯表中的外鍵資料,一并置空
delete from departments_temp2 where dept_id = 200;
select * from employees_temp5;
select * from departments_temp2;
-- 部門被洗掉后,該部門的資料被置空
4.4 外鍵約束 update時的級聯更新和級聯置空
4.4.1 級聯更新 on update cascade
-- -- ================ update 的級聯洗掉和級聯置空==========
drop table if exists departments_temp1_2;
create table departments_temp1_2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
insert into departments_temp1_2 values(100,'研發部'),(200,'市場部')
drop table if exists employees_temp4_2;
create table employees_temp4_2(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
# 使用表級宣告,真實姓名和昵稱是組合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick),
-- 使用表級宣告,增加部門編號的外鍵約束,并指定級聯更行修改
constraint fk_emp_dept_id_update foreign key (dept_id)
references departments_temp1_2(dept_id)
on update cascade -- 更新部門表中的資料,自動將所有關聯表中的外鍵資料,一并更新
)engine = innodb charset = utf8;
insert into employees_temp4_2 values (101,'王五','小五',100);
insert into employees_temp4_2 values (102,'李四','小四',200);
查詢資料:
select * from employees_temp4_2;
select * from departments_temp1_2;
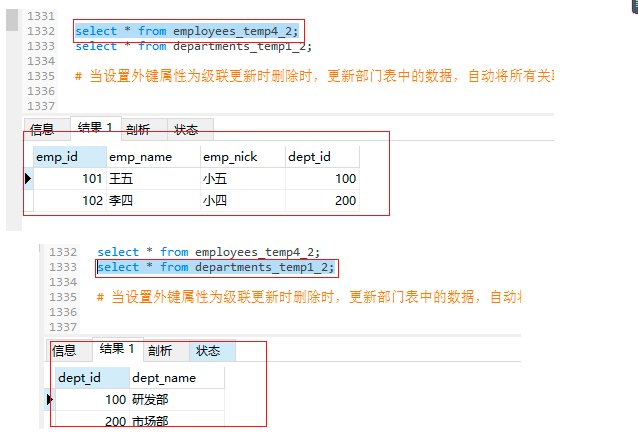
部門表資料更新:
-- 當設定外鍵屬性為級聯更新時洗掉時,更新部門表中的資料,自動將所有關聯表中的外鍵資料,一并更新
update departments_temp1_2 set dept_id = 111 where dept_id = 100;
-- 再次查詢資料
select * from employees_temp4_2;
select * from departments_temp1_2;
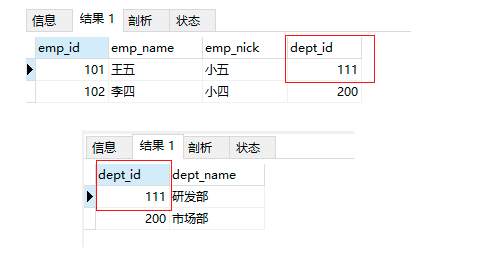
4.4.2 級聯更新置空
-- ==================update 級聯更新置空========================
drop table if exists departments_temp2_2;
create table departments_temp2_2(
dept_id int primary key,
dept_name varchar(50)
)engine = innodb charset = utf8;
insert into departments_temp2_2 values(100,'研發部'),(200,'市場部')
drop table if exists employees_temp5_2;
create table employees_temp5_2(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int,
-- 使用表級宣告,增加部門編號的外鍵約束,并指定級聯更新置空
constraint fk_emp_dept_id_update2 foreign key (dept_id)
references departments_temp2_2(dept_id)
on update set null
)engine = innodb charset = utf8;
select * from employees_temp5_2;
select * from departments_temp2_2;
查詢資料:
insert into employees_temp5_2 values (101,'王五','小五',100);
insert into employees_temp5_2 values (102,'李四','小四',200);

部門表資料更新
-- 當設定外鍵屬性為級聯置空時,更新部門表中的資料,自動將所有關聯表中的外鍵資料,一并置空
update departments_temp2_2 set dept_id = 111 where dept_id = 100;
-- 再次查詢資料
select * from employees_temp5_2;
select * from departments_temp2_2;

4.5 非空約束
-- 非空約束
drop table if exists employees_temp6;
create table employees_temp6(
emp_id int primary key,
emp_name varchar(50),
emp_nick char(11),
dept_id int not null,
-- 使用表級宣告,真實姓名和昵稱是組合唯一
constraint uk_emp_name_nick unique(emp_name,emp_nick)
)engine = innodb charset = utf8;
-- 增加非空約束列,插入資料時,必須保證該列有效值,或者默認值,但不能為null
insert into employees_temp6 values (101,'王五','小五',100);
insert into employees_temp6 values (102,'李四','小四',null); -- 不能插入,因為 dept_id 設定了不能為空
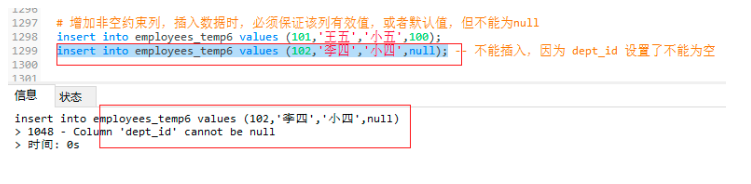
5、索引
5.1分類
- 主鍵索引(主鍵約束) primary key
- 唯一索引(唯一約束) unique
- 普通索引 index/key
- 全文索引fulltext (存盤引擎必須時MyISAM)
5.2 作用
為了提高資料庫的查詢效率(SQL執行性能) ,底層索引演算法是B+樹(BTree);
5.3 建議
索引的創建和管理是資料庫負責,開發人員無權干涉,原因:查詢資料是否走索引,是資料庫決定,底層演算法覺得走索引查詢效率高就走索引,如果覺得不走索引查詢效率高,就不走索引,在寫SQL陳述句時,盡量要避免索引失效(SQL調優);
5.4 注意
1.不是索引越多越好,資料庫底層要管理索引,也需要耗費資源和性能(資料庫性能會下降);
2.如果當前列資料重復率較高,比如性別,不建議使用索引;
3.如果當前列內容,經常改變,不建議使用索引,因為資料頻繁修改要頻繁的維護索引,性能會下降;
4.小資料量的表也不推薦索引,因為小表的查詢效率本身就很快;
5.5 強調
一般索引都是加在where,order by 等子句經常設計的列欄位,提高查詢性能;
主鍵索引和唯一索引,對應列查詢資料效率高;
5.6 建表時添加索引
-- 普通索引的創建1,建表時添加
drop table if exists employees_temp7;
create table employees_temp7(
emp_id int primary key,
emp_name varchar(50),
index index_emp_name (emp_name)
)engine = innodb charset = utf8;
5.7 建表后添加索引
-- 普通索引的創建2,建表后添加
drop table if exists employees_temp8;
create table employees_temp8(
emp_id int primary key,
emp_name varchar(50)
)engine = innodb charset = utf8;
-- 使用修改表語法,添加索引
alter table employees_temp8 add index index_emp_name_new(emp_name);
5.8 查看表的索引
-- 查看表的索引語法
show index from employees_temp7;
show index from employees_temp8;
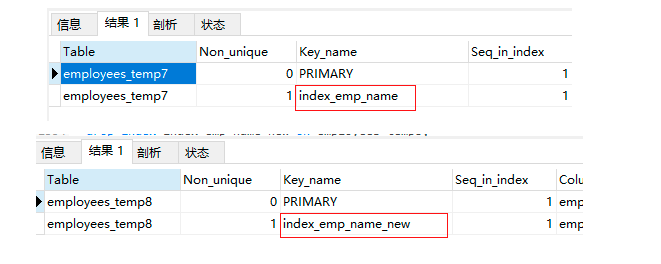
5.9 洗掉索引
-- 洗掉索引1
alter table employees_temp7 drop index index_emp_name;
show index from employees_temp7;

-- 洗掉索引2
drop index index_emp_name_new on employees_temp8;
show index from employees_temp8;

5.10 分析執行陳述句的執行性能
-- 分析執行陳述句的執行性能
-- 查看SQL陳述句的執行計劃,通過分析執行計劃結果,優化SQL陳述句,提示查詢性能
-- 使用 explain select 陳述句,可以看SQL是全表查詢還是走了索引等
-- 先把索引添加回來
alter table employees_temp8 add index index_emp_name_new(emp_name);
explain select * from employees_temp8;

5.10 全文索引
-- 全文索引
-- 快速進行全表資料的定位,是使用與MyISAM存盤引擎表,而且只適用于char,varchar,text等資料型別
drop table if exists employees_temp9;
create table employees_temp9(
emp_id int primary key,
emp_name varchar(50),
fulltext findex_emp_name(emp_name)
)engine = myisam charset = utf8;
6、存盤程序
6.1 帶入參存盤程序
-- 作用:可以進行程式撰寫,實作整個業務邏輯單元的多條SQL陳述句的批量執行;比如:插入表10W資料
-- 帶入參的存盤程序
-- delimiter // 將MySQL結束符號更改為 // ,其他符號也可以
delimiter //
create procedure query_employee_by_id(in empId int)
begin
select * from employees_temp6 where emp_id = empId;
end//
-- 呼叫存盤程序
call query_employee_by_id(101);
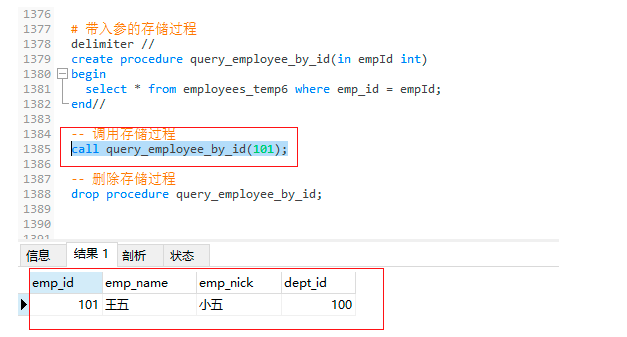
-- 洗掉存盤程序
drop procedure query_employee_by_id;
6.2 帶出參存盤程序
-- 帶出參的存盤程序
delimiter //
create procedure query_employee_by_count(out empNum int)
begin
select count(1) into empNum from employees_temp6;
end//
-- 呼叫
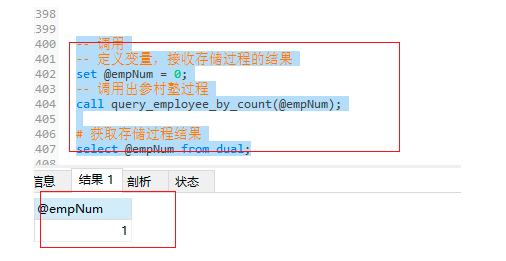
-- 定義變數,接收存盤程序的結果
set @empNum = 0;
-- 呼叫出參村塾程序
call query_employee_by_count(@empNum);
-- 獲取存盤程序結果
select @empNum from dual;
6.3 自定義存盤程序
-- 自定義存盤程序,實作出入一個數值,并計算該值內的所有奇數之和,并輸出結果
delimiter //
create procedure sum_odd(in num int)
begin
declare i int; -- 先定義,后賦值
declare sums int;
set i = 0;
set sums = 0;
-- declare i int default 0; -- 定義后直接賦默認值
-- declare sums int default 0;
while i <= num do
if i % 2 = 1 then
set sums = sums + i;
end if;
set i = i + 1;
end while;
-- 輸出結果
select sums from dual;
end
//
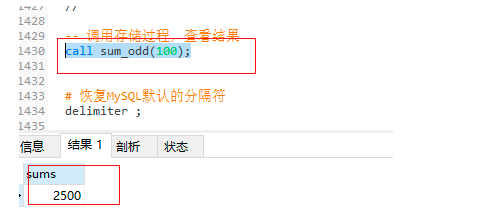
-- 呼叫存盤程序,查看結果
call sum_odd(100);
-- 恢復MySQL默認的分隔符 注意在最后一定要執行一遍整個陳述句
delimiter ;
7、觸發器
7.1 觸發器語法
-
創建類似于存盤程序
-
語法:create trigger trigger_name trigger_time trigger_event on tab_name for each row trigger_stmt
- trigger_name:觸發器名
- trigger_time 觸發時機 befor,after
- trigger_event 觸發事件, 取值:insert,update,delete
- tab_name: 觸發器作用的表名,即在那張表上建立觸發器,如果對該表操作,觸發器會自動生效
- trigger_stmt: 觸發事件的執行程式主體,可以是一條SQL,也可以是使用begin...end 包含的duoSQL陳述句
7.2 觸發器分類 (6種)
before 和 after 與 insert,update,delete的組合:
- before insert, before update, before delete
- after insert, after update, after delete
7.3 簡單案例
-- 簡單案例,當對指定表洗掉資料時,自動將該條洗掉的資料備份
drop table if exists employees_temp10;
create table employees_temp10(
emp_id int primary key,
emp_name varchar(50),
emp_time datetime
)engine = innodb charset = utf8;
insert into employees_temp10 values (101,'王五',now());
drop table if exists employees_temp10_his;
create table employees_temp10_his(
emp_id int primary key,
emp_name varchar(50),
emp_time datetime
)engine = innodb charset = utf8;
-- 自定義觸發器
-- NEW 和 OLD 含義:代表觸發器所在表中,當對資料操作時,觸發觸發器的那條資料
-- 對于insert觸發事件:NEW 表示插入后的新資料
-- 對于update觸發事件:NEW 表示修改后的資料,OLD表示被修改前的原資料
-- 對于delete出發時間:OLD 表示被洗掉前的資料
-- 語法:NEW/OLD.表中的列名
delimiter //
create trigger backup_employees_temp10_delete
after delete
on employees_temp10
for each row
begin
insert into employees_temp10_his(emp_id,emp_name,emp_time)
value (OLD.emp_id,OLD.emp_name,OLD.emp_time);
end
//
delimiter ;
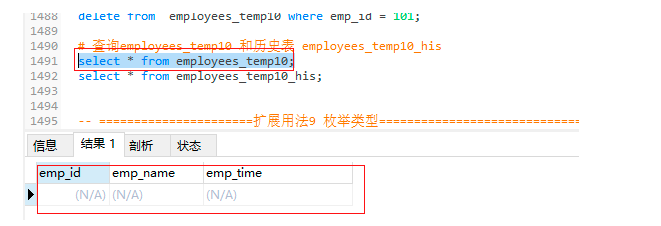
-- 洗掉employees_temp10 中的資料
delete from employees_temp10 where emp_id = 101;
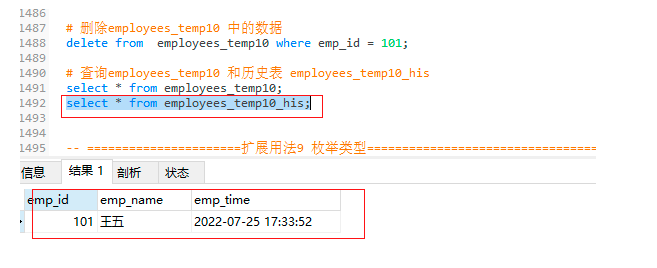
-- 查詢employees_temp10 和歷史表 employees_temp10_his
select * from employees_temp10;
select * from employees_temp10_his;
employees_temp10表:
employees_temp10_his表:
8、資料集合連接(union 和 union all)
-- 快速建表,直接將查詢的資料建成一張表
-- crate table table_name (select_SQL)
create table employees_temp11(select * from employees where department_id in(50,60));
create table employees_temp12(select * from employees where department_id in(60,70));
-- 兩張表有重復的資料 department_id = 60
8.1 union
-- union 連接:union前的那個SQL陳述句,不能是分號結尾
-- 查詢結果連接,會自動去重,相同的資料只保留一份
-- 結果51條,50號部門45條,50號部門5條,70號部門1條,執行自動去重
select department_id,employee_id
from employees_temp11
union -- 查詢的資料會去重
select department_id,employee_id
from employees_temp12;
8.2 union all
-- 結果56條,50號部門45條,50號部門5條,70號部門1條,執行連接,不會自動去重,相同的資料任然會保留
select department_id,employee_id
from employees_temp11
union all --查詢到的資料不會去重
select department_id,employee_id
from employees_temp12;
8.3 union all
-- 連接兩條SQL陳述句,查詢結果列,上下列個數要統一,否則會報錯,也可以寫*(表結構統一)
select department_id,department_id,Last_name
from employees_temp11
union all
select department_id,department_id,hire_date
from employees_temp12;
-- 別名處理
-- 如果第一個SQL陳述句的結果集使用了別名處理,自動作用到連接的后面結果集,但要單獨寫在后面就沒有效果
select department_id,department_id '部門編號',Last_name -- 有效果
from employees_temp11
union all
select department_id,department_id,hire_date
from employees_temp12;
select department_id,department_id,Last_name
from employees_temp11
union all
select department_id,department_id '部門編號',hire_date -- 無效果
from employees_temp12;
-- 連接查詢,默認是按照查詢結構第一列升序排序,也可以自定義
select employee_id,department_id '部門編號'
from employees_temp11
union all
select employee_id,department_id
from employees_temp12 order by employee_id desc;
9、視圖-view
視圖:view,是從表中抽離出(查詢出),在邏輯上有相關性的資料集合,它是一個虛表,
資料:視圖中的資料可以從一張表或者多張表查詢,視圖的結構和資料都依賴于基本表(原始表);
通過視圖可以直接查看到基本表中的資料,且可以直接操作,增刪改查;
理解:可以將視圖理解為被存盤起來的SQL陳述句,就是select陳述句;
特點:1.可以簡化SQL陳述句,經常需要執行的復雜sql陳述句我們可以通過視圖快取,簡化查詢資料及操作;
特點:2.提高安全性,通過視圖只能查詢和修改你看到的資料,其他資料你看不到也改不了,比如工資,密碼;
9.1創建視圖
-- 創建視圖
-- 普通視圖和復雜視圖
-- 創建視圖語法:
-- create or replace [{undefined | merge | temptable}]
-- view view_name [coll_list]
-- as
-- select_SQL
-- 創建視圖1:查詢50號部門的資料
create or replace view employee_view1
as
select employee_id,last_name,salary,department_id
from employees
where department_id = 50;
9.2 查詢視圖
-- 查詢視圖
select * from employee_view1;
9.3 查看視圖結構
-- 查看視圖的內容結構
desc employee_view2;
9.4 視圖特點
-- 視圖中的資料,不是固定的,實際上還是查詢的基礎表的資料,所以基礎表的資料發生改變,視圖的資料也會改變
select * from employee_view1 where last_name = 'Fripp';
-- 修改基礎表:employees,將Fripp的salary,從8200更改為9000
update employees set salary = 9000 where last_name = 'Fripp';
-- 視圖中的資料,由于是源于基礎表,跟基本表是有關系的,所以修改視圖,就是修改源表
select * from employee_view1 where last_name = 'Fripp';
-- 修改視圖 employee_view1 ,將Fripp的工資從9000更改為12000
update employees set salary = 12000 where last_name = 'Fripp';
-- 洗掉也是同理,洗掉視圖中的數,源表中的資料也會洗掉
-- 洗掉最低工資的Olson洗掉
delete from employee_view1 where last_name = 'Olson';
select * from employees where last_name = 'Olson';
9.5 修改視圖
-- 修改視圖
-- crate or replace view view_name as select_sql
-- 如果不加or replace ,第一次創建視圖是成功的,第二次會檢查視圖名是否存在,如果存在創建失敗
-- 如果加上or replace,發現已經存在會替換
create or replace view employee_view1
as
select employee_id,last_name,salary,department_id,manager_id
from employees
where department_id = 50;
-- 查看視圖
select * from employee_view1;
9.6 復雜視圖
-- 查詢員工表的所有部門的平均工資
create or replace view employee_view3
as
select d.department_id,d.department_name,avg(e.salary) 'salary_avg'
from employees e,departments d
where e.department_id = d.department_id
group by d.department_id;
-- 查詢視圖
select * from employee_view3;
# 復雜視圖說明:如果視圖是復雜視圖,對此視圖的增刪改操作
-- 一般是無效的,因為復雜視圖一般是有多表經過計算來的,所以資料庫不知道該怎么操作
-- 比如:分組,group by,聚合函式,去重等
-- 舉例:修改50號部門的平均工資
update employee_view3 set salary_avg = 6000 where department_id = 50; -- 不能修改
-- 洗掉視圖,語法類似與洗掉表,洗掉視圖定義,不會影響基本表
drop view employee_view3;
10、列舉型別
語法:enum(允許的值串列),比如:性別定義:gender enum('男','女');
好處1:可以實作對該列值的限制,非指定值串列的其他值,是部允許插入的,增加資料的安全性;
好處2:相對于字串型別純屬男或女,列舉可以節約存盤空間,原因:使用整數進行管理,取值范圍是2個位元組,有65535個選項可以使用;
場景:列中的值存在大量的重復資料,且是預先設定好的固定,并不容易發生改變;
10.1 創建列舉
-- 實體用法
drop table if exists employees_temp13;
create table if not exists employees_temp13(
emp_id int primary key auto_increment comment '編號',
emp_name varchar(32) not null comment '姓名',
emp_sex enum('男','女') comment '性別'
)engine innodb charset = utf8 comment '員工臨時表13';
10.2 插入列舉資料
10.2.1 使用串列值
-- 插入資料,使用串列值
insert into employees_temp13 values
(1,'張三','男');
10.2.2 使用索引
-- 插入資料,使用索引,從1開始編號
insert into employees_temp13 values
(2,'李四',2);
10.2.3 注意點
-- 不正常插入資料
insert into employees_temp13 values
(3,'王五',3); -- 不能插入資料
insert into employees_temp13 values
(4,'王五','未知'); -- 未知
insert into employees_temp13 values
(4,'王五',null); -- 允許插入null
10.3 列舉查詢
-- 帶條件查詢
-- 使用索引查詢
select * from employees_temp13 where emp_sex = 1;
-- 使用串列值查詢
select * from employees_temp13 where emp_sex = '男';
-- 查詢為null的
select * from employees_temp13 where emp_sex is null;
11、據備份和恢復
11.1 資料備份
# 作用1:備份就是為了防止原資料丟失,保證資料的安全,當資料庫因為某些原因造成部分或者全部資料丟失后,備份檔案可以找回丟失的資料,
# 作用2:方便資料遷移,當需要進行新的資料庫環境搭建,復制資料時,備份檔案可以快速實作資料遷移,
# 資料丟失場景:人為操作失誤造成某些資料被誤刪,硬體故障造成資料庫部分資料或全部資料丟失,安全漏洞被入侵資料惡意破壞等
# 非資料丟失場景:資料庫或者資料遷移,開發測驗環境資料庫搭建,相同資料庫的新環境搭建等
# 方式1:前面介紹的Navicat或者SQLyog,匯出腳本
# 方式2:MySQL提供了mysqldump命令,可以實作資料的備份,可以備份單個資料庫、多個資料庫和所有資料庫,
# 語法:mysqldump -h主機ip –u用戶名 –p密碼 [option選項] 資料庫名 [表名1 [表名2...]] > filename.sql
# 最后的檔案名:可以直接是單個檔案,也可以檔案名前加上可以訪問的絕對路徑,如:d:/filename.sql 或則 /usr/tmp/filename.sql
# 選項指令說明:
# --add-drop-table :匯出sql腳本會加上 DROP TABLE IF EXISTS 陳述句,默認是打開的,可以用 --skip-add-drop-table 來取消
# --add-locks :該選項會在INSERT 陳述句中捆綁一個LOCK TABLE 和UNLOCK TABLE 陳述句,好處:防止記錄被再次匯入時,其他用戶對表進行的操作,默認是打開的
# -t 或 --no-create-info : 忽略不寫創建每個轉儲表的CREATE TABLE陳述句
# -c 或 --complete-insert : 在每個INERT陳述句的列上加上欄位名,在資料庫匯入另一個資料庫已有表時非常有用
# -d 或 --no-data :忽略,不創建每個表的插入資料陳述句
# --where : 只轉儲給定的WHERE條件選擇的記錄
# --opt 該選項是速記;等同于指定(--add-drop-table,--add-locks,--create-options,--disable-keys,--extended-insert,--lock-tables,--quick,--set-charset)
# 該選項默認開啟,但可以用 --skip-opt 禁用,如果沒有使用 --opt,mysqldump 就會把整個結果集裝載到記憶體中,然后匯出,如果資料非常大就會導致匯出失敗
# -q 或 --quick : 不緩沖查詢,直接匯出到標準輸出,默認為打開狀態,使用--skip-quick取消該選項,
-- 備份資料庫的語法不能在navicat中執行,跟mysql名是同級的,命令列執行
11.1.1 備份整個資料庫
mysqldump -u root -p bbsdb > D:/sqlDumpTest/bbsdbTemp.sql
11.1.2 備份整個資料庫,插入資料陳述句前 增加列名指定 -c
mysqldump -u root -p -c bbsdb > D:/sqlDumpTest/bbsdbTemp.sql
11.1.3 備份單張表
mysqldump -u root -p -c bbsdb bbs_detail > D:/sqlDumpTest/bbsdbTemp.sql
11.1.4 備份多張表
mysqldump -u root -p -c bbsdb bbs_detail bbs_sort > D:/sqlDumpTest/bbsdbTemp.sql
11.2.5 備份多個資料庫
mysqldump -u root -p --databases [option] bbsdb [xxdb1 xxdb2] > D:/sqlDumpTest/bbsdbTemp.sql
11.2.6 備份所有資料庫
mysqldump -u root -p --all-databases bbsdb [xxdb1 xxdb2] > D:/sqlDumpTest/bbsdbTemp.sql
11.2 資料恢復
資料恢復:前提,先備份資料檔案;
11.2.1 source命令
-- 方式1:使用source命令,是在MySQL的命令列中執行的,所以必須登錄到MySQL資料庫中,且要先創建好資料庫,并切換到當前資料庫中
-- source D:/sqlDumpTest/bbsdbTemp.sql
11.2.2 mysql指令
-- 方式 2:使用mysql指令,不需要登錄
-- 語法:mysql -uroot -p db_name < D:/sqlDumpTest/bbsdbTemp.sql
11.2.3 多資料備份
--方式3:如果備份的是多資料庫,備份的資料庫檔案中,包含創建和切換資料庫陳述句,不需要先創建資料庫,直接使用source命令
-- 語法:登錄到mysql中,在命令列中執行
-- source D:/sqlDumpTest/bbsdbTemp.sql
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500467.html
標籤:其他
下一篇:Redis SCAN命令