2008年,“大資料”一詞在《大資料時代》中被首次提出,距今已有整整14個年頭,在這14年中,許多人親眼見證了資料的力量,以及目睹它如何改變世界,大部分企業的決策者都明白了一個道理:資料才是企業中最有價值的商品,它可以被人為選擇成就還是破壞業務,
然而,自流行詞“大資料”出現的14年后,如何獲得更高質量的資料,以及更智能的資料管理,幫助企業做出明智和及時的決策,仍然是許多企業的“疑難雜癥”,每個人的嘴里都在談論資料治理和資料管理,卻沒有人真正知道該怎么辦,
幸運的是,一種幫助企業提升資料分析質量和效率的方法論正在興起,它就是DataOps,基于DataOps,企業資料中臺可以實作資料利用率最大化,加快生產周期,及針對結果優化的資料管道,
今天,我們將展開說說DataOps,以及為什么它對于每一個想要真正實作資料賦能業務的企業都很重要,
一、DataOps是什么
DataOps(Data Operations)并不是一個新的概念,根據維基百科的說明,早在2014年就被IBM(Lenny Liebmann)提出,在2017年得到大范圍關注,并在2018年正式被納入Gartner的資料管理技術成熟度曲線當中,
今年,中國信通院正式牽頭啟動了DataOps的標準建設作業,以此為基礎推動我國大資料產業的多元化發展,為企業經營決策提供資料支持,
同時需注意的一點,DataOps不是一個工具或產品,可以理解成一種「方法論,或者最佳實踐」,類似軟體開發中的「敏捷方法」,不能以功能的視角去看待DataOps,而是以「我應該如何做」的視角來看待此問題,
DataOps的目標是提供工具、程序以及結構化的方式來應對快速增長的資料,對企業內的資料團隊賦能,能夠使企業內的資料團隊更高效、高質量的完成資料分析,它強調交流、協作、多系統集成以及自動化流程,并配套具備對應的度量方式,
二、DataOps的涵蓋內容
下圖為標準的DataOps涵蓋的內容,主要包括資料技術、資料管道、資料處理3個方面,最終為商業用戶輸出價值,
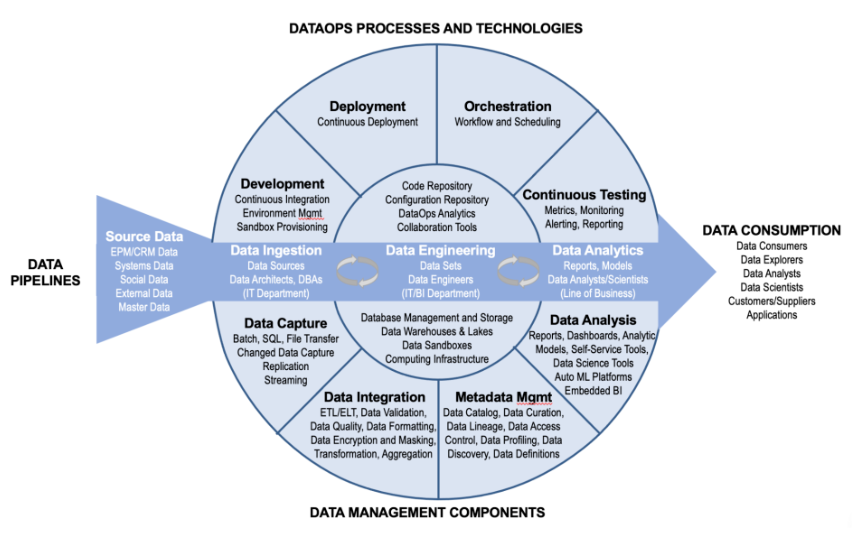
原圖出自:https://www.eckerson.com/articles/diving-into-dataops-the-underbelly-of-modern-data-pipelines
三、數堆疊DataOps實踐
從發展上看,自2018年被納入Gartner的資料管理技術成熟度曲線中以來,DataOps的熱度逐年上升;從實踐上看,歐美企業對于DataOps的探索和發展要早于中國,DataOps在我國仍處于一個從萌芽期到爆發期的關鍵過渡階段,
數堆疊依據多年經驗,通過敏銳的嗅覺快人一步開始探索DataOps的實踐,總結出DataOps的3個層次+4個核心能力,助力企業加快資料洞察的步伐,具體分析如下:
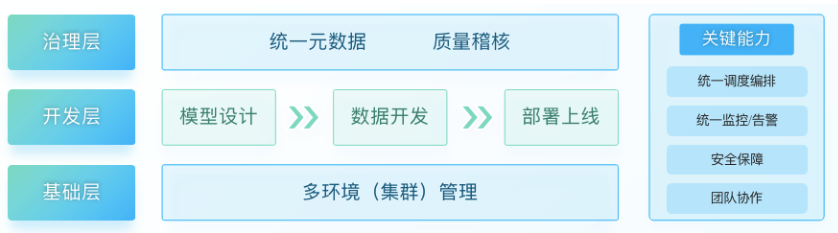
1、基礎層:多環境(集群)管理
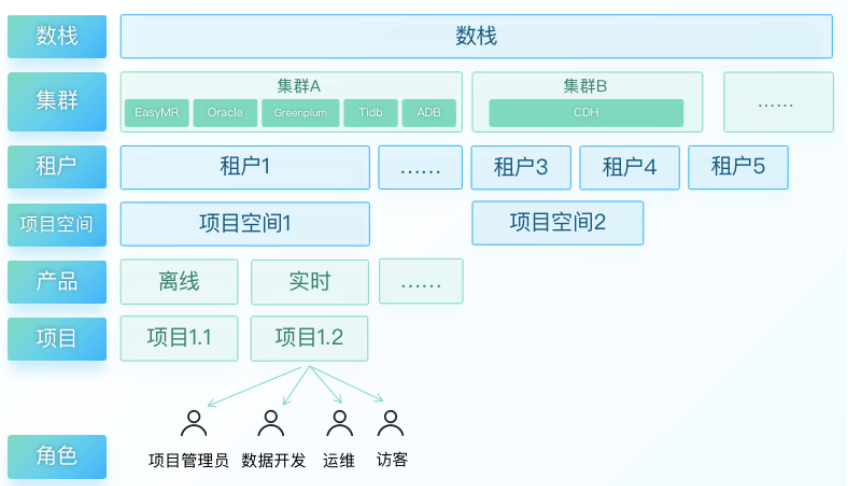
在基礎層,數堆疊支持多環境多集群管理,支持一套統一的平臺來對接多套不同規模、不同型別的集群,支持Cloudera Hadoop、華為FusionInsight、華為MRS、星環Inceptor、Greenplum、GaussDB、MySQL等各類資料庫作為計算引擎,提供統一的開發與應用體驗,具備跨云部署以及對跨云EMR的兼容能力,面向多云場景提供統一開發、統一管控能力,用戶可在不同的集群環境中(同型別引擎)實作代碼及相關資源的無縫發布,
2、開發層:資料開發全鏈路
按照資料開發的基本程序,分為:模型設計、資料開發、部署上線、質量稽核4個步驟,日常用戶的主要操作均是在這4個步驟之中,下面詳細闡述:
1)模型設計
按照標準的資料中臺建設模式,分為「制定標準」、「模型設計」2大部分,制定標準、模型的在線設計均可在數堆疊中在線進行,無需線下維護單獨的資料標準檔案、資料模型檔案等內容,普通開發人員完成模型設計后,需提交管理員審核,模型經審核后允許上線/變更操作,
模型設計及標準制定可細分為6個單元,如下圖所示:
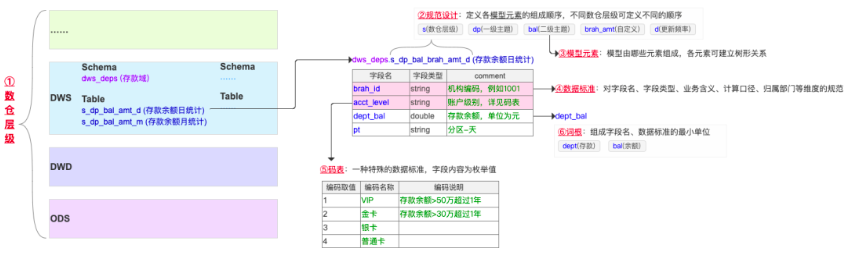
其中數倉層級、規范設計、模型元素屬于表級別定義,資料詞表、詞根、碼表屬于欄位級別定義,數堆疊將6個單元以產品化的形式進行梳理、組合,便于企業建立自己的資料治理體系,
3)資料開發
資料開發環節,通過豐富的任務型別、代碼的版本管理、責任人機制等,實作資料開發、資料分析的可持續發展,具體內容如下:
● 20+種豐富的任務型別
支持離線同步、實時同步、離線計算、實時計算、關系型資料庫計算、管理節點、腳本任務等5大類,20+種不同的任務型別,用戶可將企業內的資料采集、加工的各類離線、實時處理程序統一由數堆疊進行管理,實作一體化的資料開發平臺,
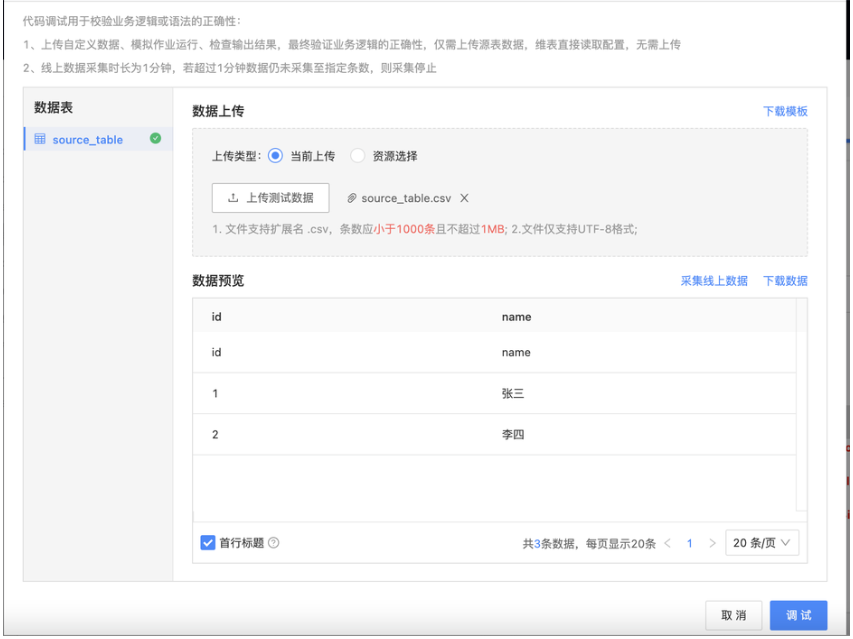
● 資料測驗
支持上傳樣本資料,模擬測驗,進行資料邏輯驗證與測驗,
● 代碼預檢查
提交代碼之前進行「預檢查」,防止上線后發生問題,
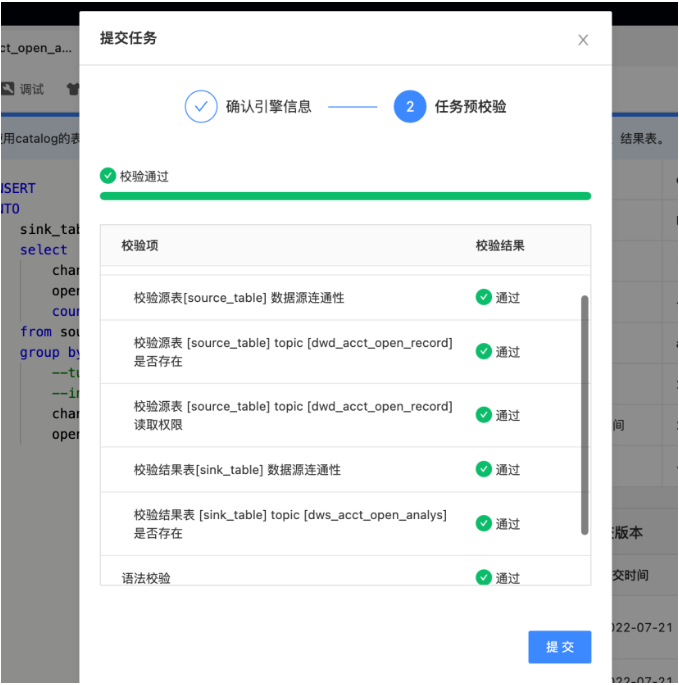
未來數堆疊將在系統規則的基礎上,支持自定義校驗規則,用戶可基于數堆疊暴露的介面進行自定義開發,例如代碼JOIN次數限制、磁區表禁止全表掃描、禁止跨數倉層級訪問等規則,可通過自定義開發Jar包的方式進行自定義規則校驗,
3)部署上線
用戶完成開發后,需將代碼從測驗環境發布至生產環境,平臺需支持快速的任務發布,將開發/測驗環節的代碼及其依萊澩快速發布至生產環境,
數堆疊的部署發布分為兩種模式:
● 雙專案模式
可將一個專案中開發的任務發布至另一個專案,雙專案模式可以在代碼層和底層資料層面實作很好的隔離性,保障資料安全,
● 匯入匯出式發布
對于物理環境隔離的場景,可將開發的任務代碼、依賴的UDF函式、Jar包等關聯資源一起匯出為zip包,并在生產環境執行一鍵匯入,
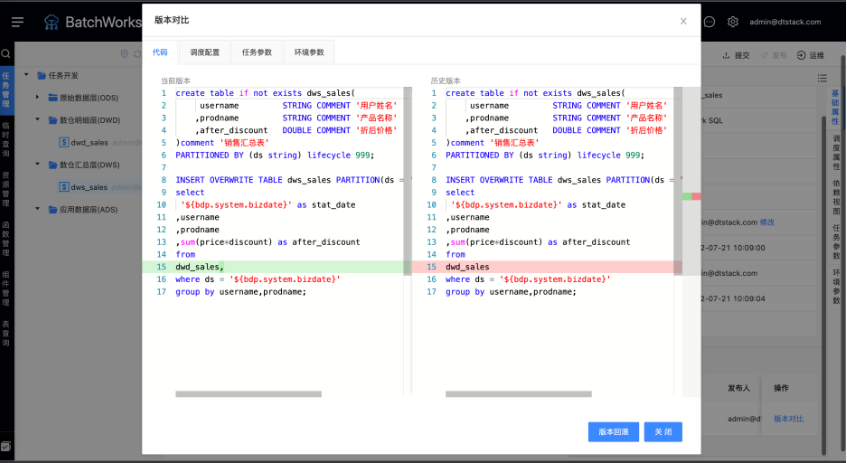
除了代碼發布外,還支持代碼的版本管理、版本對比、快速回滾能力,數堆疊能記錄每次提交發布的任務代碼和運行引數,并標注每個版本的修改內容,幫助定位代碼問題,同時可支持一鍵版本回滾,
3)治理層:統一元資料 質量稽核
治理層主要包括統一元資料及質量稽核兩塊能力:
統一元資料
支持將數堆疊平臺內的各類元資料匯聚、展示、打通、分析等,包括:元資料基礎屬性、離線表/任務、實時表/任務、API、標簽、指標等各類元資料,
● 全域血緣打通
根據資料在中臺內的采集、流轉、對外服務等各環節的處理方式,自動建立全平臺的血緣關系,基于核心的智能化SQL血緣決議能力,實作平臺內跨應用的血緣打通,可視化展示資料的流轉影響鏈路,
● 資產分析
可支持資產的版本變更記錄/對比、資料產出分析、使用分析、質量分析等統計內容,
質量稽核
支持對資料進行質量校驗,幫助企業及時發現資料問題,通過事前規則配置、事中規則校驗、事后分析報告的流程化方式,對資料的完整性、準確性、規范性、唯一性、一致性等方面進行多維度評估,保障企業資料質量服務,支持規則配置、任務查詢、實時校驗等,
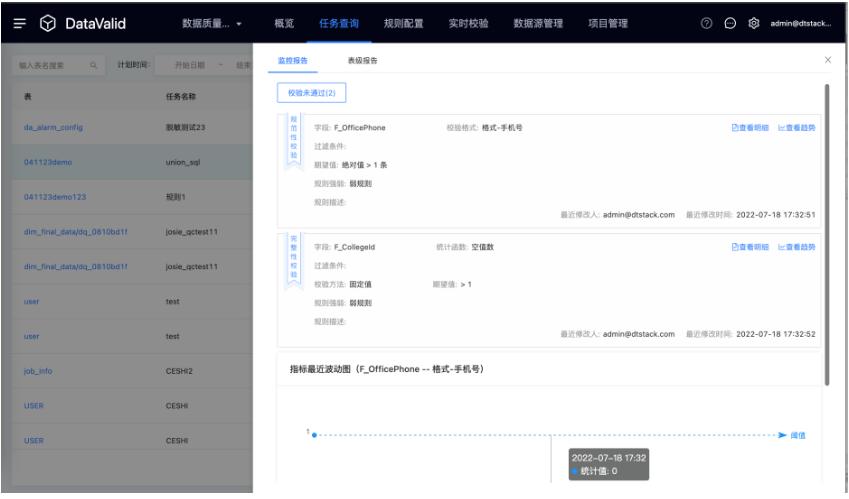
4)關鍵能力
數堆疊DataOps包括以下四大能力:
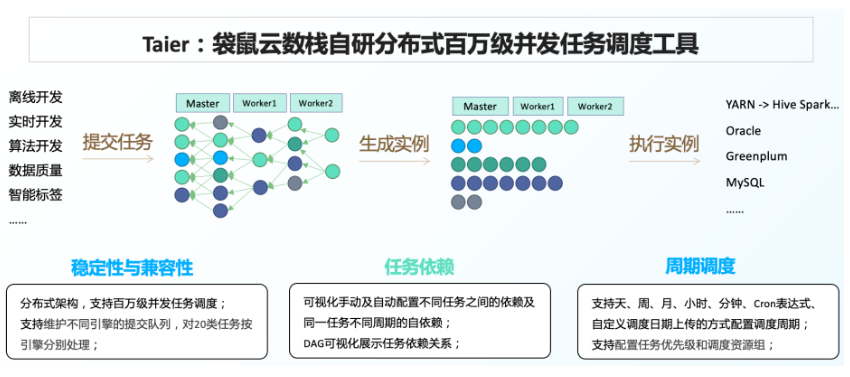
統一調度編排
數堆疊內置分布式調度引擎Taier,支持百萬級別復雜依賴調度,調度平臺在數堆疊內為底層通用能力,離線、實時、質量校驗、標簽、指標等各任務均使用統一的調度能力,
在此基礎上,各產品模塊之間可進行靈活的相互依賴,例如離線完成資料抽取+計算后,自動觸發標簽任務的計算等場景,
統一監控/告警
數堆疊支持統一的告警通道,不同的產品模塊內可能都會使用告警能力,例如離線任務突破基線、實時任務失敗、API呼叫失敗、質量校驗未通過等,針對某個告警通道僅需開發一次,即可再各個產品內使用此告警方式,例如短信、郵件,企業微信、釘釘、電話告警等,
模型設計
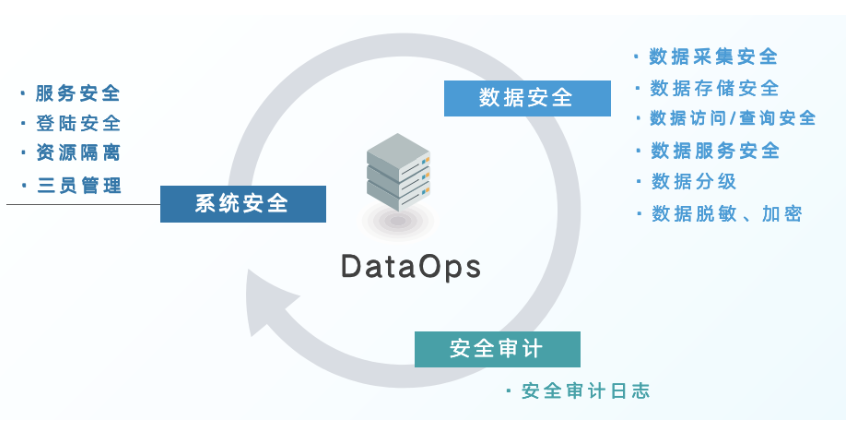
數堆疊在資料安全層面可分為如下幾個方面:
● 系統安全
通過服務高可用部署、資料定期備份等策略保障服務安全,登錄密碼可按照長度、復雜度、強制定期更換等方式支持多種安全策略,密碼采用國密加密傳輸+加密存盤,
● 資料安全
底層可集成LDAP+Ranger+Kerberos資料安全組件,在Hadoop體系內可支持庫、表、列、行級資料權限控制,在服務安全方面,可支持行、列權限控制、多種認證方式、國密加密等特性,保障用戶資料安全,
● 安全審計
自動記錄用戶的關鍵操作行為、資料訪問行為,可由管理員進行用戶操作行為審計,排查例外行為,
團隊協作
● 責任人機制
每個任務、表、標簽、API、指標、告警配置等「資源」均建立責任人機制,當發生例外需配合排查時,可快速獲取相關負責人,便于線下溝通,
● 一鍵交接
當發生人員變動時,支持一鍵交接,可批量將當前負責人的全部資源自動替換,便于作業交接,
● 用戶組
當開發團隊規模較大,需要再次細分時,可按照用戶組的方式進行管理,例如按用戶組批量添加用戶、分配功能權限/資料權限、發送告警等場景,無需反復操作,
四、結語
隨著時間的推移,資料的數量、頻率、多樣性都在增加,在一個萬物皆可被度量的時代,資料積累的速度超過大部分企業跟上其腳步的速度,這也意味著能夠幫助企業完成自動化日常任務,提高資料質量,促進不同團隊之間的協作,帶來更準確的洞察和分析,以及助力企業進入敏捷、自動化和加速的資料供應鏈環境的DataOps,未來將會在企業的數智化蛻變中,發揮不可小覷的作用,
企業實作 DataOps 有賴于一系列廣泛的技術和流程,數堆疊目前已經在采集、加工、治理的核心流程上,通過版本控制、團隊協同、一鍵發布、質量稽核、資料安全等能力實踐了基本的DataOps理念,但依然有很多方面亟需改善,例如:利用AI/ML技術降低人為操作的成本與失誤、對研發效能增加更多的的度量指標(Metric),以資料化的方式來衡量研發效能的增減等方面,均需要數堆疊團隊,以及全行業一起努力,
袋鼠云開源框架釘釘技術交流qun(30537511),歡迎對大資料開源專案有興趣的同學加入交流最新技術資訊,開源專案庫地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500472.html
標籤:其他