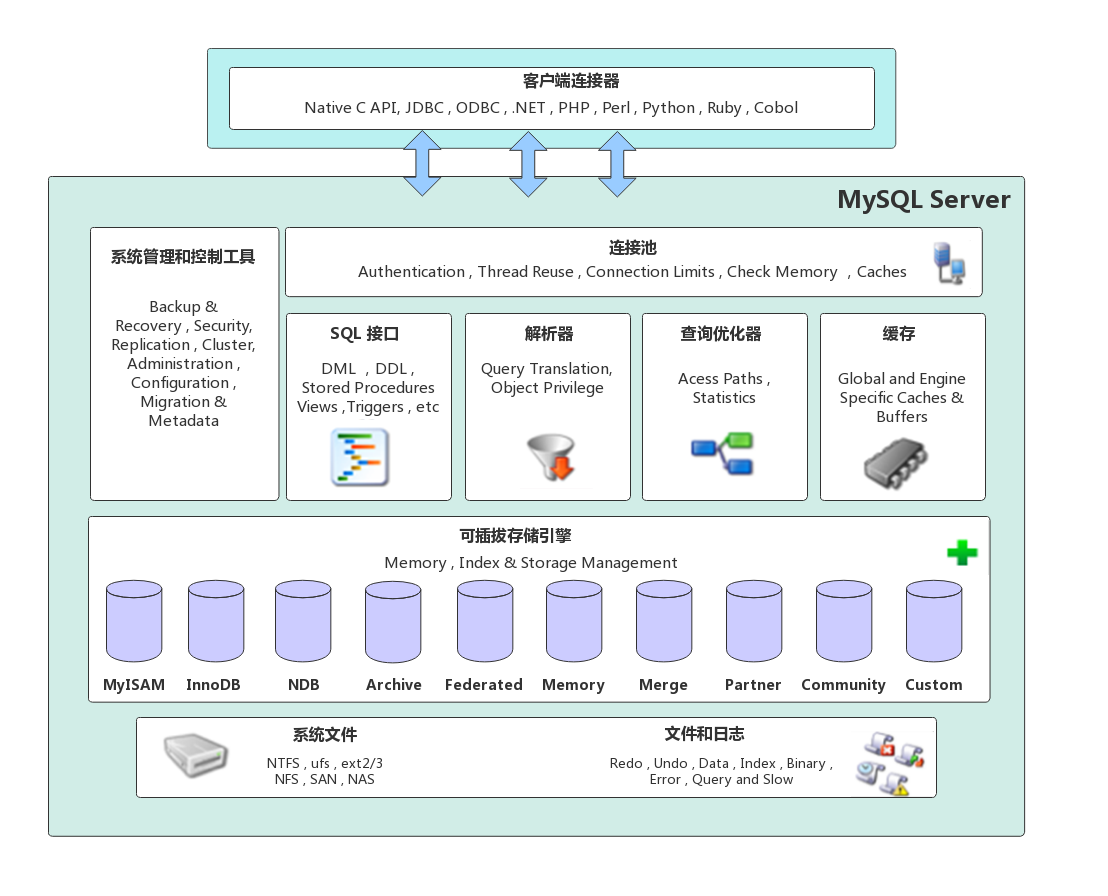
一、Mysql的系統架構圖
二、Mysql存盤引擎
Mysql中的資料是通過一定的方式存盤在檔案或者記憶體中的,任何方式都有不同的存盤、查找和更新機制,這意味著選擇不同的方式對于資料的存取有效率的差距, 這種不同的存盤方式在 MySQL中被稱作存盤引擎,
存盤引擎是Mysql資料庫系統的底層組件,資料庫管理系統通過這些組件來進行創建、查詢、更新和洗掉資料,它操作的物件是表,存盤引擎型別在肉眼上體現為表的型別,Mysql的存盤引擎型別可以通過運行命令' SHOW ENGINES; '獲得,目前Mysql8支持的存盤引擎有如下幾種:
- FEDERATED:將資料存盤在遠程資料庫中,用來訪問遠程表的存盤引擎,
- MRG_MYISAM:是一組MyISAM的組合,他將MyISAM引擎的多個表聚合起來,但是他的內部沒有資料,真正的資料依然是MyISAM引擎的表中,但是可以直接進行查詢、洗掉更新等操作,
- MyISAM:是MySQL早期默認的存盤引擎,擁有較高的插入、查詢速度,表鎖設計,支持全文索引,但不支持事務和外鍵,
- BLACKHOLE:充當一個“黑洞”,接受資料,但將其扔掉,不存盤資料,類似于Linux系統中的/dev/null檔案,主要用于查找和存盤引擎無關的其他方面的性能瓶頸,
- CSV:會在MySQL安裝目錄data檔案夾中,和該表所在資料庫名相同的目錄生成一個.CSV檔案,它可以將CSV型別的檔案當做表進行處理,相比其他存盤引擎的檔案內容,可以直接查看和編輯,
- MEMORY:資料保存在記憶體中,表結構保存在磁盤上,如果資料庫重啟或者發生崩潰,表中的資料都將消失,非常適用于存盤臨時資料的臨時表,
- ARCHIVE:用于資料存檔的引擎,僅僅支持最基本的插入(insert)和查詢(select)兩種功能,Archive擁有很好的壓碩訓制,比MyISAM、InnoDB存盤引擎更加節約存盤空間,
- InnoDB:是MySQL當前版本默認的存盤引擎,支持事務安全表(ACID),支持行鎖定和外鍵,要求實作并發控制,需要頻繁的更新、洗掉操作的資料庫,那選擇InnoDB有很大的優勢,
- PERFORMANCE_SCHEMA:MySQL資料庫系統專用引擎,用戶不能創建這種存盤引擎的表,
查看當前默認的存盤引擎:
SHOW VARIABLES LIKE 'default_storage_engine%';
修改默認存盤引擎(臨時生效,重啟后恢復InnoDB):
SET default_storage_engine=< 存盤引擎名 >
修改單個資料表的存盤引擎:
ALTER TABLE <表名> ENGINE=<存盤引擎名>;
查看資料表的存盤引擎:
SHOW CREATE TABLE tablename \G
修改表的默認存盤引擎,要想永久生效,需要在組態檔my.cnf中 [mysqld] 后面加入:
default-storage-engine=存盤引擎名稱
如何根據業務場景來選擇合適自己的存盤引擎呢?這需要先了解幾種存盤引擎的特性,以下是幾種存盤引擎的特性表,可做參考:
| 特性 | MyISAM | InnoDB | MEMORY |
|---|---|---|---|
| 存盤限制 | 有 | 支持 | 有 |
| 事務安全 | 不支持 | 支持 | 不支持 |
| 鎖機制 | 表鎖 | 行鎖 | 表鎖 |
| B樹索引 | 支持 | 支持 | 支持 |
| 哈希索引 | 不支持 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 | 不支持 |
| 集群索引 | 不支持 | 支持 | 不支持 |
| 資料快取 | 支持 | 支持 | |
| 索引快取 | 支持 | 支持 | 支持 |
| 資料可壓縮 | 支持 | 不支持 | 不支持 |
| 空間使用 | 低 | 高 | N/A |
| 記憶體使用 | 低 | 高 | 中等 |
| 批量插入速度 | 高 | 低 | 高 |
| 支持外鍵 | 不支持 | 支持 | 不支持 |
三、InnoDB存盤引擎存取原理
InnoDB是最常用的存盤引擎,我們的業務系統在使用Mysql作為資料庫的時候,一般都選擇InnoDB作為存盤引擎,原因是該引擎支持行鎖、索引、事務安裝、主外鍵,而這些特性正是業務系統資料所需要的,
資料在InnoDB中將被劃分為若干個頁,頁的大小一般為16KB,以頁作為存取資料的單位,前一節提到InnoDB的資料是存到磁盤上的,而程式代碼需要的資料是在記憶體中的,因此存取資料的操作實際上是磁盤和記憶體之間資料交換的程序,
以下是Mysql資料頁的結構圖,不同的部分代表著不同的功能,其中:
- File Header:表示檔案的頭部,存盤了一些頁的通用資訊,
- Page Header:表示頁面的頭部,存盤一些有關資料頁的資訊,
- Infimun+supremum:表示兩個虛擬的行記錄(最小記錄和最大記錄),
- UserRecord:真正用于存盤資料行的內容,
- FreeSpace:空閑部分,
- PageDirectory:頁目錄,記錄了某些記錄的位置,
- FileTrailer:頁尾,用于校驗頁的完整性,
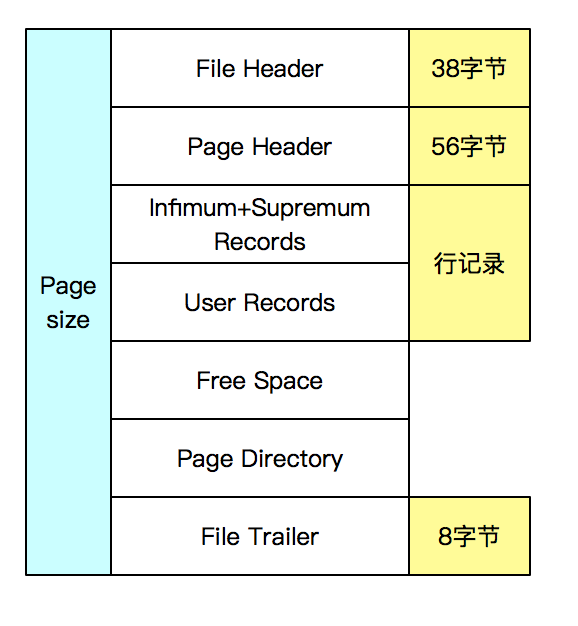
UserRecord這部分空間是可變的,當向資料庫中插入記錄時,資料會被存到這個位置,UserRecord空間被增加,同時FreeSpace容量會變小,直到空閑空間FreeSpace被用完,如果還有新的資料插入,則引擎會申請新的資料頁再進行存盤,
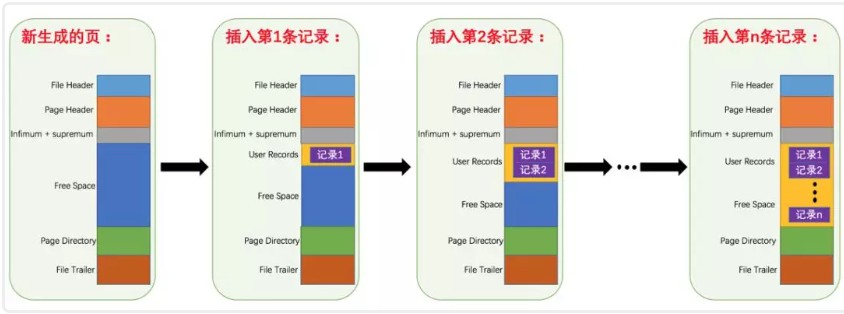
多條資料被存到UserRecord這個位置,那他們之間的物理位置有什么關系呢?這里牽涉到兩種主要關系,一種是同一資料頁之間的資料記錄位置關系,另一種是不同資料頁之間的記錄的位置關系,要談記錄的位置關系,我們要了解每條記錄的存盤結構,
每條記錄都包含我們存盤的真實欄位資料和記錄額外的資訊資料,一行記錄可以以不同的行格式存在,目前有Compact、Redundant、Dynamic、Compressed等幾種格式,以下是Compact行格式的圖解:
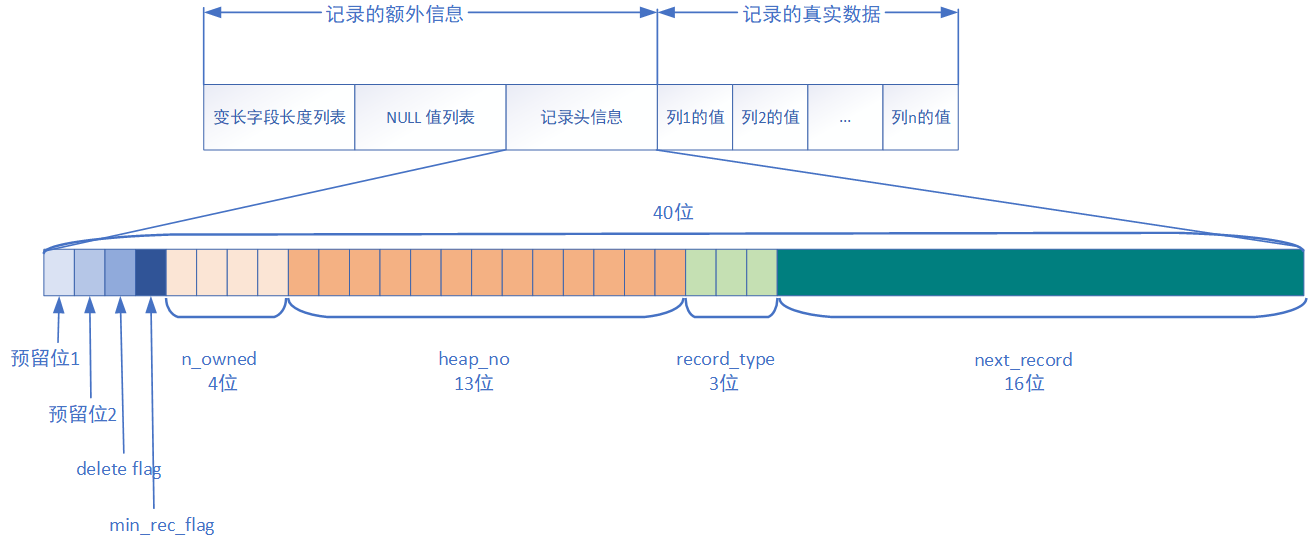
其中,每個屬性說明如下:
| 名稱 | 大小(bit) | 描述 |
|---|---|---|
| 預留位1 | 1 | 空閑 |
| 預留位2 | 1 | 空閑 |
| delete_mask | 1 | 標記記錄是否被洗掉(0未洗掉,1已洗掉),當標記為洗掉時沒有真實從物理磁盤中洗掉,只是代表這塊地址可以被覆寫 |
| min_rec_mask | 1 | 標記記錄是否為B+樹的非葉子節點中的最小記錄(索引時用到) |
| n_owned | 4 | 當前槽管理的記錄數 |
| heap_no | 13 | 記錄在堆中的相對位置 |
| record_type | 3 | 記錄的型別,0表示普通記錄,1表示B+樹非葉節點記錄,2表示最小記錄,3表示最大記錄 |
| next_record | 16 | 下一條記錄的相對位置 |
| NULL值串列 | 用于標記和統一管理值為NULL的列 | |
| 變長欄位長度串列 | 用于存盤可變長度的欄位的值占用的位元組數 |
記錄是以單向鏈表的方式存盤的,因此:
- 當我們插入一條記錄時,新的記錄會記錄下它在堆中的位置并更新相鄰的前一記錄的next_record值為它的heap_no,更新它的next_record值為它的相鄰位置后一記錄的heap_no值,
- 當我們洗掉記錄時,該記錄的delete_mask會被標記為1,同時相鄰的前一記錄的next_record值被更改為它的下一記錄的heap_no值,
思考一個問題:如果一個資料表的列欄位很多或者存盤的值太多,一個資料頁存不完怎么辦?在Compact行格式中,對于占用存盤空間很大的列,在記錄真實資料的地方只存盤一部分資料,把剩余的資料分散存盤在其它頁中,通過在記錄資料的尾部存盤指向其它頁資料的地址來關聯這些分散的資料,
四、InnoDB索引原理
我們知道,資料庫使用索引的目的是為了加快查詢速度,那么MySQL是如何實作索引的呢?
對于資料行的插入,默認情況下是順序存盤(按主鍵排序)的,查詢的時候將按照插入的順序顯示結果,當一個資料頁存盤欄位較少且欄位值內容較少的時候,很有可能這個資料頁就能夠同時存盤上千行記錄,前一節我們說過,資料是以單向鏈表的方式存盤的,這種存盤方式對于插入來說比較快,而對于查詢來說就比較慢,如果我們需要使用where查詢條件從上千行記錄中獲取滿足條件的記錄,如何才能加快查找速度呢?
InnoDB引擎為我們提供了一個叫做PageDirectory的頁目錄,這個概念在前面介紹資料頁結構的時候提到過,它用于為資料頁的行記錄提供目錄索引,類似書籍的章節目錄,能夠幫助我們快速定位資料記錄所在的分組,從而加快查詢速度,其實作原理是:將頁內所有非洗掉的記錄劃分為N個組,每個組里最后一條記錄(主鍵最大的記錄)的n_owned屬性記錄了組內的記錄數量,將這條記錄的偏移地址取出按序從File Trailer位置開始向前寫入形成PageDirectory,其中偏移地址稱為'槽',圖示如下:
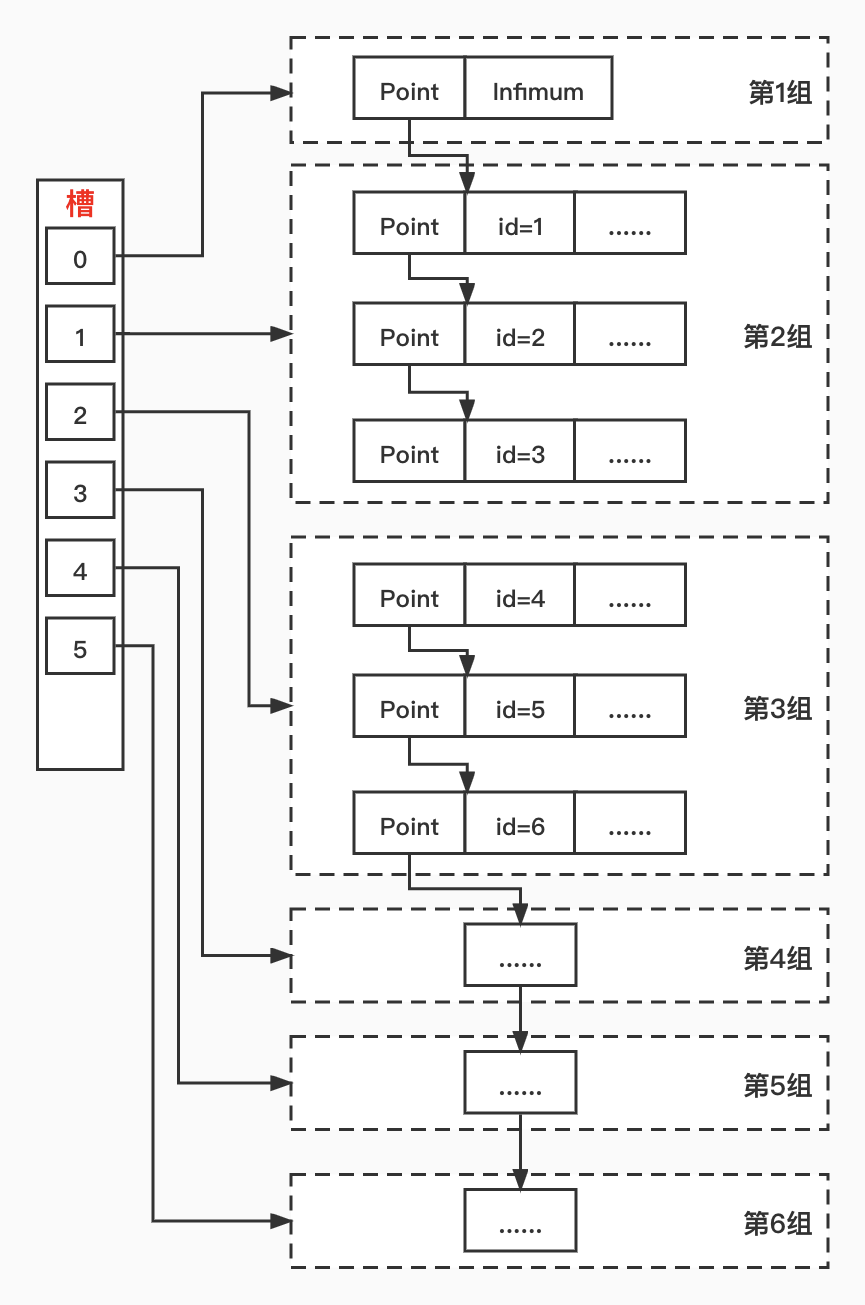
根據上圖所示.如果我們要獲取id=4的記錄,可以先通過二分法從目錄頁中快速找到這一記錄所在的頁,然后在快速定位資料記錄所在的位置,
. 通過上面的決議,我們理解了從同一個資料頁中快速查找記錄的方式,再來想一想,如果資料行較多,分散存盤到了多個資料頁里,那又如何快速的確定資料在哪一個資料頁的哪一個分組呢?
InnoDB為我們提供了"資料頁"概念的同時,也給我們提供了一個叫做"目錄頁"的概念,目錄頁用于存盤資料頁的頁號和頁對應的記錄的最小主鍵(相當存了一組{key,value}鍵值對集合,key主鍵,value為頁號),因此在執行條件查詢時,先通過主鍵確定記錄所在的頁,在根據頁內的頁目錄定位(通過主鍵定位)到分組,從而快速獲取結果,結構圖示如下:
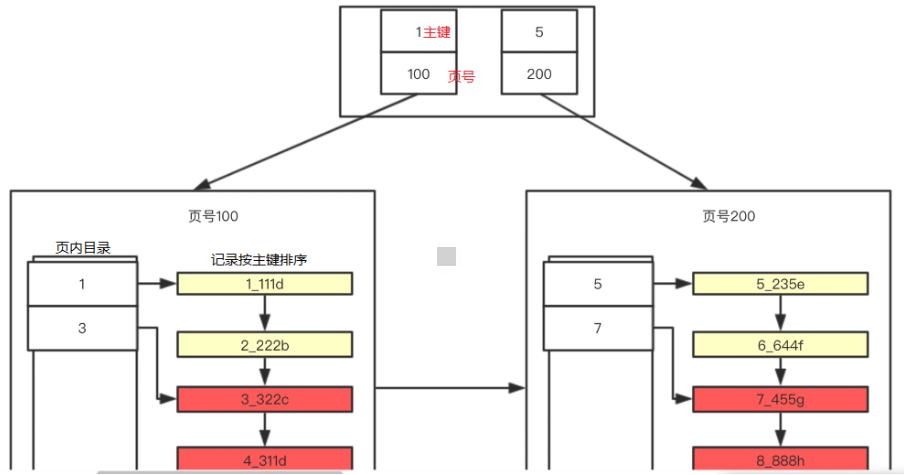
分析結構圖,發現結構是一棵B+樹,B+樹是一種樹資料結構,通常用于資料庫和作業系統的檔案系統中,B+樹的特點是能夠保持資料穩定有序,其插入與修改擁有較穩定的對數時間復雜度,B+樹元素自底向上插入,這與二叉樹恰好相反,B+樹的葉子節點用于存盤真實資料,非葉子節點用于存盤主鍵值和指標(頁碼),
前面我們提到資料在插入時是按照主鍵的順序來進行排序存盤的,所以這就是為什么我們在設計表時建議設定主鍵自增的原因(新增記錄時不會對之前的資料進行重新排列,這會加快插入的速度),其實一個資料行欄位除了我們自己創建的欄位之外,還存在三個隱藏的欄位row_id(行ID)、transaction_id(事務ID)、roll-pointer(回滾指標),如果我們設計表時沒有設定主鍵,也沒有設定唯一索引,那么它會自動以隱藏的欄位row_id來作為自增主鍵進行排序存盤,
思考一個問題:如果一個列的值占用空間較多,會發生什么?當一行記錄存盤的資料較多時,意味著要使用更多的資料頁,更多的資料頁意味著更多的目錄頁,這會增加" B+結構的高度 ",這也會隱形的降低查詢效率,
到這里我們已經知道,對于主鍵欄位來說,它會通過頁目錄和目錄頁的方式來增加資料查詢速度,但是在實際開發中,我們可能還需要通過其他欄位的查詢條件來篩選資料,那么InnoDB引擎又是如何通過什么方式來增加查詢速度的呢?
其實,我們也可以為非主鍵欄位來創目錄頁,這些目錄頁同樣組成了B+樹結構,只不過它的葉子節點存盤的是主鍵值,當通過非主鍵欄位查詢記錄時,首先會通過非主鍵目錄頁B+樹結構查找到主鍵,再去呼叫主鍵的目錄頁B+樹,去查找真實資料,我們知道,除了可以為單獨為非主鍵欄位的某一個欄位創建索引,還可以使用聯合多個欄位來創建一個索引,這兩種方式的實作方式都是相同的,
根據前面的分析和探究,我們需要知道如下幾點:
- InnoDB引擎在磁盤和記憶體之間進行資料傳輸時是以“ 資料頁 ”為基本單位傳輸的,
- 資料行記錄是以單向鏈表的方式存盤的,特點是插入快,更新和查詢慢,
- 目錄頁能夠幫助引擎快速定位記錄所在的資料頁,
- 頁內目錄能夠幫助引擎快速定位記錄所在的分組,
- 為某個欄位創建索引就相當于為這個欄位創建了一個B+樹結構的目錄頁,
- 以多個欄位為一體創建了一個索引就相當為這些欄位組合創建了一個B+樹結構的目錄頁,
- 如果定義表時指定了主鍵和唯一索引,則存盤時將以主鍵和唯一索引的邏輯順序進行物理存盤,這種索引中鍵值的邏輯順序決定了表中相應行的物理順序,這種索引稱為聚集索引,反正稱為非聚集索引,
- 如果定義表時沒有指定主鍵和唯一索引,則InnoDB會以隱藏的欄位row_id為主鍵進行資料存盤,
- 綜上前兩點證明,建表時會產生一個聚集索引(每張表值只有一個),聚集索引產生的B+樹結構的葉子節點存盤的是真實資料(完整資料),非葉子節點存盤的是主鍵和頁碼指標,
- 非聚集索引是手動創建的,用于在聚集索引之外創建目錄頁B+樹,葉子節點存盤的是索引列和主鍵值(不是指標),非葉子節點存盤的是索引列和頁碼指標,
- 為已經存在大量資料的表創建和修改索引時,可能需要長時間的等待操作,甚至導致資料庫崩潰,
五、表的掃描
我們已經了解了索引的原理,知道了可以為表建立多種索引方式,來加快我們的查詢速度,但是不同的索引型別的查詢效率是有區別的,mysql有幾種表的掃描機制:
- 全表掃描:遍歷整個主鍵索引的B+樹,并且需要讀葉子節點資料,
- 全索引掃描:遍歷整個二級索引的B+樹,
- 回表查詢:對于非聚集索引的查詢,會先查非聚集索引的B+樹定位主鍵值,再用這個值去聚集索引的B+樹上查找資料,
在進行資料查詢是應該盡量使用最小的掃描代價去獲得結果,這是SQL性能優化的核心思想,需要注意的是并非避免全表掃描就能獲得最佳效果,反之在具有多個索引的中,過多的索引組合反而可能導致效果不如全表掃描實在,這就是在創建索引時并非越多越好的原因,
Mysql給我提供了一個關鍵字explain用于分析和測驗sql陳述句的性能,在SQL陳述句前增加該關鍵字,運行后會回傳SQL執行計劃的資訊,通過這些資訊,可以幫助我們更好的選擇索引和優化SQL陳述句,例如運行如下陳述句得到結果如圖:
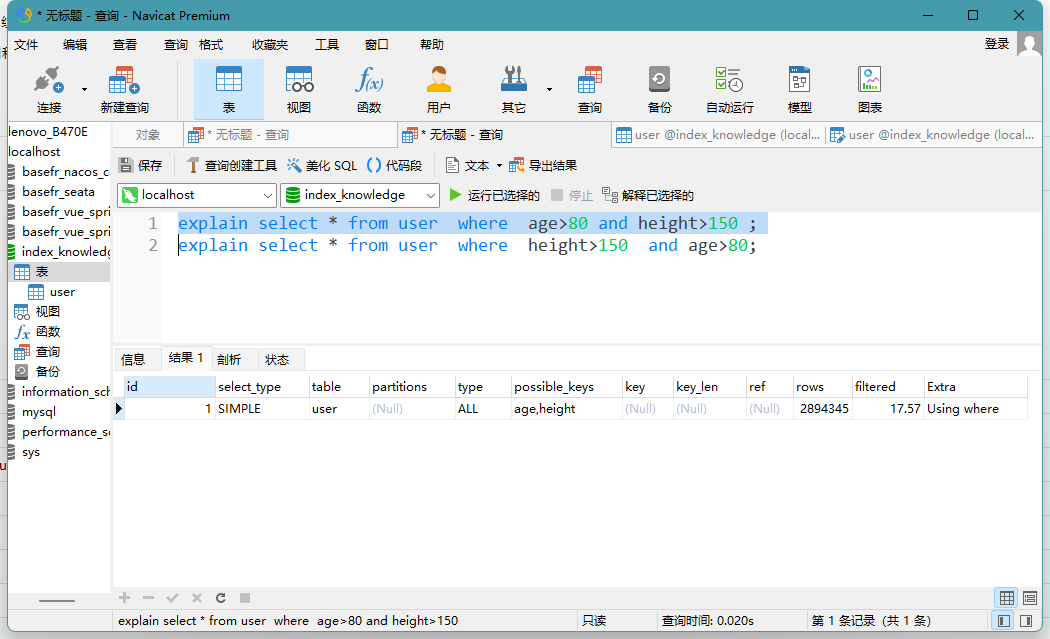
其中,結果集的每個欄位和可能的值說明如下:
| id |
查詢陳述句的序號:相同ID:多條記錄表示執行順序由上而下;不同ID:如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行, |
| select_type |
SIMPLE:簡單的select查詢,查詢中不包含子查詢或者UNION, PRIMARY:查詢中若包含任何復雜的子部分,最外層查詢則被標記為PRIMARY, SUBQUERY:在SELECT或WHERE串列中包含了子查詢, DERIUED:在FROM串列中包含的子查詢被標記為DERIVED(衍生)MySQL會遞回執行這些子查詢,把結果放在臨時表里, UNION:若第二個SELECT出現在UNION之后,則被標記為UNION;若UNION包含在FROM子句的子查詢中外層SELECT將被標記為:DERIVED, UNION RESULT: 從UNION表獲取結果的SELECT, |
| table | 表名:資料來自那張表, |
| partitions | 磁區表資訊,沒有磁區表則為NULL, |
| type | 訪問型別指標,查詢速度由快到慢:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index >ALL, |
| possible_keys | 可能選擇的索引,一個或多個, |
| key | 實際使用的索引,如果為NULL,則沒有使用索引, |
| key_len | 選擇的索引的長度,通常來說越小越好, |
| ref | 和索引匹配的列, |
| rows | 估算的掃描行數,越小越好, |
| filtered | 被條件過濾行數的百分比, |
| extra |
Using filesort:使了用臨時表保存中間結果, Using index:查詢使用了索引, Using where:使用了where過濾, Using join buffer:使用了連接快取, impossible where:where子句的值總是false,不能用來獲取任何資料, |
六、資料庫優化
我們已經了解了索引的原理,明白了資料頁的存盤結構是一棵B+樹,同時目錄頁存盤結構也是一棵B+樹,能夠通過索引定位資料所在的父節點,減少表的掃面,從而快速找到記錄,但是當存在的索引越多時,查找資料的實作方案就越多,那如何才能盡量讓我們撰寫的SQL盡量使用最優的方案呢?
文章頭部的Mysql架構圖中我們可以看到,我們撰寫的SQL陳述句在經過分析器進行語法分析后,傳遞給優化器,優化器幫助我們選擇索引并生成執行計劃,然后再交給執行器獲取操作結果,但是優化器并非萬能的,它只能為我們執行一些可控的優化,我們還需要從減少資料的碎片存盤、不同型別資料的索引效率、表的掃面機制等方面考慮,特此總結出如下幾個優化和設計規則:
- 控制欄位長度:在設計表的欄位的時候,根據業務需求,盡量控制欄位的長度空間不浪費,比如存盤身份證號的欄位不超過18個字符,手機號的欄位不超過11位,
- 控制欄位型別:根據mysql提供的欄位型別特性,來選擇合理的欄位型別存盤業務資料,比如存狀態0和1使用boolean型別而不使用字符型別CHAR(1),
- 盡量滿足表設計的三大范式,建立合理的資料庫結構,但同時也要考慮需求本身,
- 控制熱表資料量:結合業務需求,盡量讓熱表的資料量偏小,必要時采用分庫分表的方式,分表包括垂直分表和水平分表,具體根據業務需求來定,
- 盡量控制事務盡快提交和回滾,以免造成長時間鎖表鎖行,
- 盡量減少SQL參與過多的計算邏輯,比如createtime欄位不做時間格式轉換處理,
- 禁止使用外鍵來約束資料的一致性,如需約束請在業務代碼中實作,
- 盡量使用自增INT/BIGINT型別作為主鍵,使用CHAR和UUID作為主鍵會導致資料的存盤順序離散,產生磁盤碎片,
- 統一庫、表、存盤程序的字符集,字符集的不同會導致隱式轉換或報錯,或導致無法使用索引,InnoDB通常推薦使用utf8mb4,
- 索引會影響插入性能,單表索引數量不建議超過5個,必要時可以建立合適的多列索引并注意其順序,
- 核心涉密資料加密后存盤,這主要是為了資料泄露安全考慮,
- 使用INT型別來替代浮點型,避免使用浮點型這種效率較低的型別,
- 遇到BlOB、TEXT等大物件型別的資料,盡量拆分為單獨表,然后使用主鍵做關聯,
- 字符型別盡量使用靈活高效的varchar來代替char型別,盡量減少字串型別的加長更新操作,
- 日期型別盡量選擇datetime型別,因為timestamp型別只能存盤日期時間為1970-2038年,而char型別查詢效率比datetime低,
- 多表JOIN時,條件列的資料型別要一致,否則可能導致無法使用索引,
- 多表JOIN時,將過濾后結果集較小的表作為驅動表,
- SELECT時盡量不讀取不使用的列,這可以減少IO代價,
- 減少LIKE '% xxxx %'格式的使用,該陳述句會導致查詢不使用索引,必要時可以使用LIKE ' xxxx %'格式,它會使用前綴索引,
- 盡量主要' != '條件的使用,這有可能導致全表掃描,當然并非一定會全表掃描,具體情況的具體分析,
- 當能確定回傳結果數量時,最好加上LIMIT N,當查詢到指定數量結果后就會立即結束掃描,
- 優先使用UNION ALL代替UNION,因為UNION會產生臨時表,前者還不會產生去重的代價,
七、SQL的慢查詢分析
SQL的執行總是有一個執行時間的,我們可以給資料庫設定一個時間節點引數long_query_time,當SQL執行超過這個值時,便認為本次查詢是慢查詢,將被記錄到慢查詢日志中,有利于我們進行性能排查,默認的long_query_time默認值為10s,
開啟慢查詢日志:
- 在my.cnf中配置:
[mysqld] log-slow-queries=/data/mysqldata/slow-query.log #慢查詢日志的位置 long_query_time=10 #表示查詢超過10s就作為慢查詢
- 命令臨時開啟:
set global slow_query_log='ON'; #開啟慢查詢 set global slow_query_log_file='/usr/local/slow.log'; #指定日志檔案路徑 set global long_query_time=10; #自定慢查詢的時長
八、常用的SQL演算法設計
- 使用 WITH RECURSIVE tmp AS 語法實作遞回查詢,比如獲取數結構的所有子節點Id:
with RECURSIVE tmp as ( select * from work_order_question where id=4 union all select c.* from work_order_question as c,tmp t where c.parent_id=t.id ) select id from tmp
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/500862.html
標籤:MySQL
上一篇:mysql主從